秒懂Dubbo接口(原理篇)
文章目录
- 引言
- 背景
- 单一应用架构
- 垂直应用架构
- 分布式服务架构
- 流动计算架构
- 为什么要用 Dubbo?
- 什么是分布式?
- 为什么要分布式?
- Dubbo 的架构
- Dubbo 的架构图解
- Dubbo 工作原理
- Dubbo 的负载均衡策略
- 先来解释一下什么是负载均衡
- 再来看看 Dubbo 提供的负载均衡策略
- Random LoadBalance(默认,基于权重的随机负载均衡机制)
- RoundRobin LoadBalance(不推荐,基于权重的轮询负载均衡机制)
- LeastActive LoadBalance
- ConsistentHash LoadBalance
- 配置方式
- zookeeper宕机与dubbo直连的情况
引言
在上文性能基础之常见RPC框架浅析中我们详细介绍常见的RPC框架,本文将详细介绍Dubbo接口。
背景
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
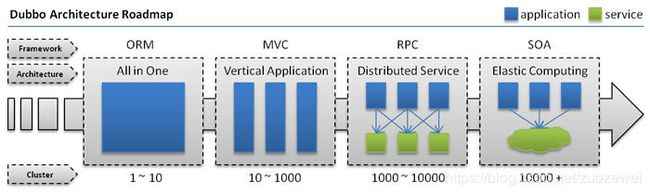
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
流动计算架构
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
为什么要用 Dubbo?
Dubbo 的诞生和 SOA 分布式架构的流行有着莫大的关系。SOA 面向服务的架构(Service Oriented Architecture),也就是把工程按照业务逻辑拆分成服务层、表现层两个工程。服务层中包含业务逻辑,只需要对外提供服务即可。表现层只需要处理和页面的交互,业务逻辑都是调用服务层的服务来实现。SOA架构中有两个主要角色:服务提供者(Provider)和服务使用者(Consumer)。
如果你要开发分布式程序,你也可以直接基于 HTTP 接口进行通信,但是为什么要用 Dubbo呢?
我觉得主要可以从 Dubbo 提供的下面四点特性来说为什么要用 Dubbo:
- 负载均衡——同一个服务部署在不同的机器时该调用那一台机器上的服务
- 服务调用链路生成——随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
- 服务访问压力以及时长统计、资源调度和治理——基于访问压力实时管理集群容量,提高集群利用率。
- 服务降级——某个服务挂掉之后调用备用服务
另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
我们刚刚提到了分布式这个概念,下面再给大家介绍一下什么是分布式?为什么要分布式?
什么是分布式?
分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
为什么要分布式?
从开发角度来讲单体应用的代码都集中在一起,而分布式系统的代码根据业务被拆分。所以,每个团队可以负责一个服务的开发,这样提升了开发效率。另外,代码根据业务拆分之后更加便于维护和扩展。
另外,我觉得将系统拆分成分布式之后不光便于系统扩展和维护,更能提高整个系统的性能。你想一想嘛?把整个系统拆分成不同的服务/系统,然后每个服务/系统 单独部署在一台服务器上,是不是很大程度上提高了系统性能呢?
