垃圾分类、EfficientNet模型B0~B7、Rectified Adam(RAdam)、Warmup、带有Warmup的余弦退火学习率衰减

日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
垃圾分类、EfficientNet模型、数据增强(ImageDataGenerator)、混合训练Mixup、Random Erasing随机擦除、标签平滑正则化、tf.keras.Sequence
垃圾分类、EfficientNet模型B0~B7、Rectified Adam(RAdam)、Warmup、带有Warmup的余弦退火学习率衰减
EfficientNet中的每个模型要求的输入形状大小
每个网络要求的输入形状大小:
EfficientNetB0 - (224, 224, 3)
EfficientNetB1 - (240, 240, 3)
EfficientNetB2 - (260, 260, 3)
EfficientNetB3 - (300, 300, 3)
EfficientNetB4 - (380, 380, 3)
EfficientNetB5 - (456, 456, 3)
EfficientNetB6 - (528, 528, 3)
EfficientNetB7 - (600, 600, 3)
EfficientNet模型迁移的使用注意事项:
1.因为该模型的源码是在tensorflow 1.x的版本,并非是tensorflow 2.0的版本,因此在tensorflow 2.0环境中使用的话,
需要用到tf.compat.v1.disable_eager_execution(),表示关闭默认的eager模式,但要注意的是,如果关闭默认的eager模式了的话,
那么同时还使用tf.keras.callbacks.TensorBoard的话会报错,tf.keras.callbacks.ModelCheckpoint不会报错,
那么解决的方式要么此时不使用TensorBoard,或者不关闭默认的eager模式。
2.layers.py中的class Swish中的call()函数返回值的修改建议。
如果使用了tf.compat.v1.disable_eager_execution()之后,报错No registered 'swish_f32' OpKernel for GPU devices compatible with node的话,
把 layers.py中的class Swish中的call()函数返回值 return tf.nn.swish(inputs) 修改为 return inputs * tf.math.sigmoid(inputs) 即可解决,
实际上底层是 tf.nn.swish(x) 封装了 x* tf.math.sigmoid(x),不使用tf.nn.swish之后,即可也把tf.compat.v1.disable_eager_execution()给注释掉,
即不需要关闭默认的eager模式了,那么此时也可以正常同时使用TensorBoard。4.10 综合案例:垃圾分类之模型构建与训练
学习目标
- 目标
- 掌握EfficientNet模型原理
- 掌握warmup以及余弦退火学习率原理
- 应用
- 应用完成垃圾分类的训练过程
- 应用完成余弦退火与warmup的实现
4.10.1 EfficientNet模型介绍
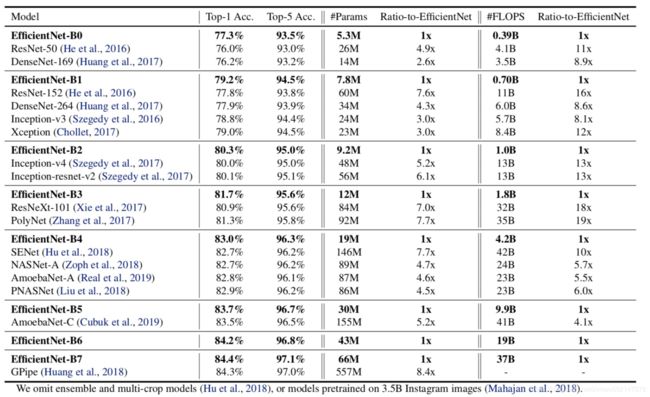
先再来看一遍efficientnet的取得的成绩
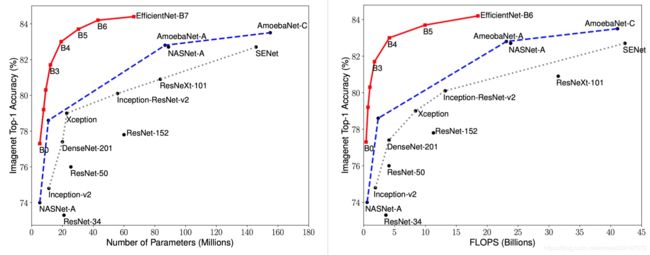
可以看出 EfficientNet 系列完胜了其他所有的卷积网络。其中EfficientNet-B7实现了ImageNet的state-of-the-art率,达到了 84.4%。但是它的参数量相比 GPipe 减少了 8.4 倍,并且推理速度达到了 GPipe 的 6.1 倍。更加细节的数据可以参考后面的实验部分。
论文地址:https://arxiv.org/pdf/1905.11946.pdf
4.10.1.1 摘要
作者系统地研究了模型缩放并且仔细验证了网络深度、宽度和分辨率之间的平衡可以导致更好的性能表现。提出了一种新的缩放方法——使用一个简单高效的复合系数来完成对深度/宽度/分辨率所有维度的统一缩放。在MobileNets和ResNet上展示了这种缩放方法的高效性。为了进一步研究,我们使用神经架构搜索设计了一个baseline网络。使用神经架构搜索来设计新的baseline并进行扩展以获得一系列模型,称EfficientNets。
引入:
一般ConvNets的精度随着它的size增加,有很多工作通过增加ConvNets的宽度、深度或者图像分辨率去提升网络的性能。尽管可以任意缩放二维或三维,但任意缩放需要繁琐的手动调整,并且仍然经常产生次优的精度和效率。
作者重新思考和研究了ConvNets的缩放问题,是否存在一种原则性的方法缩放ConvNets,从而实现更高的精度和效率?作者的实证研究表明,平衡网络宽度/深度/分辨率的所有维度是至关重要的,且可通过简单地按比例缩放每个维度来实现这种平衡。基于此,提出了一种简单而有效的复合缩放方法。
4.10.1.2 原理介绍
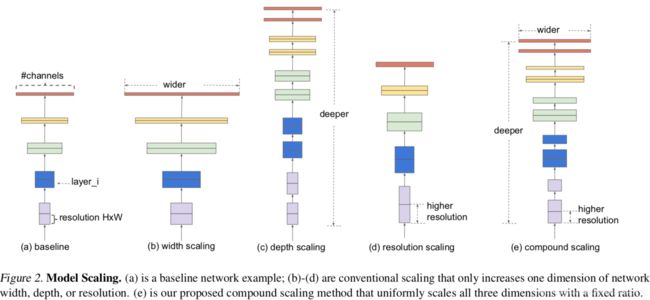

1、复合模型缩放-问题建模



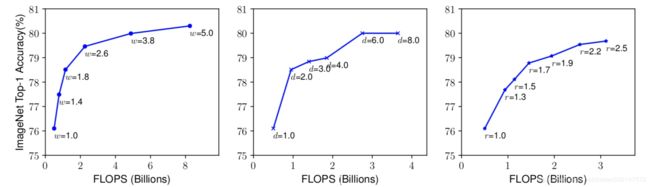
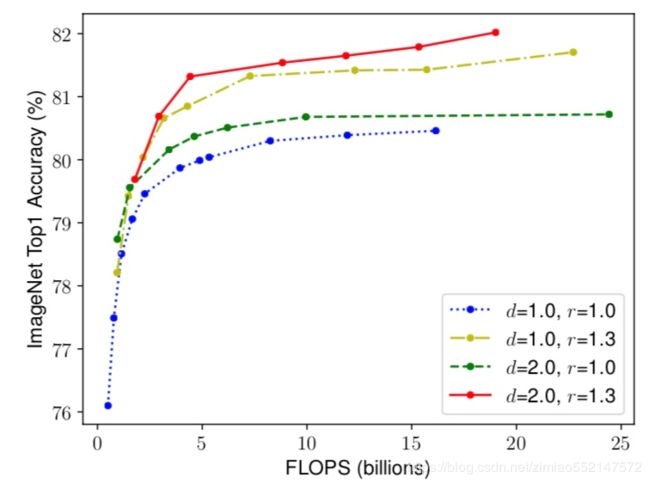
表示比较了不同网络深度和分辨率下的宽度缩放,如下图所示。在不改变深度(d = 1.0)和分辨率(r = 1.0)的情况下缩放网络宽度w,则精度会很快达到饱和。 随着更深(d = 2.0)和更高分辨率(r = 2.0),宽度缩放在相同的FLOPS成本下实现了更好的精度。
2、新的复合方法

4.10.1.3 Efficientnet 架构
所以通过上面的方法,作者找到了一个新的baseline((MBConv),类似于MobileNetV2和MnasNet)来评估,称为EfficientNet-B0。
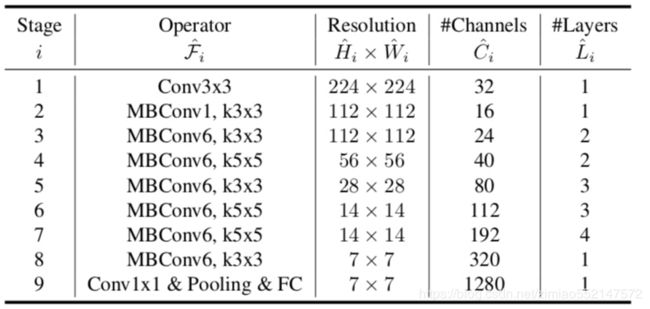

4.10.1.4 实验
- 对MobileNets 和 ResNets进行缩放
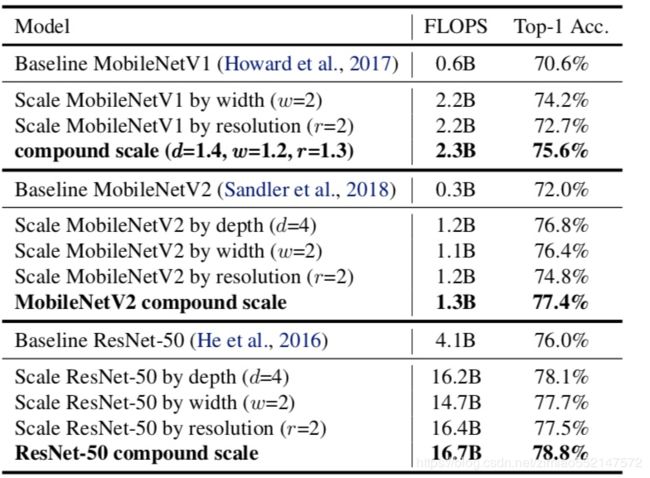
这个复合缩放方法提高了所有这些模型的准确性,表明了缩放方法对现有的卷积网络结构有效性。
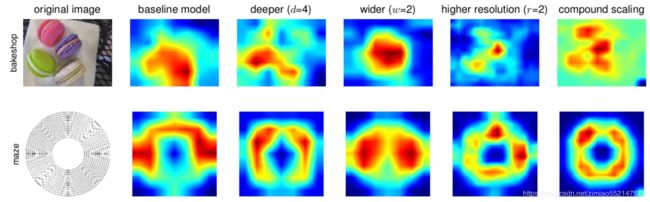
- 类激活图说明了具有复合缩放的模型倾向于关注具有更多对象细节的更相关区域,而其他模型要么缺少对象细节,要么无法捕获图像中的所有对象。
- 在各比赛中做迁移学习得成就
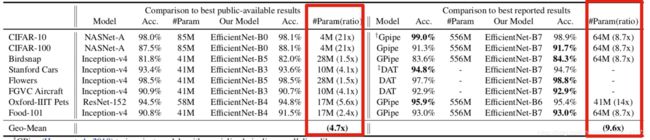
- 与公开可用模型相比,EfficientNet模型减少了平均4.7倍(最多21倍)的参数,同时实现了更高的精度。
- 与最先进的模型相比,EfficientNet模型在8个数据集中有5个仍然超过了它们的准确度,且使用的参数减少了9.6倍。
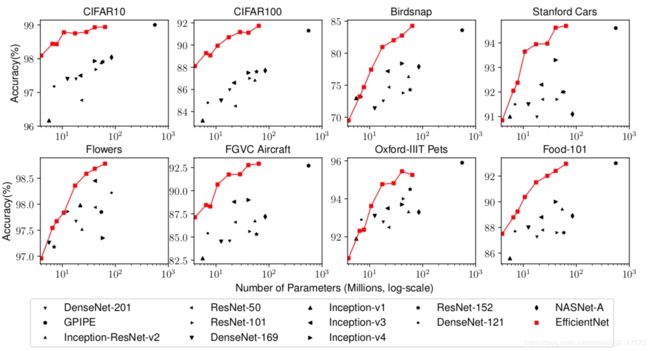
最终各种模型的精度 - 参数曲线,红色为EfficientNet的结果,明显比各个模型精度高,参数量少。
注:最终的效果比率,都是在大量的设备和模型上计算得来的,资源消耗不可想象。Google有足够的资源和设备(TPU)去做。
4.10.2 垃圾分类开源EfficientNet实现介绍
4.10.2.1 模型目录
TensorFlow2.0 可进行迁移学习的实现版本不存在efficientnet,需要第三方实现的模型两种选择:
1、可迁移学习的TF低版本能使用(部分操作不支持默认Eager 模式)
https://github.com/calmisential/Basic_CNNs_TensorFlow2
我们选择的是这个版本,可以在与训练模型上迁移,使用简单
from efficientnet import EfficientNetB0
EfficientNetB0(weights=None, include_top=False, input_shape=(336, 336, 3))
2、TF2.0实现版本不能使用在imagenet上的与训练模型,版本简单易懂,项目中也含有其他的模型
https://github.com/Tony607/efficientnet_keras_transfer_learning

去工程中看看指定模型。其中参数include_top,指定了我们可以进行迁移学习:
if include_top:
x = KL.GlobalAveragePooling2D(data_format=global_params.data_format)(x)
if global_params.dropout_rate > 0:
x = KL.Dropout(global_params.dropout_rate)(x)
