24种设计模式(一)
24种设计模式
第1章 简单工厂
第2章 外观模式
第3章 适配器模式
第4章 单例模式
第5章 工厂方法模式
第6章 抽象工厂模式
第7章 生成器模式
第8章 原型模式
第9章 中介者模式
第10章 代理模式
第11章 观察者模式
第12章 命令模式
Github 源码下载
第1章 简单工厂
1.简单工厂的定义
提供一个创建对象实例的功能,而无须关心其具体实现。被创建实例的类型可以是接口、抽象类,也可以是具体的类。
简单工厂的结构如图所示。

■ Api:定义客户所需要的功能接口。
■ Impl:具体实现Api的实现类,可能会有多个。
■ Factory:工厂,选择合适的实现类来创建Api接口对象。
■ Client:客户端,通过Factory来获取Api接口对象,然后面向Api接口编程。
2.简单工厂示例代码
public class Client {
public static void main(String[] args) {
SimpleFactory factory = new SimpleFactory();
GoodApi goodApi = factory.createGood(1);
goodApi.operation();
}
}
interface GoodApi{
void operation();
}
class GoodA implements GoodApi{
@Override
public void operation() {
System.out.println("GoodA");
}
}
class GoodB implements GoodApi{
@Override
public void operation() {
System.out.println("GoodB");
}
}
class SimpleFactory{
public GoodApi createGood(int type){
GoodApi goodApi = null;
if(type==0){
goodApi = new GoodA();
}else if(type ==1 ){
goodApi = new GoodB();
}
return goodApi;
}
}
3.静态工厂
使用简单工厂的时候,通常不用创建简单工厂类的类实例,没有创建实例的必要。因此可以把简单工厂类实现成一个工具类,直接使用静态方法就可以了。也就是说简单工厂的方法通常是静态的,所以也被称为静态工厂。如果要防止客户端无谓地创造简单工厂实例,还可以把简单工厂的构造方法私有化了。
4.简单工厂命名的建议
■ 类名称建议为“模块名称+Factory”。比如,用户模块的工厂就称为UserFactory。
■ 方法名称通常为“get+接口名称”或者是“create+接口名称”。比如,有一个接口名称为UserEbi,那么方法名称通常为getUserEbi或者是createUserEbi。
5. 可配置的简单工厂
使用配置文件,当有了新的实现类后,只要在配置文件里面配置上新的实现类即可。在简单工厂的方法里面可以使用反射,当然也可以使用IoC/DI(控制反转/依赖注入)来实现。
6 简单工厂的优缺点
简单工厂有以下优点。
■ 帮助封装
简单工厂虽然很简单,但是非常友好地帮助我们实现了组件的封装,然后让组件外部能真正面向接口编程。
■ 解耦
通过简单工厂,实现了客户端和具体实现类的解耦。
如同上面的例子,客户端根本就不知道具体是由谁来实现,
也不知道具体是如何实现的,客户端只是通过工厂获取它需要的接口对象。
简单工厂有以下缺点。
■ 可能增加客户端的复杂度
如果通过客户端的参数来选择具体的实现类,那么就必须让客户端能理解各个参数所代表的具体功能和含义,
这样会增加客户端使用的难度,也部分暴露了内部实现,这种情况可以选用可配置的方式来实现。
■ 不方便扩展子工厂
私有化简单工厂的构造方法,使用静态方法来创建接口,也就不能通过写简单工厂类的子类来改变创建接口的方法的行为了。
不过,通常情况下是不需要为简单工厂创建子类的。
7. 简单工厂的本质
简单工厂的本质是:选择实现。
简单工厂的目的在于为客户端来选择相应的实现,从而使得客户端和实现之间解耦。
第2章 外观模式(Facade)
1.外观模式的定义
外观模式就是通过引入这么一个外观类,在这个类里面定义客户端想要的简单的方法,然后在这些方法的实现里面,由外观类再去分别调用内部的多个模块来实现功能,从而让客户端变得简单。这样一来,客户端就只需要和外观类交互就可以了。
通俗讲就是一个大型系统对外有众多接口,不同的接口属于不同的服务。这对于另一个与其进行交互的系统来管理这么多接口是糟糕的事!故facade模式讲系统所有的接口都汇总到一个接口里(称之为门面),与其交互的系统只需要管理这一个接口就可以。

2. 外观模式示例代码

public class FacadeDemo {
static class Client{
public static void main(String[] args) {
Facade.opreation();
}
}
}
interface ModelA{
void add();
}
interface ModelB{
void delete();
}
interface ModelC{
void update();
}
class ModelAImpl implements ModelA{
@Override
public void add() {
System.out.println("modelA add()");
}
}
class ModelBImpl implements ModelB{
@Override
public void delete() {
System.out.println("modelA delete()");
}
}
class ModelCImpl implements ModelC{
@Override
public void update() {
System.out.println("modelC update()");
}
}
class Facade{
public static void opreation(){
ModelA modelA = new ModelAImpl();
modelA.add();
ModelB modelB = new ModelBImpl();
modelB.delete();
ModelC modelC = new ModelCImpl();
modelC.update();
}
}
3.外观模式的目的
外观模式的目的不是给子系统添加新的功能接口,而是为了让外部减少与子系统内多个模块的交互,松散耦合,从而让外部能够更简单地使用子系统。
4. 外观模式的优缺点
外观模式有如下优点:
■ 松散耦合
外观模式松散了客户端与子系统的耦合关系,让子系统内部的模块能更容易扩展和维护。
■ 简单易用
外观模式让子系统更加易用,客户端不再需要了解子系统内部的实现,也不需要跟众多子系统内部的模块进行交互,
只需要跟外观交互就可以了,相当于外观类为外部客户端使用子系统提供了一站式服务。
■ 更好地划分访问的层次
通过合理使用Facade,可以帮助我们更好地划分访问的层次。
有些方法是对系统外的,有些方法是系统内部使用的。
把需要暴露给外部的功能集中到外观中,这样既方便客户端使用,也很好地隐藏了内部的细节。
外观模式有如下缺点:
过多的或者是不太合理的Facade也容易让人迷惑。到底是调用Facade好呢,还是直接调用模块好。
5.外观模式的本质
外观模式的本质是:封装交互,简化调用。
Facade封装了子系统外部和子系统内部多个模块的交互过程,从而简化了外部的调用。通过外观,子系统为外部提供一些高层的接口,以方便它们的使用。
6.何时选用外观模式
建议在如下情况时选用外观模式。
■ 如果你希望为一个复杂的子系统提供一个简单接口的时候,可以考虑使用外观模式。
使用外观对象来实现大部分客户需要的功能,从而简化客户的使用。
■ 如果想要让客户程序和抽象类的实现部分松散耦合,可以考虑使用外观模式,
使用外观对象来将这个子系统与它的客户分离开来,从而提高子系统的独立性和可移植性。
■ 如果构建多层结构的系统,可以考虑使用外观模式,使用外观对象作为每层的入口,
