学习笔记之车道线相关记录
一. 车道线相关的知识
&&1.标线的分类
以下分类来自于百科:
按照道路交通标线的功能划分为:指示标线、警告标线和禁止标线。
按标划方法可分为:白色虚线、白色实线、黄色虚线、黄色实线、双白虚线、双白实线、双黄虚线和双黄实线等。
按作用又可分为:车行道中心线、车道分界线、停止线、减速让行线、人行横道线、导流线、导向箭头和左转弯导线等。
根据下面这张图,大致可以看到的分类:
实车道线,虚车道线,人行道,箭头或停止线。
&&2.现目前所知道的检测方法
以下内容摘自:https://blog.csdn.net/liaojiacai/article/details/63685342 ,感谢作者,如果侵权,立马删除
车道线的检测方法有很多,基于视觉的车道线检测有一下几种:
基于霍夫之间检测、基于LSD直线检测、基于俯视图变换的车道线检测、基于拟合的车道线检测、基于平行透视灭点的。主流的方法就是这几种吧,当然使用雷达扫描也可以的检测的。下面讲分别讲一下霍夫直线检测、拟合、仿射变换进行检测车道线的原理,并给出变换的效果。
一、基于霍夫的车道线检测
霍夫直线检测有两种,但是原理相同。
一般的车道有三车道或者四车道,固定的前方摄像头的视角范围内,由于车辆周围的其他车辆的遮挡,不能够稳定的提取所有的车道,能稳定检测摄像头安装车辆所在车道线。检测当前车道线,被检测的车辆中不处于前方同车道内的车辆就可以根据被检测车辆坐标与当前车道线距离关系划分为左右两侧车道内的车辆。
本文进行的车道线检测是基于统计概论霍夫直线检测实现的,其原理是将图像的笛卡尔坐标系统转换到极坐标霍夫空间,从而完成点到曲线的变换,对应的每个像素坐标P(x,y)被转换到(r,theta)的曲线点上面。

同一条直线上的点P(x,y)都满足x*cos(theta) + y * sin(theta) = r ,这样一组(r,theta)常量就对应了图像中位移确定的一条直线。遍历图像感兴趣区域的像素点时,不断的累加每个(r,theta)对应的数据点个数,当某一对(r,theta) 对应的统计的点数达到我们设定的阈值时就认为这些点在一条直线上,通过霍夫检测的同一条直线上的的点的个数,可以过滤掉很多干扰直线。
1、图像前处理的方法
对于原始的车载图像,是BGR的彩色图,对于只需要提取车道线的算法,车道线是宝色的,我们只需要保留有白色车道线的厚度图即可,所以对原始图的第一步处理就是灰度化。
原图:

第一步灰度均衡化:

第二步进行边缘检测:
边缘检测有很多方法。可以使用sobel算子或者canny边缘检测,其差别是,检测算子的模板中的权值不同,造成最后保留的边缘的细节部分有差别

2、提取车道线
在感兴趣区域内寻找车道线,大大缩减图像的处理计算量

通过霍夫检测直线,找到车道线:

3、标注车道线并进行相应的预警
通过标定实验,找到直线距离车道线左右边缘30cm范围内的报警区域,一旦车辆发生在预警区域内启动报警

4、车道线的检测的适应性
车道线检测需要适应多种情况,通过测试,这种算法有良好的鲁棒性,对于白天和夜晚都具有良好的适应性,相对于以上的两种算法明显有很多的优势,白天和夜晚的车道线检测效果:

夜晚:

偏离车道时的预警:

车道偏移基本功能实现,满足了对一般环境的要求,不足之处是对于曲率半径大于100的车道线还不能够识别,还需要有深入学习和算法设计。
二、基于透视变换变换的车道线检测
采用仿射变换的方法是将前方图像的路面通过仿射变换为俯视图,在俯视图中将车道线提取出来,提取的方法也是寻找车道线的特征,按照灰度值进行二值化,然后采用边缘检测,得到车道线的边缘轮廓,将检测到的车道线提取出来。军事交通学院采用这种方法进行车道线检测,在高速公路上得到了很好的效果,这种方法的优点是,可以找到多条车道线,实时效果比较好,但是缺点是对于复杂路况稳定性比较差,仿射变换时图像的损失比较大,在仿射图中不一定能够检测到变形后的车道线,受到周边物体遮挡影响严重。不适用于路况复杂和摄像头的视角比较小的前方视野。