x = KL.Dense(global_params.num_classes, kernel_initializer=DenseKernalInitializer())(x)
x = KL.Activation('softmax')(x)
else:
if pooling == 'avg':
x = KL.GlobalAveragePooling2D(data_format=global_params.data_format)(x)
elif pooling == 'max':
x = KL.GlobalMaxPooling2D(data_format=global_params.data_format)(x)
4.10.3 优化算法以及学习率trick
4.10.2.1 Rectified Adam(Adam with warm up)
RAdam能根据方差分散度,动态地打开或者 关闭自适应学习率,并且提供了一种不需要可 调参数学习率预热的方法。
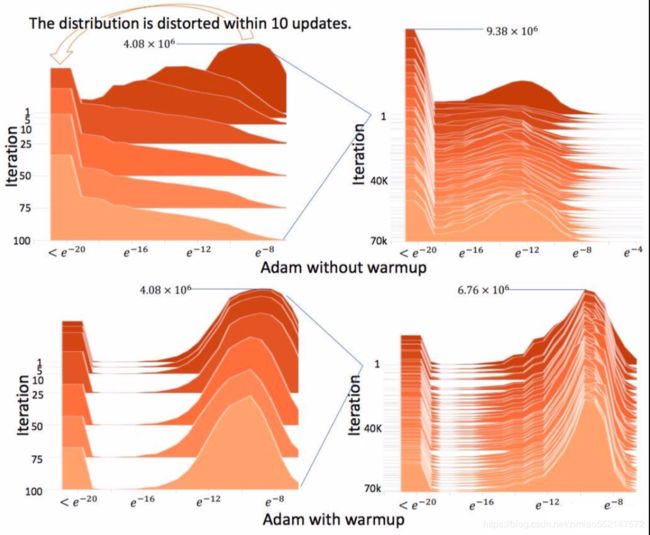
上述结果表明使用原始Adam必须预热,否则正态分布会变得扭曲
4.10.2.2 Warmup
- 定义:学习率预热就是在刚开始训练的时候先使用一个较小的学习率,训练一些epoches或iterations,等模型稳定时再修改为预先设置的学习率进行训练。
学习率是神经网络训练中最重要的超参数之一,针对学习率的技巧有很多。Warm up是在ResNet论文中提到的一种学习率预热的方法。
- 原因:由于刚开始训练时模型的权重(weights)是随机初始化的,此时选择一个较大的学习率,可能会带来模型的不稳定。
- 论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个iterations),然后使用0.1的学习率进行训练。
理解:刚开始模型对数据的“分布”理解为零,或者是说“均匀分布”;在第一轮训练的时候,每个数据点对模型来说都是新的,模型会很快地进行数据分布修正,如果这时候学习率就很大,极有可能导致开始的时候就对该数据“过拟合”,后面要通过多轮训练才能拉回来,浪费时间。
4.10.2.3 余弦学习率衰减(Cosine Learning rate decay)
余弦学习率衰减的方式,Cosine Learning rate decay。公式如下:
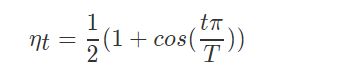
下图是逐步衰减学习率与余弦学习率衰减的方式对比:
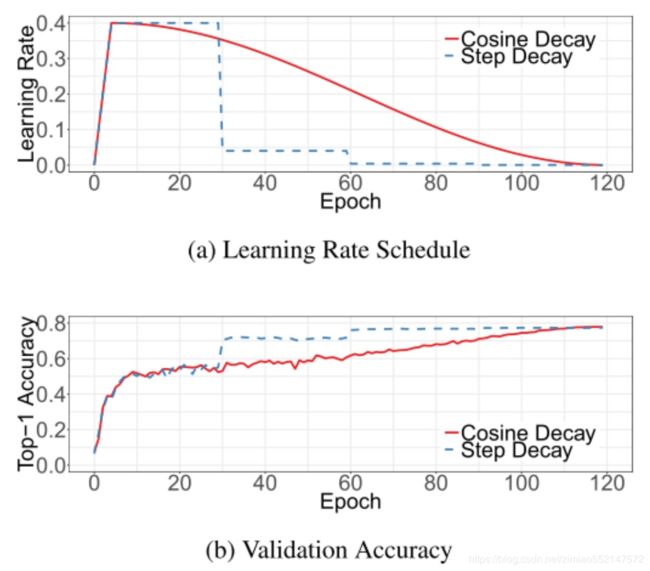
- 现象:当Step Decay方法的学习率已经较小的时候,Cos Decay方法的学习仍比较大,因而能够加速整个训练的过程。但是看图中b,很明显Step Decay再衰减之后,准确率就上来了,说明衰减之前的数量级效用已经不强了,这个时候Cos decay还是那个数量级,所以速度就比Step Decay慢了
- 结果:
- 1、cos的学习率的前期是warm-up阶段,这个时候是以线性增长的方式增长到初始学习率,然后开始执行cos的学习率变化,最终两种学习率达到一致。从准确性的角度来看,使用step的方式似乎学习的更快一些。而且其变化的拐点和其学习率的拐点是对应着的,即学习率降了之后,验证的准确性也跟着开始提升,而cos学习率的整个过程中准确性都很平稳,最终两者的准确性也是一致。
- 2、区别在于中间的学习过程。而且step的方式有一定的随机性,不知道要以多大的step来改变学习率,如果这个’step’可以根据某种方式量化
定义:常用的Learning Rate Decay是Step Decay,即每隔N个Epoch,learning rate乘上一个固定decay系数。
- 但是Step Decay不好的地方在于学习率衰减的时候,跳跃变化较大,带来了较大的冲量Momentum
4.10.2.4 TensorFlow实现
Keras 的 callbacks 中有 ReduceLROnPlateau() 和 LearningRateScheduler() 函数可以动态的调整学习率。但是前者只在验证误差停止衰减的时候减小学习率,后者只能在每个 Epoch 开始或结束的时候,改变学习率两者使用参考文档:https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/callbacks/LearningRateScheduler#class_learningratescheduler
如果需要在训练的时候每批次更加细致的控制学习率,需要自定义回调方法
1、tf.keras.callbacks.Callback
该类在Model 的.fit()方法中会调用一下回调方法
- on_batch_begin( batch, logs=None)
- 一批次数据开始时的处理
- on_batch_end(batch, logs=None)
- 一批次数据处理结束
- on_epoch_begin和on_epoch_end
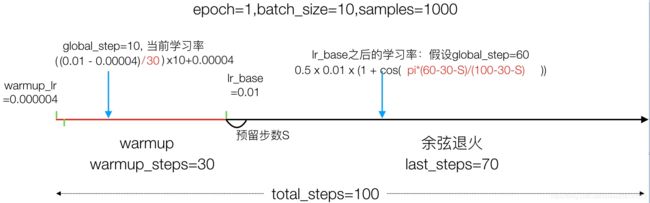
4.10.3 垃圾分类带有warmup的余弦退火学习率调度实现
4.10.3.1 流程分析
- 分为两个结算
- warmup阶段
- 余弦退火阶段
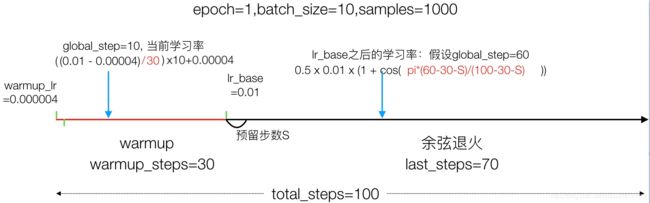
4.10.3.2 完整代码过程实现
参考文件,并运行测试
- 步骤:
- 1、自定义WarmUpCosineDecayScheduler调度器,实现批次前后的处理逻辑
- 2、实现warmup的余弦退火学习率计算方法
1、自定义WarmUpCosineDecayScheduler调度器,实现批次前后的处理逻辑
import numpy as np
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
class WarmUpCosineDecayScheduler(tf.keras.callbacks.Callback):
"""带有warmup的余弦退火学习率调度
"""
def __init__(self,
learning_rate_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
verbose=0):
"""
初始化参数
:param learning_rate_base: 基础学习率
:param total_steps: 总共迭代的批次步数 epoch * num_samples / batch_size
:param global_step_init: 初始
:param warmup_learning_rate: 预热学习率默认0.0
:param warmup_steps:预热的步数默认0
:param hold_base_rate_steps:
:param verbose:
"""
super(WarmUpCosineDecayScheduler, self).__init__()
self.learning_rate_base = learning_rate_base
self.total_steps = total_steps
self.global_step = global_step_init
self.warmup_learning_rate = warmup_learning_rate
self.warmup_steps = warmup_steps
self.hold_base_rate_steps = hold_base_rate_steps
# 是否在每次训练结束打印学习率
self.verbose = verbose
# 记录所有批次下来的每次准确的学习率,可以用于打印显示
self.learning_rates = []
def on_batch_end(self, batch, logs=None):
# 1、批次开始前当前步数+1
self.global_step = self.global_step + 1
# 2、获取优化器上一次的学习率,并记录
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
def on_batch_begin(self, batch, logs=None):
# 1、通过参数以及记录的次数和上次学习率
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps)
# 2、设置优化器本次的学习率
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\n批次数 %05d: 设置学习率为'
' %s.' % (self.global_step + 1, lr))
这里面涉及到一个设置当前优化器学习率的使用,会用到keras.backend这个模块。keras是一种基于模块的高级深度学习开发框架,它并没有仅依赖于某一种高速底层张量库,而是对各种底层张量库进行高层模块封装,让底层库完成诸如张量积、卷积操作。在keras中,各种底层库(Google开发的TensorFlow、蒙特利尔大学实验室开发的Theano、微软开发的CNTK)都可以作为后端(backend)引擎为keras模块提供服务。
