pandas切片操作
在得到数据后,经常需要对数据进行提取、分析和使用,提取数据过程中难免要对数据进行各种切片操作,根据具体的业务需求筛选出所需的数据,pandas提供了一些方法方便我们选取数据,下面主要讲解dataFrame类型的数据选取,Series类型用法类似,可以参考官方文档进行更细致的探究
pandas主要提供了三种属性用来选取行/列数据
| 属性名 | 属性 |
|---|---|
| ix | 根据整数索引或者行标签选取数据 |
| loc | 根据行标签选取数据 |
| iloc | 根据位置的整数索引选取数据 |
这三种属性,既可以让我们获取整行/整列的数据,也可以让我们选取符合标准的行/列数据,但ix这种混用的方式官方已经不再推荐使用,下文的小案例中也不对此例做过多的讲述
具体案例
导入pandas并创建一个4行5列的DataFrame
import pandas as pd
import numpy as np
data = pd.DataFrame(np.arange(20).reshape((4,5)),index=list("ABCD"),columns=list("vwxyz"))
print(data)
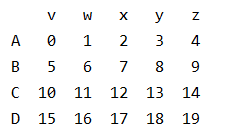
下面对得到的这组数据进行相关的切片操作
1、获取某一行的数据
print(data.iloc[1])
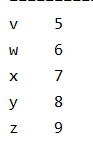
2、获取连续的多行数据
print(data[1:3])
#print(data.head(3))
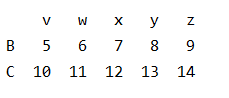
3、获取不连续的多行数据
print(data.iloc[[1,3]])
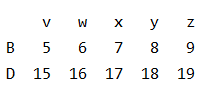
4、获取指定的列的数据
print(data.loc[:,["v","z"]])

5、获取指定的多行多列
print(data.loc[["A","B"],["x","y"]])

6、获取列上某些大于或者小于特定的数
print(data[data['v']>5])
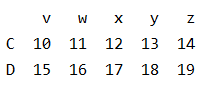
7、为某一列的特定的数据赋值
data[data["v"]<5] = 5

8、求出某一列上的数据是否满足特定的要求
print(data[data["v"].isin([5,15])])

9、统计具体的某一列的平均值
print(data["v"].mean())

10、统计指定的多列的平均值
print(data.loc[:,["v","w"]].mean())

11、统计某一行的平均值
print(data.iloc[1].mean())

11、统计某一列中某个数的出现次数
data[data["v"]<5] = 5
print(data["v"].value_counts())

以上列举了pandas中简单的切片的常用操作,包括几个简单的统计函数,更多的大家可以结合文档进行深入的研究,或者使用的时候查阅具体的API也可,下面结合一个具体的需求对上述的切片操作使用进行说明
需求:统计某个办件表中,各个办件的数量并绘制成柱状图进行展示
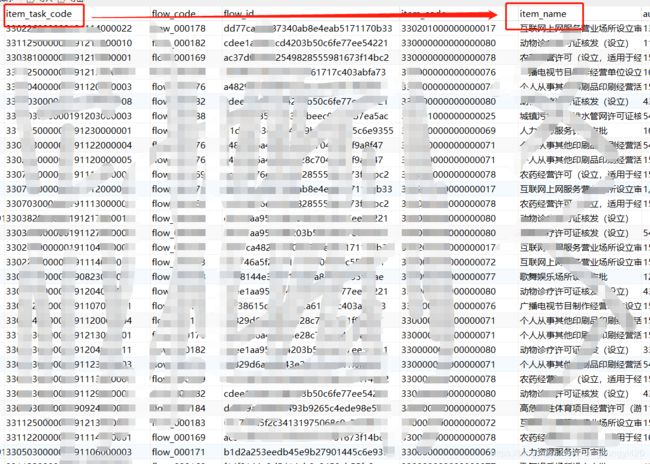
表中的数据结构和字段展示大致如上图,其中只列举了部分字段,其中item_task_code为办件产生的唯一编号,可作为统计的唯一标识,item_name为对应的事项名称,item_task_code为唯一的,即统计不同的事项名的办件数量,我们使用pandas连接mysql来读取这张表,并通过数据提取与切片,并最终绘制柱状图
import pandas as pd
from matplotlib import pyplot as pt
from sqlalchemy import create_engine
#获取mysql查询到的数据
def get_table_data():
sql_info = 'mysql+pymysql://root:123456@localhost:3306/test'
engine = create_engine(sql_info)
# 查询语句,选出employee表中的所有数据
sql = ''' select * from sx_flow_task; '''
# read_sql_query的两个参数: sql语句, 数据库连接
data = pd.read_sql_query(sql, engine)
# 输出employee表的查询结果
print(data)
return data
#处理数据切片并绘制柱状图
def show_pic(data):
# 取出不连续的多列数据
data_tasks = data[["item_task_code", "item_name"]]
# 设置中文显示字体,避免乱码
pt.rcParams['font.sans-serif'] = ['SimHei']
pt.rcParams['axes.unicode_minus'] = False
#获取X轴和Y轴的数据
x_lists = []
y_lists = []
for name in data_tasks["item_name"]:
x_lists.append(name)
x_lists = list(set(x_lists))
sumlists = data_tasks["item_name"].value_counts()
for counts in sumlists:
y_lists.append(counts)
# 设置网格
pt.grid(alpha=0.5)
# 设置每根柱显示的数值
for x, y in enumerate(y_lists):
pt.text(y + 0.2, x - 0.1, '%s' % y)
pt.barh(x_lists, y_lists, color="orange", label="我的办件统计图")
# 设置属性与说明
pt.legend()
pt.xlabel("数量")
pt.ylabel("办件名称")
pt.title("办件数量统计表")
pt.show()
if __name__ == '__main__':
data = get_table_data()
show_pic(data)
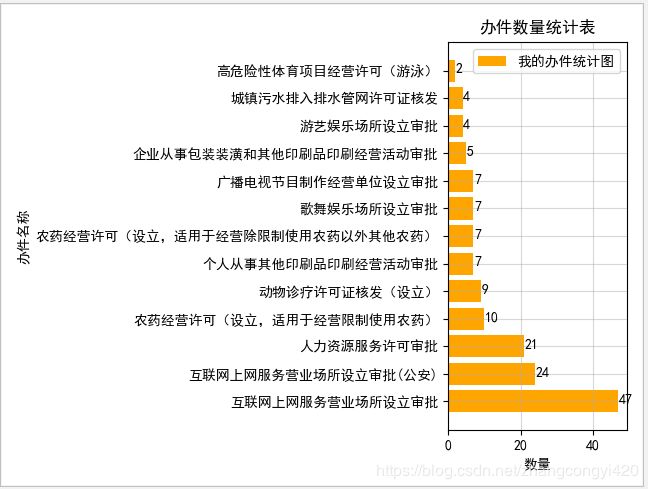
运行代码,最终展示如下效果,可以看到,整个逻辑的代码非常简单,仅仅就是一些切片的操作,可见pandas的切片功能非常强大,使用恰当的话可以大大提升工作效率
本篇的使用就到此结束,最后感谢观看!