三、基于拟合的车道线检测
边缘点拟合依据的原理是:车道线是白色的,而路面是灰色的,车道线和路面存在稳定的灰度梯度差,通过设定合理的阈值,就可以将车道线的边缘提取出来,提取的车道线的边缘点有很多,找到同一水平位置相邻的车道线的边缘点,取他们的中点作为车道线上的一点,依次方法得到整个车道线的点,由于车道线的与路面的颜色灰度值会受到颜色变化的影响,所以单一的阈值分割出来的边缘点并不在车道线的中间,而是在一个区域内,车道线提取的中点集合并不是在一条直线上,而是分布在直线的两侧,要得到最终的车道线需要对这些点进行拟合,一般采用拟合函数进行拟合。清华大学、重庆大学等一些高校采用这种拟合的方法。这种方法的优点是计算量较小,可以拟合带有曲率的车道线,缺点是环境适应性差,受光照干扰较大,稳定性差。

最后补充内容:
方法对比
上述方法为基本的车道线检测方法,其他方法在这些方法上融合出来的,比如放射变换后使用拟合或者霍夫检测直线,加上灭点的约束等方法。霍夫直线检测方法准确、简单,不能直接做弯道检测。拟合方法不稳定,优点是可以检测弯道。仿射变换优点是可以做多车道检测,缺点是在复杂情况下,前方车辆或者其他物体容易遮挡,受干扰严重。后面延伸的很多方法讲各种方法融合到一起,但是基本的变化还是有这几种方法的影子。
车道线检测中的跟踪算法
车道线检测时容易丢失,为了保证检测效果的准确,使用追踪可以提升检测速度和准确率,追踪的基本思想是,车辆在前进的过程中,是一个连续的位移移动过程,对应的车道线变化也是一个连续到变化,这种变化体现在车道线的斜率上,前后两帧图像中的车道线的斜率相差不大所在的位置也不会差到太远,所以通过控制比较前后两帧中的车道线的斜率,在之前检测到的车道线区域附近进行限定。这就是跟踪的基本思想。
&&3.车道检测的目的和车道跟踪
以下内容来自:https://blog.csdn.net/viewcode/article/details/7969259 感谢作者
车道线检测的目的,就是为了轿车可以安全平稳的保持行驶。
车道检测的目标:
1. 车道形状,包括宽度、曲率等几何参数
2. 车辆在车道中的位置,包括横向偏移量,车辆与道路的夹角(偏航角)
车道检测与跟踪一般分为以下几个部分:
@@1. 车辆、道路、相机模型
@@2. 道路特征提取
@@3. 道路参数计算,如曲率,
@@4. 车道跟踪
@@1、车辆、道路、相机模型
在现代道路设计中,道路有比较固定的设计模型,因此,对于高速公路等道路类型,车道的几何模型可以以固定的形式表示。
车道弧长、曲率、偏航角、横向偏移量构成车辆与车道几何模型的要素。
车道一般由直线、圆弧和缓和曲线构成,缓和曲线通常是不同曲率的圆弧或直线的连接过渡,其曲率均匀变化,螺旋曲线是缓和曲线常用形式。
道路曲率与弧长(路长)的关系:
C = C0 + C1*L.
C0为起始点曲率,C1为曲率变化率。C0,C1都为0时,直线; C1为0时,C0不为0,圆弧;C1不为0时,缓和曲线。
在世界坐标系下,或俯视图下,在相机可视范围内,若车道的变化方向较小,则道路可用圆弧近似表示:
道路的坐标可以由弧长和曲率一般表示为:
y = L
x = 0.5*C*L^2
若相机与车道的横向偏移量为d,与车道的夹角为a,则车道模型为
y = L
x = d + a*L + 0.5*C*L^2
从公式来看,这是一个抛物线模型。这里没有考虑曲率变换率,即忽略了高次项(C1*L^3)/6。
不同的系统要求与道路环境,道路模型的精度要求也不同。在较早的系统里,在大路(highway)环境下,
基于视觉的车道模型经历了,平行直线模型 --> 固定曲率圆弧模型 --> 螺旋曲线模型。道路模型的精度不断提高。
使用哪种模型,要根据系统的实际需求。如早期的系统里,检测大路(highway)中10米内的车道状况,应用简单的线性模型即可。而车道偏离告警(LDW)系统中,在高速公路上,需要30米-40米的精确的道路模型,这时,螺旋曲线(高阶)或抛物线(二阶)模型就更为精确。
相机模型:
由图像的二维信息恢复出场景的三维信息,就需要相机模型来确立两者之间的对应关系。相机参数包括内部参数和外部参数。相机模型分为针孔相机模型和透镜畸变扩展模型。这些在另外一篇文章里有描述。相机的内外参数通过标定都可以获取。相机的外部参数体现了相机坐标下图像与世界坐标下场景的齐次变换关系。
@@2、道路特征检测
道路上车道标志的检测是道路特征检测的关键部分,并且已有很多算法,但道路场景太多,单一的算法还是无法适用所有的场景。算法分类:
| 适用场景 | 不适用场景 | |
| 基于边缘检测 | 虚线、实线明显 | 阴影、光照变化、反射不均匀 |
| 基于频域技术 | 能处理反射不均的场景 | 阴影 |
| 基于路面纹理/模板 | 阴影、光照不均等 | 反射不均 |
基于边缘检测的常用算法有:
Sobel, DOG, LOG, Steerable Filter等。每种算法都有各自的优缺点。这里不再描述。
由基本算法处理后得到道路的特征图像,这里以边缘为例,需要进一步分析其特性,去除干扰,保留符合车道特征的边缘。如平行性、宽度等结构特征。如果这些结构特征分析做的好,也可以弥补基本算法的不足。
其他检测方法:
双阈值特征检测:原图像、梯度图像(边缘图像)分别有各自的阈值,分割出车道标志特征,当某点的灰度和梯度值分别大于各自的阈值时,才被选取为车道的特征点,这个方法会去掉一些阴影等干扰。
