线性回归中关于特征收缩与选择的方法比较(七种常用的线性回归)(python-sklearn实现)
文章目录
- 什么是特征收缩或者特征选择
- 设置和数据加载
- 线性回归(Linear Regression)
- 偏差方差均衡
- 最佳子集回归(Best Subset Regression)
- 岭回归(Ridge Regression)
- LASSO
- 弹性网(Elastic Net)
- 最小角度回归(Least Angle Regression)
- 主成分回归(Principal Components Regression)
- 偏最小二乘法(Partial Least Squares)
- 总结与回顾
本文讨论了线性回归中七种常用的特征收缩和选择方法的数学属性和实际的 Python 应用。
什么是特征收缩或者特征选择
在线性回归中,特征收缩或者特征选择意味着从可用特征中选择要包含在模型中的子集特征,从而减少其维数。另一方面,收缩意味着减小系数估计的大小(可将它们缩小到零)。请注意,如果系数缩小到恰好为零,则相应的变量将退出模型。因此,这种情况也可以看作是特征选择。
特征收缩或者特征选择旨在改进简单的线性回归。有两个主要原因可能需要改进:
-
预测准确性:线性回归估计倾向于具有低偏差和高方差(过拟合)。降低模型复杂性(需要估计的参数数量)以降低方差,增强模型的稳定性,但代价是引入更多偏差。如果我们能找到总误差的最佳位置,那么偏差导致的误差加上最小化方差的误差,便可以改进模型的预测精度。
-
模型的可解释性:由于预测变量太多,很难掌握变量之间的所有关系。在某些情况下,我们愿意确定影响最大的一小部分变量,从而牺牲一些变量以增强模型的可解释性。
设置和数据加载
先看看将要分析的数据集。它来自 Stamey 等人的一项研究。(1989)研究了不同临床测量对前列腺特异性抗原(PSA)水平的影响。任务是根据一组临床和人口统计学变量确定前列腺癌的风险因素。数据以及变量的一些描述可以在Hastie等人的网站上找到。或者这里给出数据或者评论邮箱地址发邮箱。
我们将首先导入本文中使用的模块,加载数据并将其拆分为训练和测试集,分别保留标签和特征。然后,我们将讨论每种特征收缩和选择方法,使其适合训练数据,并使用测试集检查它如何能够预测新数据的 PSA 水平。
# Import necessary modules and set options
import pandas as pd
import numpy as np
import itertools
from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV, ElasticNetCV, LarsCV
from sklearn.cross_decomposition import PLSRegression
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings("ignore")
# Load data
data = pd.read_csv("prostate_data.txt", sep = "\t")
print(data.head())
# Train-test split
y_train = np.array(data[data.train == "T"]['lpsa'])
y_test = np.array(data[data.train == "F"]['lpsa'])
X_train = np.array(data[data.train == "T"].drop(['lpsa', 'train', 'Unnamed: 0'], axis=1))
X_test = np.array(data[data.train == "F"].drop(['lpsa', 'train', 'Unnamed: 0'], axis=1))
线性回归(Linear Regression)
从简单的线性回归开始,它将目标变量 y y y 建模为 p p p 个预测变量或特征 X X X 的线性组合:
f ( X ) = β 0 + ∑ j = 1 p X j β j \mathcal{f}(X) = \beta_0 + \sum_{j=1}^{p}X_j \beta_j f(X)=β0+j=1∑pXjβj
该模型具有必须从训练数据估计的 p + 2 p + 2 p+2 个参数:
- p p p 个特征的 p p p 个 β \beta β 系数,表示相应的特征对预测目标的影响;
- 一个截距参数,表示为上面的 β 0 β_0 β0,它是在所有X都为零的情况下的预测。没有必要将它包含在模型中,实际上在某些情况下应该将其删除(例如,如果想要包含表示分类变量级别的全部虚拟对象),如果你将在下面看到它,通常它会给模型更大的灵活性;
- 高斯误差项的一个方差参数。
通常使用普通最小二乘法(OLS)估计这些参数。OLS最小化均方误差,由下式给出
R S S ( β ) = ∑ i = 1 N ( y i − f ( x i ) ) 2 RSS(\beta) = \sum_{i=1}^{N}(y_i - f(x_i))^2 RSS(β)=i=1∑N(yi−f(xi))2
= ∑ i = 1 N ( y i − β 0 − ∑ j = 1 p x i j β j ) 2 =\sum_{i=1}^{N}(y_i -\beta_0-\sum_{j=1}^{p}x_{ij}\beta_j)^2 =i=1∑N(yi−β0−j=1∑pxijβj)2
