强化学习初印象
由于工作需要,今天要了解一下强化学习。虽然之前Alpha Go和星际游戏的AI新闻让我对强化学习如雷贯耳,但从来没有想到过和自己联系在一起。机器学习有本好书是周志华的《机器学习》,通俗易懂,正好最后一个章节就是讲的是强化学习,觉得是比较适合自己的入门好资料。果然,通读之后对强化学习的基本概念和算法有了个初印象,感觉很有收获,不过为了以后查阅方便,在这里算作笔记吧。
1. 强化学习的一般定义
强化学习通常用马尔可夫决策过程(Markov Decision Process, MDP)表示; 环境E, 状态空间X,动作空间A,状态x经动作a后由转移函数P转移到另一个状态x’;在状态转移的同时,环境会根据反馈函数R给机器一个奖赏r。即强化学习任务对应四元组E=
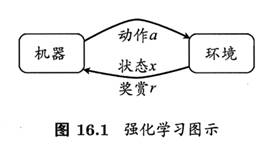
机器要做的是通过在环境中不断地尝试而学得一个“策略”,根据这个策略F,在状体x下就能得知要执行的动作a=F(x)。策略有两种表示方法:一种是确定性策略F:X->A;另一种是概率策略F:X*A->R。策略的优劣取决于长期执行这一策略后得到的累计奖赏。强化学习的目的就是要找到能使长期累积奖赏最大化的策略。长期累积奖赏的计算方法有两种:a) T步累积奖赏;b)gama折扣累积奖赏。
强化学习与监督学习的异同:1)强化学习的状态对应监督学习的“示例”或样本,“动作”对应监督学习的“标记”,强化学习的“策略”对应监督学习的“分类器”。2)不同的是强化学习没有标记好的样本,而是通过采取动作后的反馈来学习之前的动过是否合理,即强化学习的标记是学习而来的,具有延迟的。
2. 强化学习模型
强化学习如何最大化长期累积奖赏呢?有三种策略:1. 最大化单步奖赏的贪心策略;2. 有模型的动态规划算法;3. 免模型学习。
2.1 单步奖赏的贪心策略
欲最大化单步奖赏需考虑两个方面:1.需要知道每个动作带来的奖赏,这通常不是一个确定值,而是来自一个概率分布;2.执行奖赏最大的动作。前一个被称为“探索”,后一个被称为“利用”。这对应一个理论模型“K-摇臂赌博机”。
2.2 有模型学习
假定强化学习四元组
对所有策略选择最优策略则是进行“策略迭代”:从一个初始策略(通常是随机策略)出发,先进行策略评估,然后改进策略,评估改进的策略,再进一步改进策略,…,不断迭代进行策略评估和改进,直至策略收敛。
2.3 免模型学习
现实的强化学习任务,环境的转移概率和奖赏函数很难提起获知,那么如何计算最优的策略呢?
2.3.1 蒙特卡罗强化学习
使用蒙特卡洛采样,进行多次采样,然后求取平均累积奖赏作为期望累积奖赏的近似,由于采样必须为有限次数,所以该方法更适合于T步累积奖赏,而不是r折扣累积奖赏。采样方法是:对每个状态按照一定该概率采样出一个执行动作,然后转移到下一个状态后继续采样动作,直至策略的采样轨迹完成

以上采样动作采用的是e-贪心策略:以概率e均匀地从动作集合A中选取动作;以1-e概率选取当前最优策略:
2.3.2 时序差分模型
蒙特卡罗方法在完成一个采样轨迹再更新策略的值估计,而动态规则策略是每执行一步策略就进行值函数的更新。时序差分学习结合使用蒙特卡洛方法和动态规划方法,比蒙特卡洛方法更高效,其算法被称为Q-学习算法。
2.3.3 模仿学习
前述强化学习都是机器获得的反馈信息仅有多步决策后的累积奖赏,而在现实任务中,往往能够得到人类专家的决策过程范例。即除了环境反馈之外,强化学习还能利用专家范例,这被称为模仿学习。
很多强化学习的“状态-动作对”搜索空间巨大,基于累积奖赏来学习很多步之前的合适决策非常困难,更好的办法是直接模仿人类专家的“状态-动作对”选择,这被称为“直接模仿学习”。
直接模仿学习:


逆强化学习:
很多任务中,设计奖赏函数很困难,从人类专家提供的范例数据中反推出奖赏函数有助于解决该问题。这就是逆强化学习:欲使机器做出与范例一致的行为,等价于在某个奖赏函数的环境中求解最优策略,该策略所产生的轨迹与范例数据一致。
3. 进一步入门
进一步研究强化学习,好的资源如下:
1. 强化学习的学习仓库,https://github.com/applenob/rl_learn
2. 强化学习从入门到放弃的资料,https://github.com/wwxFromTju/awesome-reinforcement-learning-zh
3. 学习强化学习(包括代码,练习和解决方案), http://www.wildml.com/2016/10/learning-reinforcement-learning/
4. Web安全之强化学习与GAN, https://download.csdn.net/download/qq_38327551/10569407
最后一个是安全领域对强化学习的应用,可以看作是一个实操性强的例子。