这样可以简化层间调用,也可以松散层次之间的依赖关系。
第3章 适配器模式(Adapter)
1.适配器模式的定义
将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
2. 适配器模式的结构和说明
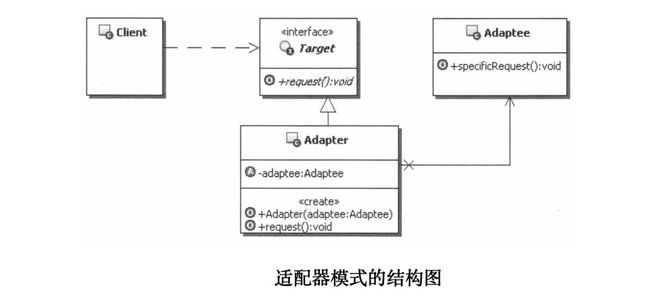
■ Client:客户端,调用自己需要的领域接口Target。
■ Target:定义客户端需要的跟特定领域相关的接口。
■ Adaptee:已经存在的接口,通常能满足客户端的功能要求,但是接口与客户端要求的特定领域接口不一致,需要被适配。
■ Adapter:适配器,把Adaptee适配成为Client需要的Target。
3.示例代码
public class AdapterDemo {
static class Client{
public static void main(String[] args) {
Adaptee adaptee = new Adaptee();
Adapter adapter = new Adapter(adaptee);
adapter.request();
}
}
}
interface Target{
void request();
}
class Adaptee{
public void existingRequest(){
System.out.println("已有接口");
}
}
class Adapter implements Target{
private Adaptee adaptee;
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
@Override
public void request() {
System.out.println("适配现有接口");
adaptee.existingRequest();
}
}
4. 适配器模式的优缺点
适配器模式有如下优点。
■ 更好的复用性
如果功能是已经有了的,只是接口不兼容,那么通过适配器模式就可以让这些功能得到更好的复用。
■ 更好的可扩展性
在实现适配器功能的时候,可以调用自己开发的功能,从而自然地扩展系统的功能。
适配器模式有如下缺点。
■ 过多地使用适配器,会让系统非常零乱,不容易整体进行把握。
5.适配器模式的本质
适配器模式的本质是:转换匹配,复用功能
适配器通过转换调用已有的实现,从而能把已有的实现匹配成需要的接口,使之能满足客户端的需要。也就是说转换匹配是手段,而复用已有的功能才是目的。
6.何时选用适配器模式
建议在以下情况中选用适配器模式。
■ 如果你想要使用一个已经存在的类,但是它的接口不符合你的需求,这种情况可以使用适配器模式,
来把已有的实现转换成你需要的接口。
■ 如果你想创建一个可以复用的类,这个类可能和一些不兼容的类一起工作,这种情况可以使用适配器模式,
到时候需要什么就适配什么。
■ 如果你想使用一些已经存在的子类,但是不可能对每一个子类都进行适配,这种情况可以选用对象适配器,
直接适配这些子类的父类就可以了。
第4章 单例模式(Singleton)
1.单例模式的定义
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
2. 单例模式的结构和说明

Singleton:负责创建Singleton类自己的唯一实例,并提供一个getInstance的方法,让外部来访问这个类的唯一实例。
3. 单例模式示例代码
在Java中,单例模式的实现又分为两种,一种称为懒汉式,一种称为饿汉式,其实就是在具体创建对象实例的处理上,有不同的实现方式。下面分别来看看这两种实现方式的代码示例。
public class SingletonDemo {
public static void main(String[] args) {
System.out.println("懒汉式:");
SluggardSingleton sluggardSingleton = SluggardSingleton.getInstance();
System.out.println("饿汉式");
HungrySingleton hungrySingleton = HungrySingleton.getInstance();
}
}
/**
* 懒汉式
*/
class SluggardSingleton{
private static SluggardSingleton sluggardSingleton = null ;
/**
* 私有化构造器,不能通过new创建
*/
private SluggardSingleton() {
}
public static synchronized SluggardSingleton getInstance(){
if(sluggardSingleton == null){
sluggardSingleton = new SluggardSingleton();
}
return sluggardSingleton;
}
}
/**
* 饿汉式
*/
class HungrySingleton{
private static HungrySingleton hungrySingleton = new HungrySingleton();
private HungrySingleton(){}
public static synchronized HungrySingleton getInstance(){
return hungrySingleton;
}
}
所谓饿汉式,既然饿,那么在创建对象实例的时候就比较着急,饿了嘛,于是就在装载类的时候就创建对象实例。
所谓懒汉式,既然是懒,那么在创建对象实例的时候就不着急,会一直等到马上要使用对象实例的时候才会创建,懒人嘛,总是推托不开的时候才去真正执行工作,因此在装载对象的时候不创建对象实例。
4.单例模式的功能
单例模式是用来保证这个类在运行期间只会被创建一个类实例,另外,单例模式还提供了一个全局唯一访问这个类实例的访问点,就是getInstance方法。不管采用懒汉式还是饿汉式的实现方式,这个全局访问点是一样的。
对于单例模式而言,不管采用何种实现方式,它都是只关心类实例的创建问题,并不关心具体的业务功能。
单例模式的懒汉式实现方式体现了延迟加载的思想。
单例模式的懒汉式实现还体现了缓存的思想,缓存也是实际开发中常见的功能。
5. 单例模式的优缺点
1.时间和空间
比较上面两种写法:懒汉式是典型的时间换空间,也就是每次获取实例都会进行判断,看是否需要创建实例,浪费判断的时间。当然,如果一直没有人使用的话,那就不会创建实例,则节约内存空间。
饿汉式是典型的空间换时间,当类装载的时候就会创建类实例,不管你用不用,先创建出来,然后每次调用的时候,就不需要再判断了,节省了运行时间。
2.线程安全
(1)从线程安全性上讲,不加同步的懒汉式是线程不安全的。
(2)饿汉式是线程安全的,因为虚拟机保证只会装载一次,在装载类的时候是不会发生并发的。
(4)双重检查加锁
所谓双重检查加锁机制,指的是:并不是每次进入getInstance方法都需要同步,而是先不同步,进入方法过后,先检查实例是否存在,如果不存在才进入下面的同步块,这是第一重检查。进入同步块过后,再次检查实例是否存在,如果不存在,就在同步的情况下创建一个实例,这是第二重检查。这样一来,就只需要同步一次了,从而减少了多次在同步情况下进行判断所浪费的时间。
双重检查加锁机制的实现会使用一个关键字volatile,它的意思是:被volatile修饰的变量的值,将不会被本地线程缓存,所有对该变量的读写都是直接操作共享内存,从而确保多个线程能正确的处理该变量。
这种实现方式既可以实现线程安全地创建实例,而又不会对性能造成太大的影响。它只是在第一次创建实例的时候同步,以后就不需要同步了,从而加快了运行速度。
由于volatile关键字可能会屏蔽掉虚拟机中一些必要的代码优化,所以运行效率并不是很高。因此一般建议,没有特别的需要,不要使用。也就是说,虽然可以使用“双重检查加锁”机制来实现线程安全的单例,但并不建议大量采用,可以根据情况来选用。
6. 在Java中一种更好的单例实现方式
■ 什么是类级内部类?
