比特币源码分析--加密算法
比特币系统为了保证其安全性,用到了很多算法,包括各种加密算法以及共识算法,理解这些算法对于理解比特币的原理是至关重要的,这篇文章就来简单的总结一下比特币中用到的一些主要的算法。
1 Hash算法
1.1 hash的概念
Hash对于任何一个从事计算机软件开发的同行应该是在熟悉不过了。Hash算法是指将任意长度的一串明文映射为一段长度较短的(通常长度也是固定的)二进制串,并且对于不同的明文,很难映射得到相同的hash串。平时在开发过程中用的比较多的MD5来检验文件就是hash的最常见的应用:用某种hash算法对文件生成hash值(数字摘要),一旦之后文件发生了改变,重新计算将得到不同的摘要值,从而认为文件发生了变化。
一个好的hash算法需要具备的特点:
(1) 正向快速:对于给定的明文,能在有限的时间和资源内得到hash值;
(2)逆向困难:对于给定的hash值,想逆向推导出明文基本不可能;
(3)输入敏感:明文发生变化,新的hash值会有很大的不同;
(3)抗碰撞性:很难找到两段不同的明文能够产生相同的hash值;
1.2 常见的hash算法
常见的hash算法:
MD4:该算法由Rivest于1990年设计,对于任意明文,能够输出128位的hash。MD4目前已经被证明为不安全的。
MD5:MD4的改进版,作者也是Rivest。同样输出128位的hash,相比MD4更加安全,但是速度稍慢。
SHA:SHA并非一个算法,而是一个算法族,由NIST(National Institute of Standards and Technology)于1993年发布了首个实现。该算法族包含了SHA-1,SHA-224,SHA-256,SHA-384,SHA-512等。
目前MD5和SHA1已经被破解,通常推荐使用SHA-256或更安全的算法。
1.3 比特币不可篡改性
区块链的一个主要特点之一就是其不可篡改性:一旦数据写入到区块链,将无法篡改。区块链中这种无法篡改的特性实际上就是利用了hash的特点。从结构上来讲,区块链实际上是由一个一个的区块构成的链条,其中每个区块的区块头中都包含有上一区块(父区块)的hash值。一旦链条中的某个区块被篡改,那么其hash值将发生变化,进而导致该区块的子区块内容发生变化(持有的父区块的hash值变了),如此递归下去,受影响的区块数目越多,重新计算并重构区块链所需要付出的算力就越大,一般超过6个区块基本上就认为是安全的。
2 加解密算法
比特币作为一种加密货币,其中少不了加解密算法,本节简单复习一下加解密算法。
2.1 加解密的过程
加解密过程描述起来很简单:加密就是将明文和秘钥,通过加密算法生成密文,解密是加密的反过程:密文和秘钥通过解密算法,还原出明文。
根据加密和解密过程中是否使用相同的秘钥,加密算法又可以分为对称加密和非对称加密算法:
对称加密:加密和解密使用相同的秘钥。
非对称加密:加密和解密使用不同的秘钥。
两种加密方式各有有缺点,实践中有时会将二者结合起来使用。
注意:理论上不存在绝对安全的算法,所以在实际的项目中,如果对安全性要求较高,最好不要使用自己设计的加密算法,很多情况下即使不公开加密算法,系统也很容易被破解,明智的做法是使用已经经过长期验证和论证的算法。
2.2 对称加密算法
对称加密算法即加密和解密使用相同的秘钥。其优点是效率和加密强度高,但缺点是参与方需要提前持有秘钥,一旦有人将秘钥泄漏,就会有安全风险。
从实现方式上,对称加密算法又可以分为分组密码和序列密码。
(1) 分组密码:将明文以定长的数据块为加密单位,应用最为广泛。
(2) 序列密码:每次只对一个字节或字符加密。
分组密码应用较为广泛,有一些大家耳熟能详的经典算法:DES,3DES,AES。
DES:经典的加密算法,由美国联邦信息处理标准FIPS采用。将64位名为变为64位密文,秘钥长度64位。该算法目前已经可以被暴力破解,不再安全。
3DES:顾名思义,采用3重DES加密,强度高于DES,但是目前也被证明是不安全的。
AES:由美国国家标准研究所采用,目前已取代了DES成为了对称加密实现的标准。AES的分组长度为128位、192位和256位,目前还没有有效的破解手段。
2.3 非对称加密算法
非对称加密算法是指加密和解密使用不同的秘钥,分别称为公钥和私钥。私钥一般通过随机数算法来生成,公钥通常通过私钥生成。公钥谁都可以看到,私钥不能泄露,只有自己持有。
非对称加密的优点是公私钥分开,缺点是效率低,强度也比对称加密低。
安全性方面,非对称加密的安全性需要数学问题来保障,常见的有大质数因子分解,椭圆曲线,离散对数等数学难题。
常见的非对称加密算法:
RSA:经典的公钥算法,利用了对大数进行质因子分解困难的特性;
Diffie-Hellman:秘钥交换,基于离散对数不能快速求解;
椭圆曲线算法(ECC):这是目前关注度比较高的算法系列,也是比特币中使用的算法。基于对椭圆曲线上特定点进行特殊乘法逆运算难以计算的特性。ECC算法目前被认为安全度高,但缺点是效率低,计算比较耗时。
2.3.1 ECDSA椭圆曲线加密算法
比特币中的非对称加密使用的是ECDSA椭圆曲线加密算法,本节对其进行简要介绍,由于数学知识基本已经还给了老师,所以此处只是抛砖引玉,对密码学有兴趣的同学可以自行深入研究。
