Java:浅析类加载过程(一)
文章目录
- 本文主要内容
- 类加载模型:双亲委派模型
- 类加载类图
- 类加载过程
- 生成一个类库加载器
- 类库加载器的顺序是这么保证的?
- ClassPath的顺序是怎么来的?
- 我们重写的类,为啥能覆盖jar包里面的类呢?
- 加载配置文件的几种常见方式
- 类库加载器是如何加载类或者资源的
- 总结
《深入理解java虚拟机》一文中,把类加载的过程分为5步:加载、验证、准备、解析以及初始化。而第一步“加载”这个过程,虚拟机需要完成3大步骤:
(1)通过一个类的全限定名来获取此类的二进制流。
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
(3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
本文重点探讨“加载”的3大步骤中的第一个步骤的其中一部分,那就是:
通过一个类的全限定名获得此类的统一资源定位符(URL)。
为什么要研究这部分内容呢?自己分析了一下,对于开发者来说,只需要关注一下这部分就行了,基本上可以解决我们开发中的所有有关类加载的问题,至于其它的阶段里面的各种问题,正常开发的情况下很少能够碰到。
本文主要内容
主要是分析一下源码,了解一下类加载过程。
- 基本的类加载器与加载过程。
- 通过类名找到url,全过程源码分析解析。
- 浅析:我们重写了第三方包中的类,并把这个类拷贝在我们的工程下,为什么加载到的就是我们重写的类?
- 开发工具启动工程的时候与命令行启动有什么区别,他们分别做了什么。
- 常用的使用加载配置文件的方式:class.getResource()与classLoader.getResource()方法的源码解读与正确使用。
注:本文所有的源码都来自于虚拟机hotspot的JDK1.8。
类加载模型:双亲委派模型
在虚拟机中,有3种基本的类加载器:
- 启动类加载器(Bootstrap ClassLoader):主要负责加载%JAVA_HOME%/lib目录下的jar包。这个类加载器是由C++实现的,代码中无法引用到,但是仍然可以看到它的影子,比如在ClassLoader这个类里面有一个方法就是使用这个类加载去加载的:
private native Class findBootstrapClass(String name);
- 扩展类加载器(Extension ClassLoader):负责加载%JAVA_HOME%/lib/ext目录下的类库,这个类可以直接引用到,类名是:sun.misc.Launcher.ExtClassLoader
- 应用程序类加载器(Application ClassLoader):负责加载用户定义的类路径上的类库,也就是系统变量“java.class.path”上面指定的类库。这个类加载是我们最常用的,凡是使用main方法启动的程序都是用的这个类加载器。这个也是我们接下来要探讨的类加载器。类名是:sun.misc.Launcher.AppClassLoader
我们的应用程序一般都是使用上述3种类加载器,当然也会有自定义的一些。类加载对象中有一个属性,叫做parent,也是类加载器。也就是在新建类加载器的时候,需要指定父类加载器。这几种类加载器的关系如下图所示:
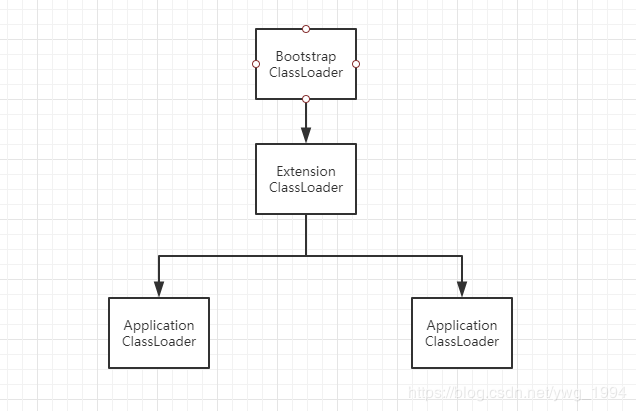
每个类加载器都有父类加载器,从ClassLoader的方法里面就能看出来,优先使用父类加载器去加载器,如果没有加载到才会使用自己的。
protected Class loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先看一下有没有被加载过
Class c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//使用父类加载器架子啊
c = parent.loadClass(name, false);
} else {
//没有父加载器的话,就使用启动类加载器
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
//如果没有找到,再使用自己的去加载。
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
这边实现的话使用了组合,而不是继承。这一点也在平时开发过程中非常关键,如果有时候我们需要使用一些父类的方法的时候,也并不一定必须继承,也可以用一个属性指向父类,反正就是:多用组合少用继承。
从这点来看,我倒觉得明明是单亲啊,为什么要叫做双亲呢,哈哈。可能双亲指的是:每一个应用程序的类加载器都会有扩展类与启动类加载器这两个类加载器。
因此,我们如果重写了JDK本身的一些类,编译本身不会有问题,但是在运行态永远加载不到自己写的类,原因也很简单。