简单点说,类级内部类指的是,有static修饰的成员式内部类。如果没有static修饰的成员式内部类被称为对象级内部类。
■ 类级内部类相当于其外部类的static成分,它的对象与外部类对象间不存在依赖关系,因此可直接创建。而对象级内部类的实例,是绑定在外部对象实例中的。
■ 类级内部类中,可以定义静态的方法。在静态方法中只能够引用外部类中的静态成员方法或者成员变量。
■ 类级内部类相当于其外部类的成员,只有在第一次被使用的时候才会被装载。
在多线程开发中,为了解决并发问题,主要是通过使用synchronized来加互斥锁进行同步控制。但是在某些情况中,JVM已经隐含地为您执行了同步,这些情况下就不用自己再来进行同步控制了。这些情况包括:
■ 由静态初始化器(在静态字段上或static{}块中的初始化器)初始化数据时
■ 访问final字段时
■ 在创建线程之前创建对象时
■ 线程可以看见它将要处理的对象时
6.1 解决方案的思路
要想很简单地实现线程安全,可以采用静态初始化器的方式,它可以由JVM来保证线程的安全性。
一种可行的方式就是采用类级内部类,在这个类级内部类里面去创建对象实例。这样一来,只要不使用到这个类级内部类,那就不会创建对象实例,从而同时实现延迟加载和线程安全。
示例代码:
public class SingletonDemo {
public static void main(String[] args) {
System.out.println("类级内部类方式");
SingletonDemo singletonDemo = SingletonDemo.getInstance();
}
private static class SingletonHolder{
private static SingletonDemo singletonDemo = new SingletonDemo();
}
public static SingletonDemo getInstance(){
return SingletonHolder.singletonDemo;
}
}
当getInstance方法第一次被调用的时候,它第一次读取SingletonHolder.instance,导致SingletonHolder类得到初始化;而这个类在装载并被初始化的时候,会初始化它的静态域,从而创建Singleton的实例,由于是静态的域,因此只会在虚拟机装载类的时候初始化一次,并由虚拟机来保证它的线程安全性。
这个模式的优势在于,getInstance方法并没有被同步,并且只是执行一个域的访问,因此延迟初始化并没有增加任何访问成本。
7.单例模式的本质
单例模式的本质:控制实例数目。
8.何时选用单例模式
建议在如下情况时,选用单例模式。
当需要控制一个类的实例只能有一个,而且客户只能从一个全局访问点访问它时,可以选用单例模式,这些功能恰好是单例模式要解决的问题。
第5章 工厂方法模式 (Factory Method)
1.工厂方法(Factory Method)模式的定义
定义一个用于创建对象的接口,让子类决定实例化哪一个类,使一个类的实例化延迟到其子类。
2. 工厂方法模式的结构和说明
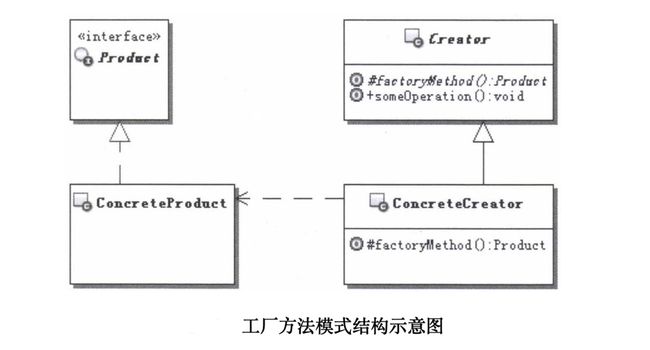
■ Product:定义工厂方法所创建的对象的接口,也就是实际需要使用的对象的接口。
■ ConcreteProduct:具体的Product接口的实现对象。
■ Creator:创建器,声明工厂方法,工厂方法通常会返回一个Product类型的实例对象,而且多是抽象方法。也可以在Creator里面提供工厂方法的默认实现,让工厂方法返回一个缺省的Product类型的实例对象。
■ ConcreteCreator:具体的创建器对象,覆盖实现Creator定义的工厂方法,返回具体的Product实例。
3. 工厂方法模式示例代码
public class FactoryMethodDemo {
public static void main(String[] args) {
Creater creater = new ConcreteCreaterA();
Product productA = creater.factoryMethod();
productA.printLog();
creater = new ConcreteCreaterB();
Product productB = creater.factoryMethod();
productB.printLog();
}
}
interface Product{
void printLog();
}
class ConcreteProductA implements Product{
@Override
public void printLog() {
System.out.println("ConcreteProductA");
}
}
class ConcreteProductB implements Product{
@Override
public void printLog() {
System.out.println("ConcreteProductB");
}
}
abstract class Creater{
protected abstract Product factoryMethod();
public void someOpreations(){}
}
class ConcreteCreaterA extends Creater{
@Override
protected Product factoryMethod() {
return new ConcreteProductA();
}
}
class ConcreteCreaterB extends Creater{
@Override
protected Product factoryMethod() {
return new ConcreteProductB();
}
}
4. 参数化工厂方法
可以改造工厂方法,去除抽象工厂类,参考简单工厂实现参数化工厂方法。
这是一种很常见的参数化工厂方法的实现方式,但是也还是有把参数化工厂方法实现成为抽象的,这点要注意,并不是说参数化工厂方法就不能实现成为抽象类了。只是一般情况下,参数化工厂方法,在父类都会提供默认的实现。
5. 工厂方法模式的优缺点
工厂方法模式的优点
■ 可以在不知具体实现的情况下编程
工厂方法模式可以让你在实现功能的时候,如果需要某个产品对象,只需要使用产品的接口即可,而无需关心具体的实现。选择具体实现的任务延迟到子类去完成。
■ 更容易扩展对象的新版本
工厂方法给子类提供了一个挂钩,使得扩展新的对象版本变得非常容易。比如上面示例的参数化工厂方法实现中,扩展一个新的导出xml文件格式的实现,已有的代码都不会改变,只要新加入一个子类来提供新的工厂方法实现,然后在客户端使用这个新的子类即可。
提示
另外这里提到的挂钩,就是我们经常说的钩子方法(hook),这个会在后面讲模板方法模式的时候详细点说明。
■ 连接平行的类层次
工厂方法除了创造产品对象外,在连接平行的类层次上也大显身手。这个在前面已经详细讲述了。
工厂方法模式的缺点
■ 具体产品对象和工厂方法的耦合性。
在工厂方法模式中,工厂方法是需要创建产品对象的,也就是需要选择具体的产品对象,并创建它们的实例,因此具体产品对象和工厂方法是耦合的。
6. 工厂方法模式的本质
工厂方法模式的本质:延迟到子类来选择实现。
第6章 抽象工厂模式(Abstract Factory)
1. 抽象工厂模式的定义