可视化: 只有一个预测变量X,我们处于由预测变量和目标形成的 2D 空间中。在此设置中,模型在 X,Y 中拟合这样的线最接近所有数据点的空间,接近度测量为所有数据点的垂直距离平方和,如左图。如果有两个预测变量X1和X2,则空间增长到3D,现在模型拟合最接近3D空间中所有点的平面,如右图。有了两个以上的特征,就变成了有点抽象的超平面。可视化也有助于了解截距如何为模型提供更大的灵活性:如果包含它,它允许线或平面不跨越空间的原点。

上述最小化问题证明具有解析解,并且β参数可以计算为:
β ^ = ( X T X ) − 1 X T y \hat{\beta} = (X^TX)^{-1}X^Ty β^=(XTX)−1XTy
证明参见
在 X 矩阵中包括一列 1 ,允许表达上述公式中的β帽矢量的截距部分。“β”上方的“帽子”表示它是基于训练数据的估计值。
偏差方差均衡
在统计学中,要考虑估计量的两个关键特征:偏差和方差。偏差是真实总体参数和预期估计量之间的差异。它衡量估计数的不准确性。另一方面,方差衡量它们之间的差异。
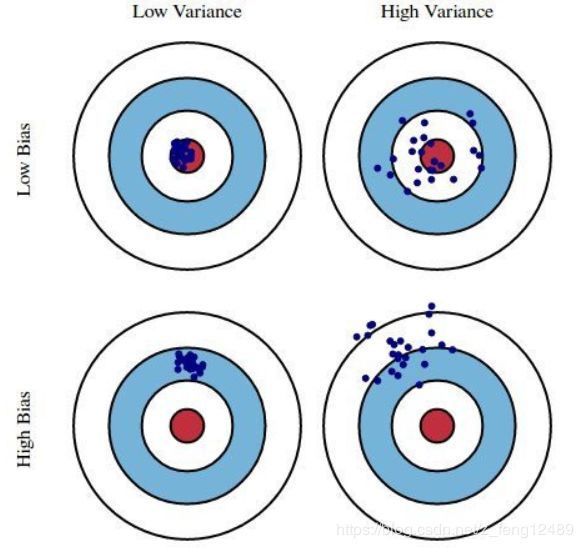
显然,如果模型太简单,偏差和方差都会损害模型的预测性能。然而,线性回归倾向于受到方差的影响,同时具有低偏差。如果模型中存在许多预测特征或者它们彼此高度相关,则尤其如此。这就是子集化和正则化来拯救的地方。它们允许以引入一些偏差为代价来减少方差,最终减少模型的总误差。
在详细讨论这些方法之前,让我们将线性回归拟合到前列腺数据中并检查其样本外的平均预测误差(MAE)。
linreg_model = LinearRegression(normalize=True).fit(X_train, y_train)
linreg_prediction = linreg_model.predict(X_test)
linreg_mae = np.mean(np.abs(y_test - linreg_prediction))
linreg_coefs = dict(
zip(['Intercept'] + data.columns.tolist()[1:-2],
np.round(np.concatenate((linreg_model.intercept_, linreg_model.coef_),
axis=None), 3))
)
print(data.columns.tolist()[1:-2], (linreg_model.intercept_, linreg_model.coef_))
print('Linear Regression MAE: {}'.format(np.round(linreg_mae, 3)))
print('Linear Regression coefficients:', linreg_coefs)
Linear Regression MAE: 0.523
Linear Regression coefficients: {'Intercept': 0.429, 'lcavol': 0.577, 'lweight': 0.614, 'age': -0.019, 'lbph': 0.145, 'svi': 0.737, 'lcp': -0.206, 'gleason': -0.03, 'pgg45': 0.009}
最佳子集回归(Best Subset Regression)
选择线性回归变量子集的直接方法是尝试所有可能的组合,并选择一个最小化某些标准的组合。这就是 Best Subset Regression 的目标。对于每一个 ķ ∈ 1 , 2 , . . . , P ķ \in {1,2,...,P} ķ∈1,2,...,P,其中 p 是可用特征的总数,它选择大小的子集 ķ 给出最小的均方误差。然而,平方和不能用作确定 k 本身的标准,因为它必然随 k 减小:模型中包含的变量越多,其残差越小。但这并不能保证更好的预测性能。这就是为什么应该使用另一个标准来选择最终模型的原因。对于预测模型,测试测试数据上的(可能是交叉验证的)均方误差是常见的选择。
由于最佳子集回归没有在任何Python包中实现,我们必须手动循环 k 和 k 大小的所有子集。以下代码块完成了这项工作。
results = pd.DataFrame(columns=['num_features', 'features', 'MAE'])
# Loop over all possible numbers of features to be included
for k in range(1, X_train.shape[1] + 1):
# Loop over all possible subsets of size k
for subset in itertools.combinations(range(X_train.shape[1]), k):
linreg_model = LinearRegression(normalize=True).fit(X_train[:, subset], y_train)
linreg_prediction = linreg_model.predict(X_test[:, subset])
linreg_mae = np.mean(np.abs(y_test - linreg_prediction))
results = results.append(pd.DataFrame([{'num_features': k,