在此简述了一下类加载器模型,当然这也仅仅是JDK本身推荐的方式,并不是强制的。关于类加载机制应用的比较好且值得我们学习就是tomcat与osgi框架了。
类加载类图
稍微先看一下应用程序类加载器的类图,如下:
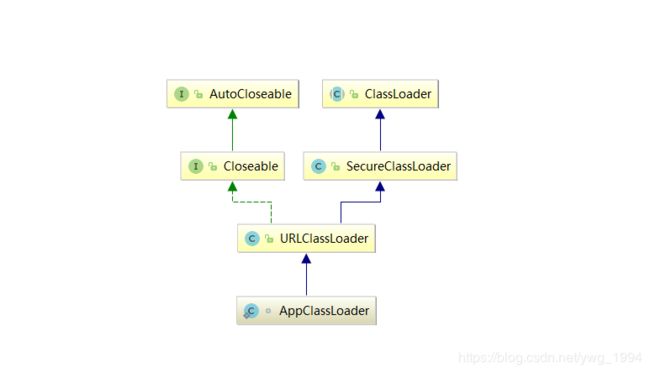
看下右侧的继承关系即可,重点研究的类是URLClassLoader,就是通过URL去加载一个类。什么是URL呢,就是统一资源定位符,能够定位到一个class文件的资源描述符,常见的class文件都会在一个jar包里面或者文件夹下面。
类加载过程
我们要加载一个自己定义的类,叫做:com.ywg.Test,一般需要执行以下代码:
try {
Thread.currentThread().getContextClassLoader().loadClass("com.ywg.Test");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//然后执行的是ClassLoader类里面的方法
ClassLoader.loadClass(String name);
ClassLoader.loadClass(String name, boolean resolve);
//因为是自己定义的,上面两个方法肯定加载不到,需要执行子类的findClass(String name)方法。
URLClassLoader.findClass(final String name);
这个方法的内容重点如下:
protected Class findClass(final String name)
throws ClassNotFoundException
{
final Class result;
try {
//AccessController.doPrivileged这个方法底层代码经常会出现,可以忽略。直接认为就是执行PrivilegedExceptionAction接口的run方法的实现。
result = AccessController.doPrivileged(
new PrivilegedExceptionAction>() {
public Class run() throws ClassNotFoundException {
//转换成com/ywg/Test.class
String path = name.replace('.', '/').concat(".class");
//重点就是这行代码,后面的所有分析都是这行代码,也是本文的主题。
//这个的返回就是资源的描述符,包含了这个类的一个URL。
//这个ucp是:URLClassPath
Resource res = ucp.getResource(path, false);
if (res != null) {
try {
return defineClass(name, res);
} catch (IOException e) {
throw new ClassNotFoundException(name, e);
}
} else {
return null;
}
}
}, acc);
} catch (java.security.PrivilegedActionException pae) {
throw (ClassNotFoundException) pae.getException();
}
if (result == null) {
throw new ClassNotFoundException(name);
}
return result;
}
Resource res = ucp.getResource(path, false);
这行代码就是本文的重点了。
生成一个类库加载器
URLClassPath这个类是在sun包下面的,因此没有源码。下述代码都是反编译出来的。
- 先看一下URLClassPath这个类有哪些重点属性:
private ArrayList path;
Stack urls;
ArrayList loaders;
HashMap lmap;
- ArrayList path:有序列表,表示的就是这个类加载器能加载到的所有的类库路径。这个是初始化对象的时候必须提供的属性,应用程序的类加载器的话,这个值就是系统变量“java.class.path”的值。
- Stack urls:堆栈,在初始化的时候,会把path所有的值,反向压在栈中。但是这里面的值不仅仅是path,还会包含path里面每一个jar包所依赖的其余类库(如果有的话)。这个变量表示的应该是维护了一组还没有执行过任何类加载动作的类库路径。就是知道我依赖了你,但是我还没有从你那边加载过任何类,就先暂时放在urls,加载一个,就取出来一个,同时生成这个类库的加载器,以后直接就用类库加载器进行加载了。我把它称之为:待处理类库。当程序正常运行的时候,urls这个变量应该是空的。
