linux内核编程--4netfiter钩子函数
1. 背景
京东金融资深C/C++开发工程师 岗位被面试到,本来在《深入linux内核架构》一书中见过,但由于整本书看的不是很懂,也没实验,当时吱吱唔唔的回答了,答案不是很理想。后来也就没有了后来······
2. 概述
netfilter是自2.4内核的一个数据包过滤框架。可以过滤数据包,网络地址和端口转换(nat和napt技术),以及其他操作数据包的功能。主要工作原理是在内核模块注册回调函数(hook函数)到内核,内核执行到相关点时会触发这个回调函数,然后根据回调函数里的逻辑,对包含网络协议栈的sk_buff结构进行操作(丢失、修改等)。
iptables的内核模块就是使用的netfilter。
3. 相关API与数据结构
int nf_register_hook(struct nf_hook_ops *reg); --------------注册钩子函数
void nf_unregister_hook(struct nf_hook_ops *reg); ----------去注册钩子函数
struct nf_hook_ops { ----------钩子点结构体
struct list_head list; /* 标准链表—由于链接所有钩子点 */
/* User fills in from here down. */
nf_hookfn *hook; /* 钩子函数回调指针 */
struct net_device *dev; /* 网络设备指针 */
void *priv; /* 私有数据----在钩子回调函数中使用 */
u_int8_t pf; /* 协议族 */
unsigned int hooknum; /* hook点 */
/* Hooks are ordered in ascending priority. */
int priority; /* 优先级 */
};其他API请参考文件:
4. 原理
4.1 内核hook点
linux网络协议栈中有5个hook点,其报文处理流程如下:
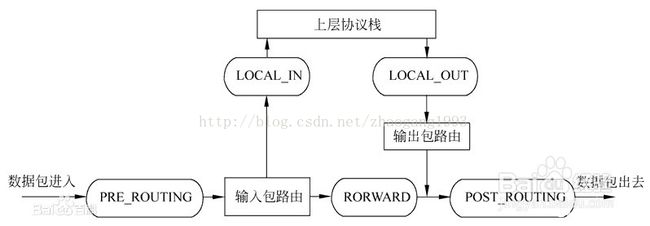
对应内核源码
/* Bridge Hooks */
/* After promisc drops, checksum checks. */------网卡混杂丢包和校验和检查之后(所有进入协议栈的数据包都会经过PRE_ROUTING)
#define NF_BR_PRE_ROUTING 0
/* If the packet is destined for this box. */------经过路由判决,确定发往本机
#define NF_BR_LOCAL_IN 1
/* If the packet is destined for another interface. */--------经过路由判决,不是发往本机,需要从其他接口转发出去
#define NF_BR_FORWARD 2
/* Packets coming from a local process. */--------由本机外发出去的报文路径
#define NF_BR_LOCAL_OUT 3
/* Packets about to hit the wire. */--------所有数据包离开本机前的路径
#define NF_BR_POST_ROUTING 4
/* Not really a hook, but used for the ebtables broute table */-------非hook点,用于其他目的
#define NF_BR_BROUTING 5
#define NF_BR_NUMHOOKS 6
4.2 内核支持的钩子协议
源码:
enum {
NFPROTO_UNSPEC = 0,
NFPROTO_INET = 1,
NFPROTO_IPV4 = 2,
NFPROTO_ARP = 3,
NFPROTO_NETDEV = 5,
NFPROTO_BRIDGE = 7,
NFPROTO_IPV6 = 10,
NFPROTO_DECNET = 12,
NFPROTO_NUMPROTO,
};4.3 钩子函数注册/去注册
源码:
int nf_register_hook(struct nf_hook_ops *reg) ----------------注册钩子函数
{
struct net *net, *last;
int ret;
rtnl_lock();
for_each_net(net) { -------------------遍历所有网络命名空间(虚拟化技术)
ret = nf_register_net_hook(net, reg); ---------注册钩子函数
if (ret && ret != -ENOENT)
goto rollback;
}
list_add_tail(®->list, &nf_hook_list);
rtnl_unlock();
return 0;
rollback:
last = net;
for_each_net(net) {
if (net == last)
break;
nf_unregister_net_hook(net, reg);
}
rtnl_unlock();
return ret;
}
int nf_register_net_hook(struct net *net, const struct nf_hook_ops *reg)
{
struct list_head *hook_list;
struct nf_hook_entry *entry;
struct nf_hook_ops *elem;
entry = kmalloc(sizeof(*entry), GFP_KERNEL);
if (!entry)
return -ENOMEM;
entry->orig_ops = reg;
entry->ops = *reg;
hook_list = nf_find_hook_list(net, reg); -------内部根据钩子节点协议和钩子点找到二维数组对应的链表头
if (!hook_list) {
kfree(entry);
return -ENOENT;
}
mutex_lock(&nf_hook_mutex);
list_for_each_entry(elem, hook_list, list) { -------------按照优先级插入到链表
if (reg->priority < elem->priority)
break;
}
list_add_rcu(&entry->ops.list, elem->list.prev);
mutex_unlock(&nf_hook_mutex);
#ifdef CONFIG_NETFILTER_INGRESS
if (reg->pf == NFPROTO_NETDEV && reg->hooknum == NF_NETDEV_INGRESS)
net_inc_ingress_queue();
#endif
#ifdef HAVE_JUMP_LABEL
static_key_slow_inc(&nf_hooks_needed[reg->pf][reg->hooknum]);
#endif
return 0;
}原理:
1. 内核将遍历网络命名空间链,为每个net命名空间挂接钩子节点。那我们疑问:每个命名空间的钩子点在内核中是怎么组织的呢?查看源码后我们知道struct net结构中有专门挂接netfilter钩子结构的成员struct netns_nf nf;
struct net {
…
#ifdef CONFIG_NETFILTER
struct netns_nf nf; ---------netfilter结构
…
};struct netns_nf {
...