Dubbo 的架构
Dubbo 的架构图解
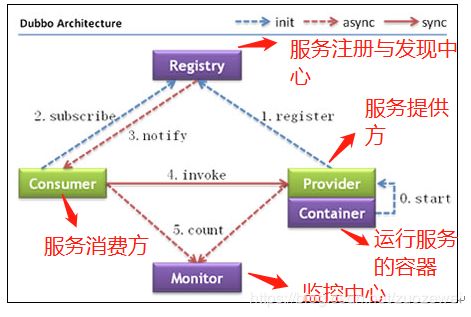
述节点简单说明:
- Provider: 暴露服务的服务提供方
- Consumer: 调用远程服务的服务消费方
- Registry: 服务注册与发现的注册中心
- Monitor: 统计服务的调用次数和调用时间的监控中心
- Container: 服务运行容器
调用关系说明:
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟8. 发送一次统计数据到监控中心。
重要知识点总结:
- 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
- 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
- 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
- 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
- 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
- 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
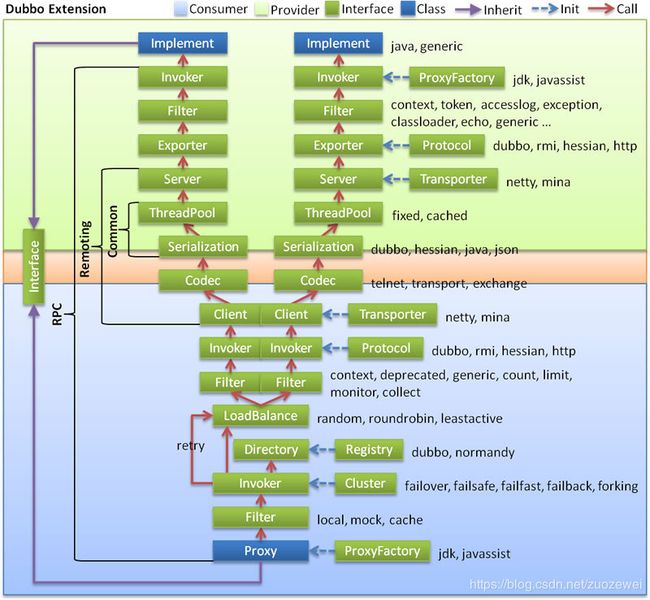
Dubbo 工作原理
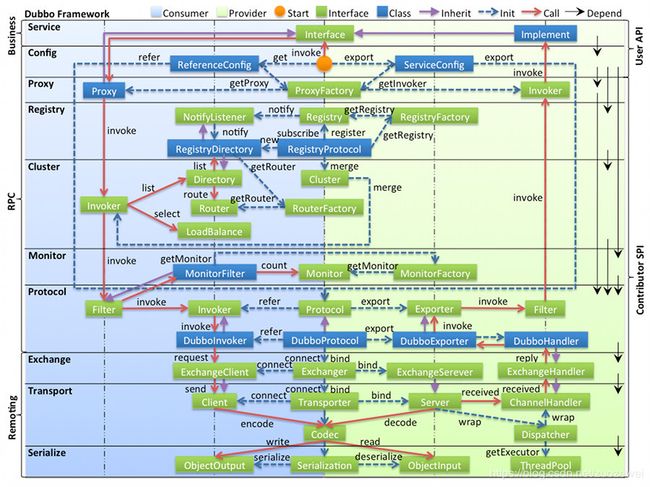
图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI。
各层说明:
- 第一层:service层,接口层,给服务提供者和消费者来实现的
- 第二层:config层,配置层,主要是对dubbo进行各种配置的
- 第三层:proxy层,服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton
- 第四层:registry层,服务注册层,负责服务的注册与发现
- 第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
- 第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控
- 第七层:protocol层,远程调用层,封装rpc调用
- 第八层:exchange层,信息交换层,封装请求响应模式,同步转异步
- 第九层:transport层,网络传输层,抽象mina和netty为统一接口
- 第十层:serialize层,数据序列化层。网络传输需要。
从上图可以看出,Dubbo对于服务提供方和服务消费方,从框架的10层中分别提供了各自需要关心和扩展的接口,构建整个服务生态系统(服务提供方和服务消费方本身就是一个以服务为中心的)。
根据官方提供的,对于上述各层之间关系的描述,如下所示:
-
在 RPC 中,Protocol 是核心层,也就是只要有Protocol + Invoker + Exporter 就可以完成非透明的RPC调用,然后在Invoker的主过程上Filter拦截点。
-
图中的 Consumer 和Provider是抽象概念,只是想让看图者更直观的了解哪些类分属于客户端与服务器端,不用Client和Server的原因是Dubbo在很多场景下都使用Provider、Consumer、Registry、Monitor划分逻辑拓普节点,保持统一概念。
