spring cloud sleuth运用与源码分析
spring cloud sleuth运用与源码分析
- 背景介绍
- 基本术语
- 基础运用
- 基于HTTP方式调用
- pom依赖
- application.properties的修改
- 基于RabbitMQ方式的调用
- 源码解析
背景介绍
基于分布式架构的环境下, 现在一个完整的调用请求往往会经过很多服务的处理,为了查询一个请求的调用经历过哪些服务,按照如何顺序,所以我们需要一个链路式追踪组件。追踪一个服务的调用所有过程。
开源链路式组件目前有Google的Dapper, 阿里的鹰眼,以及twitter的Zipkin。本文将使用Zipkin,Zipkin是基于的Dapper的基础上开发的。Zipkin 可通过http方式消息传输也可使用中间件MQ。Zipkin的消息存储可以直接存储在内存中,也可持久化到mysql,elasticsearch。
基本术语
spring cloud sleuth沿用Google的Dapper的术语:
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址),span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
- trace:是由众多span组成的树形结构,使用64位标识生成唯一调度ID。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束:
1.cs - Client Sent -客户端发起一个请求,这个annotation描述了这个span的开始
2.sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
3.ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
4.cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间。
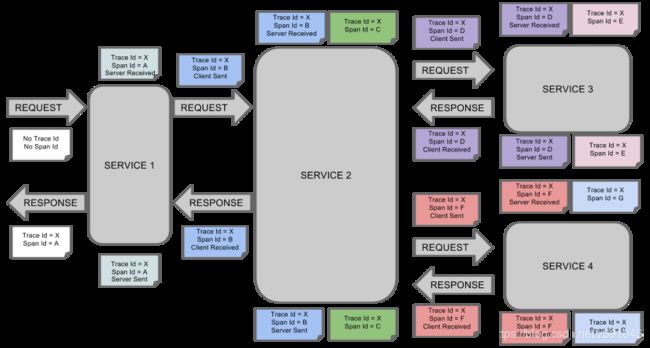
(图片来源网络)
从图可知,当一个请求进来,会进过很多服务,每个服务都会生成一个独立的span,但服务都共享一个trace。
基础运用
基于HTTP方式调用
pom依赖
本文基于之前的zuul模块,以及eureka-client模块。在两模块中都添加zipkin的client依赖以及sleuth依赖
org.springframework.cloud
spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-starter-zipkin
application.properties的修改
spring.application.name=spring-zuul
server.port=8001
zuul.routes.hizuul.service-id=eureka-client
zuul.routes.hizuul.path=/hizuul/**
# 开启sleuth
spring.sleuth.web.enabled=true
# Spring Cloud Sleuth 有一个 Sampler 策略,可以通过这个实现类来控制采样算法。采样器不会
# 阻碍 span 相关 id 的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth 默认
# 采样算法的实现是 Reservoir sampling,具体的实现类是 PercentageBasedSampler,默认的
# 采样比例为: 0.1(即 10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,
#所设置的值介于 0.0 到 1.0 之间,1.0 则表示全部采集。
spring.sleuth.sampler.probability=1.0
# zipkin的server端地址
spring.zipkin.base-url=http://localhost:9411
eureka.client.serviceUrl.defaultZone=http://localhost:1101/eureka/
关于zipkin的服务地址,spring boot 1.x的可以通过pom引入server端的依赖,用户可以自行编译,在2.0之后出于安全以及便捷性考虑,拿掉了这个依赖,推荐用户使用官方编译好的jar包。
所以笔者下载了zipkin的docker image,运行容器。
docker run -d -p 9411:9411 openzipkin/zipkin
运行后访问http://localhost:9411/zipkin/

界面支持中文,还挺友好的。
依次启动eureka-server,eureka-client,zuul三个模块,通过zuul的代理访问eureka-client。
查看zipkin的页面
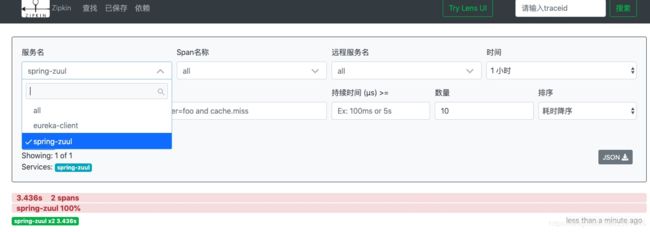
服务名的下拉列表显示了所有监听的服务,选择某个服务后点击搜索,下方先死调用时间以及span个数,点击后进入详情页面
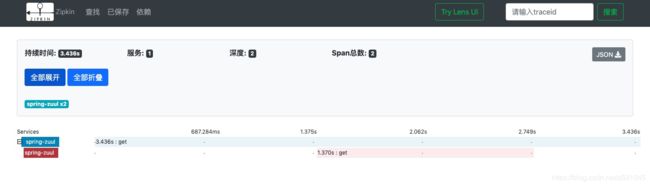