假设有这样一种场景,我通过java -jar 启动一个应用程序,没有添加其余类路径。所以path里面仅仅只有一个jar包,urls也只会有一个。但其实我这个jar引用了很多其余的第三方jar,这些都定义在了启动jar中的清单文件MANIFEST.MF中的Class-Path这个属性里面了。所以启动的时候需要加载很多类,但是urls里面根本没有。所以它会先取出一个,然后解析清单文件,找到依赖的所有jar(有序),然后再反向压入栈中。这个先解释这么多,需要结合其它属性来解释。 - ArrayList
loaders :有序列表,这个的长度和path,urls没有直接关联。维护了一组类库加载器。这个加载器是动态生成的,初始化完成以后,是空的。只有触发类加载这个动作并且在当前所有类库加载器loaders没有加载到某个类以后以及urls里面还有未加载的类库(换言之,如果当前的类库加载器满足不了,就会尝试去生成新的加载器以满足需求),然后才会去生成新的类库加载器。 - Loader类,就是类库加载器。这个加载器负责把一个类从自己负责的类库里面找出来(返回一个资源描述对象)。一个加载器负责一个类库,类库也比较好理解,就是很多类的一个集合。Loader有两个子类:FileLoader和JarLoader。也就是jar包以及文件夹的集合。我们常见的类库就是这两种了。
- HashMap
重点属性就是上述这些。
接下来看一下类URLClassPath的方法getResource方法:
public Resource getResource(String var1, boolean var2) {
if (DEBUG) {
System.err.println("URLClassPath.getResource(\"" + var1 + "\")");
}
int[] var4 = this.getLookupCache(var1);
URLClassPath.Loader var3;
for(int var5 = 0; (var3 = this.getNextLoader(var4, var5)) != null; ++var5) {
Resource var6 = var3.getResource(var1, var2);
if (var6 != null) {
return var6;
}
}
return null;
}
里面主要有三步,前面有关于调试以及缓存的可以忽略(我在调试的时候没有发现使用缓存相关的)。
- 循环找到下一个类库加载器。
- 使用类库加载器加载这个类。
- 如果加载到了,结束。否则结束。
加载每一个类(非jdk)都会执行上述步骤。
稍微注意一下,从这个方法开始,基本都会由两个参数,一个字符串,一个布尔。在类加载的过程中,这个布尔永远是false。而在加载资源的文件的时候,是true。代表着是否解析的意思。
第一步就是去寻找或者生产新的Loader,先看一下这个,方法就是getNextLoader(int[] var1, int var2):
private synchronized URLClassPath.Loader getNextLoader(int[] var1, int var2) {
if (this.closed) {
return null;
} else if (var1 != null) {
if (var2 < var1.length) {
URLClassPath.Loader var3 = (URLClassPath.Loader)this.loaders.get(var1[var2]);
if (DEBUG_LOOKUP_CACHE) {
System.out.println("HASCACHE: Loading from : " + var1[var2] + " = " + var3.getBaseURL());
}
return var3;
} else {
return null;
}
} else {
return this.getLoader(var2);
}
}
其实前面是关于缓存的,如果没有的话,就直接最后一行了, return this.getLoader(var2),下面是重点内容了,而且这个方法是加了同步锁的,因为方法内部有可能会更新好几个关键属性,需要加锁。
private synchronized URLClassPath.Loader getLoader(int var1) {
if (this.closed) {
return null;
} else {
//外层循环的时候,索引值一直在变大,并没有上限,所以会满足下面这个条件
//而且下面这个方法块里面也是我前文提到的,类库加载器是动态生成的。
//这里为什么是while呢,应该用if吧。因为待处理类库中可能有重复值,取出来重复的就直接略过了。所以还需要进一步遍历urls。
while(this.loaders.size() < var1 + 1) {
//当前循环的次数已经超过了加载器的数目的时候就进来。