问题:如何修改Keras使用的backend
(1)通过修改keras配置文件来修改backend
一旦运行过一次Keras,就会在$HOME/.keras下生成配置文件keras.json,该文件的"backend"字段的值即为keras所使用的后端库,默认情况下,该值为"tensorflow"。用户可以根据需要选择另外两个库"theano"、"cntk",甚至自己写的底层库。
(2)通过运行Python脚本时增加配置项指定backend
$ KERAS_BACKEND=theano python -c "from keras import backend"
Using Theano backend.
导入使用:
from keras import backend as K
其中两个方法可以设置张量的值:
lr = K.get_value(self.model.optimizer.lr)
K.set_value(self.model.optimizer.lr, lr)
2、实现warmup的余弦退火学习率计算方法
- 步骤:
- 1、余弦退火学习率计算
- 2、warmup之后的学习率计算
- 如果预留大于0,判断目前步数是否 > warmup步数+预留步数,是的话返回刚才上面计算的学习率,不是的话使用warmup之后的基础学习率
- 3、warmup学习率计算,并判断大小
- 4、如果最后当前到达的步数大于总步数,则归0,否则返回当前的计算出来的学习率(可能是warmup学习率也可能是余弦衰减结果)
代码如下
def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0):
"""
每批次带有warmup余弦退火学习率计算
:param global_step: 当前到达的步数
:param learning_rate_base: warmup之后的基础学习率
:param total_steps: 总需要批次数
:param warmup_learning_rate: warmup开始的学习率
:param warmup_steps:warmup学习率 步数
:param hold_base_rate_steps: 预留总步数和warmup步数间隔
:return:
"""
if total_steps < warmup_steps:
raise ValueError('总步数必须大于warmup')
# 1、余弦退火学习率计算
# 从warmup结束之后计算
# 0.5 * 0.01 * (1 + cos(pi*(1-5-0)/(10 - 5 - 0))
learning_rate = 0.5 * learning_rate_base * (1 + np.cos(
np.pi *
(global_step - warmup_steps - hold_base_rate_steps
) / float(total_steps - warmup_steps - hold_base_rate_steps)))
# 2、warmup之后的学习率计算
# 如果预留大于0,判断目前步数是否 > warmup步数+预留步数,是的话返回刚才上面计算的学习率,不是的话使用warmup之后的基础学习率
if hold_base_rate_steps > 0:
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps,
learning_rate, learning_rate_base)
# 3、warmup步数是大于0的
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError('warmup后学习率必须大于warmup开始学习率')
# 1、计算一个0.01和0.000006的差距/warmup_steps,得到warmup结束前增加多少
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
# 2、计算warmup下一步第global_step的学习率
warmup_rate = slope * global_step + warmup_learning_rate
# 3、判断global_step小于warmup_steps的话,返回这个warmup当时的学习率,否则直接返回余弦退火计算的
learning_rate = np.where(global_step < warmup_steps, warmup_rate,
learning_rate)
# 4、如果最后当前到达的步数大于总步数,则归0,否则返回当前的计算出来的学习率(可能是warmup学习率也可能是余弦衰减结果)
return np.where(global_step > total_steps, 0.0, learning_rate)
通过以下代码进行测试:
if __name__ == '__main__':
# 1、创建模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 2、参数设置
sample_count = 1000 # 样本数
epochs = 4 # 总迭代次数
warmup_epoch = 3 # warmup 迭代次数
batch_size = 16 # 批次大小
learning_rate_base = 0.0001 # warmup后的初始学习率
total_steps = int(epochs * sample_count / batch_size) # 总迭代批次步数
warmup_steps = int(warmup_epoch * sample_count / batch_size) # warmup总批次数
# 3、创建测试数据
data = np.random.random((sample_count, 100))
labels = np.random.randint(10, size=(sample_count, 1))
# 转换目标类别
one_hot_labels = tf.keras.utils.to_categorical(labels, num_classes=10)
# 5、创建余弦warmup调度器
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=4e-06, # warmup开始学习率
warmup_steps=warmup_steps,
hold_base_rate_steps=0,
)
# 训练模型
model.fit(data, one_hot_labels, epochs=epochs, batch_size=batch_size, verbose=0, callbacks=[warm_up_lr])
print(warm_up_lr.learning_rates)
结果:
[4e-06, 4.513369e-06, ...., 7.281053e-05, 7.0564354e-05, 6.826705e-05, 6.592433e-05, 6.354202e-05, 6.112605e-05, 5.868241e-05, 5.6217184e-05, 5.3736505e-05, 5.1246534e-05, 4.8753467e-05, 4.6263496e-05, 4.3782813e-05, 4.131759e-05, 3.8873954e-05, 3.6457976e-05, 3.4075667e-05, 3.173295e-05, 2.9435645e-05, 2.7189468e-05, 2.5e-05, 2.2872688e-05, 2.0812817e-05, 1.882551e-05, 1.6915708e-05, 1.5088159e-05, 1.3347407e-05, 1.1697778e-05, 1.0143374e-05, 8.688061e-06, 7.335456e-06, 6.0889215e-06, 4.9515565e-06, 3.9261895e-06, 3.015369e-06, 2.2213596e-06, 1.5461356e-06, 9.913756e-07, 5.584587e-07, 2.4846122e-07, 6.215394e-08, 0.0, 0.0]
4.10.4 模型训练过程实现
- 步骤:
- 1、建立读取数据的sequence
- 2、建立模型,指定模型训练相关参数
- 模型修改
- 模型训练优化器指定
- 3、指定训练的callbacks,并进行模型的训练
- 4、训练指定
其中代码运行逻辑
if __name__ == '__main__':
args = parser.parse_args()
train_model(args)
参数指定使用argparse工具:pip install argparse
parser = argparse.ArgumentParser()
parser.add_argument("data_url", type=str, default='./data/garbage_classify/train_data', help="data dir", nargs='?')
