ceph一些基础概念的简介
最近因为整理文档,发现一些很久以前写的关于ceph基础介绍的ppt,为了防止资料丢失,打算把搬到这里留作备份。
现在线上环境是openstack+ceph的结构,ceph直接连接在openstack中块存储模块cinder的后端。
什么是Ceph
Ceph架构
Ceph设计
RADOS
注:一个集群可包含数千个存储节点,至少需要二个OSD才能数据复制。
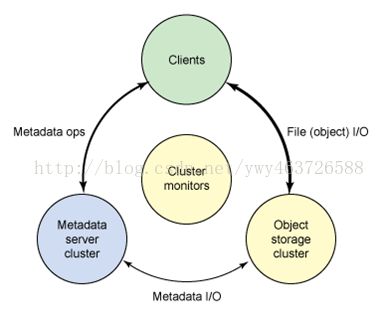
Ceph Filesystem
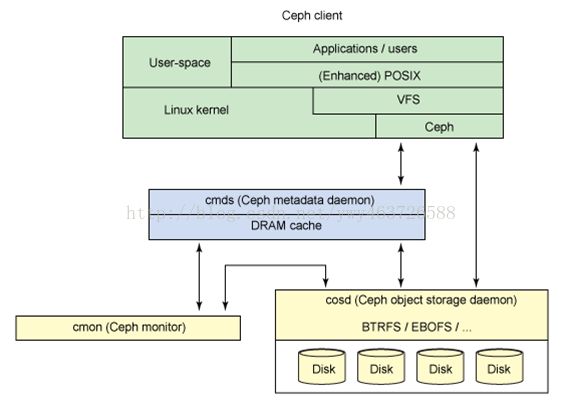
Ceph Block Device
Ceph Object Storage
对象存储系统(Object-Based StorageSystem)是综合了NAS(Network Storage Technologies)和SAN(Storage AreaNetwork)的优点,同时具有SAN的高速直接访问和NAS的数据共享等优势,提供了高可靠性、跨平台性以及安全的数据共享的存储体系结构。
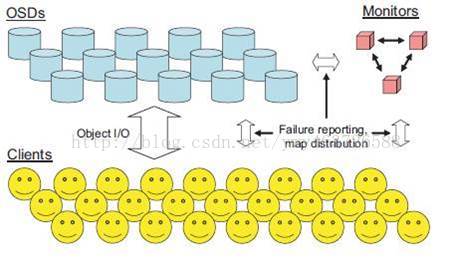
下面具体介绍一下RADOS(Reliable,Autonomic Distributed Object Store):
架构简介,由两个部分组成:
由数目可变的大规模OSDs(Object Storage Devices)组成的机群,负责存储所有的Objects数据.
由少量Monitors组成的强耦合、小规模机群,负责管理Cluster Map,其中Cluster Map是整个RADOS系统的关键数据结构,管理机群中的所有成员、关系、属性等信息以及数据的分发。
Cluster Map
管理cluster的核心数据结构,指定了OSDs和数据分布信息,monitor上存有最新副本,依靠epoch增加来维护及时更新增量信息
1.The Monitor Map
cluster fsid, the position, name address and port of each monitor
2.The OSD Map
cluster fsid,a list of pools, replica sizes, PG numbers, a list of OSDs and their status
3.The PG Map:
PG version, its time stamp, the last OSD map epoch, the full ratios, and details on each placement group such as the PG ID,the Up Set, the Acting Set, the state of the PG (e.g., active + clean), and data usage statistics for each pool.
4.The CRUSH Map
a list of storage devices, the failure domain hierarchy (e.g., device, host, rack, row, room, etc.), and rules for traversing the hierarchy when storing data
5.The MDS Map
MDS map epoch,the pool for storing metadata, a list of metadata servers, and which metadata servers are up and in