'features': subset,
'MAE': linreg_mae}]))
# Inspect best combinations
results = results.sort_values('MAE').reset_index()
print(results.head())
# Fit best model
# get corresponding feature describe
feature_describe = data.columns.tolist()[1:-2]
best_subset_feature_index = results['features'][0]
best_subset_feature_describe = []
for index in best_subset_feature_index:
best_subset_feature_describe.append(feature_describe[index])
best_subset_model = LinearRegression(normalize=True).fit(X_train[:, results['features'][0]], y_train)
best_subset_coefs = dict(
zip(['Intercept'] + best_subset_feature_describe,
np.round(np.concatenate((best_subset_model.intercept_, best_subset_model.coef_), axis=None), 3))
)
print('Best Subset Regression MAE: {}'.format(np.round(results['MAE'][0], 3)))
print('Best Subset Regression coefficients:', best_subset_coefs)
results = pd.DataFrame(columns=['num_features', 'features', 'MAE'])
# Loop over all possible numbers of features to be included
for k in range(1, X_train.shape[1] + 1):
# Loop over all possible subsets of size k
for subset in itertools.combinations(range(X_train.shape[1]), k):
subset = list(subset)
linreg_model = LinearRegression(normalize=True).fit(X_train[:, subset], y_train)
linreg_prediction = linreg_model.predict(X_test[:, subset])
linreg_mae = np.mean(np.abs(y_test - linreg_prediction))
results = results.append(pd.DataFrame([{'num_features': k,
'features': subset,
'MAE': linreg_mae}]))
# Inspect best combinations
results = results.sort_values('MAE').reset_index()
print(results.head())
# Fit best model
best_subset_model = LinearRegression(normalize=True).fit(X_train[:, results['features'][0]], y_train)
best_subset_coefs = dict(
zip(['Intercept'] + data.columns.tolist()[1:-1],
np.round(np.concatenate((best_subset_model.intercept_, best_subset_model.coef_), axis=None), 3))
)
print('Best Subset Regression MAE: {}'.format(np.round(results['MAE'][0], 3)))
print('Best Subset Regression coefficients:', best_subset_coefs)
index MAE features num_features
0 0 0.466876 (0, 1, 2, 4, 7) 5
1 0 0.467043 (0, 1, 2, 4, 6, 7) 6
2 0 0.471730 (0, 1, 2, 4, 6) 5
3 0 0.478344 (0, 1, 4, 7) 4
4 0 0.479609 (0, 1, 4, 6) 4
Best Subset Regression MAE: 0.467
Best Subset Regression coefficients: {'Intercept': -0.599, 'lcavol': 0.497, 'lweight': 0.81, 'age': -0.012, 'svi': 0.413, 'pgg45': 0.005}
岭回归(Ridge Regression)
