linux无名管道和有名管道
1)无名管道:管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道;只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程)。
单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。(有点像队列哈)
#include
int pipe(int fd[2]) 该函数创建的管道的两端处于一个进程中间,在实际应用中没有太大意义,因此,一个进程在由 pipe()创建管道后,一般再fork一个子进程,然后通过管道实现父子进程间的通信(因此也不难推出,只要两个进程中存在亲缘关系,这里的亲缘关系指的是具有共同的祖先,都可以采用管道方式来进行通信)。
向管道中写入数据时,linux将不保证写入的原子性,管道缓冲区一有空闲区域,写进程就会试图向管道写入数据。如果读进程不读走管道缓冲区中的数据,那么写操作将一直阻塞。
注:只有在管道的读端存在时,向管道中写入数据才有意义。否则,向管道中写入数据的进程将收到内核传来的SIFPIPE信号,应用程序可以处理该信号,也可以忽略(默认动作则是应用程序终止)。
2)有名管道:不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存在于文件系统中。这样,即使与FIFO的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过FIFO相互通信(能够访问该路径的进程以及FIFO的创建进程之间),因此,通过FIFO不相关的进程也能交换数据。值得注意的是,FIFO严格遵循先进先出(first in first out),对管道及FIFO的读总是从开始处返回数据,对它们的写则把数据添加到末尾。它们不支持诸如lseek()等文件定位操作。
有名管道的创建
#include
#include
int mkfifo(const char * pathname, mode_t mode) 该函数的第一个参数是一个普通的路径名,也就是创建后FIFO的名字。第二个参数与打开普通文件的open()函数中的mode参数相同。如果mkfifo的第一个参数是一个已经存在的路径名时,会返回EEXIST错误,所以一般典型的调用代码首先会检查是否返回该错误,如果确实返回该错误,那么只要调用打开FIFO的函数就可以了。一般文件的I/O函数都可以用于FIFO,如close、read、write等等
3)无名管道由一个在基本文件系统存储设备上的INODE,一个与其相连的内存INODE,两个打开文件控制块(分别对应管道的信息发送端和信息接收端)及其所属进程的描述信息来标识,在系统执行PIPE(P)命令行之后生成。并在P[0]中返回管道的读通道打开文件描述等,在P[1]中返回管道的写通道打开文件描述符。从结构上看,无名管道没有文件路径名,不占用文件目录项,因此文件目录结构中的链表不适用于这种文件,它只是存在于打开文件结构中的一个临时文件,随其所依附的进程的生存而生存,当进程终止时,无名管道也随之消亡。
送入管道的信息一旦被读进程取用就从管道中消失了,读写操作之间符合先进先出的队列原则。
管道文件是进程间通信的工具,为了尽量少的占用系统存储资源,一般系统均将其限制为最大长度为4096(PIPSIZ)字节的小型文件。当欲写入的消息超过4096字节时,就产生了读、写进程之间的同步问题。首先写操作查找PIPE文件中当前指针的偏移量F-OFFSET,然后从此位置开始尽量写入信息,当长度达到4096字节时,系统控制写进程进入睡眠状态,一直等待读进程取走全部信息时,文件长度指针置0,写进程才被唤醒继续工作。
为防止多个进程同时读写一个管道文件而产生混乱,在管道文件的INODE标志字I-FLAY项中设置了ILOCK标志项,以设置软件锁的方式实现多进程间对管道文件的互斥使用。
无名管道存在着如下两个严重的缺点。
第一,无名管道只能用于连接具有共同祖先的进程。
第二,无名管道是依附进程而临时存在的。所以后来推出了一种无名管道的变种-有名管道,它常被称为FIFO。有名管道除继承了无名管道的所有特性优点之外,还屏弃了无名管道的两个缺点。
首先,FIFO是一种永久性的机构,它具有普通的UNIX系统文件名。在系统下可利用MKNOD命令建立永久的管道,除非刻意删除它,否则它将一直保持在系统中。
其次,正是由于有名管道以“文件名”来标识,所以只要事先约定某一特定文件名,那样所有知道该约定的服务进程,不论它们之间是否有亲属关系,都可以便利地利用管道进行通信。
通过下面的命令可以创建一个命名管道:
