Scrapy框架总结(1)
Scrapy框架总结
- Scrapy简介
- Scrapy架构
- Scrapy运作流程
- 项目文件目录结构
- 最基本的Scrapy爬虫制作流程
- 实战
- 环境安装
- 1、新建项目
- 2、明确目标
- 3、制作爬虫
- 4、 存储内容
Scrapy简介
较为流行的python爬虫框架。
本文着重将记录本人入门Scrapy时的所有精炼总结(除了一些书、官方文档,同时也会借鉴一些比较好的blog的内容,因为书写的太生涩,而官方文档又搞得和过家家一样,乱的不行,根本没法看)。希望能给大家带来帮助,抛砖引玉。
如果爬下来的数据还不会分析,建议先看本人上一篇博文《BeautifulSoup总结及contents内容分析》
Scrapy架构
架构如下图所示:
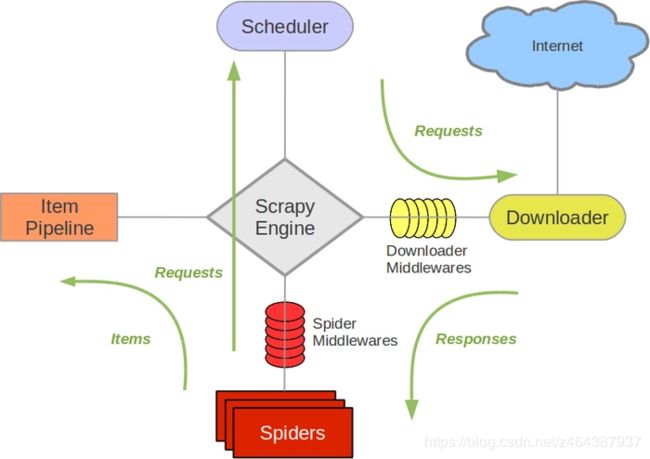
图中绿色线条代表了数据流向。其他几个则是其组件。
//以下是我个人对这些组件的理解,并非官方文档解释
- 引擎(Scrapy Engine):负责整个数据流走向
- 调度器(scheduler):负责将Request入队,并在需要时提供给引擎
- 下载器(DownLoader): 负责提交Request,并获得对应网站的Response,将其提交给spider下一步处理。(可以根据用户定义的下载中间件中的配置进行自定义下载)
- 蜘蛛(Spider):负责处理网站返回的Response,提取Item 或者是 需要继续跟进的URL
- 数据管道(Item pipeline): 去重、过滤、加工和存储Item
- 下载中间件(Downloader middlewares):自定义扩展下载功能的组件
- Spider 中间件 (Spider middlewares):自定义扩展Engine和Spider中间通信的功能组件
Scrapy运作流程
1 引擎:Hi!Spider, 你要处理哪一个网站?
2 Spider:老大要我处理xxxx.com。
3 引擎:你把第一个需要处理的URL给我吧。
4 Spider:给你,第一个URL是xxxxxxx.com。
5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6 调度器:好的,正在处理你等一下。
7 引擎:Hi!调度器,把你处理好的request请求给我。
8 调度器:给你,这是我处理好的request
9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14 管道``调度器:好的,现在就做!
参考: https://segmentfault.com/a/1190000013178839
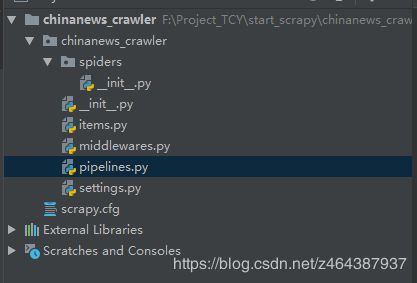
项目文件目录结构
在命令行中,执行 scrapy startproject <项目名称>即会在所在当前目录下创建项目目录以及相关文件。
项目名
|—— 项目名
| |—— _init_.py #包定义
| |—— items.py #模型定义
| |—— middlewares.py #中间件定义
| |—— pipelines.py #管道定义
| |—— settings.py #配置文件。编程方式控制的配置文件
| |—— spider
| |—— _init_.py #默认蜘蛛代码文件
|——— scrapy.cfg #运行配置文件。该文件存放的目录为根目录。模块名的字段定义了项目的设置
最基本的Scrapy爬虫制作流程
1、新建项目
2、明确目标:主要是编写Item.py
3、制作爬虫:主要是编写spider.py
4、存储内容:主要是编写pipelines.py
实战
环境安装
//建议直接安装,不要用conda创建一个环境再安装。
//因为scrapy命令需要在全局使用,这样才能在任何文件夹轻松调用。
pip install Scrapy
//验证是否安装成功。运行该命令出现图中内容即为成功。
scrapy
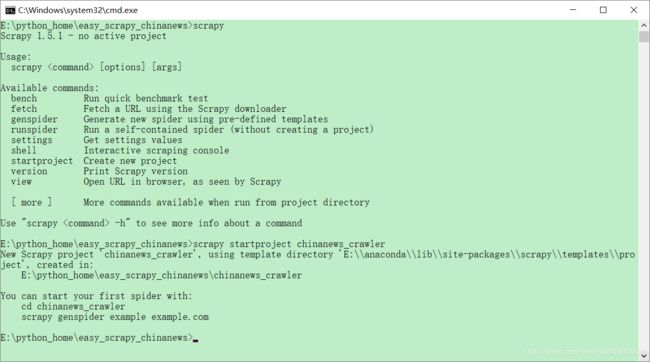
1、新建项目
项目介绍:从中新网爬取新闻供稿的标题、链接、内容和日期,并以json形式保存到本地。
// 需要先cd到你想要存放该项目的路径下
scrapy startproject chinanews_crawler
2、明确目标
先查看以下目标网站内容:
中新网:http://www.chinanews.com/rss/
然后用chrome的开发者工具,查看以下我们需要的链接的位置。
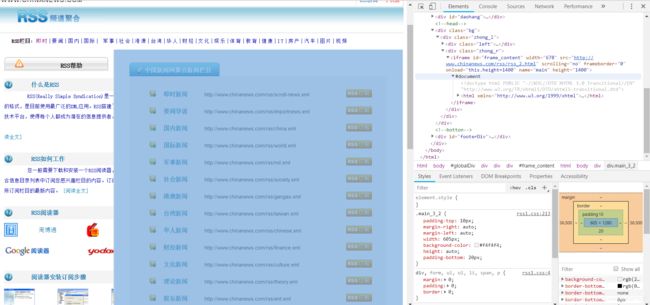
我们发现,那些链接是被放在一个