最佳子集回归(BSR)的一个缺点是它没有告诉我们关于从模型中排除的特征对响应变量的影响。岭回归提供了这种硬选择的替代方案,将这些特征分成包含在模型中的和不包含的。相反,它惩罚系数以将它们缩小到零。不完全为零,因为这意味着从模型中排除,但是在零方向上,这可以被视为以连续方式降低模型的复杂性,同时将所有变量保持在模型中。
在岭回归中,线性回归损失函数以这样的方式增强,不仅可以最小化差方和,还可以惩罚参数估计的大小:
L r i d g e ( β ^ ) = ∑ i = 1 n ( y i − x i ′ β ^ ) 2 + λ ∑ j = 1 m β j ^ 2 = ∣ ∣ y − X β ^ ∣ ∣ 2 + λ ∣ ∣ β ^ ∣ ∣ 2 \mathcal{L}_{ridge}(\hat\beta )=\sum_{i=1}^{n}(y_i-x_i'\hat\beta)^2+\lambda\sum_{j=1}^{m}\hat{\beta_j}^2=||y-X\hat{\beta}||^2+\lambda||\hat\beta||^2 Lridge(β^)=i=1∑n(yi−xi′β^)2+λj=1∑mβj^2=∣∣y−Xβ^∣∣2+λ∣∣β^∣∣2
解决这个最小化问题解析解:
β ^ r i d g e = ( X T X + λ I ) − 1 X T y \hat{\beta}^{ridge} = (X^TX+\lambda I)^{-1}X^Ty β^ridge=(XTX+λI)−1XTy
其中 I 表示单位矩阵。惩罚项λ是要选择的超参数:其值越大,系数越向零收缩。从上面的公式可以看出,当 λ 变为零时,加性罚分消失,β-ridge 与线性回归中的 β-OLS 相同。另一方面,当 λ 增长到无穷大时,β-ridge 接近于零:在足够高的惩罚下,系数可以任意地收缩到接近零。
但这种收缩是否真的会导致减少模型的方差,但会以承诺的方式引入一些偏差?是的,确实如此,从岭回归估计的偏差和方差的公式中可以清楚地看出:随着λ的增加,偏差也随之增加,而方差则下降!
B i a s ( β ^ r i d g e ) = − λ ( X ′ X + λ I ) − 1 β Bias(\hat{\beta}_{ridge}) = -\lambda(X'X+\lambda I)^{-1}\beta Bias(β^ridge)=−λ(X′X+λI)−1β
V a r ( β r i d g e ^ ) = σ 2 ( X ′ X + λ I ) − 1 X ′ X ( X ′ X + λ I ) − 1 Var(\hat{\beta_{ridge}})=\sigma^2(X'X+\lambda I)^{-1}X'X(X'X+\lambda I)^{-1} Var(βridge^)=σ2(X′X+λI)−1X′X(X′X+λI)−1
现在,如何选择 λ 的最佳值?运行交叉验证尝试一组不同的值,并选择一个最小化测试数据上交叉验证错误的值。
# ridge regression
ridge_cv = RidgeCV(normalize=True, alphas=np.logspace(-10, 1, 400))
ridge_model = ridge_cv.fit(X_train, y_train)
ridge_prediction = ridge_model.predict(X_test)
ridge_mae = np.mean(np.abs(y_test - ridge_prediction))
ridge_coefs = dict(
zip(['Intercept'] + data.columns.tolist()[1:-2],
np.round(np.concatenate((ridge_model.intercept_, ridge_model.coef_),
axis=None), 3))
)
print('Ridge Regression MAE: {}'.format(np.round(ridge_mae, 3)))
print('Ridge Regression coefficients:', ridge_coefs)
Ridge Regression MAE: 0.517
Ridge Regression coefficients: {'Intercept': 0.155, 'lcavol': 0.51, 'lweight': 0.605, 'age': -0.016, 'lbph': 0.14, 'svi': 0.692, 'lcp': -0.134, 'gleason': 0.009, 'pgg45': 0.008}
LASSO
Lasso,或最小绝对收缩和选择算子,在精髓上与岭回归非常相似。它还为损失函数的非零系数增加了一个惩罚,但与惩罚平方系数之和(所谓的 L2 惩罚)的岭回归不同,LASSO惩罚它们的绝对值之和( L1 惩罚)。因此,对于 λ 的高值,许多系数在 LASSO 下完全归零,这在岭回归中从未如此。
它们之间的另一个重要区别是它们如何解决这些特征之间的多重共线性问题。在岭回归中,相关变量的系数趋于相似,而在 LASSO 中,其中一个通常为零,另一个则分配整个影响。因此,如果存在大约相同值的许多大参数,即当大多数预测变量真正影响响应时,预期岭回归将更好地工作。另一方面,当存在少量重要参数且其他参数接近于零时,即当只有少数预测因子实际影响响应时,LASSO效果更好。
然而,在实践中,人们不知道参数的真实值。因此,岭回归和 LASSO 之间的选择可以基于样本外预测误差。另一种选择是将这两种方法合二为一,就是下一种回归方法。
LASSO的损失函数如下:
L l a s s o ( β ^ ) = ∑ i = 1 n ( y i − x i ′ β ^ ) 2 + λ ∑ j = 1 m ∣ β ^ j ∣ \mathcal{L}_{lasso}(\hat\beta) = \sum_{i=1}^{n} (y_i-x'_i\hat\beta)^2+\lambda\sum_{j=1}^{m}|\hat\beta_j| Llasso(β^)=i=1∑n(yi−xi′β^)2+λj=1∑m∣β^j∣
与岭回归不同,这种最小化问题无法通过分析解决。幸运的是,有数值算法可以处理它。
# LASSO
lasso_cv = LassoCV(normalize=True, alphas=np.logspace(-10, 1, 400))
lasso_model = lasso_cv.fit(X_train, y_train)
lasso_prediction = lasso_model.predict(X_test)
lasso_mae = np.mean(np.abs(y_test - lasso_prediction))
lasso_coefs = dict(
zip(['Intercept'] + data.columns.tolist()[1:-2],
np.round(np.concatenate((lasso_model.intercept_, lasso_model.coef_), axis=None), 3))
)
print('LASSO MAE: {}'.format(np.round(lasso_mae, 3)))
print('LASSO coefficients:', lasso_coefs)
LASSO MAE: 0.5
LASSO coefficients: {'Intercept': 0.074, 'lcavol': 0.459, 'lweight': 0.456, 'age': -0.0, 'lbph': 0.05, 'svi': 0.352, 'lcp': 0.0, 'gleason': 0.0, 'pgg45': 0.002}
弹性网(Elastic Net)
弹性网首先是针对 LASSO 的劣势而产生的,LASSO的变量选择过于依赖数据,因而不稳定。它的解决方案是将 Ridge Regression 和 LASSO 的惩罚结合起来,以获得两全其美的效果。弹性网旨在最大限度地减少包括 L1 和 L2 惩罚的损失函数:
L e n e t ( β ^ ) = ∑ i = 1 n ( y i − x i ′ β ^ ) 2 2 n + λ ( 1 − α 2 ∑ j = 1 m β ^ j 2 + α ∑ j = 1 m ∣ β ^ j ∣ ) \mathcal{L}_{enet}(\hat\beta)=\frac{\sum_{i=1}^{n}(y_i-x'_i\hat\beta)^2}{2n}+\lambda (\frac{1-\alpha}{2}\sum_{j=1}^{m}\hat\beta_j^2+\alpha\sum_{j=1}^{m}|\hat\beta_j|) Lenet(β^)=2n∑i=1n(yi−xi′β^)2+λ(21−αj=1∑mβ^j2+αj=1∑m∣β^j∣)
其中 α 是岭回归(当它为零时)和 LASSO(当它为1时)之间的混合参数。可以使用基于 scikit-learn 的基于交叉验证的超左侧调整来选择最佳α。
# Elastic Net
elastic_net_cv = ElasticNetCV(normalize=True, alphas=np.logspace(-10, 1, 400),
l1_ratio=np.linspace(0, 1, 100))
elastic_net_model = elastic_net_cv.fit(X_train, y_train)
elastic_net_prediction = elastic_net_model.predict(X_test)
elastic_net_mae = np.mean(np.abs(y_test - elastic_net_prediction))
elastic_net_coefs = dict(
zip(['Intercept'] + data.columns.tolist()[1:-2],
np.round(np.concatenate((elastic_net_model.intercept_,
elastic_net_model.coef_), axis=None), 3))
)
print('Elastic Net MAE: {}'.format(np.round(elastic_net_mae, 3)))
print('Elastic Net coefficients:', elastic_net_coefs)
Elastic Net MAE: 0.5
Elastic Net coefficients: {'Intercept': 0.074, 'lcavol': 0.459, 'lweight': 0.456, 'age': -0.0, 'lbph': 0.05, 'svi': 0.352, 'lcp': 0.0, 'gleason': 0.0, 'pgg45': 0.002}
最小角度回归(Least Angle Regression)