ECDSA的全称是Elliptic Curve Digital Signature Algorithm,翻译过来就是椭圆曲线数字签名算法。这个算法的介绍参考下面链接:
ECDSA介绍
上面链接中的文章很短,但是说明了一些非常重要的概念:
(1) 比特币中使用ECDSA算法的目的是为了证明某一笔比特币只能被其所有人花费;
(2) 私钥:需要保密,只有生成它的人才知道,私钥是一串随机数,在比特币中用32位整数保存;
(2) 公钥:和私钥对应的一串数字,公钥可以由私钥计算生成(但不强制),公钥的作用是在不暴露私钥的情况下验证签名的有效性;
(3) 签名:签名由私钥加上需要被签名的数据的hash(数据摘要)生成。通过公钥加上某种数学算法,就能在不暴露私钥的情况下对签名进行验证。
比特币中所用的椭圆曲线的参数由secp256k1定义,定义在Standard Efficient Cryptography(SEC)中,该算法在比特币出现之前几乎没有被人使用过,但是随着比特币的应用,现在越来越受到关注。secp256k1和传统的椭圆曲线算法相比具有如下特性:
(1) secp256k1是用非随机的方式生成,而传统的椭圆曲线则是用随机方式生成;
(2) 因为secp256k1用非随机方式生成,因此效率很高,如果实现中优化的好,效率会比常用的椭圆曲线高30%。
关于secp256k1的更详细说明请参考下面链接:
secp256k1
2.3.2 比特币中的钱包地址
如前所述,比特币中的非对称加密实现使用的是ECDSA椭圆曲线,曲线的参数采用secp256k1算法生成。下图说明了比特币钱包地址的生成方式:
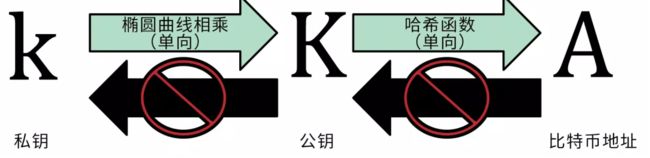
首先通过随机数算法生成私钥,然后将私钥用ECDSA椭圆曲线进行加密得到公钥,公钥在通过hash得到比特币钱包地址。在实现时比特币使用了libsecp256k1库。下面看看比特币核心中是如何生成私钥和公钥的。
在命令行中输入$bitcoin_cli getnewaddress可以生成一个新的比特币钱包地址,生成私钥和公钥的代码参考CWallet::GenerateNewKey:
CPubKey CWallet::GenerateNewKey(WalletBatch &batch, bool internal)
{
AssertLockHeld(cs_wallet); // mapKeyMetadata
bool fCompressed = CanSupportFeature(FEATURE_COMPRPUBKEY); // default to compressed public keys if we want 0.6.0 wallets
CKey secret;
// Create new metadata
int64_t nCreationTime = GetTime();
CKeyMetadata metadata(nCreationTime);
// use HD key derivation if HD was enabled during wallet creation
if (IsHDEnabled()) {
DeriveNewChildKey(batch, metadata, secret, (CanSupportFeature(FEATURE_HD_SPLIT) ? internal : false));
} else {
secret.MakeNewKey(fCompressed);
}
// Compressed public keys were introduced in version 0.6.0
if (fCompressed) {
SetMinVersion(FEATURE_COMPRPUBKEY);
}
CPubKey pubkey = secret.GetPubKey();
assert(secret.VerifyPubKey(pubkey));
mapKeyMetadata[pubkey.GetID()] = metadata;
UpdateTimeFirstKey(nCreationTime);
if (!AddKeyPubKeyWithDB(batch, secret, pubkey)) {
throw std::runtime_error(std::string(__func__) + ": AddKey failed");
}
return pubkey;
}比特币的私钥用类CKey来封装,从代码中可以看到先通过CKey.MakeNewKey生成私钥:
void CKey::MakeNewKey(bool fCompressedIn) {
do {
GetStrongRandBytes(keydata.data(), keydata.size());
} while (!Check(keydata.data()));
fValid = true;
fCompressed = fCompressedIn;
}私钥起始就是一串随机生成的字节。有了私钥,在通过CKey::GetPubKey生成公钥:
CPubKey CKey::GetPubKey() const {
assert(fValid);
secp256k1_pubkey pubkey;
size_t clen = CPubKey::PUBLIC_KEY_SIZE;
CPubKey result;
int ret = secp256k1_ec_pubkey_create(secp256k1_context_sign, &pubkey, begin());
assert(ret);
secp256k1_ec_pubkey_serialize(secp256k1_context_sign, (unsigned char*)result.begin(), &clen, &pubkey, fCompressed ? SECP256K1_EC_COMPRESSED : SECP256K1_EC_UNCOMPRESSED);
assert(result.size() == clen);
assert(result.IsValid());
return result;
}2.3.3 数字签名
非对称加密的一个主要应用场景就是数字签名,简单说就是对消息的发送者验明正身。
假设alice给bob在一条不可靠的通道上发送了一条消息,那么bob如何证明发送者就是alice呢?可以按如下步骤来:
(1) alice用hash生成消息的数字摘要,然后用自己的私钥对摘要进行签名;
(2) alice将签名后的摘要、所用的hash一并发送给bob;
(3) bob使用alice的公钥对收到的经过alice私钥签名的摘要进行解密,得到摘要;
(4) bob用同样的hash对收到的消息计算摘要,如果与第(3)步得到的摘要相同,则可以证明消息没有被改动,而且发送者就是alice本人,因为只有alice的公钥才能解开由alice的私钥签名的数据。
数字签名在比特币中的作用就是证明某人是比特币的合法所有人:
假设alice的钱包有一笔未花费输出UTXO,包含5个BTC,现在alice给bob转账1BTC,那么比特币网络中的其他节点怎样证明alice就是这笔UTXO的所有人,只有她才能动用这笔钱呢?假设alice给bob转账的交易为T:
(1) alice的钱包对T进行hash生成数字摘要;
(2) alice的钱包用私钥对(1)中生成的交易的摘要进行签名;
(3) 交易T被广播到比特币网络中;
(4) 网络中的节点收到此交易,对交易进行各种验证,其中就包括验证alice的签名。
简单看下代码里的实现:
可以用bitcoin_cli createrawtransaction来创建一笔交易,创建好的交易需要用signrawtransaction命令来进行签名,alice为了证明她具有交易T的输入所指向的UTXO的支配权,需要用自己的私钥对交易的摘要生成签名,这一步可以参考TransactionSignatureCreator::CreateSig:
bool MutableTransactionSignatureCreator::CreateSig(const SigningProvider& provider, std::vector& vchSig, const CKeyID& address, const CScript& scriptCode, SigVersion sigversion) const
{
CKey key;
if (!provider.GetKey(address, key))
return false;
// Signing with uncompressed keys is disabled in witness scripts
if (sigversion == SigVersion::WITNESS_V0 && !key.IsCompressed())
return false;
uint256 hash = SignatureHash(scriptCode, *txTo, nIn, nHashType, amount, sigversion); //这里生成交易的摘要
if (!key.Sign(hash, vchSig)) //用私钥生成签名
return false;
vchSig.push_back((unsigned char)nHashType);
return true;
} 先通过SignatureHash生成交易的摘要,然后通过CKey::Sign来生成签名,CKey是私钥的封装。
bool CKey::Sign(const uint256 &hash, std::vector& vchSig, uint32_t test_case) const {
if (!fValid)
return false;
vchSig.resize(CPubKey::SIGNATURE_SIZE);
size_t nSigLen = CPubKey::SIGNATURE_SIZE;
unsigned char extra_entropy[32] = {0};
WriteLE32(extra_entropy, test_case);