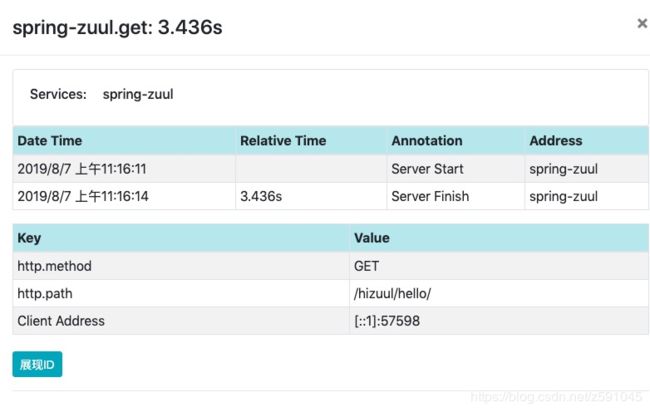
可以看到请求的链路具体信息,深度,spans以及服务调用数。垫底下方的具体service可以看到具体的调用信息
基于RabbitMQ方式的调用
zipkin和rabbitMQ搭配也非常便捷,编写一个docker 的yml文件
version: "3"
services:
rabbitmq:
image: rabbitmq:3-management
container_name: rabbitmq
ports:
- "5672:5672"
- "15672:15672"
zipkin:
image: openzipkin/zipkin:last
container_name: zipkin
depends_on:
- rabbitmq
ports:
- "9411:9411"
environment:
- "RABBIT_URI=amqp://guest:guest@rabbitmq:5672"
运行docker compose的命令就可以将zipkin server端与rabbitMQz组合起来
docker-compose -f zipkin-rabbitmq.yml up
对应的client端只需pom文件引入rabbit的依赖即可以
org.springframework.cloud
spring-cloud-stream-binder-rabbit
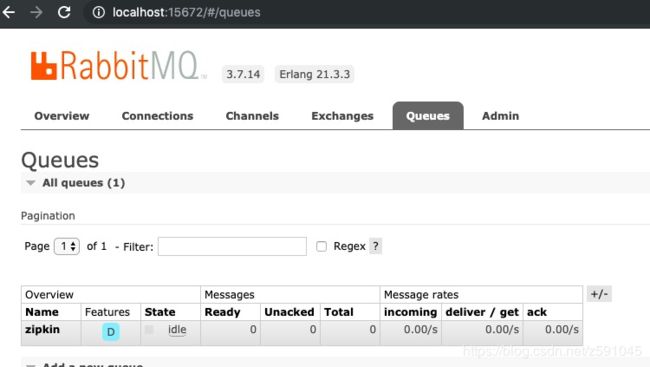 在rabbitMQ的页面上可以看到了zipkin的queue信息。
在rabbitMQ的页面上可以看到了zipkin的queue信息。
zipkin 与mysql的结合,或者kafka,elasticsearc的结合都可以通过yml文件让docker完成。https://github.com/openzipkin/docker-zipkin 官方详细的介绍了zipkin的docker使用,以及帮用户准备好了与mysql,kafka等常用中间件的docker yml文件
源码解析
spring cloud sleuth 需要关注的源码量很少,与zuul,hystrix的适配都是通过spring boot的autoconfig 配置实现的。只需关注一个类TraceAutoConfiguration够了。
@Bean
@ConditionalOnMissingBean
// NOTE: stable bean name as might be used outside sleuth
Tracing tracing(
@Value("${spring.zipkin.service.name:${spring.application.name:default}}") String serviceName,
Propagation.Factory factory, CurrentTraceContext currentTraceContext,
Sampler sampler, ErrorParser errorParser, SleuthProperties sleuthProperties,
@Nullable List> spanReporters) {
Tracing.Builder builder = Tracing.newBuilder().sampler(sampler)
.errorParser(errorParser)
.localServiceName(StringUtils.isEmpty(serviceName) ? DEFAULT_SERVICE_NAME
: serviceName)
.propagationFactory(factory).currentTraceContext(currentTraceContext)
.spanReporter(new CompositeReporter(this.spanAdjusters,
spanReporters != null ? spanReporters : Collections.emptyList()))
.traceId128Bit(sleuthProperties.isTraceId128())
.supportsJoin(sleuthProperties.isSupportsJoin());
for (FinishedSpanHandler finishedSpanHandlerFactory : this.finishedSpanHandlers) {
builder.addFinishedSpanHandler(finishedSpanHandlerFactory);
}
return builder.build();
}
@Bean(name = TRACER_BEAN_NAME)
@ConditionalOnMissingBean
Tracer tracer(Tracing tracing) {
return tracing.tracer();
}
@Bean
@ConditionalOnMissingBean
Sampler sleuthTraceSampler() {
return Sampler.NEVER_SAMPLE;
}
简单的看,就是检查在各种bean丢失的情况下,创建对应的bean,链路追踪的底层实现还是调用zipkin来实现的。