到目前为止,我们已经讨论了一种子集化方法,最佳子集回归和三种收缩方法:岭回归,LASSO及其组合,弹性网络。本节专门介绍位于子集和收缩之间的方法:最小角度回归(LAR)。该算法以零模型开始,所有系数等于零,然后迭代地工作,在每个步骤将一个变量的系数移向其最小二乘值。
更具体地说,LAR从识别与响应最相关的变量开始。然后,它将该变量的系数连续地移向其最小平方值,从而降低其与演化残差的相关性。一旦另一个变量在与残差的相关性方面“赶上”,该过程就会暂停。然后,第二个变量加入有效集,即具有非零系数的变量集,并且它们的系数以保持其相关性连接和减少的方式一起移动。继续该过程直到所有变量都在模型中,并以完全最小二乘拟合结束。
下面的代码块将LAR应用于前列腺数据。
LAR_cv = LarsCV(normalize=True)
LAR_model = LAR_cv.fit(X_train, y_train)
LAR_prediction = LAR_model.predict(X_test)
LAR_mae = np.mean(np.abs(y_test - LAR_prediction))
LAR_coefs = dict(
zip(['Intercept'] + data.columns.tolist()[1:-2],
np.round(np.concatenate((LAR_model.intercept_, LAR_model.coef_), axis=None), 3))
)
print('Least Angle Regression MAE: {}'.format(np.round(LAR_mae, 3)))
print('Least Angle Regression coefficients:', LAR_coefs)
Least Angle Regression MAE: 0.499
Least Angle Regression coefficients: {'Intercept': 0.05, 'lcavol': 0.46, 'lweight': 0.46, 'age': 0.0, 'lbph': 0.054, 'svi': 0.362, 'lcp': 0.0, 'gleason': 0.0, 'pgg45': 0.002}
主成分回归(Principal Components Regression)
我们已经讨论了选择变量(子集)和降低系数(收缩)的方法。本文中介绍的最后两种方法采用了稍微不同的方法:它们将原始要素的输入空间挤压到较低维度的空间中。主要是,他们使用X创建一小组新特征Z,它们是X的线性组合,然后在回归模型中使用它们。
这两种方法中的第一种是主成分回归。它应用主成分分析,这种方法允许获得一组新特征,彼此不相关且具有高方差(以便它们可以解释目标的方差),然后将它们用作简单线性回归中的特征。这使得它类似于岭回归,因为它们都在原始特征的主成分空间上运行(对于基于PCA的岭回归推导,参见[参考文献1])。不同之处在于 PCR 丢弃具有最少信息功能的成分,而Ridge Regression只是将它们缩小得更强。
要重新获得的成分数量可以视为超参数,并通过交叉验证进行调整,如下面的代码块中的情况。
# Principal Components Regression
regression_model = LinearRegression(normalize=True)
pca_model = PCA()
pipe = Pipeline(
steps=[
('pca', pca_model), ('least_squares', regression_model)])
param_grid = {'pca__n_components': range(1, 9)}
search = GridSearchCV(pipe, param_grid)
pcareg_model: GridSearchCV = search.fit(X_train, y_train)
pcareg_prediction = pcareg_model.predict(X_test)
pcareg_mae = np.mean(np.abs(y_test - pcareg_prediction))
n_comp = list(pcareg_model.best_params_.values())[0]
pcareg_coefs = dict(
zip(['Intercept'] + ['PCA_comp_' + str(x) for x in range(1, n_comp + 1)],
np.round(np.concatenate((pcareg_model.best_estimator_.steps[1][1].intercept_,
pcareg_model.best_estimator_.steps[1][1].coef_), axis=None), 3))
)
print('Principal Components Regression MAE: {}'.format(np.round(pcareg_mae, 3)))
print('Principal Components Regression coefficients:', pcareg_coefs)
实验降到7个成分时测试结果最佳:
Principal Components Regression MAE: 0.504