-
而Cluster是外围概念,所以Cluster的目的是将多个Invoker伪装成一个Invoker,这样其它人只要关注Protocol层Invoker即可,加上Cluster或者去掉Cluster对其它层都不会造成影响,因为只有一个提供者时,是不需要Cluster的。
-
Proxy层封装了所有接口的透明化代理,而在其它层都以Invoker为中心,只有到了暴露给用户使用时,才用Proxy将Invoker转成接口,或将接口实现转成Invoker,也就是去掉Proxy层RPC是可以Run的,只是不那么透明,不那么看起来像调本地服务一样调远程服务。
-
而Remoting 实现是Dubbo协议的实现,如果你选择RMI协议,整个Remoting都不会用上,Remoting内部再划为Transport传输层和Exchange信息交换层,Transport层只负责单向消息传输,是对Mina、Netty、Grizzly的抽象,它也可以扩展UDP传输,而Exchange层是在传输层之上封装了Request-Response语义。
-
Registry和Monitor实际上不算一层,而是一个独立的节点,只是为了全局概览,用层的方式画在一起。
从上面的架构图中,我们可以了解到,Dubbo作为一个分布式服务框架,主要具有如下几个核心的要点:
服务定义
服务是围绕服务提供方和服务消费方的,服务提供方实现服务,而服务消费方调用服务。
服务注册
对于服务提供方,它需要发布服务,而且由于应用系统的复杂性,服务的数量、类型也不断膨胀;对于服务消费方,它最关心如何获取到它所需要的服务,而面对复杂的应用系统,需要管理大量的服务调用。而且,对于服务提供方和服务消费方来说,他们还有可能兼具这两种角色,即既需要提供服务,有需要消费服务。
通过将服务统一管理起来,可以有效地优化内部应用对服务发布/使用的流程和管理。服务注册中心可以通过特定协议来完成服务对外的统一。
Dubbo提供的注册中心有如下几种类型可供选择:
-
Multicast注册中心
-
Zookeeper注册中心
-
Redis注册中心
-
Simple注册中心
服务监控
无论是服务提供方,还是服务消费方,他们都需要对服务调用的实际状态进行有效的监控,从而改进服务质量。
远程通信与信息交换
远程通信需要指定通信双方所约定的协议,在保证通信双方理解协议语义的基础上,还要保证高效、稳定的消息传输。Dubbo继承了当前主流的网络通信框架,主要包括如下几个:
-
Mina
-
Netty
-
Grizzly
服务调用
下面从Dubbo官网直接拿来,看一下基于RPC层,服务提供方和服务消费方之间的调用关系,如图所示:
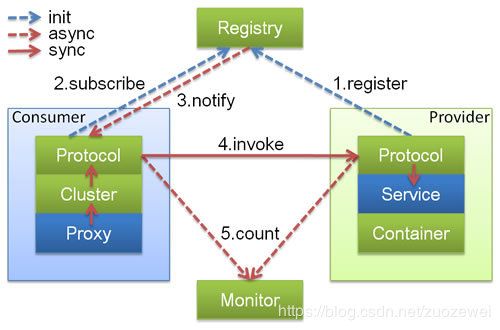
上图中,蓝色的表示与业务有交互,绿色的表示只对Dubbo内部交互。上述图所描述的调用流程如下:
-
服务提供方发布服务到服务注册中心;
-
服务消费方从服务注册中心订阅服务;
-
服务消费方调用已经注册的可用服务
接着,将上面抽象的调用流程图展开,详细如图所示:
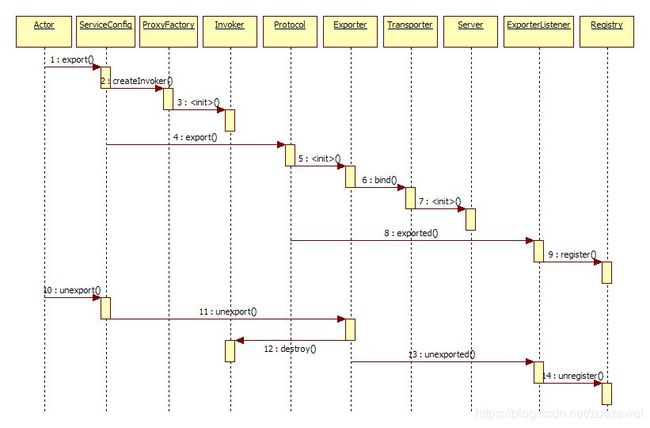
注册/注销服务
服务的注册与注销,是对服务提供方角色而言,那么注册服务与注销服务的时序图,如图所示:
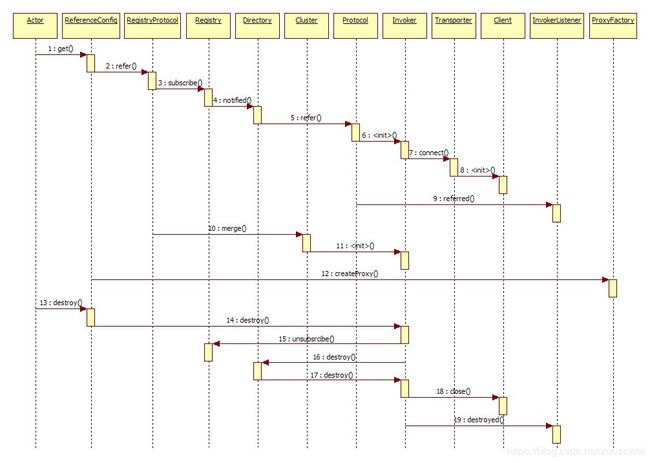
服务订阅/取消