提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
2. 抽象工厂模式的结构和说明
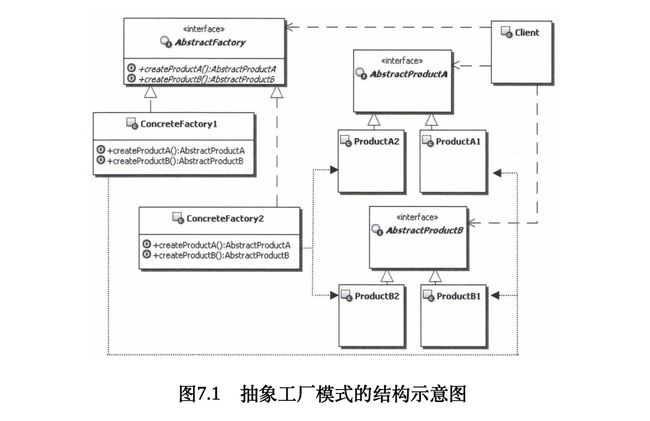
Abstract Factory:抽象工厂,定义创建一系列产品对象的操作接口。
■ Concrete Factory:具体的工厂,实现抽象工厂定义的方法,具体实现一系列产品对象的创建。
■ Abstract Product:定义一类产品对象的接口。
■ Concrete Product:具体的产品实现对象,通常在具体工厂里面,会选择具体的产品实现对象,来创建符合抽象工厂定义的方法返回的产品类型的对象。
■ Client:客户端,主要使用抽象工厂来获取一系列所需要的产品对象,然后面向这些产品对象的接口编程,以实现需要的功能。
3. 抽象工厂模式示例代码
public class AbstractFactoryMethodDemo {
public static void main(String[] args) {
AbstractFactoryMethod abstractFactoryMethod = new ConcreteFactoryMethodA1();
ProductA productA = abstractFactoryMethod.createA();
ProductB productB = abstractFactoryMethod.createB();
productA.printAlog();
productB.printBlog();
abstractFactoryMethod = new ConcreteFactoryMethodB1();
productA = abstractFactoryMethod.createA();
productB = abstractFactoryMethod.createB();
productA.printAlog();
productB.printBlog();
}
}
interface ProductA{
void printAlog();
}
interface ProductB{
void printBlog();
}
class ConcreteProductA1 implements ProductA{
@Override
public void printAlog() {
System.out.println("A1");
}
}
class ConcreteProductA2 implements ProductA{
@Override
public void printAlog() {
System.out.println("A2");
}
}
class ConcreteProductB1 implements ProductB{
@Override
public void printBlog() {
System.out.println("B1");
}
}
class ConcreteProductB2 implements ProductB{
@Override
public void printBlog() {
System.out.println("B2");
}
}
interface AbstractFactoryMethod{
ProductA createA();
ProductB createB();
}
class ConcreteFactoryMethodA1 implements AbstractFactoryMethod{
@Override
public ProductA createA() {
return new ConcreteProductA1();
}
@Override
public ProductB createB() {
return new ConcreteProductB1();
}
}
class ConcreteFactoryMethodB1 implements AbstractFactoryMethod{
@Override
public ProductA createA() {
return new ConcreteProductA2();
}
@Override
public ProductB createB() {
return new ConcreteProductB2();
}
}
4. 抽象工厂模式的优缺点
抽象工厂模式的优点
■ 分离接口和实现
客户端使用抽象工厂来创建需要的对象,而客户端根本就不知道具体的实现是谁,客户端只是面向产品的接口编程而已。也就是说,客户端从具体的产品实现中解耦。
■ 使得切换产品簇变得容易
因为一个具体的工厂实现代表的是一个产品簇,比如上面例子的Scheme1代表装机方案一:Intel的CPU+技嘉的主板,如果要切换成为Scheme2,那就变成了装机方案二:AMD的CPU+微星的主板。
客户端选用不同的工厂实现,就相当于是在切换不同的产品簇。
抽象工厂模式的缺点
■ 不太容易扩展新的产品
前面也提到这个问题了,如果需要给整个产品簇添加一个新的产品,那么就需要修改抽象工厂,这样就会导致修改所有的工厂实现类。在前面提供了一个可以扩展工厂的方式来解决这个问题,但是又不够安全。如何选择,则要根据实际应用来权衡。
■ 容易造成类层次复杂
在使用抽象工厂模式的时候,如果需要选择的层次过多,那么会造成整个类层次变得复杂。
5.抽象工厂模式的本质
抽象工厂模式的本质:选择产品簇的实现。
工厂方法是选择单个产品的实现,虽然一个类里面可以有多个工厂方法,但是这些方法之间一般是没有联系的,即使看起来像有联系。
但是抽象工厂着重的就是为一个产品簇选择实现,定义在抽象工厂里面的方法通常是有联系的,它们都是产品的某一部分或者是相互依赖的。如果抽象工厂里面只定义一个方法,直接创建产品,那么就退化成为工厂方法了。
6.何时选用抽象工厂模式
建议在以下情况中选用抽象工厂模式。
■ 如果希望一个系统独立于它的产品的创建、组合和表示的时候。换句话说,希望一个系统只是知道产品的接口,而不关心实现的时候。
■ 如果一个系统要由多个产品系列中的一个来配置的时候。换句话说,就是可以动态地切换产品簇的时候。
■ 如果要强调一系列相关产品的接口,以便联合使用它们的时候。
第7章 生成器模式(Builder)
1.生成器模式的定义
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
2. 生成器模式的结构和说明
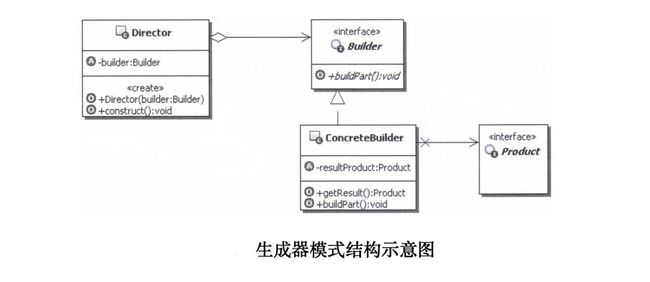
■ Builder:生成器接口,定义创建一个Product对象所需的各个部件的操作。
■ ConcreteBuilder:具体的生成器实现,实现各个部件的创建,并负责组装Product对象的各个部件,同时还提供一个让用户获取组装完成后的产品对象的方法。
■ Director:指导者,也被称为导向者,主要用来使用Builder接口,以一个统一的过程来构建所需要的Product对象。
■ Product:产品,表示被生成器构建的复杂对象,包含多个部件。
3. 生成器模式示例代码
public class BuilderDemo {
public static void main(String[] args) {
Builder builder = new ConcreteBuilder();
Director director = new Director(builder);
director.construct();
}
}
interface BuildProduct{