parser.add_argument("train_url", type=str, default='./garbage_ckpt/', help="save model dir", nargs='?')
parser.add_argument("num_classes", type=int, default=40, help="num_classes", nargs='?')
parser.add_argument("input_size", type=int, default=300, help="input_size", nargs='?')
parser.add_argument("batch_size", type=int, default=16, help="batch_size", nargs='?')
parser.add_argument("learning_rate", type=float, default=0.0001, help="learning_rate", nargs='?')
parser.add_argument("max_epochs", type=int, default=30, help="max_epochs", nargs='?')
parser.add_argument("deploy_script_path", type=str, default='', help="deploy_script_path", nargs='?')
parser.add_argument("test_data_url", type=str, default='', help="test_data_url", nargs='?')
其中nargs是为了在pycharm中运行时,不输入命令行参数值也能直接运行。否则需要命令行运行
python train.py data_url .....
1、建立读取数据的sequence
import multiprocessing
import numpy as np
import argparse
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard, Callback
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from efficientnet import model as EfficientNet
from data_gen import data_from_sequence
from utils.lr_scheduler import WarmUpCosineDecayScheduler
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
# 注意关闭默认的eager模式
tf.compat.v1.disable_eager_execution()
def train_model(param):
"""训练模型
:param param: 传入的命令参数
:return:
"""
# 1、建立读取数据的sequence
train_sequence, validation_sequence = data_from_sequence(param.data_url, param.batch_size,
param.num_classes, param.input_size)
2、建立模型,指定模型训练相关参数
# 2、建立模型,指定模型训练相关参数
model = model_fn(param)
optimizer = Adam(lr=param.learning_rate)
objective = 'categorical_crossentropy'
metrics = ['accuracy']
# 模型修改
# 模型训练优化器指定
model.compile(loss=objective, optimizer=optimizer, metrics=metrics)
model.summary()
# 判断模型是否加载历史模型
if os.path.exists(param.train_url):
filenames = os.listdir(param.train_url)
model.load_weights(filenames[-1])
print("加载完成!!!")
def model_fn(param):
"""迁移学习修改模型函数
:param param:
:return:
"""
base_model = EfficientNet.EfficientNetB3(include_top=False, input_shape=(param.input_size, param.input_size, 3),
classes=param.num_classes)
x = base_model.output
x = GlobalAveragePooling2D(name='avg_pool')(x)
predictions = Dense(param.num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model
3、指定训练的callbacks,并进行模型的训练
sample_count = len(train_sequence) * param.batch_size
epochs = param.max_epochs
warmup_epoch = 5
batch_size = param.batch_size
learning_rate_base = param.learning_rate
total_steps = int(epochs * sample_count / batch_size)
warmup_steps = int(warmup_epoch * sample_count / batch_size)
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=0,
warmup_steps=warmup_steps,
hold_base_rate_steps=0,
)
#(3)模型保存相关参数
check = tf.keras.callbacks.ModelCheckpoint(param.train_url+'weights_{epoch:02d}-{val_acc:.2f}.h5',
monitor='val_acc',
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)
4、训练
这里使用model.fit_generator函数,因为填入参数的是一个迭代序列,指定工作线程数(multiprocessing.cpu_count() * 0.7。
model.fit_generator(
train_sequence,
steps_per_epoch=len(train_sequence),
epochs=param.max_epochs,
verbose=1,
callbacks=[check, tensorboard, warm_up_lr],
validation_data=validation_sequence,
max_queue_size=10,
workers=int(multiprocessing.cpu_count() * 0.7),
use_multiprocessing=True,
shuffle=True
)
4.10.5 总结
- EfficientNet模型原理
- warmup以及余弦退火学习率原理
- 完成垃圾分类的训练过程
- 完成余弦退火与warmup的实现
garbage_clssify 垃圾分类
train.py
import multiprocessing
import numpy as np
import argparse
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard, Callback
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, RMSprop
from efficientnet import model as EfficientNet
from data_gen import data_from_sequence
from utils.lr_scheduler import WarmUpCosineDecayScheduler
import os
# os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
"""
TensorBoard 和 tf.compat.v1.disable_eager_execution() 不兼容,因此需要把这个注释掉,
才能使用 TensorBoard
"""
# # 注意关闭默认的eager模式
# tf.compat.v1.disable_eager_execution()
parser = argparse.ArgumentParser()
parser.add_argument("data_url", type=str, default='./data/garbage_classify/train_data', help="data dir", nargs='?')
parser.add_argument("train_url", type=str, default='./garbage_ckpt/', help="save model dir", nargs='?')
parser.add_argument("num_classes", type=int, default=40, help="num_classes", nargs='?')
parser.add_argument("input_size", type=int, default=300, help="input_size", nargs='?')
parser.add_argument("batch_size", type=int, default=8, help="batch_size", nargs='?')
parser.add_argument("learning_rate", type=float, default=0.001, help="learning_rate", nargs='?')
parser.add_argument("max_epochs", type=int, default=30, help="max_epochs", nargs='?')
parser.add_argument("deploy_script_path", type=str, default='', help="deploy_script_path", nargs='?')
parser.add_argument("test_data_url", type=str, default='', help="test_data_url", nargs='?')
def model_fn(param):
"""修改符合垃圾分类的模型
:param param: 命令行参数
:return:
"""
base_model = EfficientNet.EfficientNetB3(include_top=False,
input_shape=(param.input_size, param.input_size, 3),
classes=param.num_classes)
x = base_model.output
# 自定义修改40个分类的后面基层
x = GlobalAveragePooling2D(name='avg_pool')(x)
predictions = Dense(param.num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model
def train_model(param):
"""训练模型逻辑
:param param: 各种参数命令行
:return:
"""
# 1、读取sequence数据
train_sequence, validation_sequence = data_from_sequence(param.data_url, param.batch_size, param.num_classes, param.input_size)
# 2、建立模型,修改模型指定训练相关参数
model = model_fn(param)
optimizer = Adam(lr=param.learning_rate)
objective = 'categorical_crossentropy'
metrics = ['accuracy']
# 模型修改
# 模型训练优化器指定
model.compile(loss=objective, optimizer=optimizer, metrics=metrics)
model.summary()
"""
TensorBoard 和 tf.compat.v1.disable_eager_execution() 不兼容,因此需要把这个注释掉,
才能使用 TensorBoard
"""
# 3、指定相关回调函数
# Tensorboard
tensorboard = tf.keras.callbacks.TensorBoard(log_dir='./graph', histogram_freq=1, write_graph=True, write_images=True)
# modelcheckpoint
# (3)模型保存相关参数
check = tf.keras.callbacks.ModelCheckpoint(param.train_url + 'weights_{epoch:02d}-{val_loss:.2f}.h5',
monitor='val_loss',
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)
# 余弦退回warmup
# 得到总样本数
batch_size = param.batch_size
"""
要求训练样本数/标签数和验证样本/标签数数都必须是可以整除batch_size的,
否则在mixup中X = X1 * X_l + X2 * (1 - X_l)代码再进行矩阵广播运算的时候会报错,因为形状不一致,
报错信息:ValueError: operands could not be broadcast together with shapes (不满batch_size大小,300,300,3) (batch_size,1,1,1)。
正因为如此,所以要求训练样本数和验证样本数都必须是可以整除batch_size的,因为在一个epoch中遍历到最后一个step时,
剩余的训练样本数不足以整除batch size,那么就会报错。
"""
"""
#总共样本数: 14802 , 训练样本数: 12581, 验证样本数: 2221
"""
print("sample_count:",len(train_sequence)) #1573 即是 一个epoch 中 遍历的批量数据 的个数
sample_count = len(train_sequence) * batch_size
print("sample_count:",sample_count) #12584 即是 一个epoch 中 训练样本数
# 第二阶段学习率以及总步数
learning_rate_base = param.learning_rate
# (epochs * 一个epoch 中 训练样本数 )/ batch_size 求出一共这么多epochs 一共需要遍历的 批量数据的个数
total_steps = int(param.max_epochs * sample_count) / batch_size
# 计算第一阶段的步数需要多少 warmup_steps
warmup_epoch = 8
warmup_steps = int(warmup_epoch * sample_count) / batch_size
warm_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=0,
warmup_steps=warmup_steps,
hold_base_rate_steps=0,)
"""
报错:报错文件路径 \Anaconda3\lib\multiprocessing\...