为了满足应用系统的需求,服务消费方的可能需要从服务注册中心订阅指定的有服务提供方发布的服务,在得到通知可以使用服务时,就可以直接调用服务。反过来,如果不需要某一个服务了,可以取消该服务。下面看一下对应的时序图,如图所示:
协议支持
Dubbo支持多种协议,如下所示:
-
Dubbo协议
-
Hessian协议
-
HTTP协议
-
RMI协议
-
WebService协议
-
Thrift协议
-
Memcached协议
-
Redis协议
在通信过程中,不同的服务等级一般对应着不同的服务质量,那么选择合适的协议便是一件非常重要的事情。你可以根据你应用的创建来选择。例如,使用RMI协议,一般会受到防火墙的限制,所以对于外部与内部进行通信的场景,就不要使用RMI协议,而是基于HTTP协议或者Hessian协议。
参考补充
Dubbo以包结构来组织各个模块,各个模块及其关系,如图所示:
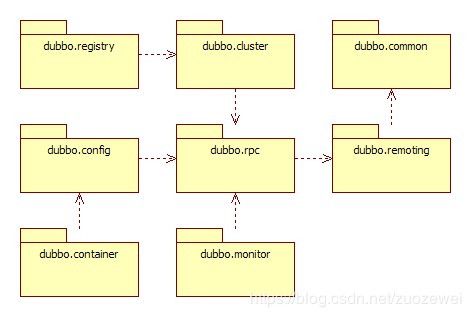
可以通过Dubbo的代码(使用Maven管理)组织,与上面的模块进行比较。简单说明各个包的情况:
-
dubbo-common 公共逻辑模块,包括Util类和通用模型。
-
dubbo-remoting 远程通讯模块,相当于Dubbo协议的实现,如果RPC用RMI协议则不需要使用此包。
-
dubbo-rpc 远程调用模块,抽象各种协议,以及动态代理,只包含一对一的调用,不关心集群的管理。
-
dubbo-cluster 集群模块,将多个服务提供方伪装为一个提供方,包括:负载均衡、容错、路由等,集群的地址列表可以是静态配置的,也可以是由注册中心下发。
-
dubbo-registry 注册中心模块,基于注册中心下发地址的集群方式,以及对各种注册中心的抽象。
-
dubbo-monitor 监控模块,统计服务调用次数,调用时间的,调用链跟踪的服务。
-
dubbo-config 配置模块,是Dubbo对外的API,用户通过Config使用Dubbo,隐藏Dubbo所有细节。
-
dubbo-container 容器模块,是一个Standalone的容器,以简单的Main加载Spring启动,因为服务通常不需要Tomcat/JBoss等Web容器的特性,没必要用Web容器去加载服务。
Dubbo 的负载均衡策略
先来解释一下什么是负载均衡
先来个官方的解释。
维基百科对负载均衡的定义:负载均衡改善了跨多个计算资源(例如计算机,计算机集群,网络链接,中央处理单元或磁盘驱动的的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。使用具有负载平衡而不是单个组件的多个组件可以通过冗余提高可靠性和可用性。负载平衡通常涉及专用软件或硬件
上面讲的大家可能不太好理解,再用通俗的话给大家说一下。
比如我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
再来看看 Dubbo 提供的负载均衡策略
在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 random 随机调用。可以自行扩展负载均衡策略,参见:负载均衡扩展。
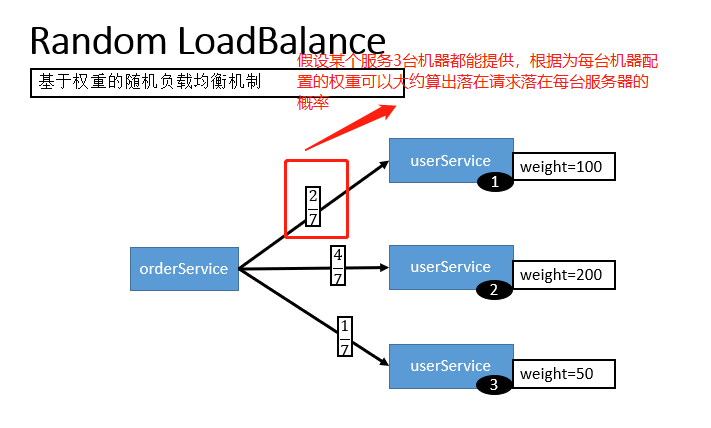
Random LoadBalance(默认,基于权重的随机负载均衡机制)
- 随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
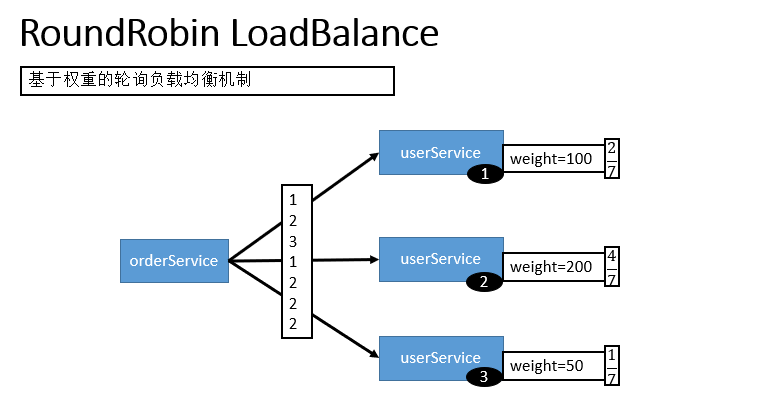