Stack var3 = this.urls;
URL var2;
synchronized(this.urls) {
//前提是urls里面还有未处理的类库。
//所以urls,代表的就是未处理的类库。
if (this.urls.empty()) {
return null;
}
//取出来一个
var2 = (URL)this.urls.pop();
}
//把一个资源描述符转换成一个字符串,详情可以看一下这个类。里面处理了有关协议以及端口。
String var9 = URLUtil.urlNoFragString(var2);
//判断了一下lmap里面有没有存在var9了。这可能是这个map唯一的作用了。
//正常加载的情况下,这边会有重复的吗?还真的会有很多。我在调试的是,发现urls里面有很多重复的类库。
//当超过两个类库,依赖了同一个类库的时候,加载的时候,会重复把被依赖的类库压入栈中。这样判断一下,也省去了不少时间。
if (!this.lmap.containsKey(var9)) {
URLClassPath.Loader var4;
try {
//通过url生成类库加载器,方法内部就是根据协议去生成jar加载器或文件加载器或他们的父类加载器(这个用于处理http等协议)。
var4 = this.getLoader(var2);
//这一步是获取当前这个类库(var2)所依赖的其它类库。当然仅限是jar包的情况。前文在说urls变量的时候提到过,
//urls的值和path不一定相同。具体的获取方式就是寻找清单文件,找到Class-Path的变量值。
//这里面最后一步,因为Class-Path一般都是相对路径,它这边也稍微处理了一下。返回的url集合都是绝对路径,方法是parseClassPath(URL var1, String var2)。
URL[] var5 = var4.getClassPath();
//拿出来以后,反向压进栈中。
if (var5 != null) {
this.push(var5);
}
} catch (IOException var6) {
continue;
} catch (SecurityException var7) {
if (DEBUG) {
System.err.println("Failed to access " + var2 + ", " + var7);
}
continue;
}
//然后后面更新一下类库加载器。
this.validateLookupCache(this.loaders.size(), var9);
this.loaders.add(var4);
this.lmap.put(var9, var4);
}
}
if (DEBUG_LOOKUP_CACHE) {
System.out.println("NOCACHE: Loading from : " + var1);
}
//最后按照索引返回一个类库加载器。
return (URLClassPath.Loader)this.loaders.get(var1);
}
上述就是构造生成类库加载器的过程,我们接下来梳理一下完整的流程,如下:
- 初始化,提供应用程序的所有ClassPath,并且同时反向压入待处理类库栈中,此时一个类库加载器都没有。
- 类加载,需要使用类库加载器来记载器。但是发现已有的并没有加载器到这个类,并且待处理类库有。所以从栈顶取出,因为之前是反向压栈的,所以取出来的就是原ClassPath中的第一个。取出来的类库,如果已经处理过了,就过滤掉。接下来如果本身还有依赖的类库,再把依赖的项反向压入栈中。同时生成这个类库的加载器。
应用程序的ClassPath是从哪里来的呢?稍微看一下应用程序的类记载器的生成方法就比较清楚了:
public static ClassLoader getAppClassLoader(final ClassLoader var0) throws IOException {
final String var1 = System.getProperty("java.class.path");
final File[] var2 = var1 == null ? new File[0] : Launcher.getClassPath(var1);
return (ClassLoader)AccessController.doPrivileged(new PrivilegedAction() {
public Launcher.AppClassLoader run() {
URL[] var1x = var1 == null ? new URL[0] : Launcher.pathToURLs(var2);
return new Launcher.AppClassLoader(var1x, var0);
}
});
}
类库加载器的顺序是这么保证的?