/etc/mknod pipe_name p 其中“pipe_name”是要创建的命名管道的名字,参数p必须出现在命名管道名字之后。
命名管道文件被创建后,一些进程就可以不断地将信息写入命名管道文件里,而另一些进程也可以不断地从命名管道文件中读取信息。对命名管道文件的读写操作是可以同时进行的。下面的例子显示命名管道的工作过程。
进程A、B、C中运行的程序只是一条简单的echo命令,它们不断地把信息写入到命名管道文件/tmp/pipe1中。与此同时,程序中的“read msg”命令不断地从命名管道文件/tmp/pipe1中读取这些信息,从而实现这些进程间的信息交换。
程序执行时,首先创建命名管道文件,此时程序处于等待状态,直到A、B、C进程中某一个进程往命名管道中写入信息时,程序才继续往下执行。使用rm命令可以删除命名管道文件从而清除已设置的 命名管道。
下面是一个用于记录考勤的例子:
在主机上运行的程序/tmp/text产生命名管道/tmp/pipe1,并不断地从命名管道中读取信息送屏幕上显示。
/tmp/text程序:
if [ ! -p /tmp/pipe1 ]
then
/etc/mknode /tmp/pipe1 p
fi
while :
do
read msg
if [ “$msg" = “" ]
then
continue
else
echo “$msg"
fi
done < /tmp/pipe1在终端上运行的是雇员签到程序/tmp/text1。每个雇员在任何一台终端上键入自己的名字或代码,程序/tmp/text1将把这个名字连同当时的签到时间送入命名管道。
/tmp/text1程序:
tty=‘who am I | awk ‘{print $2}’’
while :
do
echo “Enter your name: \c" > /dev/$tty
read name
today=‘date’
echo “$name\t$today"
done > /tmp/pipe1当雇员从终端上输入自己的姓名后,运行/tmp/text程序的主机将显示类似下面的结果:
wang Thu Jan 28 09:29:26 BTJ 1999
he Thu Jan 28 09:29:26 BTJ 1999
cheng Thu Jan 28 09:30:26 BTJ 1999
zhang Thu Jan 28 09:31:26 BTJ 1999named pipes(命名管道)管道具有很好的使用灵活性,表现在:
1) 既可用于本地,又可用于网络。
2) 可以通过它的名称而被引用。
3) 支持多客户机连接。
4) 支持双向通信。
5) 支持异步重叠I/O操作。
不过,当前只有Windows NT,UNIX支持服务端的命名管道技术,win95/97/98等不支持。SQL Server等数据库就有named pipes的连接方式。
(资料来源于互联网)
========================================================================================================
===========================================================================================================
管道:
管道是进程间通信的主要手段之一。一个管道实际上就是个只存在于内存中的文件,对这个文件的操作要通过两个已经打开文件进行,它们分别代表管道的两端。管道是一种特殊的文件,它不属于某一种文件系统,而是一种独立的文件系统,有其自己的数据结构。根据管道的适用范围将其分为:无名管道和命名管道。
●无名管道
主要用于父进程与子进程之间,或者两个兄弟进程之间。在linux系统中可以通过系统调用建立起一个单向的通信管道,且这种关系只能由父进程来建立。因此,每个管道都是单向的,当需要双向通信时就需要建立起两个管道。管道两端的进程均将该管道看做一个文件,一个进程负责往管道中写内容,而另一个从管道中读取。这种传输遵循“先入先出”(FIFO)的规则。
●命名管道
命名管道是为了解决无名管道只能用于近亲进程之间通信的缺陷而设计的。命名管道是建立在实际的磁盘介质或文件系统(而不是只存在于内存中)上有自己名字的文件,任何进程可以在任何时间通过文件名或路径名与该文件建立联系。为了实现命名管道,引入了一种新的文件类型——FIFO文件(遵循先进先出的原则)。实现一个命名管道实际上就是实现一个FIFO文件。命名管道一旦建立,之后它的读、写以及关闭操作都与普通管道完全相同。虽然FIFO文件的inode节点在磁盘上,但是仅是一个节点而已,文件的数据还是存在于内存缓冲页面中,和普通管道相同。
实现机制:
