文本分类与SVM
之前做过一些文本挖掘的项目,比如网页分类、微博情感分析、用户评论挖掘,也曾经将libsvm进行包装,写了一个文本分类的开软软件Tmsvm。所以这里将之前做过一些关于文本分类的东西整理总结一下。
1 基础知识
1. 1 样本整理
如下面的整理的样本,1为正类,-1为反类(为了能便于展示,这里使用了一些即时聊天工具中的文本,里面的一些对话都是YY,并非真实的)。
表 1.1‑1 一个训练样本的例子
| 标签 |
样本 |
| 1 |
如要购买商品的请加我qq61517891联系我购买! |
| 1 |
联系qq1121107282 |
| 1 |
你好需要订购请加扣扣 |
| -1 |
索尼爱立信手机的体验是一个月吗 |
| -1 |
不好意思这个价钱最便宜了 |
| -1 |
3件的那个他是高价在卖 |
1.2 特征选择
文本分类中最著名的特征提取方法就是向量空间模型(VSM),即将样本转换为向量的形式。为了能实现这种转换,需要做两个工作:确定特征集和提取特征。
1.2.1 确定特征集
特征集其实就是词典,而且还需要给每个词设定一个编号。
一般可以将所有样本的词都提取出来作为词典,而词典的编号可以随意设置,默认情况下,所有词的权重都是等同的。如何从样本中提取出一个个意义的词呢?最常用的方法就是使用分词工具,比如“如要购买商品的请加我qq61517891联系我购买!”,可以分成“如^要^购买^商品^的^请^加^我^qq61517891^联系^我^购买^!”,其中“^”是用来分割词的。现在比较常见的分词工具有ICTCLAS(C++),Iksegment(Java)。
下图是一个典型的生成词典的流程图。

图 1.1‑1 从样本中提取词典流程图
1.2.2 特征选择
根据不同的业务,文本分类中词典的规模在万级到千万级甚至亿级。而这么大的维度可能会带来维度灾难,因此就要想办法从大量的特征中选择一些有代表性的特征而又不影响分类的效果(而根据文献中的结果,特征选择可以在一定程度上提高分类的效果)。特征选择就是从特征集中选择一些代表性的词。而如何衡量词的代表性呢?一般的计算方法有词频、卡方公式、信息增益等。当前文献中一致认为比较好的方法是卡方公式。
下面几个链接是几篇写的比较详细介绍如何进行特征选择的文章
1. http://www.blogjava.net/zhenandaci/archive/2009/04/19/266388.html 特征选择与特征权重计算的区别
2. http://www.blogjava.net/zhenandaci/archive/2009/03/24/261701.html 特征选择方法之信息增益
3. http://www.blogjava.net/zhenandaci/archive/2008/08/31/225966.html 特征选择算法之开方检验
1.2.3 特征抽取
另外一种解决维度灾难的思路就是特征抽取。同样是降维,相比特征选择,特征抽取采用了一种高级的方法来进行。Topic Modeling是原理就是将利用映射将高纬度空间映射到低纬空间,从而达到降维的目的。具体可以见2.1特征抽取部分
1.3 计算特征权重
给定一个样本,如何转换成向量呢?