void someMethod();
}
interface Builder{
void buildPart();
}
class ConcreteBuilder implements Builder{
private String buildResult = null;
public String getBuildResult() {
return buildResult;
}
@Override
public void buildPart() {
System.out.println("构建产品细节。。。");
}
}
class Director{
private Builder builder;
public Director(Builder builder) {
this.builder = builder;
}
public void construct(){
builder.buildPart();
}
}
4. 生成器模式的优点
■ 松散耦合
生成器模式可以用同一个构建算法构建出表现上完全不同的产品,实现产品构建和产品表现上的分离。生成器模式正是把产品构建的过程独立出来,使它和具体产品的表现松散耦合,从而使得构建算法可以复用,而具体产品表现也可以灵活地、方便地扩展和切换。
■ 可以很容易地改变产品的内部表示
在生成器模式中,由于Builder对象只是提供接口给Director使用,那么具体的部件创建和装配方式是被Builder接口隐藏了的,Director并不知道这些具体的实现细节。这样一来,要想改变产品的内部表示,只需要切换Builder的具体实现即可,不用管Director,因此变得很容易。
■ 更好的复用性
生成器模式很好地实现了构建算法和具体产品实现的分离。这样一来,使得构建产品的算法可以复用。同样的道理,具体产品的实现也可以复用,同一个产品的实现,可以配合不同的构建算法使用。
5.生成器模式的本质
生成器模式的本质:分离整体构建算法和部件构造。
构建一个复杂的对象,本来就有构建的过程,以及构建过程中具体的实现。生成器模式就是用来分离这两个部分,从而使得程序结构更松散、扩展更容易、复用性更好,同时也会使得代码更清晰,意图更明确。
6.何时选用生成器模式
建议在以下情况中选用生成器模式。
■ 如果创建对象的算法,应该独立于该对象的组成部分以及它们的装配方式时。
■ 如果同一个构建过程有着不同的表示时。
第8章 原型模式(Prototype)
1.原型模式的定义
用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象。
2. 原型模式的结构和说明
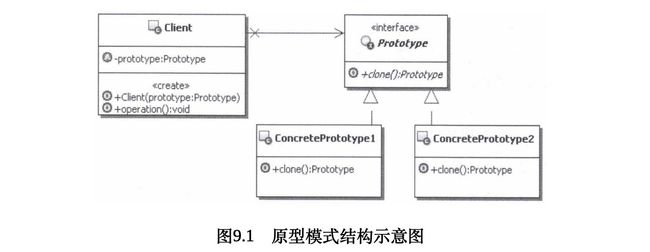
■ Prototype:声明一个克隆自身的接口,用来约束想要克隆自己的类,要求它们都要实现这里定义的克隆方法。
■ ConcretePrototype:实现Prototype接口的类,这些类真正实现了克隆自身的功能。
■ Client:使用原型的客户端,首先要获取到原型实例对象,然后通过原型实例克隆自身来创建新的对象实例。
3. 原型模式示例代码
public class PrototypeDemo {
public static void main(String[] args) {
Prototype prototypeA = new PrototypeA();
prototypeA.setName("tom");
System.out.println(prototypeA.getName());
Client client = new Client(prototypeA);
client.someOperation();
}
}
interface Prototype{
String getName();
void setName(String name);
Prototype clone();
}
class PrototypeA implements Prototype{
private String name ;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public Prototype clone() {
Prototype prototypeA = new PrototypeA();
return prototypeA;
}
}
class PrototypeB implements Prototype{
private String name ;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public Prototype clone() {
Prototype prototypeB = new PrototypeA();
return prototypeB;
}
}
class Client{
private Prototype prototype;
public Client(Prototype prototype) {
this.prototype = prototype;
}
public Prototype someOperation(){
Prototype newPrototype = prototype.clone();
newPrototype.setName("liom");
System.out.println(newPrototype.getName());
return newPrototype;
}
}
4.原型模式的功能
原型模式的功能实际上包含两个方面:
■ 一个是通过克隆来创建新的对象实例;
■ 另一个是为克隆出来的新的对象实例复制原型实例属性的值。
5. Java中的克隆方法
需要克隆功能的类,只需要实现java.lang.Cloneable接口,这个接口没有需要实现的方法,是一个标识接口。
6. 浅度克隆和深度克隆
■ 浅度克隆:只负责克隆按值传递的数据(比如基本数据类型、String类型)。
■ 深度克隆:除了浅度克隆要克隆的值外,还负责克隆引用类型的数据,基本上就是被克隆实例所有的属性数据都会被克隆出来。
7. 原型模式的优缺点
原型模式的优点:
■ 对客户端隐藏具体的实现类型
原型模式的客户端只知道原型接口的类型,并不知道具体的实现类型,从而减少了客户端对这些具体实现类型的依赖。
■ 在运行时动态改变具体的实现类型
原型模式可以在运行期间,由客户来注册符合原型接口的实现类型,也可以动态地改变具体的实现类型,看起来接口没有任何变化,但其实运行的已经是另外一个类实例了。因为克隆一个原型就类似于实例化一个类。
原型模式的缺点
原型模式最大的缺点就在于每个原型的子类都必须实现clone的操作,尤其在包含引用类型的对象时,clone方法会比较麻烦,必须要能够递归地让所有的相关对象都要正确地实现克隆。
8.原型模式的本质
原型模式的本质:克隆生成对象。
克隆是手段,目的是生成新的对象实例。正是因为原型的目的是为了生成新的对象实例,原型模式通常是被归类为创建型的模式。
原型模式也可以用来解决“只知接口而不知实现的问题”,使用原型模式,可以出现一种独特的“接口造接口”的景象,这在面向接口编程中很有用。同样的功能也可以考虑使用工厂来实现。
另外,原型模式的重心还是在创建新的对象实例,至于创建出来的对象,其属性的值是否一定要和原型对象属性的值完全一样,这个并没有强制规定,只不过在目前大多数实现中,克隆出来的对象和原型对象的属性值是一样的。
也就是说,可以通过克隆来创造值不一样的实例,但是对象类型必须一样。可以有部分甚至是全部的属性的值不一样,可以有选择性地克隆,就当是标准原型模式的一个变形使用吧。