secp256k1_ecdsa_signature sig;
int ret = secp256k1_ecdsa_sign(secp256k1_context_sign, &sig, hash.begin(), begin(), secp256k1_nonce_function_rfc6979, test_case ? extra_entropy : nullptr);
assert(ret);
secp256k1_ecdsa_signature_serialize_der(secp256k1_context_sign, vchSig.data(), &nSigLen, &sig);
vchSig.resize(nSigLen);
return true;
} 之前已经提到过,比特币的非对称加密实现使用的是libsecp256k1实现的椭圆曲线算法,这里直接调用库提供的接口用私钥生成了hash摘要的签名。
之后交易被广播到比特币网络中,收到此交易的节点将会对交易进行验证,包括交易签名的验证,我们以比特币中最常见的P2PKH标准交易为例,其最后一步就是OP_CHECKSIG,即验证签名,实现可参考TransactionSignatureChecker::CheckSig:
template
bool GenericTransactionSignatureChecker::CheckSig(const std::vector& vchSigIn, const std::vector& vchPubKey, const CScript& scriptCode, SigVersion sigversion) const
{
CPubKey pubkey(vchPubKey);
if (!pubkey.IsValid())
return false;
// Hash type is one byte tacked on to the end of the signature
std::vector vchSig(vchSigIn);
if (vchSig.empty())
return false;
int nHashType = vchSig.back();
vchSig.pop_back();
uint256 sighash = SignatureHash(scriptCode, *txTo, nIn, nHashType, amount, sigversion, this->txdata); //交易签名
if (!VerifySignature(vchSig, pubkey, sighash)) //用公钥验证签名
return false;
return true;
} 这里同样用SignatureHash生成交易摘要,然后通过VerifySignature来验证签名:
template
bool GenericTransactionSignatureChecker::VerifySignature(const std::vector& vchSig, const CPubKey& pubkey, const uint256& sighash) const
{
return pubkey.Verify(sighash, vchSig);
} 最终调用了CPubKey::Verfy,CPubKey封装了公钥,即用公钥验证签名:
bool CPubKey::Verify(const uint256 &hash, const std::vector& vchSig) const {
if (!IsValid())
return false;
secp256k1_pubkey pubkey;
secp256k1_ecdsa_signature sig;
if (!secp256k1_ec_pubkey_parse(secp256k1_context_verify, &pubkey, &(*this)[0], size())) {
return false;
}
if (!ecdsa_signature_parse_der_lax(secp256k1_context_verify, &sig, vchSig.data(), vchSig.size())) {
return false;
}
/* libsecp256k1's ECDSA verification requires lower-S signatures, which have
* not historically been enforced in Bitcoin, so normalize them first. */
secp256k1_ecdsa_signature_normalize(secp256k1_context_verify, &sig, &sig);
return secp256k1_ecdsa_verify(secp256k1_context_verify, &sig, hash.begin(), &pubkey);
} 关于比特币的交易及其签名脚本,后续再分析比特币交易部分的源码时会进行更详细的分析,现在只需要知道比特币里通过数字签名的方式可以证明一笔UTXO的合法所有人就可以啦!
