自然语言情感分析之jieba分词
之前在CNN和RNN几个模型下分别测试了自然语言情感分析的效果(即能够达到的精确度),但那是调用已有的词典还有语言数据也是函数自带的,所以没有达到我们的目标(帮我们判别某句话是正面还是负面)。
分析内容:
用tensorflow进行中文自然语言处理的情感分析 github链接 https://github.com/aespresso/chinese_sentiment
预训练词向量:
北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室的研究者开源的"chinese-word-vectors" github链接为:
https://github.com/Embedding/Chinese-Word-Vectors
具体步骤如下图:

其中第二步采用的分词方法是jieba分词,具体可参考 https://github.com/fxsjy/jieba
其实分词是一个很复杂的过程,首先可能是一个字一个字的切分,但如果相邻词之间能合在一起,则就会把它们合并。比如下面“我喜欢文学”后面还有一个“著作”或“书”字能与“文学”二字合在一起,则会考虑把它们分在一起。(当然这只是个简单的例子,具体分法需要考虑的还很多呢,毕竟中华文化博大精深~)
第三步:根据已有的词典建立索引
相当于平时我们查字典,而且便于计算,平时出现频率越大的词索引也越靠前。
第四步:词向量模型
在这个词向量模型里,每一个词是一个索引,对应的是一个长度为300的向量,我们需要构建的LSTM神经网络模型并不能直接处理汉字文本,需要先进行分次并把词汇转换为词向量。
最后就是放到神经网络上去训练了。
训练语料
使用了谭松波老师的酒店评论语料,训练样本分别被放置在两个文件夹里: 分别的pos和neg,每个文件夹里有2000个txt文件,每个文件内有一段评语,共有4000个训练样本。在上面链接里有。
# 首先加载必用的库
import numpy as np
import matplotlib.pyplot as plt
import re
import jieba # 结巴分词
# gensim用来加载预训练word vector
from gensim.models import KeyedVectors
# 我们使用tensorflow的keras接口来建模
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense, GRU, Embedding, LSTM, Bidirectional
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.optimizers import Adam
from tensorflow.python.keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
from tensorflow.python.keras.preprocessing.text import Tokenizer
from tensorflow.python.keras.optimizers import RMSprop
import warnings
warnings.filterwarnings("ignore")
# 获得样本的索引,样本存放于两个文件夹中,
# 分别为 正面评价'pos'文件夹 和 负面评价'neg'文件夹
# 每个文件夹中有2000个txt文件,每个文件中是一例评价
import os
pos_txts = os.listdir('F:/Desktop/chinese_sentiment-master/pos')
neg_txts = os.listdir('F:/Desktop/chinese_sentiment-master/neg')
# 使用gensim加载预训练中文分词embedding
cn_model = KeyedVectors.load_word2vec_format('F:/Desktop/chinese_sentiment-master/sgns.zhihu.bigram', binary=False)
# 由此可见每一个词都对应一个长度为300的向量
embedding_dim = cn_model['大学'].shape[0]
print('词向量的长度为{}'.format(embedding_dim))
print( '样本总共: '+ str(len(pos_txts) + len(neg_txts)) )
# 现在我们将所有的评价内容放置到一个list里
train_texts_orig = [] # 存储所有评价,每例评价为一条string
# 添加完所有样本之后,train_texts_orig为一个含有4000条文本的list
# 其中前2000条文本为正面评价,后2000条为负面评价
for i in range(len(pos_txts)):
with open('F:/Desktop/chinese_sentiment-master/pos/'+pos_txts[i], 'r', errors='ignore') as f:
text = f.read().strip()
train_texts_orig.append(text)
f.close()
for i in range(len(neg_txts)):
with open('F:/Desktop/chinese_sentiment-master/neg/'+neg_txts[i], 'r', errors='ignore') as f:
text = f.read().strip()
train_texts_orig.append(text)
f.close()
#分词和tokenize
#首先我们去掉每个样本的标点符号,然后用jieba分词,jieba分词返回一个生成器,没法直接进行tokenize,
#所以我们将分词结果转换成一个list,并将它索引化,这样每一例评价的文本变成一段索引数字,对应着预训练词向量模型中的词。
# 进行分词和tokenize
# train_tokens是一个长长的list,其中含有4000个小list,对应每一条评价
train_tokens = []