可调滤波器steerable filter:
对原图分别获取Gxx, Gyy, Gxy,高斯二阶分量。角度可变的滤波器的强度响应如下:
求上式的极值,则需求角度的导数,则能获取两个角度
对于滤波器窗口内圆形对称的物体,则两个角度的响应差不多;而对车道,两个角度响应的差值就比较大,响应大的方向就是车道方向,车道方向也可以探测出。
@@3、道路参数计算
道路方向、曲率的计算。霍夫变换是常用的检测直线的方法,还有其他方法筛选特征计算参数的方法,如最小二乘估计,RANSAC,这些方法基本上都设定了道路模型,由特征点来计算参数。但也可以由计算出的模型,去除不符合条件的特征。
@@4、跟踪
一般跟踪的作用就是预测下一帧图像内道路特征的位置,在一个较小的范围内检测道路特征,提高效率。若预测范围内没有检测到道路特征,则采用估计或上一帧特征的位置,若连续几帧都没有检测到道路特征,则启动全图像道路特征检测。KalmanFilter是常用的跟踪算法。
车道的状态要考虑车道的位置、速度、偏航角及车辆行驶转角之间的关系。
夹角增量 = 曲率 * 长度
状态变量为道路弧长、车道夹角、道路曲率、车道宽度
车辆的行驶转角作为控制输入变量。
测量变量为道路弧长和车辆与道路的夹角。
则状态转移方程如下:
二、网络文章 opencv 处理 车道线
该内容来自https://blog.csdn.net/yang1688899/article/details/79519798 ,感谢作者,如果有侵权,立马删除,我主要是作为学习笔记记录。
使用openCV设计算法处理车辆前置摄像头录下的视频,检测车辆前方的车道,并计算车道曲率
项目代码GitHub地址:https://github.com/yang1688899/CarND-Advanced-Lane-Lines
这是在几张测试图片上的处理结果:
实现步骤:
- 使用提供的一组棋盘格图片计算相机校正矩阵(camera calibration matrix)和失真系数(distortion coefficients).
- 校正图片
- 使用梯度阈值(gradient threshold),颜色阈值(color threshold)等处理图片得到清晰捕捉车道线的二进制图(binary image).
- 使用透视变换(perspective transform)得到二进制图(binary image)的鸟瞰图(birds-eye view).
- 检测属于车道线的像素并用它来测出车道边界.
- 计算车道曲率及车辆相对车道中央的位置.
- 处理图片展示车道区域,及车道的曲率和车辆位置.
相机校正(Camera Calibration)
这里会使用opencv提供的方法通过棋盘格图片组计算相机校正矩阵(camera calibration matrix)和失真系数(distortion coefficients)。首先要得到棋盘格内角的世界坐标"object points"和对应图片坐标"image point"。假设棋盘格内角世界坐标的z轴为0,棋盘在(x,y)面上,则对于每张棋盘格图片组的图片而言,对应"object points"都是一样的。而通过使用openCv的cv2.findChessboardCorners(),传入棋盘格的灰度(grayscale)图片和横纵内角点个数就可得到图片内角的"image point"。
def get_obj_img_points(images,grid=(9,6)):
object_points=[]
img_points = []
for img in images:
#生成object points
object_point = np.zeros( (grid[0]*grid[1],3),np.float32 )
object_point[:,:2]= np.mgrid[0:grid[0],0:grid[1]].T.reshape(-1,2)
#得到灰度图片
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#得到图片的image points
ret, corners = cv2.findChessboardCorners(gray, grid, None)
if ret:
object_points.append(object_point)
img_points.append(corners)
return object_points,img_points
然后使用上方法得到的object_points and img_points 传入cv2.calibrateCamera() 方法中就可以计算出相机校正矩阵(camera calibration matrix)和失真系数(distortion coefficients),再使用 cv2.undistort()方法就可得到校正图片。
def cal_undistort(img, objpoints, imgpoints):
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img.shape[1::-1], None, None)
dst = cv2.undistort(img, mtx, dist, None, mtx)
return dst
以下为其中一张棋盘格图片校正前后对比:

校正测试图片
代码如下:
#获取棋盘格图片
cal_imgs = utils.get_images_by_dir('camera_cal')
#计算object_points,img_points
object_points,img_points = utils.calibrate(cal_imgs,grid=(9,6))
#获取测试图片
test_imgs = utils.get_images_by_dir('test_images')
#校正测试图片
undistorted = []
for img in test_imgs:
img = utils.cal_undistort(img,object_points,img_points)
undistorted.append(img)
测试图片校正前后对比:
阈值过滤(thresholding)
这里会使用梯度阈值(gradient threshold),颜色阈值(color threshold)等来处理校正后的图片,捕获车道线所在位置的像素。(这里的梯度指的是颜色变化的梯度)
以下方法通过"cv2.Sobel()"方法计算x轴方向或y轴方向的颜色变化梯度导数,并以此进行阈值过滤(thresholding),得到二进制图(binary image):
def abs_sobel_thresh(img, orient='x', thresh_min=0, thresh_max=255):
#装换为灰度图片
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
#使用cv2.Sobel()计算计算x方向或y方向的导数
if orient == 'x':
abs_sobel = np.absolute(cv2.Sobel(gray, cv2.CV_64F, 1, 0))
if orient == 'y':
abs_sobel = np.absolute(cv2.Sobel(gray, cv2.CV_64F, 0, 1))
#阈值过滤
scaled_sobel = np.uint8(255*abs_sobel/np.max(abs_sobel))
binary_output = np.zeros_like(scaled_sobel)
binary_output[(scaled_sobel >= thresh_min) & (scaled_sobel <= thresh_max)] = 1
return binary_output
通过测试发现使用x轴方向阈值在35到100区间过滤得出的二进制图可以捕捉较为清晰的车道线:
x_thresh = utils.abs_sobel_thresh(img, orient='x', thresh_min=35, thresh_max=100)
以下为使用上面方法应用测试图片的过滤前后对比图:
可以看到该方法的缺陷是在路面颜色相对较浅且车道线颜色为黄色时,无法捕捉到车道线(第三,第六,第七张图),但在其他情况车道线捕捉效果还是不错的。
接下来测试一下使用全局的颜色变化梯度来进行阈值过滤:
def mag_thresh(img, sobel_kernel=3, mag_thresh=(0, 255)):
# Convert to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# Take both Sobel x and y gradients
sobelx = cv2.Sobel(gray, cv2.CV_64F, 1, 0, ksize=sobel_kernel)
sobely = cv2.Sobel(gray, cv2.CV_64F, 0, 1, ksize=sobel_kernel)
# Calculate the gradient magnitude
gradmag = np.sqrt(sobelx**2 + sobely**2)
# Rescale to 8 bit
scale_factor = np.max(gradmag)/255
gradmag = (gradmag/scale_factor).astype(np.uint8)
# Create a binary image of ones where threshold is met, zeros otherwise
binary_output = np.zeros_like(gradmag)
binary_output[(gradmag >= mag_thresh[0]) & (gradmag <= mag_thresh[1])] = 1
# Return the binary image
return binary_output
mag_thresh = utils.mag_thresh(img, sobel_kernel=9, mag_thresh=(50, 100))
结果仍然不理想(观察第三,第六,第七张图片),原因是当路面颜色相对较浅且车道线颜色为黄色时,颜色变化梯度较小,想要把捕捉车道线需要把阈值下限调低,然而这样做同时还会捕获大量的噪音像素,效果会更差。