解决:把 fit/fit_generator中配置的 use_multiprocessing=True 注释掉
报错:ResourceExhaustedError OOM when allocating
解决:把batch_size设置得小一点,因为GPU内存不够用,训练的参数量/数据过于巨大
"""
# 4、训练步骤
model.fit_generator(
train_sequence,
steps_per_epoch=int(sample_count / batch_size), # 一个epoch需要多少步 , 1epoch sample_out 140000多样本, 140000 / 16 = 步数
epochs=param.max_epochs,
verbose=1,
callbacks=[check, tensorboard, warm_lr],
validation_data=validation_sequence,
max_queue_size=10,
workers=int(multiprocessing.cpu_count() * 0.7),
# use_multiprocessing=True, #这句window会报错:G:\Anaconda3\lib\multiprocessing\...
shuffle=True
)
return None
if __name__ == '__main__':
args = parser.parse_args()
train_model(args)
data_gen文件夹 processing_data.py
import math
import os
import random
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical, Sequence
from sklearn.model_selection import train_test_split
from data_gen.random_eraser import get_random_eraser
class GarbageDataSequence(Sequence):
"""垃圾分类数据流,每次batch返回batch_size大小数据
model.fit_generator使用
"""
def __init__(self, img_paths, labels, batch_size, img_size, use_aug):
# 1、获取训练特征与目标值的合并结果 [batch_size, 1], [batch_size, 40] [batch_size, 41]
self.x_y = np.hstack((np.array(img_paths).reshape(len(img_paths), 1),
np.array(labels)))
self.batch_size = batch_size
self.img_size = img_size # (300, 300)
self.use_aug = use_aug
self.alpha = 0.2
# 随机擦出方法
self.eraser = get_random_eraser(s_h=0.3, pixel_level=True)
def __len__(self):
return math.ceil(len(self.x_y) / self.batch_size)
@staticmethod
def center_img(img, size=None, fill_value=255):
"""改变图片尺寸到300x300,并且做填充使得图像处于中间位置
"""
h, w = img.shape[:2]
if size is None:
size = max(h, w)
shape = (size, size) + img.shape[2:]
background = np.full(shape, fill_value, np.uint8)
center_x = (size - w) // 2
center_y = (size - h) // 2
background[center_y:center_y + h, center_x:center_x + w] = img
return background
def preprocess_img(self, img_path):
"""处理每张图片,大小, 数据增强
:param img_path:
:return:
"""
# 1、读取图片对应内容,做形状,内容处理, (h, w)
img = Image.open(img_path)
# [180, 200, 3]
scale = self.img_size[0] / max(img.size[:2])
img = img.resize((int(img.size[0] * scale), int(img.size[1] * scale)))
img = img.convert('RGB')
img = np.array(img)
# 2、数据增强:如果是训练集进行数据增强操作
if self.use_aug:
# 1、随机擦处
img = self.eraser(img)
# 2、翻转
datagen = ImageDataGenerator(
width_shift_range=0.05,
height_shift_range=0.05,
horizontal_flip=True,
vertical_flip=True,
)
img = datagen.random_transform(img)
# 4、处理一下形状 【300, 300, 3】
# 改变到[300, 300] 建议不要进行裁剪操作,变形操作,保留数据增强之后的效果,填充到300x300
img = self.center_img(img, self.img_size[0])
return img
def __getitem__(self, idx):
# 1、获取当前批次idx对应的特征值和目标值
batch_x = self.x_y[idx * self.batch_size: self.batch_size * (idx + 1), 0]
batch_y = self.x_y[idx * self.batch_size: self.batch_size * (idx + 1), 1:]
batch_x = np.array([self.preprocess_img(img_path) for img_path in batch_x])
# print("batch_x:",batch_x.shape)
batch_y = np.array(batch_y).astype(np.float32)
# 2、mixup
batch_x, batch_y = self.mixup(batch_x, batch_y)
# 3、归一化处理
batch_x = self.preprocess_input(batch_x)
return batch_x, batch_y
def on_epoch_end(self):
np.random.shuffle(self.x_y)
def mixup(self, batch_x, batch_y):
"""
数据混合mixup
:param batch_x: 要mixup的batch_X
:param batch_y: 要mixup的batch_y
:return: mixup后的数据
"""
size = self.batch_size
l = np.random.beta(self.alpha, self.alpha, size)
X_l = l.reshape(size, 1, 1, 1)
y_l = l.reshape(size, 1)
X1 = batch_x
Y1 = batch_y
X2 = batch_x[::-1]
Y2 = batch_y[::-1]
X = X1 * X_l + X2 * (1 - X_l)
Y = Y1 * y_l + Y2 * (1 - y_l)
return X, Y
def preprocess_input(self, x):
"""归一化处理样本特征值
:param x:
:return:
"""
assert x.ndim in (3, 4)
assert x.shape[-1] == 3
MEAN_RGB = [0.485 * 255, 0.456 * 255, 0.406 * 255]
STDDEV_RGB = [0.229 * 255, 0.224 * 255, 0.225 * 255]
x = x - np.array(MEAN_RGB)
x = x / np.array(STDDEV_RGB)
return x
def smooth_labels(y, smooth_factor=0.1):
assert len(y.shape) == 2
if 0 <= smooth_factor <= 1:
y *= 1 - smooth_factor
y += smooth_factor / y.shape[1]
else:
raise Exception(
'Invalid label smoothing factor: ' + str(smooth_factor))
return y
def data_from_sequence(train_data_dir, batch_size, num_classes, input_size):
"""读取本地数据到sequence
:param train_data_dir: 训练数据目录
:param batch_size: 批次大小
:param num_classes: 总类别书40
:param input_size: 输入图片大小(300, 300)
:return:
"""
# 1、读取txt文件,打乱文件顺序, .jpg, .txt
label_files = [os.path.join(train_data_dir, filename) for filename
in os.listdir(train_data_dir) if filename.endswith('.txt')]
random.shuffle(label_files)
# 2、解析txt文件当中 特征值以及目标值(标签)
img_paths = []
labels = []
for index, file_path in enumerate(label_files):
with open(file_path, 'r') as f:
line = f.readline()
line_split = line.strip().split(', ')
# line '*.jpg, 0'
if len(line_split) != 2:
print("% 文件格式出错", (file_path))
continue
img_name = line_split[0]
label = int(line_split[1])
# 最后保存到所有的列表当中
img_paths.append(os.path.join(train_data_dir, img_name))
labels.append(label)
# print(img_paths, labels)
# 3、目标标签类别ont_hot编码转换, 平滑处理
labels = to_categorical(labels, num_classes)
labels = smooth_labels(labels)
# 分割训练集合验证集合
train_img_paths, validation_img_paths, train_labels, validation_labels \
= train_test_split(img_paths, labels, test_size=0.15, random_state=0)
# print(validation_img_paths)
# print(train_labels, validation_labels)
#总共样本数: 14802 , 训练样本数: 12581, 验证样本数: 2221
print("总共样本数: %d , 训练样本数: %d, 验证样本数: %d" % (len(img_paths), len(train_img_paths), len(validation_img_paths)))
#====================================================
"""
要求训练样本数/标签数和验证样本/标签数数都必须是可以整除batch_size的,
否则在mixup中X = X1 * X_l + X2 * (1 - X_l)代码再进行矩阵广播运算的时候会报错,因为形状不一致,
报错信息:ValueError: operands could not be broadcast together with shapes (不满batch_size大小,300,300,3) (batch_size,1,1,1)。
正因为如此,所以要求训练样本数和验证样本数(包括标签集)都必须是可以整除batch_size的,因为在一个epoch中遍历到最后一个step时,
剩余的训练样本数不足以整除batch size,那么就会报错。
"""
i = -2
j = -2
while 1:
if (len(train_img_paths) % batch_size == 0):
break
else:
train_img_paths = train_img_paths[:i]
train_labels = train_labels[:i]
i -= 1
while 1:
if (len(validation_img_paths) % batch_size == 0):
break
else:
validation_img_paths = validation_img_paths[:j]
validation_labels = validation_labels[:j]
j -= 1
print("处理后的总共样本数: %d , 处理后的训练样本数: %d, 处理后的验证样本数: %d, 处理后的训练样本标签数: %d, 处理后的验证样本标签数: %d" %
(len(train_img_paths)+len(validation_img_paths), len(train_img_paths), len(validation_img_paths)
, len(train_labels), len(validation_labels)
))
#====================================================
# 4、Sequence调用测试
train_sequence = GarbageDataSequence(train_img_paths, train_labels, batch_size, [input_size, input_size], use_aug=True)
validation_sequence = GarbageDataSequence(validation_img_paths, validation_labels, batch_size, [input_size, input_size], use_aug=False)
return train_sequence, validation_sequence
if __name__ == '__main__':
train_data_dir = "../data/garbage_classify/train_data"
batch_size = 32
train_sequence, validation_sequence = data_from_sequence(train_data_dir, batch_size, num_classes=40, input_size=300)
for i in range(100):
print("第 %d 批次数据" % i)
batch_x, batch_y = train_sequence.__getitem__(i)
print(batch_x, batch_y)
data_gen文件夹 random_eraser.py
import numpy as np
import tensorflow as tf
def get_random_eraser(p=0.5, s_l=0.02, s_h=0.4, r_1=0.3, r_2=1/0.3, v_l=0, v_h=255, pixel_level=False):
def eraser(input_img):
img_h, img_w, img_c = input_img.shape
p_1 = np.random.rand()
if p_1 > p:
return input_img
while True:
s = np.random.uniform(s_l, s_h) * img_h * img_w
r = np.random.uniform(r_1, r_2)
w = int(np.sqrt(s / r))
h = int(np.sqrt(s * r))
left = np.random.randint(0, img_w)
top = np.random.randint(0, img_h)
if left + w <= img_w and top + h <= img_h:
break
if pixel_level:
c = np.random.uniform(v_l, v_h, (h, w, img_c))
else:
c = np.random.uniform(v_l, v_h)
input_img[top:top + h, left:left + w, :] = c
return input_img
return eraserutils文件夹 lr_scheduler.py
import numpy as np
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0):
"""
每批次带有warmup余弦退火学习率计算
:param global_step: 当前到达的步数
:param learning_rate_base: warmup之后的基础学习率
:param total_steps: 总需要批次数