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大一般为4K大小,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
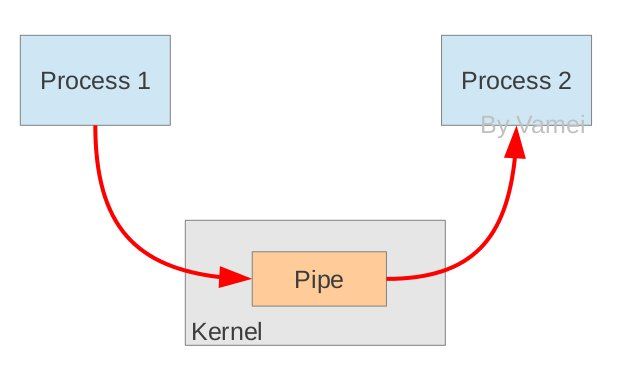
从原理上,管道利用fork机制建立,从而让两个进程可以连接到同一个PIPE上。最开始的时候,上面的两个箭头都连接在同一个进程Process 1上(连接在Process 1上的两个箭头)。当fork复制进程的时候,会将这两个连接也复制到新的进程(Process 2)。随后,每个进程关闭自己不需要的一个连接 (两个黑色的箭头被关闭; Process 1关闭从PIPE来的输入连接,Process 2关闭输出到PIPE的连接),这样,剩下的红色连接就构成了如上图的PIPE。
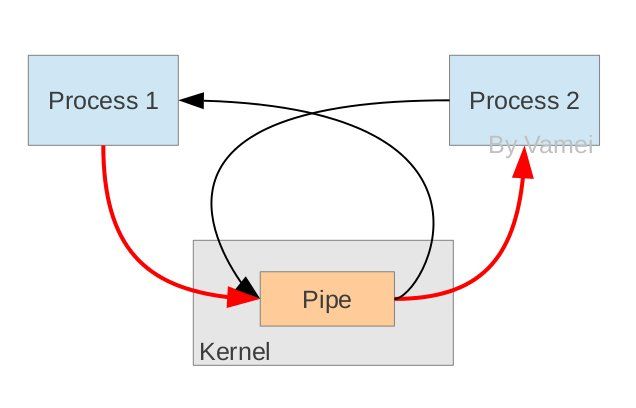
详细的管道创建过程如下图:
实现细节:
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。如下图
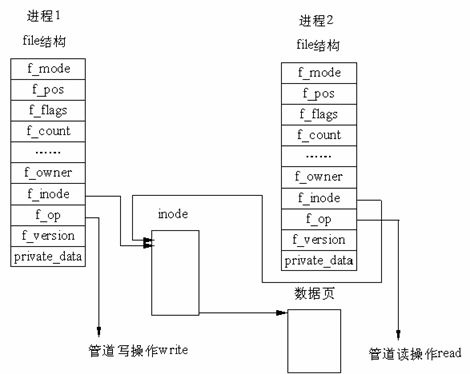
有两个 file 数据结构,但它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。
关于管道的读写
管道实现的源代码在fs/pipe.c中,在pipe.c中有很多函数,其中有两个函数比较重要,即管道读函数pipe_read()和管道写函数pipe_wrtie()。管道写函数通过将字节复制到 VFS 索引节点指向的物理内存而写入数据,而管道读函数则通过复制物理内存中的字节而读出数据。当然,内核必须利用一定的机制同步对管道的访问,为此,内核使用了锁、等待队列和信号。
当写进程向管道中写入时,它利用标准的库函数write(),系统根据库函数传递的文件描述符,可找到该文件的 file 结构。file 结构中指定了用来进行写操作的函数(即写入函数)地址,于是,内核调用该函数完成写操作。写入函数在向内存中写入数据之前,必须首先检查 VFS 索引节点中的信息,同时满足如下条件时,才能进行实际的内存复制工作:
·内存中有足够的空间可容纳所有要写入的数据;
·内存没有被读程序锁定。
如果同时满足上述条件,写入函数首先锁定内存,然后从写进程的地址空间中复制数据到内存。否则,写入进程就休眠在 VFS 索引节点的等待队列中,接下来,内核将调用调度程序,而调度程序会选择其他进程运行。写入进程实际处于可中断的等待状态,当内存中有足够的空间可以容纳写入数据,或内存被解锁时,读取进程会唤醒写入进程,这时,写入进程将接收到信号。当数据写入内存之后,内存被解锁,而所有休眠在索引节点的读取进程会被唤醒。
管道的读取过程和写入过程类似。但是,进程可以在没有数据或内存被锁定时立即返回错误信息,而不是阻塞该进程,这依赖于文件或管道的打开模式。反之,进程可以休眠在索引节点的等待队列中等待写入进程写入数据。当所有的进程完成了管道操作之后,管道的索引节点被丢弃,而共享数据页也被释放。
Linux函数原型
int pipe(int filedes[2]);filedes[0]用于读出数据,读取时必须关闭写入端,即close(filedes[1]);
filedes[1]用于写入数据,写入时必须关闭读取端,即close(filedes[0])。
程序实例:
int main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if(pipe(fd) 0){ /* 先建立管道得到一对文件描述符 */
exit(0);
}
if((pid = fork()) 0) /* 父进程把文件描述符复制给子进程 */
exit(1);
else if(pid > 0){ /* 父进程写 */
close(fd[0]); /* 关闭读描述符 */
write(fd[1], "\nhello world\n", 14);
}
else{ /* 子进程读 */
close(fd[1]); /* 关闭写端 */
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
exit(0);
}由于基于fork机制,所以管道只能用于父进程和子进程之间,或者拥有相同祖先的两个子进程之间 (有亲缘关系的进程之间)。为了解决这一问题,Linux提供了FIFO方式连接进程。FIFO又叫做命名管道(named PIPE)。