那么使用颜色阈值过滤呢? 下面为使用hls颜色空间的s通道进行阈值过滤:
def hls_select(img,channel='s',thresh=(0, 255)):
hls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)
if channel=='h':
channel = hls[:,:,0]
elif channel=='l':
channel=hls[:,:,1]
else:
channel=hls[:,:,2]
binary_output = np.zeros_like(channel)
binary_output[(channel > thresh[0]) & (channel <= thresh[1])] = 1
return binary_output
s_thresh = utils.hls_select(img,channel='s',thresh=(180, 255))
可以看到在路面颜色相对较浅且车道线颜色为黄色的区域,车道线仍然被清晰的捕捉到了,然而在其他地方表现却不太理想(第四,第八张图片)
因此为了应对多变的路面情况,需要结合多种阈值过滤方法。
以下为最终的阈值过滤组合:
def thresholding(img):
x_thresh = utils.abs_sobel_thresh(img, orient='x', thresh_min=10 ,thresh_max=230)
mag_thresh = utils.mag_thresh(img, sobel_kernel=3, mag_thresh=(30, 150))
dir_thresh = utils.dir_threshold(img, sobel_kernel=3, thresh=(0.7, 1.3))
hls_thresh = utils.hls_select(img, thresh=(180, 255))
lab_thresh = utils.lab_select(img, thresh=(155, 200))
luv_thresh = utils.luv_select(img, thresh=(225, 255))
#Thresholding combination
threshholded = np.zeros_like(x_thresh)
threshholded[((x_thresh == 1) & (mag_thresh == 1)) | ((dir_thresh == 1) & (hls_thresh == 1)) | (lab_thresh == 1) | (luv_thresh == 1)] = 1
return threshholded
透视变换(perspective transform)
这里使用"cv2.getPerspectiveTransform()"来获取变形矩阵(tranform matrix),把阈值过滤后的二进制图片变形为鸟撒视角。
以下为定义的源点(source points)和目标点(destination points)
| Source | Destination |
|---|---|
| 585, 460 | 320, 0 |
| 203, 720 | 320, 720 |
| 1127, 720 | 960, 720 |
| 695, 460 | 960, 0 |
定义方法获取变形矩阵和逆变形矩阵:
def get_M_Minv():
src = np.float32([[(203, 720), (585, 460), (695, 460), (1127, 720)]])
dst = np.float32([[(320, 720), (320, 0), (960, 0), (960, 720)]])
M = cv2.getPerspectiveTransform(src, dst)
Minv = cv2.getPerspectiveTransform(dst,src)
return M,Minv
然后使用"cv2.warpPerspective()"传入相关值获得变形图片(wrapped image)
thresholded_wraped = cv2.warpPerspective(thresholded, M, img.shape[1::-1], flags=cv2.INTER_LINEAR)
以下为原图及变形后的效果:
以下为阈值过滤后二进制图变形后效果:
检测车道边界
上面的二进制图还存在一定的噪音像素,为了准确检测车道边界,首先要确定哪些像素是属于车道线的。
首先要定位车道线的基点(图片最下方车道出现的x轴坐标),由于车道线在的像素都集中在x轴一定范围内,因此把图片一分为二,左右两边的在x轴上的像素分布峰值非常有可能就是车道线基点。
以下为测试片x轴的像素分布图:
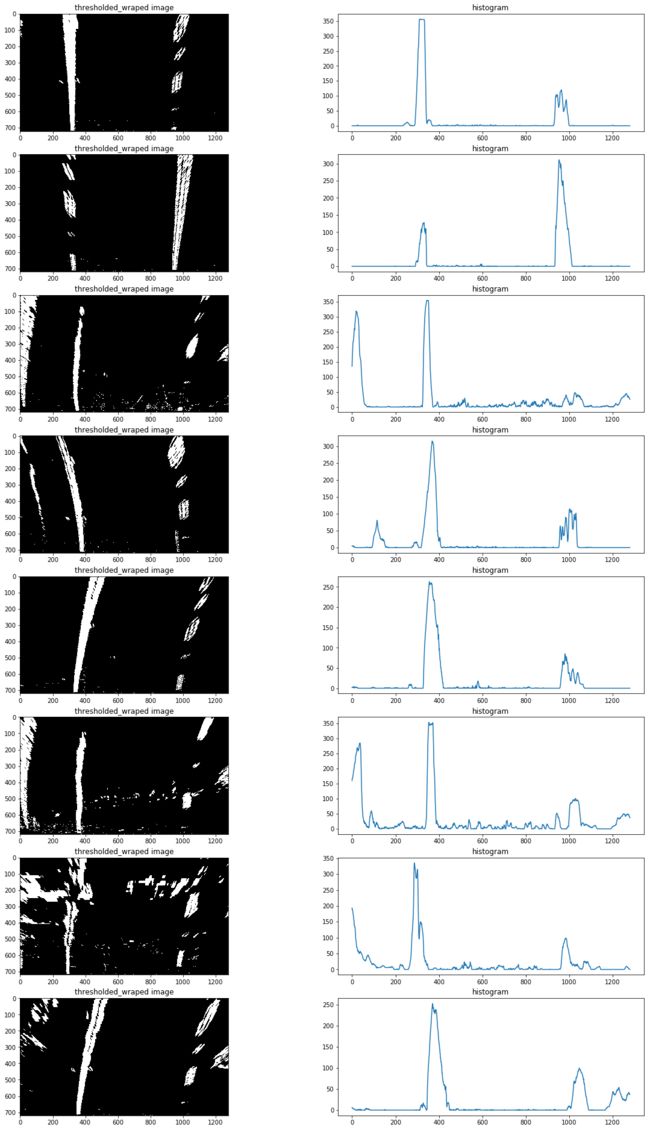