for text in train_texts_orig:
# 去掉标点
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", text)
# 结巴分词
cut = jieba.cut(text)
# 结巴分词的输出结果为一个生成器
# 把生成器转换为list
cut_list = [ i for i in cut ]
for i, word in enumerate(cut_list):
try:
# 将词转换为索引index
cut_list[i] = cn_model.vocab[word].index
except KeyError:
# 如果词不在字典中,则输出0
cut_list[i] = 0
train_tokens.append(cut_list)
# 获得所有tokens的长度
num_tokens = [ len(tokens) for tokens in train_tokens ]
num_tokens = np.array(num_tokens)
# 平均tokens的长度
np.mean(num_tokens)
# 最长的评价tokens的长度
np.max(num_tokens)
plt.hist(np.log(num_tokens), bins=100)
plt.xlim((0, 10))
plt.ylabel('number of tokens')
plt.xlabel('length of tokens')
plt.title('Distribution of tokens length')
plt.show()
# 取tokens平均值并加上两个tokens的标准差,
# 假设tokens长度的分布为正态分布,则max_tokens这个值可以涵盖95%左右的样本
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
max_tokens = int(max_tokens)
# 取tokens的长度为236时,大约95%的样本被涵盖
# 我们对长度不足的进行padding,超长的进行修剪
np.sum( num_tokens < max_tokens ) / len(num_tokens)
# 用来将tokens转换为文本
def reverse_tokens(tokens):
text1 = ''
for i in tokens:
if i != 0:
text1 = text1 + cn_model.index2word[i]
else:
text1 = text1 + ' '
return text
reverse = reverse_tokens(train_tokens[0])
print(reverse)
# 经过tokenize再恢复成文本
# 可见标点符号都没有了
# 原始文本
a = train_texts_orig[0]
print(a)
# 只使用前20000个词
num_words = 50000
# 初始化embedding_matrix,之后在keras上进行应用
embedding_matrix = np.zeros((num_words, embedding_dim))
# embedding_matrix为一个 [num_words,embedding_dim] 的矩阵
# 维度为 50000 * 300
for i in range(num_words):
embedding_matrix[i, :] = cn_model[cn_model.index2word[i]]
embedding_matrix = embedding_matrix.astype('float32')
# 检查index是否对应,
# 输出300意义为长度为300的embedding向量一一对应
np.sum( cn_model[cn_model.index2word[333]] == embedding_matrix[333] )
# embedding_matrix的维度,
# 这个维度为keras的要求,后续会在模型中用到
print(embedding_matrix.shape)
# 进行padding和truncating, 输入的train_tokens是一个list
# 返回的train_pad是一个numpy array
train_pad = pad_sequences(train_tokens, maxlen=max_tokens, padding='pre', truncating='pre')
# 超出五万个词向量的词用0代替
train_pad[ train_pad>=num_words ] = 0
# 可见padding之后前面的tokens全变成0,文本在最后面
print(train_pad[33])
# 准备target向量,前2000样本为1,后2000为0
train_target = np.concatenate( (np.ones(2000), np.zeros(2000)) )
# 进行训练和测试样本的分割
# 90%的样本用来训练,剩余10%用来测试
X_train, X_test, y_train, y_test = train_test_split(train_pad, train_target, test_size=0.1, random_state=12)
# 查看训练样本,确认无误
print(reverse_tokens(X_train[35]))
print('class: ', y_train[35])
# 用LSTM对样本进行分类
model = Sequential()
# 模型第一层为embedding
model.add(Embedding(num_words,
embedding_dim,
weights=[embedding_matrix],
input_length=max_tokens,
trainable=False))
model.add(Bidirectional(LSTM(units=32, return_sequences=True)))
model.add(LSTM(units=16, return_sequences=False))