9.何时选用原型模式
建议在以下情况时选用原型模式。
■ 如果一个系统想要独立于它想要使用的对象时,可以使用原型模式,让系统只面向接口编程,在系统需要新的对象的时候,可以通过克隆原型来得到。
■ 如果需要实例化的类是在运行时刻动态指定时,可以使用原型模式,通过克隆原型来得到需要的实例。
第9章 中介者模式(Mediator)
1.中介者模式的定义
用一个中介对象来封装一系列的对象交互。中介者使得各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
2. 中介者模式的结构和说明

■ Mediator:中介者接口。在里面定义各个同事之间交互需要的方法,可以是公共的通信方法,比如changed方法,大家都用,也可以是小范围的交互方法。
■ ConcreteMediator:具体中介者实现对象。它需要了解并维护各个同事对象,并负责具体的协调各同事对象的交互关系。
■ Colleague:同事类的定义,通常实现成为抽象类,主要负责约束同事对象的类型,并实现一些具体同事类之间的公共功能,比如,每个具体同事类都应该知道中介者对象,也就是具体同事类都会持有中介者对象,都可以定义到这个类里面。
■ ConcreteColleague:具体的同事类,实现自己的业务,在需要与其他同事通信的时候,就与持有的中介者通信,中介者会负责与其他的同事交互。
3. 中介者模式示例代码
public class MediatorDemo {
public static void main(String[] args) {
Mediator mediator = new ConcreteMediator();
ColleagueA colleague = new ColleagueA(mediator);
colleague.someOperation();
ColleagueB colleagueB = new ColleagueB(mediator);
colleagueB.someOperation();
}
}
interface Mediator{
void changed(Colleague colleague);
}
abstract class Colleague{
private Mediator mediator;
public Colleague(Mediator mediator) {
this.mediator = mediator;
}
public Mediator getMediator() {
return mediator;
}
}
class ColleagueA extends Colleague{
public ColleagueA(Mediator mediator) {
super(mediator);
}
public void someOperation(){
getMediator().changed(this);
}
}
class ColleagueB extends Colleague{
public ColleagueB(Mediator mediator) {
super(mediator);
}
public void someOperation(){
getMediator().changed(this);
}
}
class ConcreteMediator implements Mediator{
@Override
public void changed(Colleague colleague) {
if(colleague instanceof ColleagueA){
System.out.println("完成与A的交互操作");
}else if (colleague instanceof ColleagueB){
System.out.println("完成与B的交互操作");
}
}
}
4. 中介者模式的优缺点
中介者模式的优点。
■ 松散耦合
中介者模式通过把多个同事对象之间的交互封装到中介者对象里面,从而使得同事对象之间松散耦合,
基本上可以做到互不依赖。
这样一来,同事对象就可以独立地变化和复用,而不再像以前那样“牵一发而动全身”了。
■ 集中控制交互
多个同事对象的交互,被封装在中介者对象里面集中管理,使得这些交互行为发生变化的时候,
只需要修改中介者对象就可以了,当然如果是已经做好的系统,那就扩展中介者对象,
而各个同事类不需要做修改。
■ 多对多变成一对多
没有使用中介者模式的时候,同事对象之间的关系通常是多对多的,引入中介者对象以后,
中介者对象和同事对象的关系通常变成了双向的一对多,这会让对象的关系更容易理解和实现。
中介者模式的缺点。
中介者模式的一个潜在缺点是,过度集中化。如果同事对象的交互非常多,而且比较复杂,
当这些复杂性全部集中到中介者的时候,会导致中介者对象变得十分复杂,而且难于管理和维护。
5.中介者模式的本质
中介者模式的本质:封装交互。
中介者模式的目的,就是用来封装多个对象的交互,这些交互的处理多在中介者对象里面实现。因此中介对象的复杂程度,就取决于它封装的交互的复杂程度。
6.何时选用中介者模式
建议在以下情况时选用中介者模式。
■ 如果一组对象之间的通信方式比较复杂,导致相互依赖、结构混乱,可以采用中介者模式,把这些对象相互的交互管理起来,各个对象都只需要和中介者交互,从而使得各个对象松散耦合,结构也更清晰易懂。
■ 如果一个对象引用很多的对象,并直接跟这些对象交互,导致难以复用该对象,可以采用中介者模式,把这个对象跟其他对象的交互封装到中介者对象里面,这个对象只需要和中介者对象交互就可以了。
第10章 代理模式(Proxy)
1.代理模式的定义
为其他对象提供一种代理以控制对这个对象的访问。
2. 代理模式的结构和说明

■ Proxy:代理对象,通常具有如下功能。
实现与具体的目标对象一样的接口,这样就可以使用代理来代替具体的目标对象。保存一个指向具体目标对象的引用,可以在需要的时候调用具体的目标对象。
可以控制对具体目标对象的访问,并可以负责创建和删除它。
■ Subject:目标接口,定义代理和具体目标对象的接口,这样就可以在任何使用具体目标对象的地方使用代理对象。
■ RealSubject:具体的目标对象,真正实现目标接口要求的功能。
3. 代理模式示例代码
public class ProxyDemo {
public static void main(String[] args) {
RealSubject realSubject = new RealSubject();
Proxy proxy = new Proxy(realSubject);
proxy.request();
}
}
interface Subject{
void request();
}
class RealSubject implements Subject{
@Override
public void request() {
System.out.println("realSubject");
}
}
class Proxy implements Subject{
private RealSubject realSubject;
public Proxy(RealSubject realSubject) {
this.realSubject = realSubject;
}
@Override
public void request() {
System.out.println("开始请求前做一些校验操作。。。");
System.out.println("校验完成!");