定位基点后,再使用使用滑动窗多项式拟合(sliding window polynomial fitting)来获取车道边界。这里使用9个200px宽的滑动窗来定位一条车道线像素:
def find_line(binary_warped):
# Take a histogram of the bottom half of the image
histogram = np.sum(binary_warped[binary_warped.shape[0]//2:,:], axis=0)
# Find the peak of the left and right halves of the histogram
# These will be the starting point for the left and right lines
midpoint = np.int(histogram.shape[0]/2)
leftx_base = np.argmax(histogram[:midpoint])
rightx_base = np.argmax(histogram[midpoint:]) + midpoint
# Choose the number of sliding windows
nwindows = 9
# Set height of windows
window_height = np.int(binary_warped.shape[0]/nwindows)
# Identify the x and y positions of all nonzero pixels in the image
nonzero = binary_warped.nonzero()
nonzeroy = np.array(nonzero[0])
nonzerox = np.array(nonzero[1])
# Current positions to be updated for each window
leftx_current = leftx_base
rightx_current = rightx_base
# Set the width of the windows +/- margin
margin = 100
# Set minimum number of pixels found to recenter window
minpix = 50
# Create empty lists to receive left and right lane pixel indices
left_lane_inds = []
right_lane_inds = []
# Step through the windows one by one
for window in range(nwindows):
# Identify window boundaries in x and y (and right and left)
win_y_low = binary_warped.shape[0] - (window+1)*window_height
win_y_high = binary_warped.shape[0] - window*window_height
win_xleft_low = leftx_current - margin
win_xleft_high = leftx_current + margin
win_xright_low = rightx_current - margin
win_xright_high = rightx_current + margin
# Identify the nonzero pixels in x and y within the window
good_left_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xleft_low) & (nonzerox < win_xleft_high)).nonzero()[0]
good_right_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) &
(nonzerox >= win_xright_low) & (nonzerox < win_xright_high)).nonzero()[0]
# Append these indices to the lists
left_lane_inds.append(good_left_inds)
right_lane_inds.append(good_right_inds)
# If you found > minpix pixels, recenter next window on their mean position
if len(good_left_inds) > minpix:
leftx_current = np.int(np.mean(nonzerox[good_left_inds]))
if len(good_right_inds) > minpix:
rightx_current = np.int(np.mean(nonzerox[good_right_inds]))