RoundRobin LoadBalance(不推荐,基于权重的轮询负载均衡机制)
- 轮循,按公约后的权重设置轮循比率。
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive LoadBalance
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance
- 一致性 Hash,相同参数的请求总是发到同一提供者。(如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性hash策略。)
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
- 缺省只对第一个参数 Hash,如果要修改,请配置
- 缺省用 160 份虚拟节点,如果要修改,请配置
配置方式
xml 配置方式
服务端服务级别
<dubbo:service interface="..." loadbalance="roundrobin" />
客户端服务级别
<dubbo:reference interface="..." loadbalance="roundrobin" />
服务端方法级别
<dubbo:service interface="...">
<dubbo:method name="..." loadbalance="roundrobin"/>
</dubbo:service>
客户端方法级别
<dubbo:reference interface="...">
<dubbo:method name="..." loadbalance="roundrobin"/>
</dubbo:reference>
注解配置方式:
消费方基于基于注解的服务级别配置方式:
@Reference(loadbalance = "roundrobin")
HelloService helloService;
zookeeper宕机与dubbo直连的情况
zookeeper 宕机与 dubbo 直连的情况在面试中可能会被经常问到,所以要引起重视。
在实际生产中,假如 zookeeper 注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,这只是dubbo健壮性的一种提现。
dubbo的健壮性表现:
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
我们前面提到过:注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。所以,我们可以完全可以绕过注册中心——采用 dubbo 直连 ,即在服务消费方配置服务提供方的位置信息。
xml配置方式:
<dubbo:reference id="userService" interface="com.zuozewei.gmall.service.UserService" url="dubbo://localhost:20880" />
注解方式:
@Reference(url = "127.0.0.1:20880")
HelloService helloService;
参加文献:
[1] http://dubbo.incubator.apache.org/zh-cn/docs/user/quick-start.html
[2]https://github.com/Snailclimb/JavaGuide/blob/master/计算机网络与数据通信/dubbo.md