最常用的三种哈希算法
散列算法(Hash Algorithm),又称哈希算法,Hash算法能将将任意长度的二进制明文映射为较短的二进制串的算法,并且不同的明文很难映射为相同的Hash值。也可以理解为空间映射函数,是从一个非常大的取值空间映射到一个非常小的取值空间,由于不是一对一的映射,Hash函数转换后不可逆,意思是不可能通过逆操作和Hash值还原出原始的值。
散列方法的主要思想是根据结点的关键码值来确定其存储地址:以关键码值K为自变量,通过一定的函数关系h(K)(称为散列函数),计算出对应的函数值来,把这个值解释为结点的存储地址,将结点存入到此存储单元中。检索时,用同样的方法计算地址,然后到相应的单元里去取要找的结点。通过散列方法可以对结点进行快速检索。散列(hash,也称“哈希”)是一种重要的存储方式,也是一种常见的检索方法。
Hash算法的特点
输入敏感:原始输入信息发生任何变化,新的Hash值都应该出现很大变化。
不可逆性:给定明文和Hash算法,在有限时间和有限资源内能计算得到Hash值。但是给定Hash值,在有限时间内很难逆推出明文。
冲突避免:很难找到两段内容不同的明文,使得它们的Hash值一致。
常用的构造散列函数的方法
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位:
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a?key + b,其中a和b为常数(这种散列函数叫做自身函数)
2. 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3. 平方取中法:取关键字平方后的中间几位作为散列地址。
4. 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。
5. 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
6. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
处理冲突的方法
1. 开放寻址法;Hi=(H(key) + di) MOD m, i=1,2,…, k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列三种取法:
(1) di=1,2,3,…, m-1,称线性探测再散列;
(2)di=1^2, (-1)^2, 2^2,(-2)^2, (3)^2, …, ±(k)^2,(k<=m/2)称二次探测再散列;
(3)di=伪随机数序列,称伪随机探测再散列。 ==
2. 再散列法:Hi=RHi(key), i=1,2,…,k RHi均是不同的散列函数,即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
3. 链地址法(拉链法)
4. 建立一个公共溢出区
常见Hash算法
一致性哈希:对于 K 个关键字和 n 个槽位(分布式系统中的节点)的哈希表,增减槽位后,平均只需对 K/n 个关键字重新映射。
1.硬哈希
分布式系统中,假设有 n 个节点,传统方案使用 mod(key, n) 映射数据和节点。当扩容或缩容时(哪怕只是增减1个节点),映射关系变为 mod(key, n+1) / mod(key, n-1),绝大多数数据的映射关系都会失效。
2.特性
均衡性(Balance):将关键字的哈希地址均匀地分布在地址空间中,使地址空间得到充分利用,这是设计哈希的一个基本特性。
单调性(Monotonicity): 单调性是指当地址空间增大时,通过哈希函数所得到的关键字的哈希地址也能映射的新的地址空间,而不 是仅限于原先的地址空间。或等地址空间减少时,也是只能映射到有效的地址空间中。简单的哈希函数往往不能满足此性质。
分散性(Spread): 哈希经常用在分布式环境中,终端用户通过哈希函数将自己的内容存到不同的缓冲区。此时,终端有可能看不 到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load): 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
3.映射思想描述

把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
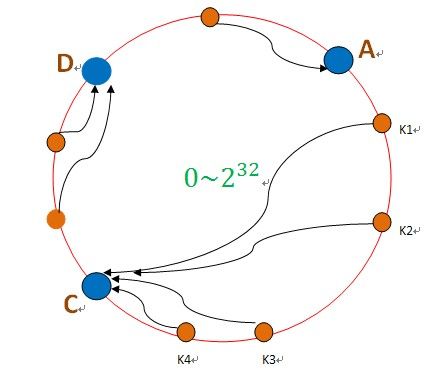
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
