JVM垃圾回收算法和回收器
一、垃圾回收算法:
1、引用计数法
引用计数法就是对于一个对象A,只要有任何一个对象引用了A,则A的计数器就加1,当引用失效时就减1。只要对象A的计数器数值为0,将会被回收。
注意:无法处理循环引用的问题,引用计数法不适合JVM的垃圾回收
2、标记--清除算法(Mark--Sweep)
标记清除算法就是先通过根节点标记所有可到达的对象,然后清除所有不可达的对象,完成垃圾回收,此算法最大的问题就是可能产生空间碎片,如下图所示:

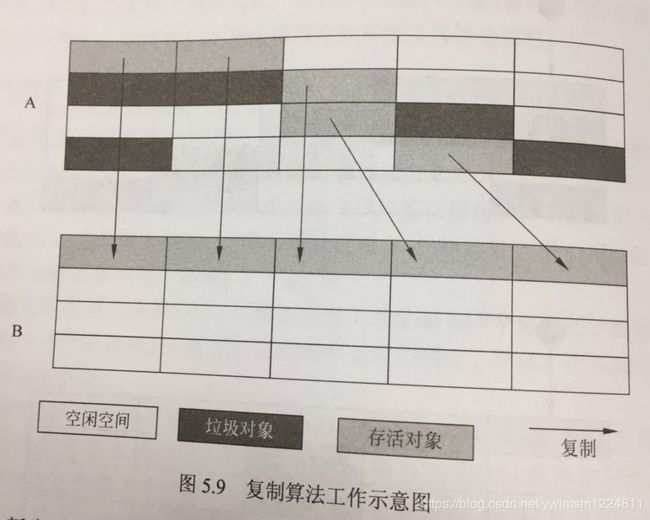
3、复制算法
与标记清除算法相比,复制算法是一种相对高效的回收方法,其思想是将原有的内存分为大小相等的两块,每次只使用一块,垃圾回收时将正在使用的内存中的存活对象复制到未使用的内存中,之后清除正在使用的内存块的所有对象,交换两个内存的角色,完成垃圾回收。在 Java 的新生代串行垃圾回收器中,使用了复制算法,s0(from) 和 s1(to) 大小相等,可进行角色互换。
复制算法回收后的内存空间是连续没有空间碎片的,但是当存活对象比较少时才能发挥高效,因此该算法适用于新生代,新生代的垃圾对象高于存活对象,复制效果比较好。该算法如下图所示:
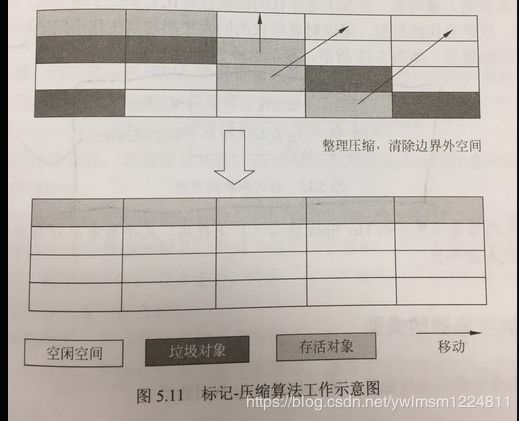
4、标记--压缩(整理)算法(Mark--Compact)
标记--压缩算法是一种老年代的回收算法,它在标记--清除算法的基础上做了一些优化。首先从根节点开始标记所有可达对象,然后将存活的对象压缩到内存的一端,清理边界外的所有空间,这种做法避免了碎片的产生,又不需要两块内存空间,因此性价比较高。该算法如下图所示:
5、增量算法
在垃圾回收的过程中,应用软件将处于一种 Stop the World 的状态,所有应用程序的线程都会挂起,暂停一切工作,等待垃圾回收的完成。
增量算法的思想是让垃圾收集线程和应用程序线程交替执行,而不是一次性进行垃圾回收,这样产生的问题是由于线程切换和上下文转换的消耗,会使得垃圾回收的总体成本上升,造成系统吞吐量的下降。
6、分代(Generational Collecting)
分代思想就是将内存区间根据对象的特点分成几块,根据每块内存区间的特点,使用不同的回收算法。例如:新生代会选择使用复制算法,老年代会选择标记--压缩算法,以提高垃圾回收效率,如下图所示:

二、垃圾收集器
1、新生代串行收集器
它有两个特点:第一、它仅仅使用单线程进行垃圾回收;第二、它是独占式的垃圾回收。新生代串行收集器使用复制算法,使用 -XX:+UseSerialGC 参数指定使用新生代串行收集器和老年代串行收集器,当 JVM 在Client 模式下运行时,它是默认的垃圾收集器。
2、老年代串行收集器
老年代串行收集器使用标记--压缩算法,它回收通常比新生代回收需要更长的时间。但是它可以和多种新生代回收器配合使用,同时也可作为 CMS 回收器的备用回收器,使用以下参数设置:
-XX:+UseSerialGC:新生代、老年代都使用串行收集器
-XX:+UseParNewGC:新生代使用并行收集器、老年代使用串行收集器
-XX:+UseParallelGC:新生代使用并行回收收集器,老年代使用串行收集器
3、并行收集器
并行收集器是工作在新生代的垃圾收集器,他只是简单地将串行收集器多线程化。由于使用多线程进行垃圾回收,因此在并发能力较强的CPU上,它产生的停顿时间要短于串行收集器,但是在单CPU或者并发能力较弱的系统中,由于多线程的压力,它的性能反而比串行收集器差,使用以下参数设置并行收集器:
-XX:+UseParNewGC:新生代使用并行收集器,老年代使用串行收集器
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用 CMS
4、新生代并行回收收集器(Parallel Scavenge)
新生代并行回收收集器也是使用的复制算法,表面上看它和并行收集器一样,都是多线程的,但是它有一个重要的特点就是:关注系统的吞吐量。使用以下参数设置:
-XX:+UseParallelGC:新生代使用并行回收收集器,老年代使用串行收集器
-XX:+UseParallelOldGc:新生代和老年代都是用并行回收收集器
并行回收收集器提供了两个重要的参数控制系统的吞吐量:
-XX:MaxGCPauseMillis:最大垃圾收集停顿时间,这个值越小将会导致 JVM 使用一个较小的堆(小堆比大堆回收时间快),使垃圾回收变得频繁,降低系统的吞吐量
-XX:GCTimeRatio:设置吞吐量的大小,默认情况下它取值为 99,假设-XX:GCTimeRatio 的值为 n,则垃圾回收时间为 time = 1 / (1 + n)
并行回收收集器与并行收集器还有一个重要区别,它支持一种自适应的 GC 调节策略。使用下面的参数设置:
-XX:+UseAdaptiveSizePolicy:自适应GC策略
这种模式下,新生代的大小,eden 和 survivor 的比例,晋升老年代的对象年龄等参数都会被自动调整,已达到在堆大小、吞吐量和停顿时间之间的平衡点。在手动调优比较难的场合下,可以选择使用此模式,仅需指定 JVM 的最大堆、目标的吞吐量(GCTimeRatio)和停顿时间(MaxGCPauseMillis),让 JVM 自己完成调优工作。
5、老年代并行回收收集器
它使用标记--压缩算法,和新生代并行回收收集器一样关注系统吞吐量,使用以下参数设置:
-XX:+UseParallelOldGc:新生代和老年代都是用并行回收收集器
-XX:ParallelGCThreads:设置垃圾回收时的线程数量
6、CMS(Concurrent Mark Sweep) 收集器
CMS 收集器只要关注于系统停顿时间,只用于老年代GC垃圾回收,CMS 是 Concurrent Mark Sweep 的缩写,意为并发标记清除,它使用的是标记--清除算法,同时它又是一个多线程并行回收的垃圾收集器。
CMS 工作时的主要步骤有:初始化标记、并发标记、重新标记、并发清除和并发重置,其中初始化标记和重新标记是独占系统资源的,而并发标记、并发清除和并发重置是可以和用户线程一起执行的。因此,从整体上来说,它不是独占式的,它可以在应用程序运行过程中进行垃圾回收,原理如下图所示:
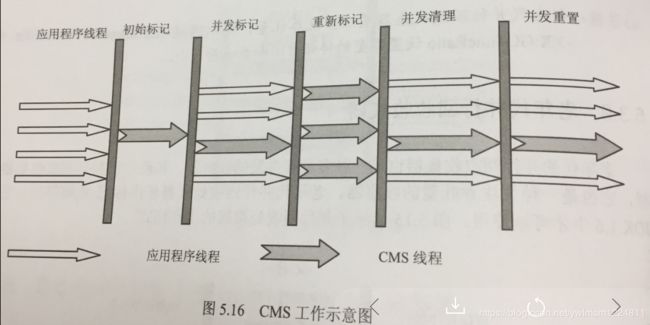
CMS 的 初始化标记、并发标记和重新标记都是为了标记出需要回收的对象,并发清理就是并发清理后重新初始化 CMS 数据结构和数据,为下一次回收做准备。CMS 收集器不会等待堆内存饱和时才进行垃圾回收,而是当内存使用率达到某一阀值时才进行回收,以确保应用程序在 CMS 回收时依然有足够的空间支持应用程序运行。回收阀值可以使用下面参数设置:
-XX:CMSInitiatingOccupancyFraction:指定当老年代空间使用率达到多少时,进行一次 CMS 垃圾回收,默认值是 68
-XX:ParallelCMSThreads:设定 CMS 的线程数量
如果应用程序的内存使用率增长很快,在 CMS 的执行过程中,已经出现了内存不足的情况,此时 CMS 回收就会失败,JVM 自动启动老年代串行收集器进行垃圾回收。如果内存增加缓慢,则可以设置 -XX:CMSInitiatingOccupancyFraction 一个稍微大的值,有效降低 CMS 的回收次数(频率),反之,内存增长过快,则应该降低这个阀值,以避免频繁触发老年代串行收集器。
CMS 是一个基于标记--清除算法的回收器,此算法会造成大量的内存碎片,为了解决这个问题,CMS收集器提供了几个内存压缩整理的参数,参数如下:
-XX:+UseCMSCompactAtFullCollection:CMS回收后进行一次内存碎片整理,内存碎片的整理不是并发进行的
-XX:CMSFullGCsBeforeCompaction:设定进行多少次 CMS 回收后,进行一次内存压缩
G1 收集器(Garbage First)
G1 收集器是目前最新的垃圾回收器,与 CMS 收集器相比,G1 收集器是基于标记--压缩算法的,它不会产生内存碎片,也木有必要在回收后进行一次独占式的碎片整理工作。它可以精确的控制停顿时间,可以让开发人员指定在 M 的时间段内,垃圾回收的时间不超过 N,参数设置如下:
-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC
设置 G1 回收器的目标停顿时间:
-XX:MaxGCPauseMillis = 50
-XX:GCPauseIntervalMillis = 200
以上参数含义就是在 200ms 内,停顿时间不超过 50ms,这两个参数是 G1 回收器的目标,并不能保证执行它们