3 其他算法
3.1 Merkle树
3.1.1 merkle树介绍
merkle树是一颗二叉树,在文件系统和P2P系统中有广泛应用。merkle树具有如下特点:
(1) 叶子节点包含存储数据或者数据的hash值;
(2) 非叶子节点是其两个孩子节点内容的hash。
如下图:

merkle树的应用场景:
(1) 快速比较大量数据
对于两组数据量很大的数据集合,用merkle树可以很容易比较两组数据是否相同,只需要对每组数据构造出merkle树,然后比较树根是否相同即可,时间复杂度在log级别。
(2) 零知识证明
如上图,如何在不暴露其他内容的情况下证明B在集合里?只需要知道Ha,Hcd和树根,B的拥有者只要验证生成的树根的值即可证明B的存在。
3.1.2 merkle树在比特币中的应用
merkle树在比特币中的主要应用场景就是SPV(简单支付验证),主要是利用merkle树零知识证明的特性来证明一笔交易存在于特定的区块中。
比特币中的一个区块包含了大量的交易数据。通常只有全节点才会保存由一个个完整的区块数据构成的区块链,对于一般的智能手机等移动终端,因为存储空间的限制,保存完整的区块链显然不现实,所以中本聪提出了SPV的概念即:只保存区块的区块头,由于区块头只有80字节,基本上现在的移动终端的存储都可以满足。
但是由于只保存了区块头,没有交易数据,如何来验证呢?假设alice用10个比特币向bob购买了一件艺术品,然后alice告诉bob说10个比特币已经转给你了,交易的hash是123456ABCD...,由于是大额交易,bob需要确认这笔交易确实被写入到了区块链里才敢把艺术品给alice,bob应该如何确认呢?
(1) 假如bob运行的是全节点,有完整的区块链,那么bob只要根据交易的hash找到对应的区块,然后将此区块开始一直到创世区块的UTXO检索一遍,就能知道交易是否已经写入区块链,并且不是一笔双重支付的交易。
(2) 假如bob运行的是SPV节点,只有区块头,情况就比较复杂。此时由于bob只知道交易的hash,没有交易信息,因此无法知道这笔交易是否在区块链上,此时bob只能向相邻的全节点发送请求,具体做法是:
(i) bob将交易hash发送给相邻的全节点F;
(ii) 相邻的全节点F根据收到的交易hash,定位到交易所在的区块;
(iii) 假设区块中有A,B,C,D四笔交易,其中alice给bob的交易为B,则生成一条merkle认证路径(Ha, Hcd)发送给bob;
(iiii) bob根据收到的认证路径,使用Ha,Hb,Hcd计算出merkle树根,将此树根和SPV保存的区块头的merkle树根比较,即可证明交易已经存在于区块链上。
源码实现可以参考net_processing.cpp中的ProcessGetBlockData代码:
首先全节点根据收到的hash定位到区块:
const CBlockIndex* pindex = LookupBlockIndex(inv.hash);然后生成merkle认证路径:
else if (inv.type == MSG_FILTERED_BLOCK)
{
bool sendMerkleBlock = false;
CMerkleBlock merkleBlock;
{
LOCK(pfrom->cs_filter);
if (pfrom->pfilter) {
sendMerkleBlock = true;
merkleBlock = CMerkleBlock(*pblock, *pfrom->pfilter);
}
}
if (sendMerkleBlock) {
connman->PushMessage(pfrom, msgMaker.Make(NetMsgType::MERKLEBLOCK, merkleBlock));
// CMerkleBlock just contains hashes, so also push any transactions in the block the client did not see
// This avoids hurting performance by pointlessly requiring a round-trip
// Note that there is currently no way for a node to request any single transactions we didn't send here -
// they must either disconnect and retry or request the full block.
