scrapy爬虫框架中数据库(mysql)的异步写入
数据库的异步写入
scrapy爬虫框架里数据库的异步写入与同步写入在代码上的区别也就在pipelines.py文件和settings.py文件的区别,其他的都是一样的。本文就介绍一下pipelines.py和settings.py文件里面是如何配置的。
点击此处查看同步写入
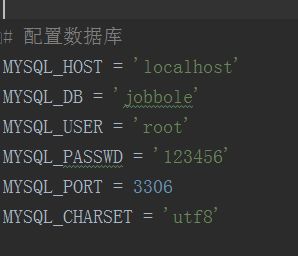
1、先到settings.py文件里面配置数据库的相关字段
2、先在pipelines.py文件里面导入相关模块
import pymysql
from scrapy.pipelines.images import ImagesPipeline
# twisted: 用于异步写入(包含数据库)的框架,cursor.execute()是同步写入
from twisted.enterprise import adbapi
3、数据库写入部分代码如下:
要在from_settings这个类方法里面写上加载配置数据的代码
然后创建一个数据库连接池对象,里面可以包含多个connect连接对象
class MySQLTwistedPipeline(object):
def __init__(self, pool):
self.dbpool = pool
@classmethod
def from_settings(cls, settings):
"""
这个函数名称是固定的,当爬虫启动的时候,scrapy会自动调用这些函数,加载配置数据。
:param settings:
:return:
"""
params = dict(
host=settings['MYSQL_HOST'],
port=settings['MYSQL_PORT'],
db=settings['MYSQL_DB'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWD'],
charset=settings['MYSQL_CHARSET'],
cursorclass=pymysql.cursors.DictCursor
)
# 创建一个数据库连接池对象,这个连接池中可以包含多个connect连接对象。
# 参数1:操作数据库的包名
# 参数2:链接数据库的参数
db_connect_pool = adbapi.ConnectionPool('pymysql', **params)
# 初始化这个类的对象
obj = cls(db_connect_pool)
return obj
def process_item(self, item, spider):
"""
在连接池中,开始执行数据的多线程写入操作。
:param item:
:param spider:
:return:
"""
# 参数1:在线程中被执行的sql语句
# 参数2:要保存的数据
result = self.dbpool.runInteraction(self.insert, item)
# 给result绑定一个回调函数,用于监听错误信息
result.addErrback(self.error)
def error(self, reason):
print('--------', reason)
# 线面这两步分别是数据库的插入语句,以及执行插入语句。这里把插入的数据和sql语句分开写了,跟何在一起写效果是一样的
def insert(self, cursor, item):
insert_sql = "INSERT INTO bole(bole_title, bole_date, bole_tag, bole_content, bole_dz, bole_sc, bole_pl, bole_img_src) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
cursor.execute(insert_sql, (item['bole_title'], item['bole_date'], item['bole_tag'], item['bole_content'], item['bole_dz'], item['bole_sc'], item['bole_pl'], item['bole_img_path']))
# 不需要commit()
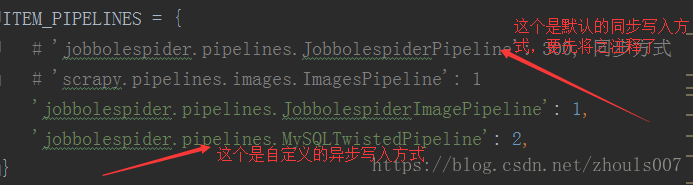
4、也就是最后一步了,在settings.py文件里面,先将系统默认的同步写入的方式给注释了,然后再写入自己自定义的异步写入方式,不然pipeline.py文件里面写的异步写入就执行不了了