首先给一张流程图:

图 1.1‑2 计算特征权重的流程
流程:
1)首先,对样本进行分词,提取出所有的词。
2)根据已经生成的词典,如果词典中的词出现,就在相应对应的位置填入该词的词频。
3)对生成的向量进行归一化
上面的所示的方法是比较简单的一种,其中特征权重采用的为词频来表示,现在比较常用的特征权重的计算方式为TF*IDF,TF*RF。详见2.3 特征权重
1.4 模型训练与预测
当把文本转换成向量的形式后,大部分的工作其实已经做完了。后面所要做的就是利用算法进行训练和预测了。
现在文本分类的算法很多,常见的有Naïve Bayes,SVM,KNN,Logistic回归等。其中SVM据文献中说是在工业界和学术界通吃的,不过据我了解现在公司里用SVM来做分类的不多 = =,而Logistic回归则是比较常用的,因为相对来说简单,而且可以并行化训练。最重要是简单可依赖。
而至于这些算法具体是什么我这里也不再累述了,因为网络上介绍相关的算法的文献很多,而且源程序也很多。可以直接下来下来使用。
资料与程序
1. http://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-classification-1.html介绍NaïveBayes方法如何应用在文本分类上
2. http://blog.163.com/jiayouweijiewj@126/blog/static/17123217720113115027394/ 详细分析了Mahout中如何实现NaïveBayes
3. http://www.csie.ntu.edu.tw/~cjlin/libsvm/ Libsvm是用来进行SVM训练与预测的开源工具。下载下来就可以直接用,作者的文档写的很详细。
4. http://www.blogjava.net/zhenandaci/category/31868.htmlSVM的八股介绍,讲解的还是通俗易懂的
5. http://blog.pluskid.org/?page_id=683 介绍支持向量机的
6. https://code.google.com/p/tmsvm/ Tmsvm是我之前写的利用svm进行文本分类的程序,涉及到文本分类的所有流程。
1.5 进一步阅读:
文本分类的技术已经被研究了很多年,所以相关的资料也是非常多,可以进一步阅读下面的一些资料
1. http://www.blogjava.net/zhenandaci/category/31868.html?Show=All 这里有一个文本分类的入门系列,介绍的还是比较详细的。
2. 《文本挖掘中若干关键问题研究》,这本书很薄,但是写的很深入,对文本挖掘的一些重点问题进行了讨论
2 若干问题的讨论
2.1 特征选择
特征选择是就是依据某种权重计算公式从词典中选择一些有代表性的词。常用的特征选择的方法有很多种,Chi、Mutual Information、Information Gain。另外TF、IDF也可以作为特征选择的一种方法。在这个问题上很多人做了大量的实验,Chi方法是效果最好的一种,所以本系统(指的是TMSVM)中采用了这种方法。关于特征选择无论是Wikipedia还是Paper中都有很细致的讲解。
2.2 特征抽取
特征抽取和特征选择都是为了降维。特征选择的方法是从词典中选出一些有代表性的词,而特征抽取是利用映射将高纬度空间映射到低纬空间,从而达到降维的目的。最常见的特征抽取的方法是Latent Semantic Analysis(潜在语义分析),其中LSA也被称作Topic Modeling,比较常用的Topic Modeling的方法有LSA、PLSA、LDA。之前使用的方法LSA。