:param warmup_learning_rate: warmup开始的学习率
:param warmup_steps:warmup学习率 步数
:param hold_base_rate_steps: 预留总步数和warmup步数间隔
:return:
"""
if total_steps < warmup_steps:
raise ValueError("总步数要大于wamup步数")
# 1、余弦退火学习率计算
learning_rate = 0.5 * learning_rate_base * (1 + np.cos(
np.pi * (global_step - warmup_steps - hold_base_rate_steps) / float(total_steps - warmup_steps - hold_base_rate_steps)
))
# 2、warmup之后的学习率计算
# 预留步数阶段
# 如果预留大于0,判断目前步数是否 > warmup步数+预留步数,是的话返回刚才上面计算的学习率,不是的话使用warmup之后的基础学习率
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps, learning_rate, learning_rate_base)
# 3、warmup学习率计算,并判断大小
# 第一个阶段的学习率计算
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError("第二阶段学习率要大于第一阶段学习率")
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
warmup_rate = slope * global_step + warmup_learning_rate
learning_rate = np.where(global_step < warmup_steps, warmup_rate, learning_rate)
# 4、如果最后当前到达的步数大于总步数,则归0,否则返回当前的计算出来的学习率(可能是warmup学习率也可能是余弦衰减结果)
return np.where(global_step > total_steps, 0.0, learning_rate)
class WarmUpCosineDecayScheduler(tf.keras.callbacks.Callback):
"""带有warnup的余弦退火学习率实现
"""
def __init__(self,
learning_rate_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
verbose=0):
super(WarmUpCosineDecayScheduler, self).__init__()
self.learning_rate_base = learning_rate_base
self.total_steps = total_steps
self.global_step = global_step_init
self.warmup_learning_rate = warmup_learning_rate
self.warmup_steps = warmup_steps
self.hold_base_rate_steps = hold_base_rate_steps
# 是否在每次训练结束打印学习率
self.verbose = verbose
# 记录所有批次下来的每次准确的学习率,可以用于打印显示
self.learning_rates = []
def on_batch_end(self, batch, logs=None):
# 记录当前训练到走到第几步数
self.global_step = self.global_step + 1
# 记录下所有每次的学习到列表,要统计画图可以使用
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
def on_batch_begin(self, batch, logs=None):
# 计算这批次开始的学习率 lr
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps)
# 设置模型的学习率为lr
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\n批次数 %05d: 设置学习率为'
' %s.' % (self.global_step + 1, lr))
if __name__ == '__main__':
# 1、创建模型
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 2、参数设置
sample_count = 1000 # 样本数
epochs = 4 # 总迭代次数
warmup_epoch = 3 # warmup 迭代次数
batch_size = 16 # 批次大小
learning_rate_base = 0.0001 # warmup后的初始学习率
total_steps = int(epochs * sample_count / batch_size) # 总迭代批次步数
warmup_steps = int(warmup_epoch * sample_count / batch_size) # warmup总批次数
# 3、创建测试数据
data = np.random.random((sample_count, 100))
labels = np.random.randint(10, size=(sample_count, 1))
# 转换目标类别
one_hot_labels = tf.keras.utils.to_categorical(labels, num_classes=10)
# 5、创建余弦warmup调度器
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=4e-06, # warmup开始学习率
warmup_steps=warmup_steps,
hold_base_rate_steps=0,
)
# 训练模型
model.fit(data, one_hot_labels, epochs=epochs, batch_size=batch_size, verbose=0, callbacks=[warm_up_lr])
print(warm_up_lr.learning_rates)EfficientNet模型B0~B7 源码
initializers.py
import numpy as np
import tensorflow as tf
import keras.backend as K
from keras.initializers import Initializer
from keras.utils.generic_utils import get_custom_objects
class EfficientConv2DKernelInitializer(Initializer):
"""Initialization for convolutional kernels.
The main difference with tf.variance_scaling_initializer is that
tf.variance_scaling_initializer uses a truncated normal with an uncorrected
standard deviation, whereas here we use a normal distribution. Similarly,
tf.contrib.layers.variance_scaling_initializer uses a truncated normal with
a corrected standard deviation.
Args:
shape: shape of variable
dtype: dtype of variable
partition_info: unused
Returns:
an initialization for the variable
"""
def __call__(self, shape, dtype=K.floatx(), **kwargs):
kernel_height, kernel_width, _, out_filters = shape
fan_out = int(kernel_height * kernel_width * out_filters)
return tf.random_normal(
shape, mean=0.0, stddev=np.sqrt(2.0 / fan_out), dtype=dtype)
class EfficientDenseKernelInitializer(Initializer):
"""Initialization for dense kernels.
This initialization is equal to
tf.variance_scaling_initializer(scale=1.0/3.0, mode='fan_out',
distribution='uniform').
It is written out explicitly here for clarity.
Args:
shape: shape of variable
dtype: dtype of variable
Returns:
an initialization for the variable
"""
def __call__(self, shape, dtype=K.floatx(), **kwargs):
"""Initialization for dense kernels.
This initialization is equal to
tf.variance_scaling_initializer(scale=1.0/3.0, mode='fan_out',
distribution='uniform').
It is written out explicitly here for clarity.
Args:
shape: shape of variable
dtype: dtype of variable
Returns:
an initialization for the variable
"""
init_range = 1.0 / np.sqrt(shape[1])
return tf.random_uniform(shape, -init_range, init_range, dtype=dtype)
conv_kernel_initializer = EfficientConv2DKernelInitializer()
dense_kernel_initializer = EfficientDenseKernelInitializer()
get_custom_objects().update({
'EfficientDenseKernelInitializer': EfficientDenseKernelInitializer,
'EfficientConv2DKernelInitializer': EfficientConv2DKernelInitializer,
})layers.py
import tensorflow as tf
import tensorflow.keras.backend as K
import tensorflow.keras.layers as KL
from tensorflow.keras.utils import get_custom_objects
"""
import tensorflow as tf
import numpy as np
x=np.array([[1.,8.,7.],[10.,14.,3.],[1.,2.,4.]])
tf.math.sigmoid(x)
tf.compat.v1.disable_eager_execution()
x=np.array([[1.,8.,7.],[10.,14.,3.],[1.,2.,4.]])
tf.nn.swish(x)
----------------------------------------------------------------
1.tf.nn.swish(x) 等同于把 x * tf.sigmoid(beta * x) 封装了。
如果使用了tf.nn.swish(x) 则需要同时使用tf.compat.v1.disable_eager_execution()。
如果使用x * tf.sigmoid(beta * x)来代替tf.nn.swish(x)的话,则可以不使用tf.compat.v1.disable_eager_execution()。
2.但注意此处可能环境问题使用tf.nn.swish(x)的话会报错,所以此处使用x * tf.sigmoid(beta * x)来代替tf.nn.swish(x)
报错信息如下:
tensorflow/core/grappler/utils/graph_view.cc:830] No registered 'swish_f32' OpKernel for GPU devices compatible with node
{{node swish_75/swish_f32}} Registered:
"""
class Swish(KL.Layer):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def call(self, inputs, **kwargs):
# return tf.nn.swish(inputs)
return inputs * tf.math.sigmoid(inputs)
class DropConnect(KL.Layer):
def __init__(self, drop_connect_rate=0., **kwargs):
super().__init__(**kwargs)
self.drop_connect_rate = drop_connect_rate
def call(self, inputs, training=None):
def drop_connect():
keep_prob = 1.0 - self.drop_connect_rate
# Compute drop_connect tensor
batch_size = tf.shape(inputs)[0]
random_tensor = keep_prob
random_tensor += tf.random.uniform([batch_size, 1, 1, 1], dtype=inputs.dtype)
binary_tensor = tf.floor(random_tensor)
output = tf.math.divide(inputs, keep_prob) * binary_tensor
return output
return K.in_train_phase(drop_connect, inputs, training=training)
def get_config(self):
config = super().get_config()
config['drop_connect_rate'] = self.drop_connect_rate
return config
get_custom_objects().update({
'DropConnect': DropConnect,
'Swish': Swish,
}) model.py
# Copyright 2019 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Contains definitions for EfficientNet model.
[1] Mingxing Tan, Quoc V. Le
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.
ICML'19, https://arxiv.org/abs/1905.11946
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import math
import numpy as np
import six
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
import tensorflow.keras.backend as K
import tensorflow.keras.models as KM
import tensorflow.keras.layers as KL
from tensorflow.keras.utils import get_file
from tensorflow.keras.initializers import Initializer
from .layers import Swish, DropConnect
from .params import get_model_params, IMAGENET_WEIGHTS
from .initializers import conv_kernel_initializer, dense_kernel_initializer
__all__ = ['EfficientNet', 'EfficientNetB0', 'EfficientNetB1', 'EfficientNetB2', 'EfficientNetB3',
'EfficientNetB4', 'EfficientNetB5', 'EfficientNetB6', 'EfficientNetB7']
class ConvKernalInitializer(Initializer):
def __call__(self, shape, dtype=K.floatx(), partition_info=None):
"""Initialization for convolutional kernels.
