Spark Streaming 整合 Flume(Spark读取Flume)
 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
- Impala 操作/读写 Kudu,使用druid连接池
- Kudu 原理、API使用、代码
- Kudu Java API 条件查询
- spark读取kudu表导出数据为parquet文件(spark kudu parquet)
- kudu 导入/导出 数据
- Kudu 分页查询的两种方式
- map、flatMap(流的扁平化)、split 的区别
-
Spark(SparkSql) 写数据到 MySQL中(Spark读取TCP socket/文件)
-
Spark Streaming 整合 Kafka(Spark读取Kafka)
-
Spark Streaming 开窗函数 reduceByKeyAndWindow
-
Spark Streaming 整合 Flume(Spark读取Flume)
-
Spark 实时处理 总文章
- spark程序打包为jar包,并且导出所有第三方依赖的jar包
-
spark提交命令 spark-submit 的参数 executor-memory、executor-cores、num-executors、spark.default.parallelism分析
Spark Streaming整合flume实战
1.flume作为日志实时采集的框架,可以与SparkStreaming实时处理框架进行对接,flume(生产者)实时产生数据,sparkStreaming应用程序(消费者)做实时处理。
Spark Streaming对接FlumeNG有两种方式,一种是FlumeNG将消息Push推给Spark Streaming,还有一种是Spark Streaming从flume 中Poll拉取数据。
2.Poll方式:启动spark-streaming应用程序,通过sinks的port端口为8888 去flume所在机器拉取数据
1.安装flume1.6以上
2.下载依赖包:spark-streaming-flume-sink_2.11-2.0.2.jar 放入到 /root/flume/lib 目录下
3.修改/root/flume/lib目录下的scala依赖包版本:
从/root/spark/jars文件夹下找到scala-library-2.11.8.jar包,替换掉/root/flume/lib目录下自带的scala-library-2.10.1.jar
4.写flume的agent,注意既然是拉取的方式,那么flume向自己所在的机器上产数据就行
5.编写/root/flume/conf/flume-poll-spark.conf配置文件(采集方案)
# 定义这个 agent 中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置 source 组件:r1
##注意:不能往监控目录中重复丢同名文件
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data # 要监控的文件夹所在的目录
a1.sources.r1.fileHeader = true
# 描述和配置 channels 组件c1,此处使用是memory内存缓存的方式
a1.channels.c1.type =memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity=5000
# 描述和配置 sinks 组件:k1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname=NODE1 # 负责汇总数据的服务器的IP地址或主机名
a1.sinks.k1.port = 8888
a1.sinks.k1.batchSize= 2000 # 批处理大小 
6.启动flume:
1.cd /root/flume
2.chmod 777 flume-ng
3.启动命令:bin/flume-ng agent -n a1 -c /root/flume/conf -f /root/flume/conf/flume-poll-spark.conf -Dflume.root.logger=INFO,console
-c conf/ 或 --conf conf/:指定 flume 框架自带的配置文件所在目录名
-f conf/xxx.conf 或 --conf-file conf/xxx.conf:指定我们所自定义创建的采集方案为conf目录下的xxx.conf
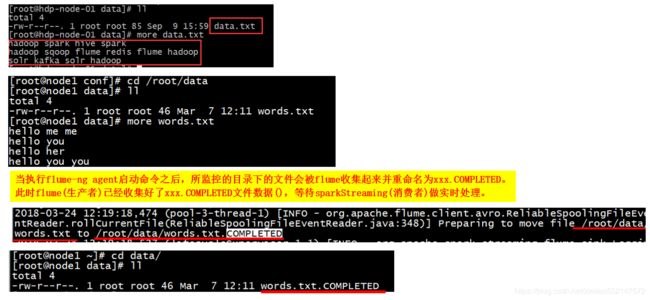
-name agent的名字 或 -n agent的名字:指定我们这个agent 的名字4.服务器上的 /root/data目录下准备数据文件data.txt
5.Poll方式:启动spark-streaming应用程序,去flume所在机器拉取数据
7.spark-streaming应用程序代码实现(Poll方式:启动spark-streaming应用程序,去flume所在机器拉取数据)
org.apache.spark
spark-streaming-flume_2.11
2.0.2
package cn.itcast.Flume
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent}
//Poll方式:启动spark-streaming应用程序,通过sinks的port端口为8888 去flume所在机器拉取数据
object SparkStreamingPollFlume
{