# Concatenate the arrays of indices
left_lane_inds = np.concatenate(left_lane_inds)
right_lane_inds = np.concatenate(right_lane_inds)
# Extract left and right line pixel positions
leftx = nonzerox[left_lane_inds]
lefty = nonzeroy[left_lane_inds]
rightx = nonzerox[right_lane_inds]
righty = nonzeroy[right_lane_inds]
# Fit a second order polynomial to each
left_fit = np.polyfit(lefty, leftx, 2)
right_fit = np.polyfit(righty, rightx, 2)
return left_fit, right_fit, left_lane_inds, right_lane_inds
以下为滑动窗多项式拟合(sliding window polynomial fitting)得到的结果:
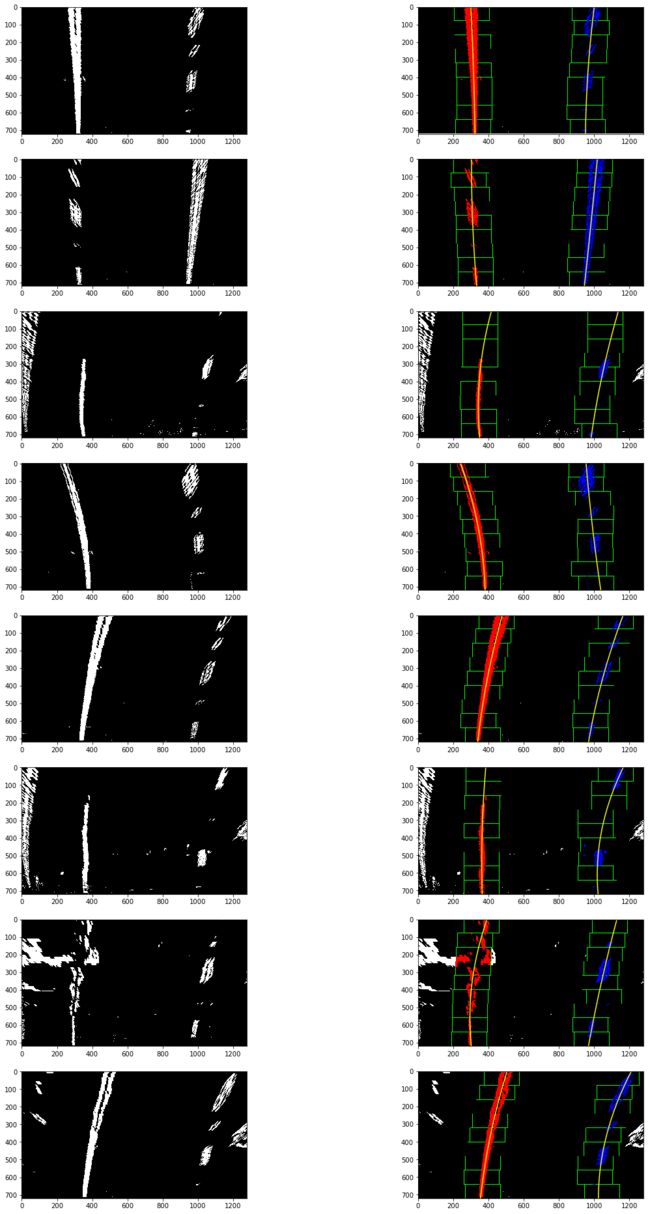
计算车道曲率及车辆相对车道中心位置
利用检测车道得到的拟合值(find_line 返回的left_fit, right_fit)计算车道曲率,及车辆相对车道中心位置:
def calculate_curv_and_pos(binary_warped,left_fit, right_fit):
# Define y-value where we want radius of curvature
ploty = np.linspace(0, binary_warped.shape[0]-1, binary_warped.shape[0] )
leftx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]
rightx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]
# Define conversions in x and y from pixels space to meters
ym_per_pix = 30/720 # meters per pixel in y dimension
xm_per_pix = 3.7/700 # meters per pixel in x dimension
y_eval = np.max(ploty)
# Fit new polynomials to x,y in world space
left_fit_cr = np.polyfit(ploty*ym_per_pix, leftx*xm_per_pix, 2)
right_fit_cr = np.polyfit(ploty*ym_per_pix, rightx*xm_per_pix, 2)
# Calculate the new radii of curvature
left_curverad = ((1 + (2*left_fit_cr[0]*y_eval*ym_per_pix + left_fit_cr[1])**2)**1.5) / np.absolute(2*left_fit_cr[0])
right_curverad = ((1 + (2*right_fit_cr[0]*y_eval*ym_per_pix + right_fit_cr[1])**2)**1.5) / np.absolute(2*right_fit_cr[0])
curvature = ((left_curverad + right_curverad) / 2)
#print(curvature)
lane_width = np.absolute(leftx[719] - rightx[719])
lane_xm_per_pix = 3.7 / lane_width
veh_pos = (((leftx[719] + rightx[719]) * lane_xm_per_pix) / 2.)
cen_pos = ((binary_warped.shape[1] * lane_xm_per_pix) / 2.)
distance_from_center = veh_pos - cen_pos
return curvature,distance_from_center
处理原图,展示信息
使用逆变形矩阵把鸟瞰二进制图检测的车道镶嵌回原图,并高亮车道区域:
def draw_area(undist,binary_warped,Minv,left_fit, right_fit):
# Generate x and y values for plotting
ploty = np.linspace(0, binary_warped.shape[0]-1, binary_warped.shape[0] )