刚才一直在说如果获取加载器,但是并没有太强调顺序。但顺序其实是最重要的。URLClassPath这个类维护了一组有顺序的类库加载器,而且我们在加载任何一个类的时候,都是严格按照这个顺序去遍历加载的。loaders每次添加的都是从待处理类库中取出来的,其实刚才强调有关顺序的只有一个词:反向压栈。包括为什么待处理类库要使用堆栈这个数据结构,就是来保证了顺序。举一个例子来说明一下,一个工程依赖了A,B,C3个jar包。同时A依赖了A1和D,B依赖了B1和B2,C依赖了D和C1。图示如下:

那么我们理想中的类加载的顺序应该是:A,A1,D,B,B1,B2,C,C1。
看一下是如何做到这一点的,
第一步初始化的时候,ClassPath里面是A,B,C,所以此时堆栈的结构如下:
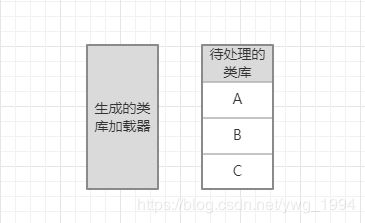
现在还没有生成任何新的类库加载器。
假设我们此时需要加载C1里面的某个类了,这样一次性就能生成所有的类库加载器。
此时,还没有类库加载器,所以会取出A,同时找到A所依赖的A1,和D。同时反向压入栈中:
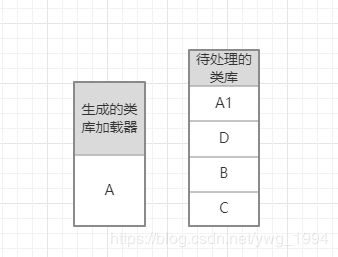
接下来生成A1和D的类库加载器:
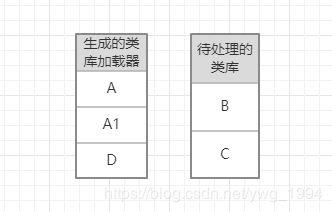
同理处理B依赖的B1和B2,
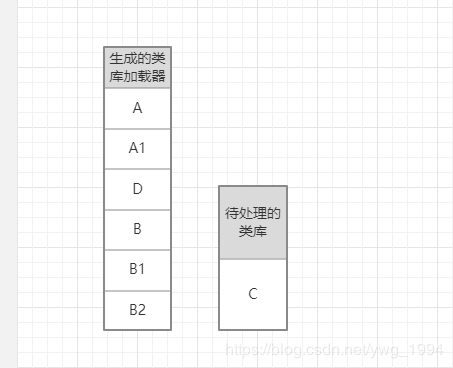
处理C的时候,稍微不一样的就是,D已经处理过了,所以不会重复生成类库加载器了,最终就是:
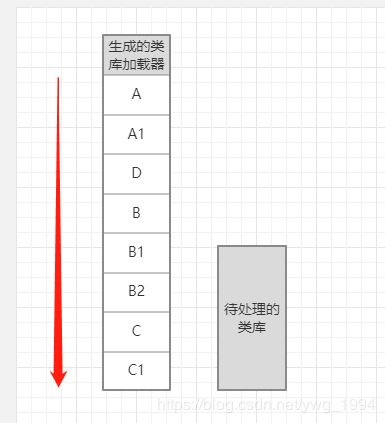
最终生成一个有序的类库加载器列表,加载每一个类的时候都会用这个顺序去加载。
这边使用堆栈处理的逻辑,确实可以给我们在开发中起到一些不错的借鉴作用。
ClassPath的顺序是怎么来的?
我们现在的工程基本上都是maven工程,如果是非web项目(或者是main方法启动的工程,包括spring-boot),我们在开发工具中启动,开发工具会自动给我们填充ClassPath,然后在启动工程。它是怎么填充的呢?
首先肯定是当前工程目录的target/classes目录作为第一个ClassPath,这是毋容置疑的。其余的会按照我们在pom文件中定义的三方依赖顺序来添加,这下知道pom文件中的依赖顺序的重要性了吧。这里有两种情况,一种是模块依赖,这种也比较常见,开发工具会把依赖的模块路径下的target/classes这个目录放进classPath,另外一种据说jar包依赖了,添加的就是本地仓库的jar包路径。
如果是一些容器的话,比如tomcat,先不考虑它本身的启动逻辑与类加载器了。单说我们其中一个web工程,它肯定是优先会把我们工程下的classes目录放进属于我们应用的类加载器中的ClassPath的第一个,不过它还会把tomcat/lib下的所有jar优先于我们工程本身依赖的jar加载(这点是我猜的,应该是这样的,不过不一定是放进classPath,有可能是由父类加载器来加载的。)。OSGI也是一样,对于每一个bundle,都会有一个类加载器,不过Bundle依赖的其它bundle的类,会使用那个依赖类所属于的bundle的类加载器去加载。
工具或者容器启动,我们相对来说是比较省事的,但是有的时候,我们需要在命令行通过java命令来启动一个类。可以指定某个类来启动,但是同时要指定所有的依赖项。也可以通过jar包启动,这种情况下,不需要添加ClassPath,java会把启动jar唯一的一个放进类路径中。jar包的清单文件里面需要指定main方法以及所依赖的类。个人比较推荐后者,因为一些打包插件用上的话,还是非常方便的。自己不用处理太多有关类路径的事情。
我们重写的类,为啥能覆盖jar包里面的类呢?