The main difference with tf.variance_scaling_initializer is that
tf.variance_scaling_initializer uses a truncated normal with an uncorrected
standard deviation, whereas here we use a normal distribution. Similarly,
tf.contrib.layers.variance_scaling_initializer uses a truncated normal with
a corrected standard deviation.
Args:
shape: shape of variable
dtype: dtype of variable
partition_info: unused
Returns:
an initialization for the variable
"""
del partition_info
kernel_height, kernel_width, _, out_filters = shape
fan_out = int(kernel_height * kernel_width * out_filters)
return tf.random.normal(
shape, mean=0.0, stddev=np.sqrt(2.0 / fan_out), dtype=dtype)
class DenseKernalInitializer(Initializer):
def __call__(self, shape, dtype=K.floatx(), partition_info=None):
"""Initialization for dense kernels.
This initialization is equal to
tf.variance_scaling_initializer(scale=1.0/3.0, mode='fan_out',
distribution='uniform').
It is written out explicitly here for clarity.
Args:
shape: shape of variable
dtype: dtype of variable
partition_info: unused
Returns:
an initialization for the variable
"""
del partition_info
init_range = 1.0 / np.sqrt(shape[1])
return tf.random_uniform(shape, -init_range, init_range, dtype=dtype)
def round_filters(filters, global_params):
"""Round number of filters based on depth multiplier."""
orig_f = filters
multiplier = global_params.width_coefficient
divisor = global_params.depth_divisor
min_depth = global_params.min_depth
if not multiplier:
return filters
filters *= multiplier
min_depth = min_depth or divisor
new_filters = max(min_depth, int(filters + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_filters < 0.9 * filters:
new_filters += divisor
# print('round_filter input={} output={}'.format(orig_f, new_filters))
return int(new_filters)
def round_repeats(repeats, global_params):
"""Round number of filters based on depth multiplier."""
multiplier = global_params.depth_coefficient
if not multiplier:
return repeats
return int(math.ceil(multiplier * repeats))
def SEBlock(block_args, global_params):
num_reduced_filters = max(
1, int(block_args.input_filters * block_args.se_ratio))
filters = block_args.input_filters * block_args.expand_ratio
if global_params.data_format == 'channels_first':
channel_axis = 1
spatial_dims = [2, 3]
else:
channel_axis = -1
spatial_dims = [1, 2]
def block(inputs):
x = inputs
x = KL.Lambda(lambda a: K.mean(a, axis=spatial_dims, keepdims=True))(x)
x = KL.Conv2D(
num_reduced_filters,
kernel_size=[1, 1],
strides=[1, 1],
kernel_initializer=ConvKernalInitializer(),
padding='same',
use_bias=True
)(x)
x = Swish()(x)
# Excite
x = KL.Conv2D(
filters,
kernel_size=[1, 1],
strides=[1, 1],
kernel_initializer=ConvKernalInitializer(),
padding='same',
use_bias=True
)(x)
x = KL.Activation('sigmoid')(x)
out = KL.Multiply()([x, inputs])
return out
return block
def MBConvBlock(block_args, global_params, drop_connect_rate=None):
batch_norm_momentum = global_params.batch_norm_momentum
batch_norm_epsilon = global_params.batch_norm_epsilon
if global_params.data_format == 'channels_first':
channel_axis = 1
spatial_dims = [2, 3]
else:
channel_axis = -1
spatial_dims = [1, 2]
has_se = (block_args.se_ratio is not None) and (
block_args.se_ratio > 0) and (block_args.se_ratio <= 1)
filters = block_args.input_filters * block_args.expand_ratio
kernel_size = block_args.kernel_size
def block(inputs):
if block_args.expand_ratio != 1:
x = KL.Conv2D(
filters,
kernel_size=[1, 1],
strides=[1, 1],
kernel_initializer=ConvKernalInitializer(),
padding='same',
use_bias=False
)(inputs)
x = KL.BatchNormalization(
axis=channel_axis,
momentum=batch_norm_momentum,
epsilon=batch_norm_epsilon
)(x)
x = Swish()(x)
else:
x = inputs
x = KL.DepthwiseConv2D(
[kernel_size, kernel_size],
strides=block_args.strides,
depthwise_initializer=ConvKernalInitializer(),
padding='same',
use_bias=False
)(x)
x = KL.BatchNormalization(
axis=channel_axis,
momentum=batch_norm_momentum,
epsilon=batch_norm_epsilon
)(x)
x = Swish()(x)
if has_se:
x = SEBlock(block_args, global_params)(x)
# output phase
x = KL.Conv2D(
block_args.output_filters,
kernel_size=[1, 1],
strides=[1, 1],
kernel_initializer=ConvKernalInitializer(),
padding='same',
use_bias=False
)(x)
x = KL.BatchNormalization(
axis=channel_axis,
momentum=batch_norm_momentum,
epsilon=batch_norm_epsilon
)(x)
if block_args.id_skip:
if all(
s == 1 for s in block_args.strides
) and block_args.input_filters == block_args.output_filters:
# only apply drop_connect if skip presents.
if drop_connect_rate:
x = DropConnect(drop_connect_rate)(x)
x = KL.Add()([x, inputs])
return x
return block
def EfficientNet(input_shape, block_args_list, global_params, include_top=True, pooling=None):
batch_norm_momentum = global_params.batch_norm_momentum
batch_norm_epsilon = global_params.batch_norm_epsilon
if global_params.data_format == 'channels_first':
channel_axis = 1
else:
channel_axis = -1
# Stem part
inputs = KL.Input(shape=input_shape)
x = inputs
x = KL.Conv2D(
filters=round_filters(32, global_params),
kernel_size=[3, 3],
strides=[2, 2],
kernel_initializer=ConvKernalInitializer(),
padding='same',
use_bias=False
)(x)
x = KL.BatchNormalization(
axis=channel_axis,
momentum=batch_norm_momentum,
epsilon=batch_norm_epsilon
)(x)
x = Swish()(x)
# Blocks part
block_idx = 1
n_blocks = sum([block_args.num_repeat for block_args in block_args_list])
drop_rate = global_params.drop_connect_rate or 0
drop_rate_dx = drop_rate / n_blocks
for block_args in block_args_list:
assert block_args.num_repeat > 0
# Update block input and output filters based on depth multiplier.
block_args = block_args._replace(
input_filters=round_filters(block_args.input_filters, global_params),
output_filters=round_filters(block_args.output_filters, global_params),
num_repeat=round_repeats(block_args.num_repeat, global_params)
)
# The first block needs to take care of stride and filter size increase.
x = MBConvBlock(block_args, global_params,
drop_connect_rate=drop_rate_dx * block_idx)(x)
block_idx += 1
if block_args.num_repeat > 1:
block_args = block_args._replace(input_filters=block_args.output_filters, strides=[1, 1])
for _ in xrange(block_args.num_repeat - 1):
x = MBConvBlock(block_args, global_params,
drop_connect_rate=drop_rate_dx * block_idx)(x)
block_idx += 1
# Head part
x = KL.Conv2D(
filters=round_filters(1280, global_params),
kernel_size=[1, 1],
strides=[1, 1],
kernel_initializer=ConvKernalInitializer(),
padding='same',
use_bias=False
)(x)
x = KL.BatchNormalization(
axis=channel_axis,
momentum=batch_norm_momentum,
epsilon=batch_norm_epsilon
)(x)
x = Swish()(x)
if include_top:
x = KL.GlobalAveragePooling2D(data_format=global_params.data_format)(x)
if global_params.dropout_rate > 0:
x = KL.Dropout(global_params.dropout_rate)(x)
x = KL.Dense(global_params.num_classes, kernel_initializer=DenseKernalInitializer())(x)
x = KL.Activation('softmax')(x)
else:
if pooling == 'avg':
x = KL.GlobalAveragePooling2D(data_format=global_params.data_format)(x)
elif pooling == 'max':
x = KL.GlobalMaxPooling2D(data_format=global_params.data_format)(x)
outputs = x
model = KM.Model(inputs, outputs)
return model
def _get_model_by_name(model_name, input_shape=None, include_top=True, weights=None, classes=1000, pooling=None):
"""Re-Implementation of EfficientNet for Keras
Reference:
https://arxiv.org/abs/1807.11626
Args:
input_shape: optional, if ``None`` default_input_shape is used
EfficientNetB0 - (224, 224, 3)
EfficientNetB1 - (240, 240, 3)
EfficientNetB2 - (260, 260, 3)
EfficientNetB3 - (300, 300, 3)
EfficientNetB4 - (380, 380, 3)
EfficientNetB5 - (456, 456, 3)
EfficientNetB6 - (528, 528, 3)
EfficientNetB7 - (600, 600, 3)
include_top: whether to include the fully-connected
layer at the top of the network.
weights: one of `None` (random initialization),
'imagenet' (pre-training on ImageNet).
classes: optional number of classes to classify images
into, only to be specified if `include_top` is True, and
if no `weights` argument is specified.
pooling: optional [None, 'avg', 'max'], if ``include_top=False``
add global pooling on top of the network
- avg: GlobalAveragePooling2D
- max: GlobalMaxPooling2D
Returns:
A Keras model instance.
