【文献阅读】VQA中的原因生成(H. A. Ayyubi等人,ArXiv,2020)
一、背景
文章题目:《Generating Rationales in Visual Question Answering》
Arxiv上比较新的一篇文章。作者全部来自于UC San Diego。这篇文章重点研究的是VQA模型的可解释性,个人感觉和【文献阅读】VQA-E——一种对预测答案解释的模型和数据集(Q. Li等人,ECCV,2018)这一篇文章的思路差不多。
文章下载地址:https://arxiv.org/pdf/2004.02032.pdf
文章引用格式:H. A. Ayyubi. M. Tanjim, J. J. McAuley, G. W. Cottrell. "Stacked Attention Networks for Image Question Answering." arXiv, 2015
项目地址:暂未公布,不过作者说了Source code will be provided at the time of publication,关注这篇文章的人可以稍微等等。
二、文章导读
文章的摘要部分:
Despite recent advances in Visual Question Answering (VQA), it remains a challenge to determine how much success can be attributed to sound reasoning and comprehension ability. We seek to investigate this question by proposing a new task of rationale generation. Essentially, we task a VQA model with generating rationales for the answers it predicts. We use data from the Visual Commonsense Reasoning (VCR) task, as it contains ground-truth rationales along with visual questions and answers. We first investigate commonsense understanding in one of the leading VCR models, ViLBERT, by generating rationales from pretrained weights using a state-of-the-art language model, GPT-2. Next, we seek to jointly train ViLBERT with GPT-2 in an end-to-end fashion with the dual task of predicting the answer in VQA and generating rationales. We show that this kind of training injects commonsense understanding in the VQA model through quantitative and qualitative evaluation metrics.
尽管目前VQA取得了一些成果,但是对于模型的推理和理解能力是如何影响结果的,仍然需要研究。基于此问题,作者提出了一种原因生成的新任务。简单的说,就是用原因生成的VQA模型来回答模型的预测。数据来自于VCR。
首先作者研究了VCR领域代表模型——ViLBERT的理解能力,这里作者的生成原因来自于语言模型GPT-2的与训练参数。然后,作者训练了结合GPT-2的ViLBERT模型,用端到端的方式来预测VQA中的答案和生成原因。作者的实验表明了能够将常识理解结合到VQA中,并通过了量化评估。
三、文章详细介绍
VQA目前的关键问题是,模型究竟是如何理解图像,问题,并给出预测答案的。模型的运转是否依赖问题,图像,以及数据集中的偏见?对于这些问题的研究,能够很好的对VQA模型进行解释。
而先前对于模型理解不同模态的研究,则是对单词进行扰动,或者是对图像进行热力图构建。目前则仍旧需要对多模态的数据进行联合研究。
为了对模型理解能力进行测量,作者在VQA中提出了原因生成的任务。该任务不仅需要模型理解图像和问题,还需要推断出最终的正确答案。
作者使用的是VCR(Visual Commonsense Reasoning)数据集,该数据集包含有问题,对应的图像,4个答案选项,以及4个原因选项。作者先用VQA生成预测答案,然后再对答案生成原因,对比真实原因就可以判断模型是否完全理解问题和图像。
1. 方法介绍
首先介绍一下这个Task,作者给了一张示意图:
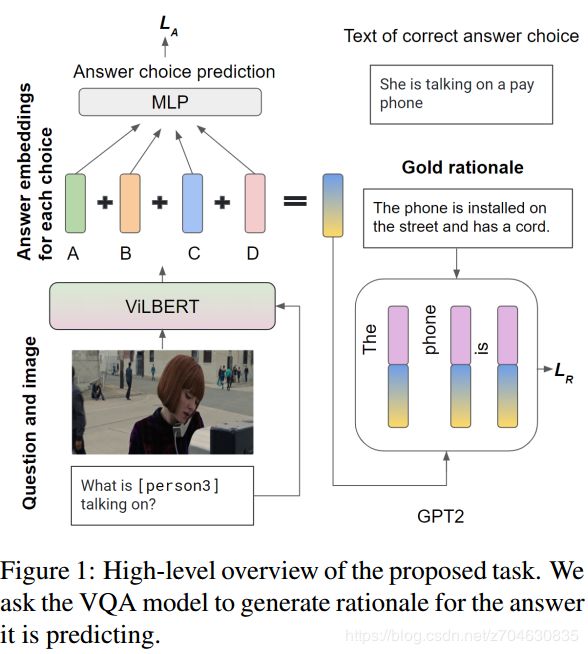
该Task包含两个模块,一个模块首先是输入图像和问题到预训练的ViBERT模型中,然后用多层感知器MLP计算答案嵌入的预测值;另一个模块是将预测好的答案嵌入输入到一个预训练的语言模型GPT2中,来生成原因。
1.1 预测答案嵌入模块
这里的VQA模型是ViBERT,输入图像I和问题Q,模型对每一个答案选项都能输出一个嵌入,然后将这个嵌入输入到softmax里。从四个答案中选择出最大概率答案嵌入的行为会使得网络变得不可微(non-differentiable),因此作者通过对每一个选项在softmax中加权后取平均来计算预测答案的嵌入。
1.2 生成原因模块
作者规定该模块为条件语言生成。条件为输入的语言嵌入和先前生成的原因符号,目标则是求取最大的对数似然。之后的模型精校正使用VCR数据集中的金标准原因(gold standard rationale)。
2. 实验
实验使用的是VCR(Visual Commonsense Reasoning)数据集,该数据集是从11万个电影场景中截取的,包含了29万个问题,并且包含了原因。reference VQA model采用的是ViLBERT,语言模型采用的是预训练的GPT-2。
如何确定模型是否理解了问题呢。作者就将ViLBERT的答案预测的嵌入提取出来,传入到GPT-2中生成原因。评估标准作者采用的是BLEU和ROUGE。另外作者还用了InferSent模型来计算句子的嵌入,并利用余弦相似度来评价生成原因和真实原因之间的差异。
下来就是实验的比较结果了,不过结果不太多。
(1)首先是生成原因这里,结果可以看下图:

该实验的ViLBERT-Fr是指预训练好的VQA模型,和使用真实原因精校正的GPT-2模型;另一个ViLBERT-Ra是指用KL散度作为正则项(计算的是ViLBERT的答案得分和对答案嵌入进行softmax得分之间的散度)的VQA模型和原因预测模型。ViLBERT-Ra的结果要稍微好一些,表明生成原因模块能够提高模型的理解能力。
(2)ViLBERT-Fr和ViLBERT-Ra比较的定性评估。这里作者从验证集随机选了100个样本,然后打乱,让工作人员从两个模型的生成原因中选择一个最佳的。结果如下图:
