Logstash配置插件grok详解
Logstash配置插件grok详解
grok是Logstash最重要的插件之一,用于将非结构化数据解析为结构化和可查询的数据。即将一个key对应的一长串非结构化的value,转成多个结构化的key-value。
非结构化数据
[2019-09-23 08:13:13,504] {base_task_runner.py:95} INFO - Subtask: [2019-09-23 08:13:13,503] {bash_operator.py:81} INFO - Running command: sh /opt/bi/shell/etl_job.sh --job_id=1140
从数据分析的角度:非结构化数据不便于检索、统计、分析。
非结构化数据变成结构化数据后才有检索、统计、分析的价值。
grok正则
grok正则主要有两部分:
- grok的默认表达式。grok预定义好的一些表达式,可以匹配常见的字符串。
Grok的默认表达式
[logstash安装路径]\logstash-7.3.2\vendor\bundle\jruby\2.5.0\gems\logstash-patterns-core-4.1.2\patterns
- 自定义grok表达式
默认表达式
grok filter 插件官方文档:https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
grok模式的语法:%{SYNTAX:SEMANTIC}
SYNTAX代表匹配值类型,SEMANTIC代表赋值字段名称。
例如:127.0.0.0:9200可以使用IP类型匹配,%{IP:client}
age是24,可以用NUMBER类型匹配,%{NUMBER:age}
默认情况下,所有语义都保存为字符串,希望转换语义的数据类型,例如将字符串更改为整数,则将其后缀为目标数据类型。例如:%{NUMBER:age:int},将age语义从一个字符串转换为一个整数。
例一:

例二:
使用grok pattern从日志中抽出有用的字段:
%{IP:client} %{WORD:method} %{URIPATHPARAM : request} %{NUMBER : bytes} %{NUMBER:duration}
在logstash.conf中添加过滤器配置:
input {
stdin{
}
}
filter {
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
}
output {
stdout { codec => rubydebug}
}
输入:
127.0.0.1 GET /index.html 5000 0.2
输出:
{
"@version" => "1",
"host" => "LW7CNENJEDRD183",
"message" => "127.0.0.1 GET /index.html 5000 0.2\r",
"client" => "127.0.0.1",
"method" => "GET",
"request" => "/index.html",
"bytes" => "5000",
"duration" => "0.2",
"@timestamp" => 2019-09-24T07:53:18.205Z
}
grok预定义好的匹配模式
- DATA
相当于正则的.*?,匹配除\n以外的任何字符,*相当于0-正无
穷,?为懒惰模式,匹配到第一个就结束
DATA .*?
- USERNAME或USER
用户名,由数字、字母、及特殊字符(._-)组成的字符串,比如1234、Tom.Y
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
- EMAILLOCALPART
电子邮件用户名部分,首位由大小写字母组成,其他位由数字、大小写及特殊字符(.+-=:)组成的字符串。比如fy123、jx_1
[a-zA-Z][a-zA-Z0-9_.+-=:]+
- EMAILADDRESS
电子邮件,比如fy123@mail.com
%{EMAILLOCALPART}@%{HOSTNAME}
- INT
整数,包括0和正负整数,比如0、-123
(?:[±]?(?:[0-9]+))
- **BASE10NUM或NUMBER**
```javascript
十进制数字,包括整数和小数,比如0、3.2
(?[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
- BASE16NUM
十六进制数字,整数
(?<![0-9A-Fa-f])(?:[+-]?(?:0x)?(?:[0-9A-Fa-f]+))
- BASE16FLOAT
十六进制数字,整数和小数
\b(?<![0-9A-Fa-f.])(?:[+-]?(?:0x)?(?:(?:[0-9A-Fa-f]+(?:\.[0-9A-Fa-f]*)?)|(?:\.[0-9A-Fa-f]+)))\b
- WORD
匹配字符串,包括数字和大小写字母
\b\w+\b

- NOTSPACE
不带任何空格的字符串
\S+

- SPACE
空格字符串
\s*

- QUOTEDSTRING
带引号的字符串
(?>(?<!\\)(?>"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>`(?>\\.|[^\\`]+)+`)|``))
\s*

- UUID
标准UUID
[A-Fa-f0-9]{8}-(?:[A-Fa-f0-9]{4}-){3}[A-Fa-f0-9]{12}
- MAC
MAC地址
(?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC})
- IP
IP地址,IPV4或IPV6地址
- HOSTNAME
主机名称
\b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)

- IPORHOST
IP或者主机名称,比如:127.0.0.1:9200
localhost:9200
IPORHOST (?:%{IP}|%{HOSTNAME})

- PATH
路径
(?:%{UNIXPATH}|%{WINPATH})

- URIPROTO
URI协议,比如http、ftp等
[A-Za-z]([A-Za-z0-9+\-.]+)+

- URIHOST
URI主机,10.0.0.1:20,www.zhangfei.com
%{IPORHOST}(?::%{POSINT:port})?