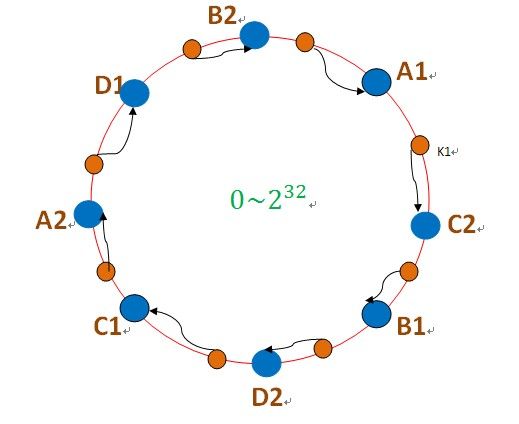
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
4.代码实现
murmurhash3.h
int murmur3_32(const char *key, int len, int seed = 17);murmurhash3.cpp
int murmur3_32(const char *key, int len, int seed)
{
static const int c1 = 0xcc9e2d51;
static const int c2 = 0x1b873593;
static const int r1 = 15;
static const int r2 = 13;
static const int m = 5;
static const int n = 0xe6546b64;
int hash = seed;
const int nblocks = len / 4;
const int *blocks = (const int *)key;
int i;
for (i = 0; i < nblocks; i++)
{
int k = blocks[i];
k *= c1;
k = (k << r1) | (k >> (32 - r1));
k *= c2;
hash ^= k;
hash = ((hash << r2) | (hash >> (32 - r2))) * m + n;
}
const int *tail = (const int *)(key + nblocks * 4);
int k1 = 0;
switch (len & 3)
{
case 3:
k1 ^= tail[2] << 16;
case 2:
k1 ^= tail[1] << 8;
case 1:
k1 ^= tail[0];
k1 *= c1;
k1 = (k1 << r1) | (k1 >> (32 - r1));
k1 *= c2;
hash ^= k1;
}
hash ^= len;
hash ^= (hash >> 16);
hash *= 0x85ebca6b;
hash ^= (hash >> 13);
hash *= 0xc2b2ae35;
hash ^= (hash >> 16);
return hash;
}
main.cpp
#include
#include
MD5
一种可以将任意长度的输入转化为固定长度输出的算法(严格来说不能称之为一种加密算法,但是它可以达到加密的效果)
1.优点
(1)容易计算及不可逆性:
现在主流的编程语言基本都支持MD5算法的实现,所以非常容易计算出一个数据的MD5值。而且MD5算法是不可逆的,也 就是说我们无法通过常规的方式从MD5值倒推出它的原文。
(2)压缩性:
任意长度的数据,其MD5值都是一个32位长度的十六进制字符串,区分大小写(所以要和安卓、服务端商量好是用大写还 是小写)。
(3)抗修改性:
对原数据做一丁点的改动,MD5值就会有巨大的变动。逆反过来理解一下这个特性,比如说两个原数据的MD5值非常相似,但是你不能想当然的认为它们俩对应的原数据也相似。如果你想要很轻易的由MD5倒猜出原文数据是不可能的,因此这个特性在某种程度上表明了MD5算法是安全的。
(4)抗碰撞性:
抗碰撞性分为两种:
第一种,知道了原数据及其MD5值,想要碰撞出这个MD5值,从而猜测出原数据,是非常困难的。这种碰撞的难度表明的 是,强制破解MD5算法是非常困难的,更别说上面的轻易倒推了。
第二种,我们知道MD5值总是一个32位的十六进制字符串,换算成二进制就是一个128位的字符串,因此所有的MD5值一共有2的128次方种可能性这种碰撞的难度表明的是,我们可以放心的去使用MD5算法,不必担心不同的数据拥有相同的MD5值。依照现在计算机的计算能力,碰撞被认为在实际中是不可能发生的。因此,这个特性也在某种程度上表明了MD5算法的安全性。
2.缺点:中国山东大学的王小云教授以及她的同事在美国加州举办的密码学会议上宣布破解了MD5算法,也就是在较短时间发现碰撞,以在对安全性要求较高的场合,不建议直接使用MD5算法。
3.MD5算法的应用场景
(1)登录、注册、修改密码等简单加密操作(设计彩虹表,加盐等名词)
(2)生成数字签名
SHA1
SHA-1算法和MD5算法都有MD4算法导出,因此他们俩的特点、缺陷、应用场景基本是相同的。它俩的区别在于SHA-1算法在长度上是40位十六进制,即160位的二进制,而MD5算法是32位的十六进制,即128位的二进制,所以2的160次是远远超过2的128次这个数量级的,所以SHA-1算法相对来说要比MD5算法更安全一些。