Principal Components Regression coefficients: {'Intercept': 2.452, 'PCA_comp_1': 0.019, 'PCA_comp_2': -0.018, 'PCA_comp_3': -0.114, 'PCA_comp_4': 0.495, 'PCA_comp_5': 0.513, 'PCA_comp_6': -0.46, 'PCA_comp_7': -0.468}
偏最小二乘法(Partial Least Squares)
本文讨论的最终方法是偏最小二乘法(PLS)。与主成分回归类似,它也使用原始要素的一小组线性组合。不同之处在于如何构建这些组合。虽然主成分回归仅使用 X 自身来创建派生特征 Z,但偏最小二乘另外使用目标 y。因此,在构建 Z 时,PLS 寻找具有高方差的方向(因为这些可以解释目标中的方差)以及与目标的高相关性。这与主成分回归形成对比,主成分回归仅关注高方差。
在 PLS 下,第一个新特征 z1 被创建为所有特征 X 的线性组合,其中每个 Xs 由其内积与目标 y 加权。然后,y 在 z1上回归,给出 PLS β 系数。最后,所有 X 都相对于 z1 正交化。然后,该过程重新开始 z2 并继续,直到获得 Z 中所需的组件数量。像往常一样,这个数字可以通过交叉验证来选择。
可以证明,尽管 PLS 根据需要缩小了 Z 中的低方差分量,但它有时会使高方差分量膨胀,这可能导致在某些情况下更高的预测误差。这似乎是我们的前列腺数据的情况:PLS 在所有讨论的方法中表现最差。
# Partial Least Squares
pls_model_setup = PLSRegression(scale=True)
param_grid = {'n_components': range(1, 9)}
search = GridSearchCV(pls_model_setup, param_grid)
pls_model = search.fit(X_train, y_train)
pls_prediction = pls_model.predict(X_test)
pls_mae = np.mean(np.abs(y_test - pls_prediction))
pls_coefs = dict(
zip(data.columns.tolist()[1:-2],
np.round(np.concatenate((pls_model.best_estimator_.coef_), axis=None), 3))
)
print('Partial Least Squares Regression MAE: {}'.format(np.round(pls_mae, 3)))
print('Partial Least Squares Regression coefficients:', pls_coefs)
Partial Least Squares Regression MAE: 1.008
Partial Least Squares Regression coefficients: {'lcavol': 0.281, 'lweight': 0.186, 'age': 0.087, 'lbph': 0.101, 'svi': 0.213, 'lcp': 0.187, 'gleason': 0.131, 'pgg45': 0.171}
总结与回顾
由于模型参数的大变化,线性模型具有许多可能相关的特征,在预测精度和模型的可解释性方面失败。这可以通过减少方差来缓解,这种方差只能以引入一些偏差为代价。找到最佳的偏差 - 方差权衡点可以优化模型的性能。
允许实现此目的的两大类方法是子集和收缩。前者选择变量的子集,而后者将模型的系数缩小为零。这两种方法都会降低模型的复杂性,从而导致参数方差的减少。
本文讨论了几种子集和收缩方法:
- 最佳子集回归(BSR)迭代所有可能的特征组合以选择最佳特征组合;
- 岭回归(Ridge Regression)惩罚平方系数值( L2 惩罚),限制权值大小;
- LASSO 惩罚系数的绝对值(L1惩罚),这可以迫使它们中的一些精确为零;
- 弹性网(Elastic Net) 结合了 L1 和 L2 的惩罚,集合了 Ridge 和 Lasso 的优势;
- 最小角度回归(LAR)适用于子集和收缩之间:它迭代地工作,在每个步骤中添加其中一个特征的“某个部分”;
- 主成分回归(PCR)执行PCA将原始特征压缩为一小部分新特征,然后将其用作预测变量;
- 偏最小二乘回归(PLS)也将原始特征概括为较小的新特征子集,但与 PCR 不同,它也利用目标构建它们。
正如您在上面运行代码块时从应用程序看到的前列腺数据,大多数这些方法在预测准确性方面表现相似。前5种方法的误差范围在0.467和0.517之间,略优于最小二乘误差为 0.523。最后两个,PCR 略好,PLS 表现一般,可能是由于数据中没有那么多特征,因此降维的收益是有限的。
参考:
- Hastie,T.,Tibshirani,R。,和Friedman,JH(2009)。统计学习的要素:数据挖掘,推理和预测。第2版。纽约:施普林格。
- https://www.datacamp.com/community/tutorials/tutorial-ridge-lasso-elastic-net
英文原文出自:https://towardsdatascience.com/a-comparison-of-shrinkage-and-selection-methods-for-linear-regression-ee4dd3a71f16