realSubject.request();
System.out.println("请求结束做一些处理事宜。。。");
System.out.println("处理完成");
}
}
4.代理的分类
事实上代理又被分成多种,大致有如下一些:
■ 虚代理:根据需要来创建开销很大的对象,该对象只有在需要的时候才会被真正创建。
■ 远程代理:用来在不同的地址空间上代表同一个对象,这个不同的地址空间可以是在本机,也可以在其他机器上。在Java里面最典型的就是RMI技术。
■ copy-on-write代理:在客户端操作的时候,只有对象确实改变了,才会真的拷贝(或克隆)一个目标对象,算是虚代理的一个分支。
■ 保护代理:控制对原始对象的访问,如果有需要,可以给不同的用户提供不同的访问权限,以控制他们对原始对象的访问。
■ Cache代理:为那些昂贵操作的结果提供临时的存储空间,以便多个客户端可以共享这些结果。
■ 防火墙代理:保护对象不被恶意用户访问和操作。
■ 同步代理:使多个用户能够同时访问目标对象而没有冲突。
■ 智能指引:在访问对象时执行一些附加操作,比如,对指向实际对象的引用计数、第一次引用一个持久对象时,将它装入内存等。
5. Java中的代理
Java对代理模式提供了内建的支持,在java.lang.reflect包下面,提供了一个Proxy的类和一个InvocationHandler的接口。
6.代理模式的本质
代理模式的本质:控制对象访问。
代理模式通过代理目标对象,把代理对象插入到客户和目标对象之间,从而为客户和目标对象引入一定的间接性。正是这个间接性,给了代理对象很多的活动空间。代理对象可以在调用具体的目标对象前后,附加很多操作,从而实现新的功能或是扩展目标对象的功能。更狠的是,代理对象还可以不去创建和调用目标对象,也就是说,目标对象被完全代理掉了,或是被替换掉了。
从实现上看,代理模式主要是使用对象的组合和委托,尤其是在静态代理的实现里面,会看得更清楚。但是也可以采用对象继承的方式来实现代理,这种实现方式在某些情况下,比使用对象组合还要来得简单。
7.何时选用代理模式
建议在如下情况中选用代理模式。
■ 需要为一个对象在不同的地址空间提供局部代表的时候,可以使用远程代理。
■ 需要按照需要创建开销很大的对象的时候,可以使用虚代理。
■ 需要控制对原始对象的访问的时候,可以使用保护代理。
■ 需要在访问对象执行一些附加操作的时候,可以使用智能指引代理。
第11章 观察者模式(Observer)
1.观察者模式的定义
定义对象间的一种一对多的依赖关系。当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
2. 观察者模式的结构和说明

■ Subject:目标对象,通常具有如下功能。
◆ 一个目标可以被多个观察者观察。
◆ 目标提供对观察者注册和退订的维护。
◆ 当目标的状态发生变化时,目标负责通知所有注册的、有效的观察者。
■ Observer:定义观察者的接口,提供目标通知时对应的更新方法,这个更新方法进行相应的业务处理,可以在这个方法里面回调目标对象,以获取目标对象的数据。
■ ConcreteSubject:具体的目标实现对象,用来维护目标状态,当目标对象的状态发生改变时,通知所有注册的、有效的观察者,让观察者执行相应的处理。
■ ConcreteObserver:观察者的具体实现对象,用来接收目标的通知,并进行相应的后续处理,比如更新自身的状态以保持和目标的相应状态一致。
3. 使用观察者模式实现示例
import java.util.ArrayList;
import java.util.List;
public class ObserverDemo {
public static void main(String[] args) {
ConcreateObserver concreateObserver = new ConcreateObserver();
concreateObserver.setObserverState("202");
System.out.println(concreateObserver.getObserverState());
ConcreateSubject subjectA = new ConcreateSubject();
subjectA.attach(concreateObserver);
subjectA.setSubjectState("404");
System.out.println(concreateObserver.getObserverState());
subjectA.detach(concreateObserver);
subjectA.setSubjectState("500");
System.out.println(concreateObserver.getObserverState());
}
}
interface Observer{
void update(SubjectA subject);
}
class SubjectA{
private List observerList = new ArrayList();
//注册
public void attach(Observer observer){
observerList.add(observer);
}
//注销
public void detach(Observer observer){
observerList.remove(observer);
}
public void notifyObservers(){
for(Observer observer : observerList){
observer.update(this);
}
}
}
class ConcreateSubject extends SubjectA{
private String subjectState;
public String getSubjectState() {
return subjectState;
}
public void setSubjectState(String subjectState) {
this.subjectState = subjectState;
this.notifyObservers();
}
}
class ConcreateObserver implements Observer{
private String ObserverState;
@Override
public void update(SubjectA subject) {
ObserverState = ((ConcreateSubject)subject).getSubjectState();
}
public String getObserverState() {
return ObserverState;
}
public void setObserverState(String observerState) {
ObserverState = observerState;
}
}
4. 推模型和拉模型
在观察者模式的实现中,又分为推模型和拉模型两种方式。
■ 推模型
目标对象主动向观察者推送目标的详细信息,不管观察者是否需要,推送的信息通常是目标对象的全部或部分数据,相当于是在广播通信。
■ 拉模型
目标对象在通知观察者的时候,只传递少量信息。如果观察者需要更具体的信息,由观察者主动到目标对象中获取,相当于是观察者从目标对象中拉数据。一般这种模型的实现中,会把目标对象自身通过update方法传递给观察者,这样在观察者需要获取数据的时候,就可以通过这个引用来获取了。