假设原来的词-文档矩阵为,即有m个term,n篇文档。表示第j篇文档的向量。,经过SVD分解后,选择前k个特征值后。再去重组文档的特征向量,,这样新的文档特征向量就由原来的m维降至k维。而一个新的文档即可通过,映射到U空间上。其实还有另外一种方法,就是,但是在实验中发现,前一种映射效果会更好一点。另外wikipedia上对LSA也有很详细的阐述
本系统将LSA用来Classification上的方法是一种叫做local relevancy weighted LSI的方法。其主要步骤为
* 模型训练
① 训练初始分类器C0
② 对训练样本预测,生成初始分值
③ 文档特征向量变换
④ 设定阈值,选择top n文档作为局部LSA区域
⑤ 对局部词/文档 矩阵做SVD分解。得到U、S、V矩阵
⑥ 将其他的训练样本映射到U空间中
⑦ 对所有经过变换后的训练样本进行训练,得到LSA分类器
* 模型预测
① 利用C0预测得到其初始分值
② 文档特征向量变换
③ 映射到U空间
④ 利用LSA模型进行预测得分
2.3 特征权重计算
文档特征向量的特征权重计算的一般公式为,即第i个term在第j篇文档向量中的权重。其中Local(i,j)被称为局部因子,与term在文档中出现的次数有关。global(i)又称为term的全局因子,与在整个训练集中term出现有关。通常我们熟悉的公式都可以转化为这一个通用的表达式。如最常用的tf形式,tf*idf形式。因此我们就可以在构造词典的时候就计算term的全局因子,把这个值放在词典中,然后在计算特征权重的时候直接调用。
具体的流程图如下:
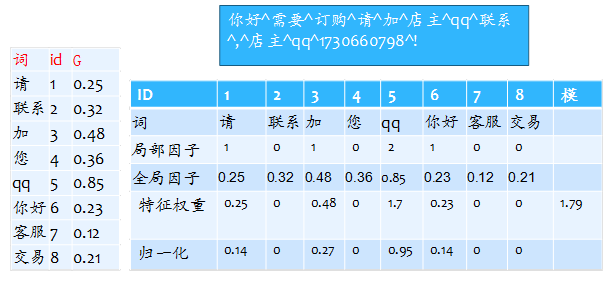
图 2.3‑1 特征权重的计算流程
在Classification中哪种特征权重的计算方式最好??tf*idf ?在文献中最常用的是tf*idf,但是其效果并一定好。曾经有人也在这上面做了一些工作,比如新加坡国立大学的Man Lan曾在ACM和AAAI上发表过文章来阐述这个问题。Zhi-Hong Deng也对各种feature weight的方法做了系统的比较,最终的结论是tf*idf并不是最佳的,而最简单的tf表现不错,一些具有区分性的方法比如tf*chi等效果差强人意。
后来Man Lan在09年发表了一篇论文,对term weighting方法做了一个综合细致的阐述,并对其提出的tf*rf方法做了各方面的论证。
2.4 TSVM的模型训练和预测流程
训练过程:对文本自动做SVM模型的训练。包括Libsvm、Liblinear包的选择,分词,词典生成,特征选择,SVM参数的选优,SVM模型的训练等都可以一步完成。示意图见下面
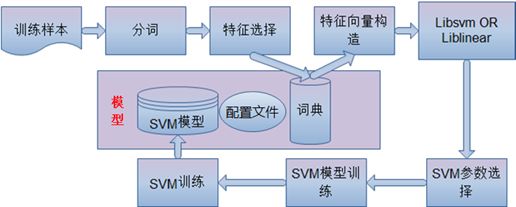
图 2.4‑1 TMSVM模型训练流程
模型预测过程:

图 2.4‑2 多个模型同时预测流程
模型结果:
模型会返回两个结果:label和score,其中label即其预测的标签。而score是该样本属于该类的隶属度,分值越大,代表属于该类的置信度越大。具体的计算方式则是根据公式,,其中k为所有支持判别类得个数,n为所有类别个数,si 为所有支持判别类的分数。返回score的好处是对与information filtering问题,因为训练样本的unbalance和randomly sampling 问题,依据判别的标签得到的结果准确率较低,因此需要通过阈值控制。
2.5 SVM参数选择
Libsvm中最重要的两个参数为C和gamma。C是惩罚系数,即对误差的宽容度。c越高,说明越不能容忍出现误差。C过大或过小,泛化能力变差。gamma是选择RBF函数作为kernel后,该函数自带的一个参数。隐含地决定了数据映射到新的特征空间后的分布,gamma越大,支持向量越少,gamma值越小,支持向量越多。支持向量的个数影响训练与预测的速度。这个问题Chih-Jen Lin在其主页上有详细的介绍。