- URIPATH
URI路径

- URIPARAM
URI里的GET参数,比如?a=1&b=2
\?(?:[A-Za-z0-9]+(?:=(?:[^&]*))?(?:&(?:[A-Za-z0-9]+(?:=(?:[^&]*))?)?)*)?

- URIPATHPARAM
URI路径+GET参数

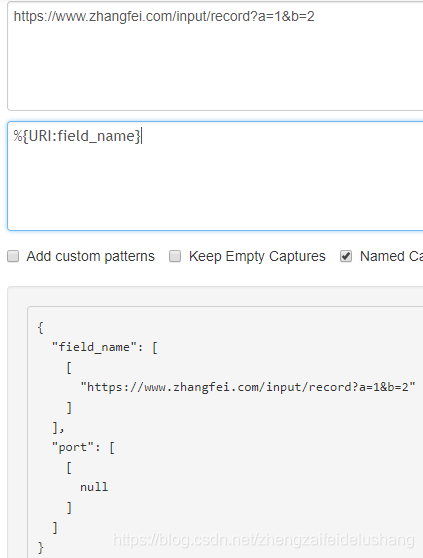
- URI
完整的URI
```
#### 日期时间表达式
- **MONTH**
```javascript
月份名称,比如Jan、January
\b(?:[Jj]an(?:uary|uar)?|[Ff]eb(?:ruary|ruar)?|[Mm](?:a|ä)?r(?:ch|z)?|[Aa]pr(?:il)?|[Mm]a(?:y|i)?|[Jj]un(?:e|i)?|[Jj]ul(?:y)?|[Aa]ug(?:ust)?|[Ss]ep(?:tember)?|[Oo](?:c|k)?t(?:ober)?|[Nn]ov(?:ember)?|[Dd]e(?:c|z)(?:ember)?)\b
- MONTHNUM
月份数字,比如06、10
(?:0?[1-9]|1[0-2])
- MONTHDAY
日期数字,比如20
(?:0?[1-9]|1[0-2])
- DAY
星期几名称,比如:Mon、Monday
(?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?)
- YEAR
年份数字
- HOUR
小时数字
- MINUTE
分钟数字
- SECOND
秒数字
- TIME
时间,比如00:09:20
(?!<[0-9])%{HOUR}:%{MINUTE}(?::%{SECOND})(?![0-9])
- DATE_US
美国日期格式,比如:9-24-2019、9/24/2019
- ISO8601_TIMEZONE
ISO8601时间格式,比如+10:30
(?:Z|[+-]%{HOUR}(?::?%{MINUTE}))
- TIMESTAMP_ISO8601
ISO8601时间戳格式,比如2019-09-24T01:30:12+08:00
%{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?
- DATE
日期,美国日期
- DATESTAMP
完整日期+时间,比如09-24-2019 13:40:30
%{DATE}[- ]%{TIME}
- HTTPDATE
http默认日期格式,比如24/Sep/2019:13:52:30 +0800
%{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
Log表达式
- LOGLEVEL
日志等级,比如:Error、WARN、INFO等
([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
自定义grok表达式
grok自定义正则语法:(?pattern)
field_name是匹配的字段名,pattern是要匹配的模式
例一:
(?

例二:

input {
stdin{
}
}
filter {
grok{
#筛选过滤
match => {
"message" => "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3}),(?[A-Z]{4,5}),(?[A-Za-z0-9/-]{4,40}),(?[A-Za-z0-9/.]{4,40}),(?\d+),(?.*)"
}
}
}
output {
stdout { codec => rubydebug}
}
输入:
1111-22-22 22:22:22,333,AAAA,http-nio-8080-exec-1,com.hh.test.logs.LogsApplication,200,测试录入错误日志,param:java.lang.ArithmeticException: / by zero
输出:
(?<date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3}),(?<level>[A-Z]{4,5}),(?<thread>[A-Za-z0-9/-]{4,40}),(?<class>[A-Za-z0-9/.]{4,40}),(?<code>\d+),(?<msg>.*)
grok模式调试方法
Logstash提供多种内置多模式,用于解析非结构化数据,例如apache、linux、aws等
grok patterns地址:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
可以在grokdebug这个网站上调试自定义的grok模式,grokdebug网站地址:
https://grokdebug.herokuapp.com/
正则表达式中文学习网站:
http://www.runoob.com/regexp/regexp-tutorial.html
自定义grok模式步骤:
- 步骤1:进入grokdebug中的discover选项,自动生成grok模式

- 步骤2:步骤一没有生成grok模式,可以参考Logstash在github上的内置模式语法,利用grok debugger上构建模式。


从而得到grok模式为:
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
patterns_dir:
值类型是数组,作用:用来指定正则表达式的匹配路径,如果使用logstash自定义的规则时,不需要写此参数。patterns_dir可以同时制定多个存放过滤规则的目录。需要注意的是该文件夹中所有文件中的正则表达式都会被依次加载,包括备份文件。
patterns_dir => ["D:\input\patterns","D:\input\extra_patterns"]
正则表达式文件以文本格式描述:
#空格前是正则表达式的名称,空格后是具体的正则表达式
NAME PATTERN
###### patterns_definitions
值类型是数组,默认值是{},用于定义当前过滤器使用的自定义模式。匹配现有名称的模式将覆盖预先存在的定义。
filter {
grok {
match => {
"message" => "%{SERVICE:service}"
}
pattern_definitions => {
"SERVICE" => "[a-z0-9]{10,11}"
}
}
}
match
作用:值类型是数组,默认值是{}
filter {
grok { match => {"message" => "Duration: %NUMBER:duration"} }
}
overwrite
作用:覆盖字段内容,值类型是array,默认是[]
filter {
grok{
match => {"message" => "%{SYSLOGBASE} %{DATA:message}"}
overwrite => ["message"]
}
}
常用选项
所有过滤器插件都支持以下配置选项:
add_field
作用:在匹配日志中增加一个field,可以通过%{field}动态命名field名或field值。也可以一次性添加多个字段。
filter {
grok{
add_field => {"foo_%{somefield}" => "Hello world, from %{host}"}
"new_field" => "zhangfei"
}
}
add_tag
作用:过滤器成功,向该事件添加任意标签。标签可以是动态的,并使用%{field}语法包含事件的一部分。也可以一次性添加多个标签。值类型是数组,默认值是[]。
filter {
grok{
add_tag => ["arr_%{somefield}","airflow"]
}
}
id
作用:向插件实例添加唯一ID,此ID用于跟踪特定配置的信息。
filter {
grok{
id => “ABC”
}
}
remove_field
作用:删除当前文档中的指定字段,值的类型是array,默认值是数组。也可以一次移除多个字段。
filter {
grok{
remove_field => ["foo_%{somefield}","error"]
}
}
remove_tag
作用:过滤器成功,从该事件中移除任意标签,标签可以是动态的,并使用%{field}语法包含事件的一部分。也可以一次删除多个标签。
filter {
grok{
remove_tag => ["foo_%{somefield}","airflow"]
}
}