FIFO (First in, First out)为一种特殊的文件类型,它在文件系统中有对应的路径。当一个进程以读(r)的方式打开该文件,而另一个进程以写(w)的方式打开该文件,那么内核就会在这两个进程之间建立管道,所以FIFO实际上也由内核管理,不与硬盘打交道。之所以叫FIFO,是因为管道本质上是一个先进先出的队列数据结构,最早放入的数据被最先读出来,从而保证信息交流的顺序。FIFO只是借用了文件系统(file system,命名管道是一种特殊类型的文件,因为Linux中所有事物都是文件,它在文件系统中以文件名的形式存在。)来为管道命名。写模式的进程向FIFO文件中写入,而读模式的进程从FIFO文件中读出。当删除FIFO文件时,管道连接也随之消失。FIFO的好处在于我们可以通过文件的路径来识别管道,从而让没有亲缘关系的进程之间建立连接
函数原型:
int mkfifo(const char *filename, mode_t mode);
int mknode(const char *filename, mode_t mode | S_IFIFO, (dev_t) 0 );其中pathname是被创建的文件名称,mode表示将在该文件上设置的权限位和将被创建的文件类型(在此情况下为S_IFIFO),dev是当创建设备特殊文件时使用的一个值。因此,对于先进先出文件它的值为0。
程序实例:
int main()
{
int res = mkfifo("/tmp/my_fifo", 0777);
if (res == 0)
{
printf("FIFO created/n");
}
exit(EXIT_SUCCESS);
} 编译这个程序:
gcc –o fifo1.c fifo
运行这个程序:
$ ./fifo1
用ls命令查看所创建的管道
$ ls -lF /tmp/my_fifo
prwxr-xr-x 1 root root 0 05-08 20:10 /tmp/my_fifo|
注意:ls命令的输出结果中的第一个字符为p,表示这是一个管道。最后的|符号是由ls命令的-F选项添加的,它也表示是这是一个管道。
FIFO读写规则
从FIFO中读取数据:
约定:如果一个进程为了从FIFO中读取数据而阻塞打开FIFO,那么称该进程内的读操作为设置了阻塞标志的读操作。
- (1)如果有进程写打开FIFO,且当前FIFO内没有数据,则对于设置了阻塞标志的读操作来说,将一直阻塞。对于没有设置阻塞标志读操作来说则返回-1,当前errno值为EAGAIN,提醒以后再试。
- (2)对于设置了阻塞标志的读操作说,造成阻塞的原因有两种:当前FIFO内有数据,但有其它进程在读这些数据;另外就是FIFO内没有数据。解阻塞的原因则是FIFO中有新的数据写入,不论信写入数据量的大小,也不论读操作请求多少数据量。
- (3)读打开的阻塞标志只对本进程第一个读操作施加作用,如果本进程内有多个读操作序列,则在第一个读操作被唤醒并完成读操作后,其它将要执行的读操作将不再阻塞,即使在执行读操作时,FIFO中没有数据也一样(此时,读操作返回0)。
- (4)如果没有进程写打开FIFO,则设置了阻塞标志的读操作会阻塞。
- 注:如果FIFO中有数据,则设置了阻塞标志的读操作不会因为FIFO中的字节数小于请求读的字节数而阻塞,此时,读操作会返回FIFO中现有的数据量。
向FIFO中写入数据:
约定:如果一个进程为了向FIFO中写入数据而阻塞打开FIFO,那么称该进程内的写操作为设置了阻塞标志的写操作。
对于设置了阻塞标志的写操作:
- (1)当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。如果此时管道空闲缓冲区不足以容纳要写入的字节数,则进入睡眠,直到当缓冲区中能够容纳要写入的字节数时,才开始进行一次性写操作。
- (2)当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。FIFO缓冲区一有空闲区域,写进程就会试图向管道写入数据,写操作在写完所有请求写的数据后返回。
对于没有设置阻塞标志的写操作:
- (1)当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。如果当前FIFO空闲缓冲区能够容纳请求写入的字节数,写完后成功返回;如果当前FIFO空闲缓冲区不能够容纳请求写入的字节数,则返回EAGAIN错误,提醒以后再写;
-
- (2)当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。在写满所有FIFO空闲缓冲区后,写操作返回。
【参考】
http://www.2cto.com/os/201607/528773.html
http://www.cnblogs.com/mydomain/archive/2011/04/26/2029493.html