# GRU的代码
# model.add(GRU(units=32, return_sequences=True))
# model.add(GRU(units=16, return_sequences=True))
# model.add(GRU(units=4, return_sequences=False))
#Embedding之后第,一层我们用BiLSTM返回sequences,然后第二层16个单元的LSTM不返回sequences,只返回最终结果,
# 最后是一个全链接层,用sigmoid激活函数输出结果。
model.add(Dense(1, activation='sigmoid'))
# 我们使用adam以0.001的learning rate进行优化
optimizer = Adam(lr=1e-3)
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# 我们来看一下模型的结构,一共90k左右可训练的变量
model.summary()
# 建立一个权重的存储点
path_checkpoint = 'sentiment_checkpoint.keras'
checkpoint = ModelCheckpoint(filepath=path_checkpoint, monitor='val_loss',
verbose=1, save_weights_only=True,
save_best_only=True)
# 尝试加载已训练模型
try:
model.load_weights(path_checkpoint)
except Exception as e:
print(e)
# 定义early stoping如果3个epoch内validation loss没有改善则停止训练
earlystopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1)
# 自动降低learning rate
lr_reduction = ReduceLROnPlateau(monitor='val_loss',
factor=0.1, min_lr=1e-5, patience=0,
verbose=1)
# 定义callback函数
callbacks = [
earlystopping,
checkpoint,
lr_reduction
]
# 开始训练
model.fit(X_train, y_train,
validation_split=0.1,
epochs=10,
batch_size=128,
callbacks=callbacks)
result = model.evaluate(X_test, y_test)
print('Accuracy:{0:.2%}'.format(result[1]))
def predict_sentiment(text):
print(text)
# 去标点
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", text)
# 分词
cut = jieba.cut(text)
cut_list = [i for i in cut]
# tokenize
for i, word in enumerate(cut_list):
try:
cut_list[i] = cn_model.vocab[word].index
except KeyError:
cut_list[i] = 0
# padding
tokens_pad = pad_sequences([cut_list], maxlen=max_tokens,
padding='pre', truncating='pre')
# 预测
result = model.predict(x=tokens_pad)
coef = result[0][0]
if coef >= 0.5:
print('是一例正面评价', 'output=%.2f' % coef)
else:
print('是一例负面评价', 'output=%.2f' % coef)
test_list = [
'酒店设施不是新的,服务态度很不好',
'酒店卫生条件非常不好',
'床铺非常舒适',
'房间很凉,不给开暖气',
'房间很凉爽,空调冷气很足',
'酒店环境不好,住宿体验很不好',
'房间隔音不到位',
'晚上回来发现没有打扫卫生',
'因为过节所以要我临时加钱,比团购的价格贵'
]
for text in test_list:
predict_sentiment(text)
y_pred = model.predict(X_test)
y_pred = y_pred.T[0]
y_pred = [1 if p >= 0.5 else 0 for p in y_pred]
y_pred = np.array(y_pred)
y_actual = np.array(y_test)
# 找出错误分类的索引
misclassified = np.where(y_pred != y_actual)[0]
# 输出所有错误分类的索引
len(misclassified)
print(len(X_test))
# 我们来找出错误分类的样本看看
idx = 101
print(reverse_tokens(X_test[idx]))
print('预测的分类', y_pred[idx])
print('实际的分类', y_actual[idx])
idx = 1
print(reverse_tokens(X_test[idx]))
print('预测的分类', y_pred[idx])
print('实际的分类', y_actual[idx])
result:

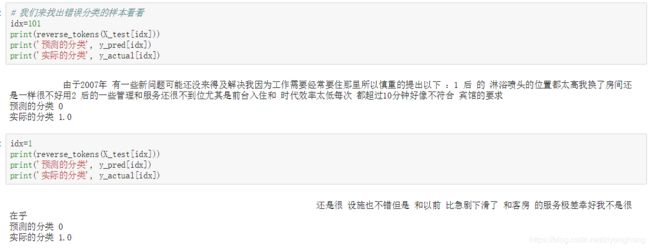
错误分类的文本 经过查看,发现错误分类的文本的含义大多比较含糊,就算人类也不容易判断极性,如index为101的这个句子,好像没有一点满意的成分,但这例子评价在训练样本中被标记成为了正面评价,而我们的模型做出的负面评价的预测似乎是合理的。
what's more,电脑跑了半天都没跑玩,不知是哪里陷入了死循环还是我的电脑配置都被这玩意给吃了 ̄へ ̄,真让人绝望?。