//currentValues:当前批次汇总成的(word,1)中相同单词的所有的1,即汇总当前批次每个单词出现的所有的1,如(hadoop,1) (hadoop,1)(hadoop,1)
//historyValues:历史的所有相同key的value总和,即在之前所有批次中所汇总的每个单词出现的总次数,如(hadoop,3)
def updateFunc(currentValues:Seq[Int], historyValues:Option[Int]):Option[Int] =
{
//Option类型变量调用getOrElse(0)的用法:如果获取不出该变量的值,则返回值默认值0
val newValue: Int = currentValues.sum + historyValues.getOrElse(0)
//{}中的最后一行Some(返回值)作为当前函数的返回值,要求函数返回类型Option类型,而Some为Option的子类。
//当函数的返回类型是Option类型时,那么如果没有返回值时使用None,None是Option的子类,相当于java的null;
//那么如果有值返回时,就使用Some来包含这个值,Some也是Option的子类。
Some(newValue)
}
def main(args: Array[String]): Unit =
{
//1、创建sparkConf
//setMaster("local[2]"):本地模式运行,启动两个线程
//设置master的地址local[N] ,n必须大于1,其中1个线程负责去接受数据,另一线程负责处理接受到的数据
val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingPollFlume").setMaster("local[2]")
//2、创建sparkContext
val sc = new SparkContext(sparkConf)
//设置日志输出的级别
sc.setLogLevel("WARN")
//3、构建StreamingContext对象,每个批处理的时间间隔,即以多少秒内的数据划分为一个批次 ,当前设置 以5秒内的数据 划分为一个批次,
// 每一个batch(批次)就构成一个RDD数据集。DStream就是一个个batch(批次)的有序序列,时间是连续的,
// 按照时间间隔将数据流分割成一个个离散的RDD数据集。
val ssc = new StreamingContext(sc, Seconds(5))
//使用了updateStateByKey方法,就必须设置checkpoint目录,用于缓存中间结果,即把所有批次的结果都先缓存在checkpoint目录中
//设置checkpoint路径,当前项目下有一个flume目录
ssc.checkpoint("./flume")
//4、通过FlumeUtils调用createPollingStream方法获取flume中的数据
// 数据采集方案flume-poll.conf配置文件中配置的sinks的port端口为8888,那么该端口为从flume中取数据的入口
val pollingStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc,"192.168.25.100",8888)
//5、获取flume中event事件的body内容:{"headers":xxxxxx,"body":xxxxx}
val data: DStream[String] = pollingStream.map(x => new String(x.event.getBody.array()))
//6、切分每一行,每个单词计为1
//flatMap(_.split(" ")) 流的扁平化,最终输出的数据类型为一维数组Array[String],所有单词都被分割出来作为一个元素存储到同一个一维数组Array[String]
//map((_,1))每个单词记为1,即(单词,1),表示每个单词封装为一个元祖,其key为单词,value为1,返回MapPartitionRDD数据
val wordAndOne: DStream[(String, Int)] = data.flatMap(_.split(" ")).map((_,1))
//7、累计统计相同单词出现的次数
// 通过updateStateByKey(function函数名)实现所有批次的结果数据进行累加:传入实现累加计数的函数名
//updateStateByKey(func):根据key的之前状态值和key的新值,对key进行更新,返回一个新状态的DStream
val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc)
//8、打印输出
result.print()
//9、开启流式计算
ssc.start()
ssc.awaitTermination()
}
}
8.运行测试:
1.window下启动spark-streaming应用程序
2.然后linux启动flume加载flume配置文件:bin/flume-ng agent -n a1 -c /root/flume/conf -f /root/flume/conf/flume-poll.conf -Dflume.root.logger=INFO,console。
当执行flume-ng agent启动命令之后,所监控的目录下的文件会被flume收集起来并重命名为xxx.COMPLETED。
此时flume(生产者)已经收集好了xxx.COMPLETED文件数据(),等待sparkStreaming(消费者)做实时处理。
3.观察window下IDEA控制台输出