而Liblinear的C参数也是非常重要的。
因此在系统中会通过5-flods交叉验证的方法对一定范围内的C,gamma进行grid 搜索,关于grid搜索可以参考论文以及libsvm中tool文件夹中grid.py源文件。grid搜索是可以得到全局最优的参数的。
为了加快SVM参数搜索的效率,采用两种粒度的搜索粗粒度和细粒度,两种搜索方式的区别就是搜索步长不同。粗粒度是指搜索步长较大,为了能在较大的搜索范围内找到一个最优解所在的大体区域。细粒度搜索搜索步长较小,为了能在一个较小范围内找到一个精确参数。
而对与大样本的文件,使用上面的方法仍然会比较耗费时间。为了进一步提高效率,同时在保证得到全局最优的情况下,先对选择大样本的子集进行粗粒度的搜索,然后得到在得到的最优区间内对全量样本进行细粒度的搜索。
2.6 SVM参数选择的并行化
SVM对训练过程还是比较久的,尤其是为了能够找到最合适的参数。自然就想到能不能对SVM的巡检并行化。我之前做的方法是对参数的选择并行化,而单个参数的训练还是放在一个机器上串行进行。我把训练的方法放在我博客上,就不再粘贴到这里了。
2 Libs与liblinear的多分类策略
2.7 Libsvm 与liblinear的多分类策略
libsvm的多分类策略为one-againt-one。总共有k*(k-1)/2个binary classifier,对这k*(k-1)/2个binary classifier的value进行遍历,如果第i个类和第j个类binary 的classifier的value大于0,则会给第i个类投1票,否则给第j个类投1票。选择最终获得投票数最多的类作为最终的类别。
而liblinear的策略为one-against-rest。总共有k个binary classifier。从所有binary classifier中选择值最大多对应的类别作为最终的预测类标签。
重复样本对SVM模型的影响
2.8 重复样本对SVM模型的影响
重复样本对于SVM模型有怎样的影响呢?
我自己做了个实验,用来看重复样本的影响。
原有一个训练样本共有Positive样本1000,Negative样本2000,然后将Positive样本*2,构造了一个Positive样本2000,Negative样本2000的训练样本。然后测试一个包含Positive样本4494 ,Negative样本24206的样本。最终的结果如下:
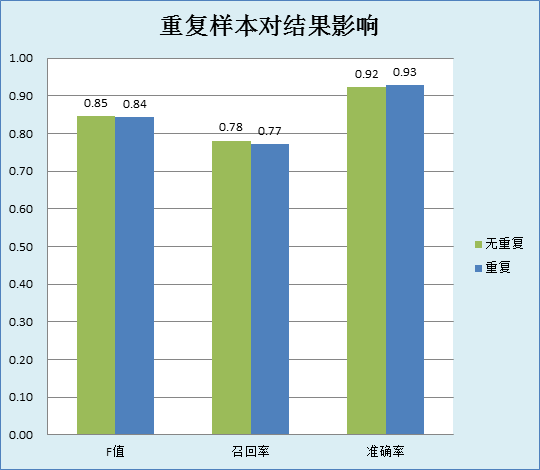
图2.8‑1重复样本对结果影响
从结果上来看:在F值上,无重复的样本会比重复样本稍高(图中保留了2位小数,其实差异不超过0.5%)。而正确率上,重复样本会比无重复样本稍高。
然后我又把模型放入到一个包含3千万样本中去测试,具体的指标无法测算。但是感觉还是重复样本会好一点。
具体分析:
1、 一个样本被重复的多次,意义上相当于增加了该样本的权重。在SVM有一种WeightedInstance。在正常样本难免会有些误判,如果同一条样本同时出现在Positive和Negative类中,包含重复样本的Positive类就会把Negative类误判的样本的影响抵消。而在SVM分类中对这些离群点会用惩罚函数进行控制。
2、 但是如果保留重复样本,会增加样本的量,对libsvm来说,分类的复杂度为O(Nsv3),而且如果一个样本是支持向量,那么所有重复的样本也都会被加入到支持向量中去。而且如果要为SVM模型选择合适的参数的,如果在SVM选择的是RBF核函数,挑选合适的惩罚cost和RBF的参数gramma,如果在都是在[1,5,0.5]进行挑选,则总共会有9*9=81组参数需要挑选,在每组参数下如果要进行5-flods的交叉验证,则需要81*5=405次训练与测试的过程。如果每次训练与测试花费2分钟(在样本达到10万数量级的时候,libsvm的训练时间差不多按分钟计算),则总共需要405*2/60=12.3小时,所以说训练一个好的SVM模型十分不容易。因此如果去掉重复样本对训练效率来说大有裨益。
2.9 将分类应用与信息过滤
分类应用与信息过滤,对最终效果影响最大的是什么?分类算法?词典大小?特征选择?模型参数?这些都会影响到最终的过滤效果,但是如果说对过滤效果影响最大的,还是训练样本的采样。
现在基于机器学习的分类算法一般都是基于一个假设:训练集和测试集的分布是一致的,这样在训练集上训练出来的分类器应用与测试集时其效果才会比较有效。
但是信息过滤面对的数据集一般是整个互联网,而互联网的数据集一般很难去随机采样。如下图所示:通常来说,信息过滤或其它面向全互联网的应用在分类,选择数据集时,需要包含P(Positive,即用户感兴趣的样本),N(Negative,即用户不关心、不敢兴趣的样本)。最理想的情况是:P选择是用户感兴趣的,而N是全网中除去P,显而易见N是无限大的,而且很难估计其真正的分布,即无法对其随机取样。

图2.9‑1样本分布
同样面对整个互联网的应用时网页分类,网页分类应用一般会选择Yahoo!或者是专门整理网页分类专门网站的网页作为初始训练样本。
信息过滤的样本一般来说,感兴趣的样本是很好随机采样的。但是与感兴趣相对于的是正常样本,这个很难去选择。而正常样本对全网测试效果是影响非常大的。我曾经做过一个实验:
首先,有一个包含5万条样本的数据集,有2.5万条Positive样本,2.5万条Negative样本。这里的Negative样本是以前用关键字的方法找出的不正确的样本。用4万条样本做训练样本,用1万条样本做测试样本。训练出得模型交叉验证的结果可以达到97%以上。在测试样本中的测试效果,然后选定阈值为0.9,这是的召回率可以达到93%,正确率为96%。
然后把这个模型放到一个包含3千万条中去测试,设置阈值为0.9,共找出疑似违规样本300万条。对这个实验来说,召回的样本实在是太多了,其正确率是很低的。
然后,我又更换了一下正常样本。从这3千万样本中随机采样出3万条样本,然后经过校验,将其中Positive的样本剔除掉。剩下大约2万7千条样本放入到训练样本重新训练。
把得到的新模型放到3千万样本中测试,同样设置阈值为0.9,共找出疑似样本15万。正确率可以达到70%左右。所以正常样本的随机选择对分类来说同样至关重要。
举一个小例子:
下图左面的图是用P和N训练出得模型。右面的图中有一个未知的类C,根据已知的模型,他应该会被分入到P中,但是实际上他是不属于P的。一般情况下,这种情况可以用阈值来控制。

图2.9‑2分类用于信息过滤
2.10 SVM解决样本倾斜的问题
所谓数据偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个,这会引起的问题显而易见,可以看看下面的图:
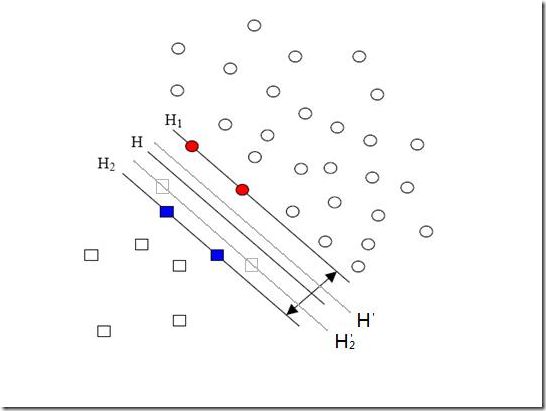
图2.10‑1样本倾斜示例
方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
具体的解决方法还是看我博客上的文章吧,这里就不单独贴出来了。
2.11 其他
文本分类的问题点很多,之前还想再写写如何对短文本(比如query)进行分类,利用利用Wikipedia的知识增强文本分类的效果,如何利用未标记样本来提高分类的效果。现在时间不多,等有时间了再继续深入的写吧。