// Thus, the protocol spec specified allows for us to provide duplicate txn here,
// however we MUST always provide at least what the remote peer needs
typedef std::pair PairType;
for (PairType& pair : merkleBlock.vMatchedTxn)
connman->PushMessage(pfrom, msgMaker.Make(SERIALIZE_TRANSACTION_NO_WITNESS, NetMsgType::TX, *pblock->vtx[pair.first]));
} 最终全节点会给SPV节点响应一个MERKLEBLOCK消息,响应数据是一个CMerkleBlock结构,其中包含merkle认证路径:
class CMerkleBlock
{
public:
/** Public only for unit testing */
CBlockHeader header;
CPartialMerkleTree txn;类中包含区块头信息和CPartialMerkleTree,CPartialMerkleTree顾名思义只包含merkle树中的一部分节点,也就是SPV节点需要的认证路径:
class CPartialMerkleTree
{
protected:
/** the total number of transactions in the block */
unsigned int nTransactions;
/** node-is-parent-of-matched-txid bits */
std::vector vBits;
/** txids and internal hashes */
std::vector vHash; merkle路径通过递归的方式即可生成,生成merkle路径的方法为CPartialMerkleTree::TraverseAndBuild:
void CPartialMerkleTree::TraverseAndBuild(int height, unsigned int pos, const std::vector &vTxid, const std::vector &vMatch) {
// determine whether this node is the parent of at least one matched txid
bool fParentOfMatch = false;
for (unsigned int p = pos << height; p < (pos+1) << height && p < nTransactions; p++)
fParentOfMatch |= vMatch[p];
// store as flag bit
vBits.push_back(fParentOfMatch);
if (height==0 || !fParentOfMatch) {
// if at height 0, or nothing interesting below, store hash and stop
vHash.push_back(CalcHash(height, pos, vTxid));
} else {
// otherwise, don't store any hash, but descend into the subtrees
TraverseAndBuild(height-1, pos*2, vTxid, vMatch);
if (pos*2+1 < CalcTreeWidth(height-1))
TraverseAndBuild(height-1, pos*2+1, vTxid, vMatch);
}
} 3.2 Bloom过滤器
bloom过滤器是一种基于概率的过滤方法。其原理概括起来就是将输入数据用若干个Hash函数映射到二进制串中的若干个bit上。
下图是一个用3个hash函数将输入映射到长度为16的二进制串中的例子:
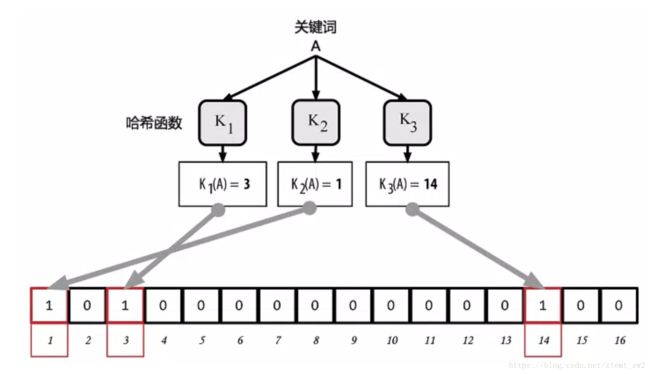
3个hash函数K1,K2,K3将输入映射后的结果分别为3,1,14,于是将二级制串中的第3,1和14位置1。
bloom过滤器的最常用的情景就是在海量的数据集中查找某个元素是否存在,这也是BAT面试题中经常会出现的问题。由于数据量巨大,需要的存储空间也会非常大,为了节省空间,可以使用bloom过滤器。
当查找的时候,只需要将输入代入到哈希函数,然后检查二进制串中对应的位是否被置1。例如对于上图中的例子,为了检查输入A是否存在,只需要用将A代入K1,K2,K3,然后分别检查第3,1,14位是否为1,如果都为1,则A很有可能(注意是可能)存在。
在比特币中,Bloom过滤器主要也是用在SPV节点的实现上,在查询交易的同时又不暴露用户的钱包地址隐私。
比特币的bloom过滤器的实现位于bloom.cpp文件中,简单过一下源码:
(1) 构造
bloom过滤器的构造函数如下:
CBloomFilter::CBloomFilter(const unsigned int nElements, const double nFPRate, const unsigned int nTweakIn, unsigned char nFlagsIn) :
/**
* The ideal size for a bloom filter with a given number of elements and false positive rate is:
* - nElements * log(fp rate) / ln(2)^2
* We ignore filter parameters which will create a bloom filter larger than the protocol limits
*/
vData(std::min((unsigned int)(-1 / LN2SQUARED * nElements * log(nFPRate)), MAX_BLOOM_FILTER_SIZE * 8) / 8),