"""
if weights not in {None, 'imagenet'}:
raise ValueError('Parameter `weights` should be one of [None, "imagenet"]')
if weights == 'imagenet' and model_name not in IMAGENET_WEIGHTS:
raise ValueError('There are not pretrained weights for {} model.'.format(model_name))
if weights == 'imagenet' and include_top and classes != 1000:
raise ValueError('If using `weights` and `include_top`'
' `classes` should be 1000')
block_agrs_list, global_params, default_input_shape = get_model_params(
model_name, override_params={'num_classes': classes}
)
if input_shape is None:
input_shape = (default_input_shape, default_input_shape, 3)
model = EfficientNet(input_shape, block_agrs_list, global_params, include_top=include_top, pooling=pooling)
model._name = model_name
if weights:
if not include_top:
weights_name = model_name + '-notop'
else:
weights_name = model_name
weights = IMAGENET_WEIGHTS[weights_name]
weights_path = get_file(
weights['name'],
weights['url'],
cache_subdir='models',
md5_hash=weights['md5'],
)
model.load_weights(weights_path)
return model
def EfficientNetB0(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b0', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB1(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b1', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB2(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b2', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB3(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b3', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB4(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b4', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB5(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b5', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB6(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b6', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
def EfficientNetB7(include_top=True, input_shape=None, weights=None, classes=1000, pooling=None):
return _get_model_by_name('efficientnet-b7', include_top=include_top, input_shape=input_shape,
weights=weights, classes=classes, pooling=pooling)
EfficientNetB0.__doc__ = _get_model_by_name.__doc__
EfficientNetB1.__doc__ = _get_model_by_name.__doc__
EfficientNetB2.__doc__ = _get_model_by_name.__doc__
EfficientNetB3.__doc__ = _get_model_by_name.__doc__
EfficientNetB4.__doc__ = _get_model_by_name.__doc__
EfficientNetB5.__doc__ = _get_model_by_name.__doc__
EfficientNetB6.__doc__ = _get_model_by_name.__doc__
EfficientNetB7.__doc__ = _get_model_by_name.__doc__params.py
import os
import re
import collections
IMAGENET_WEIGHTS = {
'efficientnet-b0': {
'name': 'efficientnet-b0_imagenet_1000.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b0_imagenet_1000.h5',
'md5': 'bca04d16b1b8a7c607b1152fe9261af7',
},
'efficientnet-b0-notop': {
'name': 'efficientnet-b0_imagenet_1000_notop.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b0_imagenet_1000_notop.h5',
'md5': '45d2f3b6330c2401ef66da3961cad769',
},
'efficientnet-b1': {
'name': 'efficientnet-b1_imagenet_1000.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b1_imagenet_1000.h5',
'md5': 'bd4a2b82f6f6bada74fc754553c464fc',
},
'efficientnet-b1-notop': {
'name': 'efficientnet-b1_imagenet_1000_notop.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b1_imagenet_1000_notop.h5',
'md5': '884aed586c2d8ca8dd15a605ec42f564',
},
'efficientnet-b2': {
'name': 'efficientnet-b2_imagenet_1000.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b2_imagenet_1000.h5',
'md5': '45b28b26f15958bac270ab527a376999',
},
'efficientnet-b2-notop': {
'name': 'efficientnet-b2_imagenet_1000_notop.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b2_imagenet_1000_notop.h5',
'md5': '42fb9f2d9243d461d62b4555d3a53b7b',
},
'efficientnet-b3': {
'name': 'efficientnet-b3_imagenet_1000.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b3_imagenet_1000.h5',
'md5': 'decd2c8a23971734f9d3f6b4053bf424',
},
'efficientnet-b3-notop': {
'name': 'efficientnet-b3_imagenet_1000_notop.h5',
'url': 'https://github.com/qubvel/efficientnet/releases/download/v0.0.1/efficientnet-b3_imagenet_1000_notop.h5',
'md5': '1f7d9a8c2469d2e3d3b97680d45df1e1',
},
}
GlobalParams = collections.namedtuple('GlobalParams', [
'batch_norm_momentum', 'batch_norm_epsilon', 'dropout_rate', 'data_format',
'num_classes', 'width_coefficient', 'depth_coefficient',
'depth_divisor', 'min_depth', 'drop_connect_rate',
])
GlobalParams.__new__.__defaults__ = (None,) * len(GlobalParams._fields)
BlockArgs = collections.namedtuple('BlockArgs', [
'kernel_size', 'num_repeat', 'input_filters', 'output_filters',
'expand_ratio', 'id_skip', 'strides', 'se_ratio'
])
# defaults will be a public argument for namedtuple in Python 3.7
# https://docs.python.org/3/library/collections.html#collections.namedtuple
BlockArgs.__new__.__defaults__ = (None,) * len(BlockArgs._fields)
def efficientnet_params(model_name):
"""Get efficientnet params based on model name."""
params_dict = {
# (width_coefficient, depth_coefficient, resolution, dropout_rate)
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
}
return params_dict[model_name]
class BlockDecoder(object):
"""Block Decoder for readability."""
def _decode_block_string(self, block_string):
"""Gets a block through a string notation of arguments."""
assert isinstance(block_string, str)
ops = block_string.split('_')
options = {}
for op in ops:
splits = re.split(r'(\d.*)', op)
if len(splits) >= 2:
key, value = splits[:2]
options[key] = value
if 's' not in options or len(options['s']) != 2:
raise ValueError('Strides options should be a pair of integers.')
return BlockArgs(
kernel_size=int(options['k']),
num_repeat=int(options['r']),
input_filters=int(options['i']),
output_filters=int(options['o']),
expand_ratio=int(options['e']),
id_skip=('noskip' not in block_string),
se_ratio=float(options['se']) if 'se' in options else None,
strides=[int(options['s'][0]), int(options['s'][1])])
def _encode_block_string(self, block):
"""Encodes a block to a string."""
args = [
'r%d' % block.num_repeat,
'k%d' % block.kernel_size,
's%d%d' % (block.strides[0], block.strides[1]),
'e%s' % block.expand_ratio,
'i%d' % block.input_filters,
'o%d' % block.output_filters
]
if block.se_ratio > 0 and block.se_ratio <= 1:
args.append('se%s' % block.se_ratio)
if block.id_skip is False:
args.append('noskip')
return '_'.join(args)
def decode(self, string_list):
"""Decodes a list of string notations to specify blocks inside the network.
Args:
string_list: a list of strings, each string is a notation of block.
Returns:
A list of namedtuples to represent blocks arguments.
"""
assert isinstance(string_list, list)
blocks_args = []
for block_string in string_list:
blocks_args.append(self._decode_block_string(block_string))
return blocks_args
def encode(self, blocks_args):
"""Encodes a list of Blocks to a list of strings.
Args:
blocks_args: A list of namedtuples to represent blocks arguments.
Returns:
a list of strings, each string is a notation of block.
"""
block_strings = []
for block in blocks_args:
block_strings.append(self._encode_block_string(block))
return block_strings
def efficientnet(width_coefficient=None,
depth_coefficient=None,
dropout_rate=0.2,
drop_connect_rate=0.2):
"""Creates a efficientnet model."""
blocks_args = [
'r1_k3_s11_e1_i32_o16_se0.25', 'r2_k3_s22_e6_i16_o24_se0.25',
'r2_k5_s22_e6_i24_o40_se0.25', 'r3_k3_s22_e6_i40_o80_se0.25',
'r3_k5_s11_e6_i80_o112_se0.25', 'r4_k5_s22_e6_i112_o192_se0.25',
'r1_k3_s11_e6_i192_o320_se0.25',
]
global_params = GlobalParams(
batch_norm_momentum=0.99,
batch_norm_epsilon=1e-3,
dropout_rate=dropout_rate,
drop_connect_rate=drop_connect_rate,
data_format='channels_last',
num_classes=1000,
width_coefficient=width_coefficient,
depth_coefficient=depth_coefficient,
depth_divisor=8,
min_depth=None)
decoder = BlockDecoder()
return decoder.decode(blocks_args), global_params
def get_model_params(model_name, override_params=None):
"""Get the block args and global params for a given model."""
if model_name.startswith('efficientnet'):
width_coefficient, depth_coefficient, input_shape, dropout_rate = (
efficientnet_params(model_name))
blocks_args, global_params = efficientnet(
width_coefficient, depth_coefficient, dropout_rate)
else:
raise NotImplementedError('model name is not pre-defined: %s' % model_name)
if override_params:
# ValueError will be raised here if override_params has fields not included
# in global_params.
global_params = global_params._replace(**override_params)
#print('global_params= %s', global_params)
#print('blocks_args= %s', blocks_args)
return blocks_args, global_params, input_shapepreprocessing.py
import numpy as np
from skimage.transform import resize
MEAN_RGB = [0.485 * 255, 0.456 * 255, 0.406 * 255]
STDDEV_RGB = [0.229 * 255, 0.224 * 255, 0.225 * 255]
MAP_INTERPOLATION_TO_ORDER = {
'nearest': 0,
'bilinear': 1,
'biquadratic': 2,
'bicubic': 3,
}
def center_crop_and_resize(image, image_size, crop_padding=32, interpolation='bicubic'):
assert image.ndim in {2, 3}
assert interpolation in MAP_INTERPOLATION_TO_ORDER.keys()
h, w = image.shape[:2]
padded_center_crop_size = int((image_size / (image_size + crop_padding)) * min(h, w))
offset_height = ((h - padded_center_crop_size) + 1) // 2
offset_width = ((w - padded_center_crop_size) + 1) // 2
image_crop = image[offset_height:padded_center_crop_size + offset_height,
offset_width:padded_center_crop_size + offset_width]
resized_image = resize(
image_crop,
(image_size, image_size),
order=MAP_INTERPOLATION_TO_ORDER[interpolation],
preserve_range=True,
)
return resized_image
def preprocess_input(x):
assert x.ndim in (3, 4)
assert x.shape[-1] == 3
x = x - np.array(MEAN_RGB)
x = x / np.array(STDDEV_RGB)
return xwarmup以及余弦退火学习率原理图