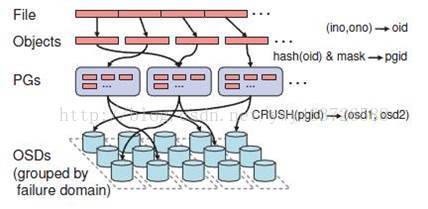
数据存放:(两层映射)
1.Object到PG的映射。PG (Placement Group)是Objects的逻辑集合。相同PG里的Object会被系统分发到相同的OSDs集合中。由Object的名称通过Hash算法得到的结果结合其他一些修正参数可以得到Object所对应的PG。
2.RADOS系统根据根据Cluster Map将PGs分配到相应的OSDs。这组OSDs正是PG中的Objects数据的存储位置。RADOS采用CRUSH算法实现了一种稳定、伪随机的hash算法。CRUSH实现了平衡的和与容量相关的数据分配策略。CRUSH得到的一组OSDs还不是最终的数据存储目标,需要经过初步的filter,因为对于大规模的分布式机群,宕机等原因使得部分节点可能失效,filter就是为过滤这些节点,如果过滤后存储目标不能满足使用则阻塞当前操作。
关于Pools
是一个存储对象的逻辑分区概念
所有权/访问对象,对象副本的数目,PG数目,CRUSH规则集的使用
以上后三项决定ceph最后如何存储数据
计算PG的ID
1.Client输入pool ID和对象ID(如pool=‘liverpool’,object-id=‘john’)
2.CRUSH获得对象ID并对其hash
3.CRUSH计算OSD个数hash取模获得PG的ID(如0x58)
4.CRUSH获得已命名pool的ID(如liverpool=4)
5.CRUSH预先考虑到pool ID相同的PG ID(如4.0x58)
Device State

peer和set
peer:属于同一个PG,彼此检查心跳,数据同步
set:Acting set(PG内所有osd属于Acting set),Up set(PG内up&in的osd)
map传播
所有消息传播都有一个epoch
client端:
首次进入去找monitor要最新副本
存取时找OSD对比epoch
OSD端:
peers之间保持心跳
只保证两个OSD之间同步
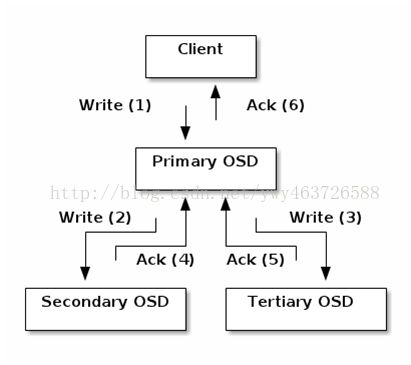
数据复制
读文件通过一个OSD
主OSD
写文件通过多个OSD复制
Client把对象写进一个确定的PG组中的主OSD
主OSD利用CRUSH map用来确定二级OSDs,复制的对象放入其中。
对象存储成功后进行响应client。
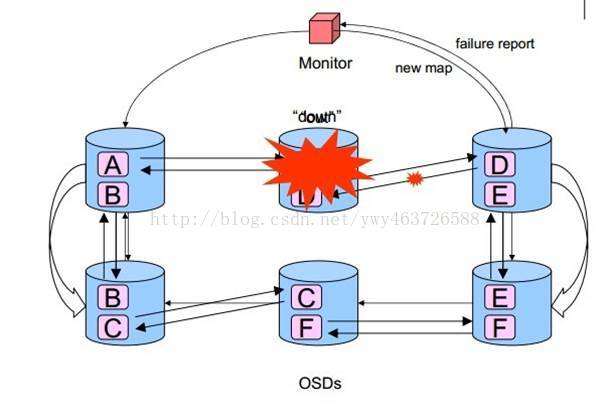
错误检测和恢复
错误检测:
利用心跳
上报monitor
更新map
错误恢复
主osd主持恢复工作
若主osd挂掉,二级osd选择一个顶上
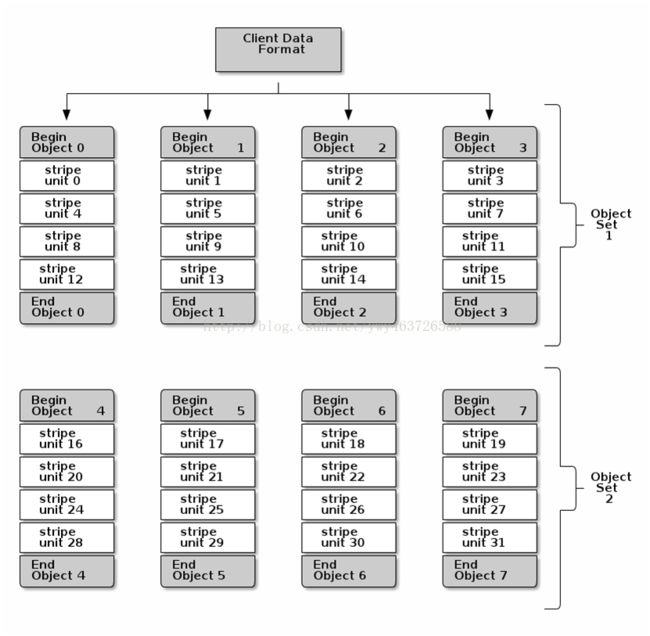
数据条带化
由于存储设备吞吐量的限制,影响性能和可伸缩性。
跨多个存储设备的连续块条带化存储信息,以提高吞吐量和性能
Ceph条带化相似于RAID0
注意:ceph条带化属于client端,不在RADOS范畴
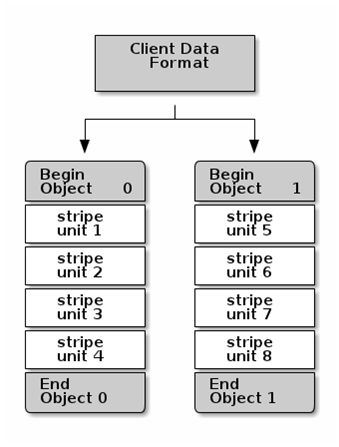
注意:条带化是独立于对象副本的。由于CRUSH副本对象跨越OSDs,所以条带自动的被复制。
条带化参数
Object Size:
足够大可以容纳条带单元,必须容纳一个或者多个条带单元。(如2MB,4MB)
Stripe Width:
一个条带单元的大小,除了最后一个,其他必须一样大(如64K)
Stripe Count:
连续写入一系列的对象的个数(如4个)
注意:
参数一旦设置不可改变,提前做好性能测试