left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]
right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]
# Create an image to draw the lines on
warp_zero = np.zeros_like(binary_warped).astype(np.uint8)
color_warp = np.dstack((warp_zero, warp_zero, warp_zero))
# Recast the x and y points into usable format for cv2.fillPoly()
pts_left = np.array([np.transpose(np.vstack([left_fitx, ploty]))])
pts_right = np.array([np.flipud(np.transpose(np.vstack([right_fitx, ploty])))])
pts = np.hstack((pts_left, pts_right))
# Draw the lane onto the warped blank image
cv2.fillPoly(color_warp, np.int_([pts]), (0,255, 0))
# Warp the blank back to original image space using inverse perspective matrix (Minv)
newwarp = cv2.warpPerspective(color_warp, Minv, (undist.shape[1], undist.shape[0]))
# Combine the result with the original image
result = cv2.addWeighted(undist, 1, newwarp, 0.3, 0)
return result
使用"cv2.putText()"方法处理原图展示车道曲率及车辆相对车道中心位置信息:
def draw_values(img, curvature, distance_from_center):
font = cv2.FONT_HERSHEY_SIMPLEX
radius_text = "Radius of Curvature: %sm" % (round(curvature))
if distance_from_center > 0:
pos_flag = 'right'
else:
pos_flag = 'left'
cv2.putText(img, radius_text, (100, 100), font, 1, (255, 255, 255), 2)
center_text = "Vehicle is %.3fm %s of center" % (abs(distance_from_center), pos_flag)
cv2.putText(img, center_text, (100, 150), font, 1, (255, 255, 255), 2)
return img
以下为测试图片处理后结果:
一段处理后的视频
三、基于深度学习的车道线检测
部分摘自:https://blog.csdn.net/u011886519/article/details/80936070 感谢作者
SCNN:
- SCNN基于框架torch做的开发,torch独有的table结构使得其模型很难转换为caffe or tensorflow等其它形式,但是其基于车道线这种形态属性的而设计的深度学习网络架构是值得参考的,见下图;

VPGnet:
- VPGnet结合了消失点等多种信息,进行模型训练,文章亮点在于其独特的车道线网格标记训练的思考,采用回归的方式定位车道线,和消失点深度学习训练方面的设计,利用整体空间结构特征而不是单点小范围像素的学习。但是作者提供的代码是不完整的,缺少参考模型,训练代码缺失VP训练部分,无法快速进行效果验证。

Lanenet:
- lanenet基于tensorflow框架,而且提供的参考内容很完整,在tusimple上验证出效果是比较好的。其特点在于曲线拟合部分,采用深度学习网络进行曲线拟合。采用H-net学习拟合矩阵,比传统bird transform 或者多项式拟合方式calculate once的局限方式,可以利用深度学习模型的大数据训练调优的优点,得到适应性更强的拟合矩阵。

四、学习相关文章
Lanenet 车道线检测网络模型学习:https://blog.csdn.net/c20081052/article/details/80622722
使用的数据集下载:http://benchmark.tusimple.ai/#/t/1/dataset
该笔记,待完善。。。。