struct list_head hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS]; -----------二维数组钩子链表
};函数nf_find_hook_list就是根据我们将要挂接的钩子节点找对其对应的挂接位置,其结构图如下:

即:内核将每个协议的所有5个钩子组成二维数组链,每次要挂接一个钩子节点,则根据协议/钩子类型找到对应的挂接链,然后根据优先级(优先级值越小,优先级越高)将钩子节点插入链表中,完成挂接。
4.4 钩子回调函数
原型:
typedef unsigned int nf_hookfn(void *priv,struct sk_buff *skb,const struct nf_hook_state *state);每监控到一条数据包,就会调用一次回调函数,数据包信息存储在sk_buff结构中,参考sk_buff相关介绍。这个函数的返回值决定了函数结束后此数据包的走向,有如下几种返回值:
/* Responses from hook functions. */
#define NF_DROP 0 ----丢弃,释放sk_buff结构
#define NF_ACCEPT 1 ----继续正常传输数据报(按照5个钩子点正常传输)
#define NF_STOLEN 2 ----模块接管该数据报,告诉Netfilter“忘掉”该数据报。该回调函数将从此开始对数据包的处理,并且Netfilter应当放弃对该数据包做任何的处理。但是,这并不意味着该数据包的资源已经被释放。这个数据包以及它独自的sk_buff数据结构仍然有效,只是回调函数从Netfilter获取了该数据包的所有权。
#define NF_QUEUE 3 ----对该数据报进行排队(通常用于将数据报给用户空间的进程进行处理)
#define NF_REPEAT 4 ----再次调用该回调函数,应当谨慎使用这个值,以免造成死循环
#define NF_STOP 5 ----终止hook链处理,不会释放sk_buff数据5 测试
我们开发一个模块程序,用于监控内核收到的特定的ICMP报文(可以由其他主机ping而产生),每匹配到一个报文,则用printk打印一条信息,然后用dmesg查看。
源码(非完整模块代码,不清楚如何编译成模块请阅读笔者之前的文章):
/* IP地址转字符串 */
STATIC void IP2Str(char *ipaddr, int size, uint32_t ip)
{
snprintf(ipaddr, size, "%d.%d.%d.%d", ( ip >> 24 ) & 0xff
, ( ip >> 16 ) & 0xff
, ( ip >> 8 ) & 0xff
, ip & 0xff);
return;
}
/* 钩子回调函数 */
STATIC UINT myHookCallBack(void *priv, struct sk_buff *skb, const struct nf_hook_state *state)
{
struct iphdr *pstIpHdr = NULL;
CHAR szIpstr[BUF_LEN_20] = {0,};
if (unlikely(NULL == skb))
{
return NF_ACCEPT;
}
pstIpHdr = ip_hdr(skb);
if (unlikely(NULL == pstIpHdr))
{
return NF_ACCEPT;
}
if (pstIpHdr->protocol != IPPROTO_ICMP)
{
return NF_ACCEPT;
}
/* 网络序转主机序,然后转成字符串 */
IP2Str(szIpstr, sizeof(szIpstr), ntohl(pstIpHdr->saddr));
if (0 == strcmp(szIpstr, "192.168.1.7")) /* 字符串比较 */
{
printk(KERN_INFO "Recv icmp packet from 192.168.1.7\n"); /* printk打印 */
}
return NF_ACCEPT;
}
struct nf_hook_ops g_stMyNfHook =
{
.hook = myHookCallBack,
.pf = NFPROTO_IPV4,
.hooknum = NF_BR_PRE_ROUTING,
.priority = NF_IP_PRI_FIRST,
};
STATIC VOID hello_NfHook_Init(VOID)
{
INT iRet;
iRet = nf_register_hook(&g_stMyNfHook); /* 注册 */
if (0 != iRet)
{
printk(KERN_WARNING "nf_register_hook failed\n");
return;
}
return;
}
STATIC VOID hello_NfHook_Fini(VOID)
{
nf_unregister_hook(&g_stMyNfHook); /* 去注册 */
return;
}测试结果:(linux内核版本: 4.4.0-21)
说明:笔者模拟公司办公环境搭建有两台电脑 linux(192.168.1.6) ------ windows(192.168.1.7) ,用windows ping linux主机,有如下结果。-----结果表明,钩子函数测试完全正确。
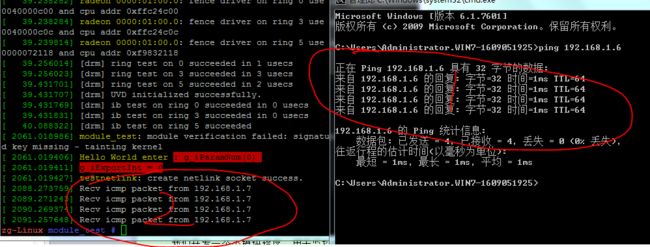
参考:
http://blog.csdn.net/wuruixn/article/details/7957368
http://blog.csdn.net/stone8761/article/details/72821733