加载顺序很重要,在前面的就一定会优先加载。
刚才其实说了加载顺序,一般情况下,我们自己写的工程,一定是在最前面,所以肯定能加载到呀,毫无疑问。
但是一些特殊的场景下,比如tomcat,你想重写tomcat/lib下的一些类,在自己的工程里面写了,估计没有什么卵用。不过这种需求应该会小一些吧。
还有一种是多模块的工程,A,B 2个模块,A是启动模块,B重写了Cjar中的方法,A依赖了B。这种情况下,肯定会加载到我们重写的类。但是如果误配置的情况下,在A中同时引用了C,而且C的顺序比B靠前,那不好意思。加载不到我们重写的类了。当然,这种几乎不可能发生。A依赖B,B依赖C。其实A也依赖了C,所以没有必要再去直接依赖了。举这个例子,就是想表明一下,启动的那个工程所依赖的类库的顺序很关键,因为肯定会以启动工程为主。
加载配置文件的几种常见方式
最常见的无非就是下面几行代码了:
Thread.currentThread().getContextClassLoader().getResource("");//或者是getResourceAsStream,可能这个也用得多一些。
this.getClass().getResource("/");
this.getClass().getResource("");
其实就这3种。
第一种关于类加载器加载资源,明说了,这个和类加载的过程是完全一模一样的。
如果是一个空字符串的话,它返回的是所有的类库里面第一个文件夹类库的路径,这种用法(空字符串)感觉没有什么意义,虽然它有时候能返回到我们期待的结果。但大多数情况下都是侥幸吧。
那如果是一个配置文件呢?它会按照顺序去找,找到第一个或者找不到。如果有同名的,它只会找到第一个,寻找顺序的话,上面有讲述。它会找文件夹下,也会寻找jar包里面,因此,我们的配置文件,放文件夹或者jar包里面都可以,但最好只放一个就行了。
第二个是类去加载资源,注意这种是以"/开头的",我们看一下这块的源码:
public java.net.URL getResource(String name) {
//解析了一下名字,关键就在这里
name = resolveName(name);
ClassLoader cl = getClassLoader0();
if (cl==null) {
// A system class.
return ClassLoader.getSystemResource(name);
}
return cl.getResource(name);
}
private String resolveName(String name) {
if (name == null) {
return name;
}
//这边重点区分了一下是不是/开头的
if (!name.startsWith("/")) {
//不是的情况下,自动带上了这个类的包路径,并转换成文件目录形式,后面再拼上资源名称
Class c = this;
while (c.isArray()) {
c = c.getComponentType();
}
String baseName = c.getName();
int index = baseName.lastIndexOf('.');
if (index != -1) {
name = baseName.substring(0, index).replace('.', '/')
+"/"+name;
}
} else {
//如果是/开头的,直接把那个给去掉了。
name = name.substring(1);
}
return name;
}
因此,"/"就是一个标记,
如果有的话,就认为是绝对路径(相对于非“/”开头),和类加载器加载过程完全一样。所以下面两种是等同的:
Thread.currentThread().getContextClassLoader().getResource("a.txt");
this.getClass().getResource("/a.txt");
还是就是第三种,它自动拼接了类的包名,所以就是找的和当前类的同路径的资源文件了。不过最后都是走的类加载器的。
类库加载器是如何加载类或者资源的
上面讲了类库加载器是这么来的,顺序是怎么样的,但是没有说具体怎么加载和判断的。篇幅有限,实在不想详细写了,具体的话可以看一下源码吧,都在sun.misc.URLClassPath这个类里面。但是也可以两句话说一下
文件类库加载器:判断一下这个目录下有没有这个类,有的话,资源描述对象。
jar类库加载器:判断一下jar里面有没有这个JarEntity,有的话,也返回一个资源描述对象。
资源和类都可以加载。
总结
篇幅很长,不过就只说了一件事情:
通过一个类的全限定名获得此类的统一资源定位符(URL)。
不过也解释了一下平时开发中自己的一些疑惑。看底层代码收获还是蛮大的,一方面可以了解到处理过程,方便自己在平时定位问题,另一方面也能够借鉴一些处理的思想。
不过要有选择的看源码,至于类加载的其它过程的源码,我觉得暂时就不需要看了,性价比一定不高。