/**
* The ideal number of hash functions is filter size * ln(2) / number of elements
* Again, we ignore filter parameters which will create a bloom filter with more hash functions than the protocol limits
* See https://en.wikipedia.org/wiki/Bloom_filter for an explanation of these formulas
*/
isFull(false),
isEmpty(true),
nHashFuncs(std::min((unsigned int)(vData.size() * 8 / nElements * LN2), MAX_HASH_FUNCS)),
nTweak(nTweakIn),
nFlags(nFlagsIn)
{
}vData是存放二进制串的向量,根据代码注释,理想的向量的长度未-nElements * log(fp rate) / ln2^2,至于为什么这么算就不是很清楚了,数学学的好的同学可以在评论区里指导一下。
nHashFuncs是对每个输入进行多少次hash。
(2) 插入元素到bloom过滤器中
void CBloomFilter::insert(const std::vector& vKey)
{
if (isFull)
return;
for (unsigned int i = 0; i < nHashFuncs; i++)
{
unsigned int nIndex = Hash(i, vKey);
// Sets bit nIndex of vData
vData[nIndex >> 3] |= (1 << (7 & nIndex));
}
isEmpty = false;
} 代码很简单,对每个输入,进行nHashFuncs次Hash运算,将映射到的值写入向量vData对应的bit。
这里Hash的计算方法关注一下:
inline unsigned int CBloomFilter::Hash(unsigned int nHashNum, const std::vector& vDataToHash) const
{
// 0xFBA4C795 chosen as it guarantees a reasonable bit difference between nHashNum values.
return MurmurHash3(nHashNum * 0xFBA4C795 + nTweak, vDataToHash) % (vData.size() * 8);
} 注意一下这里的MurmurHash3,这是一个非加密型的hash算法,由Austin Appleby于2008年发明,具有抗碰撞性强、速度快的特点,目前已经被很多知名的开源项目所使用,而发明此算法的Austin Appleby本人也被google聘用(论数学的重要性),现在MurmurHash已经到了第3个版本,下面的链接详细的对此算法进行了介绍,并包含伪码:
murmurHash介绍
比特币murmurhash3的实现如下,可以结合上面链接中的伪码看:
unsigned int MurmurHash3(unsigned int nHashSeed, const std::vector& vDataToHash)
{
// The following is MurmurHash3 (x86_32), see http://code.google.com/p/smhasher/source/browse/trunk/MurmurHash3.cpp
uint32_t h1 = nHashSeed;
const uint32_t c1 = 0xcc9e2d51;
const uint32_t c2 = 0x1b873593;
const int nblocks = vDataToHash.size() / 4;
//----------
// body
const uint8_t* blocks = vDataToHash.data();
for (int i = 0; i < nblocks; ++i) {
uint32_t k1 = ReadLE32(blocks + i*4);
k1 *= c1;
k1 = ROTL32(k1, 15);
k1 *= c2;
h1 ^= k1;
h1 = ROTL32(h1, 13);
h1 = h1 * 5 + 0xe6546b64;
}
//----------
// tail
const uint8_t* tail = vDataToHash.data() + nblocks * 4;
uint32_t k1 = 0;
switch (vDataToHash.size() & 3) {
case 3:
k1 ^= tail[2] << 16;
case 2:
k1 ^= tail[1] << 8;
case 1:
k1 ^= tail[0];
k1 *= c1;
k1 = ROTL32(k1, 15);
k1 *= c2;
h1 ^= k1;
}
//----------
// finalization
h1 ^= vDataToHash.size();
h1 ^= h1 >> 16;
h1 *= 0x85ebca6b;
h1 ^= h1 >> 13;
h1 *= 0xc2b2ae35;
h1 ^= h1 >> 16;
return h1;
} 关于merkle树和bloom过滤器的使用,可以参考比特币改进协议BIP37 :
BIP37改进协议
4 总结
本文对比特币系统中使用到的一些基本密码学算法做了介绍,这些基础的密码学算法对于理解比特币的一些关键特性至关重要:
(1) hash及比特币利用hash的特点确保数据不可篡改;
(2) 对称加密及非对称加密,介绍了比特币中使用的椭圆曲线算法;
(3) 数字签名的过程,比特币中通过数字签名验证未花费输出(UTXO)所有权的原理及实现;
(4) merkle树和bloom过滤器,说明了merkle树和bloom过滤器在比特币SPV简易支付验证中的应用;