5. 观察者模式的优缺点
观察者模式具有以下优点。
■ 观察者模式实现了观察者和目标之间的抽象耦合
原本目标对象在状态发生改变的时候,需要直接调用所有的观察者对象,但是抽象出观察者接口以后,目标和观察者就只是在抽象层面上耦合了,也就是说目标只是知道观察者接口,并不知道具体的观察者的类,从而实现目标类和具体的观察者类之间解耦。
■ 观察者模式实现了动态联动
所谓联动,就是做一个操作会引起其他相关的操作。由于观察者模式对观察者注册实行管理,那就可以在运行期间,通过动态地控制注册的观察者,来控制某个动作的联动范围,从而实现动态联动。
■ 观察者模式支持广播通信
由于目标发送通知给观察者是面向所有注册的观察者,所以每次目标通知的信息就要对所有注册的观察者进行广播。当然,也可以通过在目标上添加新的功能来限制广播的范围。
在广播通信的时候要注意一个问题,就是相互广播造成死循环的问题。比如A和B两个对象互为观察者和目标对象,A对象发生状态变化,然后A来广播信息,B对象接收到通知后,在处理过程中,使得B对象的状态也发生了改变,然后B来广播信息,然后A对象接到通知后,又触发广播信息……,如此A引起B变化,B又引起A变化,从而一直相互广播信息,就造成死循环。
观察者模式的缺点是:
■ 可能会引起无谓的操作
由于观察者模式每次都是广播通信,不管观察者需不需要,每个观察者都会被调用update方法,如果观察者不需要执行相应处理,那么这次操作就浪费了。其实浪费了还好,最怕引起误更新,那就麻烦了,比如,本应该在执行这次状态更新前把某个观察者删除掉,这样通知的时候就没有这个观察者了,但是现在忘掉了,那么就会引起误操作。
6. 观察者模式的本质
观察者模式的本质:触发联动。
当修改目标对象的状态的时候,就会触发相应的通知,然后会循环调用所有注册的观察者对象的相应方法,其实就相当于联动调用这些观察者的方法。
而且这个联动还是动态的,可以通过注册和取消注册来控制观察者,因而可以在程序运行期间,通过动态地控制观察者,来变相地实现添加和删除某些功能处理,这些功能就是观察者在update的时候执行的功能。
同时目标对象和观察者对象的解耦,又保证了无论观察者发生怎样的变化,目标对象总是能够正确地联动过来。
7.何时选用观察者模式
建议在以下情况中选用观察者模式。
■ 当一个抽象模型有两个方面,其中一个方面的操作依赖于另一个方面的状态变化,那么就可以选用观察者模式,将这两者封装成观察者和目标对象,当目标对象变化的时候,依赖于它的观察者对象也会发生相应的变化。这样就把抽象模型的这两个方面分离开了,使得它们可以独立地改变和复用。
■ 如果在更改一个对象的时候,需要同时连带改变其他的对象,而且不知道究竟应该有多少对象需要被连带改变,这种情况可以选用观察者模式,被更改的那一个对象很明显就相当于是目标对象,而需要连带修改的多个其他对象,就作为多个观察者对象了。
■ 当一个对象必须通知其他的对象,但是你又希望这个对象和其他被它通知的对象是松散耦合的。也就是说这个对象其实不想知道具体被通知的对象。这种情况可以选用观察者模式,这个对象就相当于是目标对象,而被它通知的对象就是观察者对象了。
第12章 命令模式(Command)
1.命令模式的定义
将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。
2. 命令模式的结构和说明

■ Command:定义命令的接口,声明执行的方法。
■ ConcreteCommand:命令接口实现对象,是“虚”的实现;通常会持有接收者,并调用接收者的功能来完成命令要执行的操作。
■ Receiver:接收者,真正执行命令的对象。任何类都可能成为一个接收者,只要它能够实现命令要求实现的相应功能。
■ Invoker:要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应操作的地方,也就是说相当于使用命令对象的入口。
■ Client:创建具体的命令对象,并且设置命令对象的接收者。注意这个不是我们常规意义上的客户端,而是在组装命令对象和接收者,或许,把这个Client称为装配者会更好理解,因为真正使用命令的客户端是从Invoker来触发执行。
3. 命令模式示例代码
public class CommandDemo {
public static void main(String[] args) {
Receiver receiver = new Receiver();
Command command = new ConcreateCommand(receiver);
Invoker invoker = new Invoker();
invoker.setCommand(command);
invoker.runCommand();
}
}
interface Command{
void execute();
}
class Receiver{
public void action(){
System.out.println("do something...");
}
}
class ConcreateCommand implements Command{
//命令自身状态
private String state;
private Receiver receiver;
public ConcreateCommand(Receiver receiver) {
this.receiver = receiver;
}
@Override
public void execute() {
receiver.action();
}
}
class Invoker{
private Command command;
public void setCommand(Command command) {
this.command = command;
}
public void runCommand(){
command.execute();
}
}
4. 命令模式的优点
■ 更松散的耦合
命令模式使得发起命令的对象——客户端,和具体实现命令的对象——接收者对象完全解耦,也就是说发起命令的对象完全不知道具体实现对象是谁,也不知道如何实现。
■ 更动态的控制
命令模式把请求封装起来,可以动态地对它进行参数化、队列化和日志化等操作,从而使得系统更灵活。
■ 很自然的复合命令
命令模式中的命令对象能够很容易地组合成复合命令,也就是前面讲的宏命令,从而使系统操作更简单,功能更强大。
■ 更好的扩展性
由于发起命令的对象和具体的实现完全解耦,因此扩展新的命令就很容易,只需要实现新的命令对象,然后在装配的时候,把具体的实现对象设置到命令对象中,然后就可以使用这个命令对象,已有的实现完全不用变化。
5.命令模式的本质
命令模式的本质:封装请求。
6.何时选用命令模式
建议在以下情况时选用命令模式。
■ 如果需要抽象出需要执行的动作,并参数化这些对象,可以选用命令模式。
将这些需要执行的动作抽象成为命令,然后实现命令的参数化配置。
■ 如果需要在不同的时刻指定、排列和执行请求,可以选用命令模式。
将这些请求封装成为命令对象,然后实现将请求队列化。
■ 如果需要支持取消操作,可以选用命令模式,通过管理命令对象,能很容易地实现命令的恢复和重做功能。
■ 如果需要支持当系统崩溃时,能将系统的操作功能重新执行一遍,可以选用命令模式。
将这些操作功能的请求封装成命令对象,然后实现日志命令,就可以在系统恢复以后,通过日志获取命令列表,从而重新执行一遍功能。
■ 在需要事务的系统中,可以选用命令模式。命令模式提供了对事务进行建模的方法。命令模式有一个别名就是Transaction。