Hive数据仓库的使用
之前一直没有找到Hive和yarn的实例,这片文章的例子挺详细的。https://zhuanlan.zhihu.com/p/29231823
1、Hive基本使用
*创建表和使用hive进行wordcound统计(对比mapreduce的实现的易用性)
建表语句:CREATE TABLE table_name
[(col_name data_type [COMMENT col_comment])]
那么我们进入hive建立一张hive_wordcound表格
create table hive_wordcount(context string); 注:这里还有个问题,你启动hive有的盆友会报错,比如常见的:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory。。。。。。。
这样的错误,这种情况是你需要关闭安全模式
输入hadoop dfsadmin -safemode leave 关闭
其实找错误的时候可以开启调试模式输入export HADOOP_ROOT_LOGGER=DEBUG,console
关闭调试模式export HADOOP_ROOT_LOGGER=INFO,console
好了创建成功,select表是什么都没有的,我们进终端看看
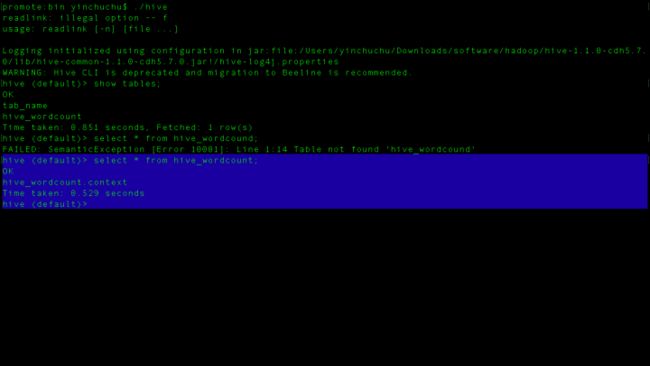
好了,这个时候我们再切到mysql中去看看元数据
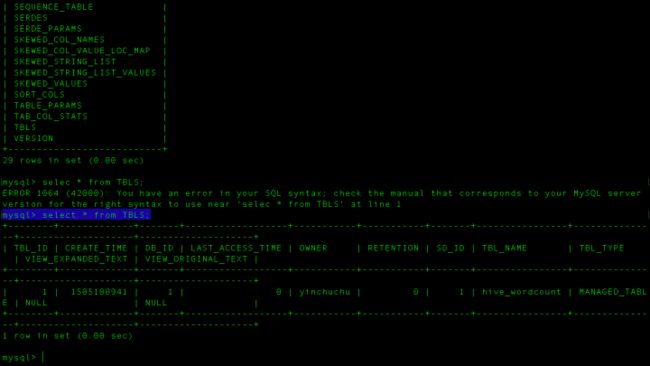
进到TBLS看到没,已经有这么个表了,表的id是1,表名叫做hive_wordcound,再来看看字段有哪些。进入COLUMNS_V2
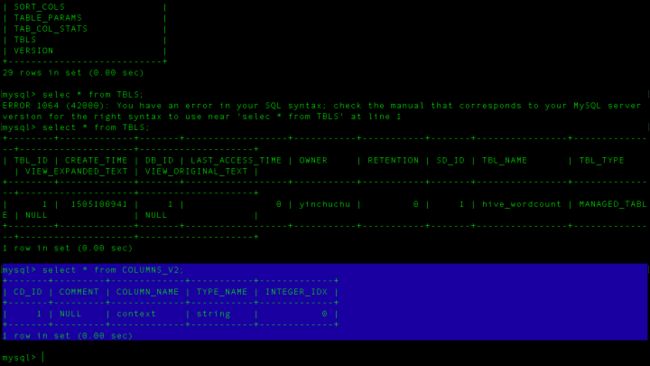
只有一个context字段,现在表建好了,那么是不是要把数据放到里面去呢?
加载数据到hive表语句:LOAD DATA LOCAL INPATH 'filepath' INTO TABLE tablename (不加 local就是在hdfs上加载过来)
根据语句在终端输入:
load data local inpath '/Users/yinchuchu/Downloads/software/hadoop/hadoop-2.6.0-cdh5.7.0/tmp/test/input/wc/hello.txt
' into table hive_wordcount;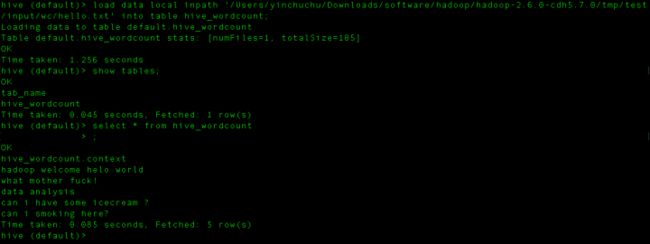
好了,现在select发现数据有了!那么数据有了,下面就要统计词频了!
这里就要用到hive一些函数了。
sql语句:select word, count(1) from hive_wordcount lateral view explode(split(context,'\s')) wc as word group by word;
注:lateral view explode(): 是把每行记录按照指定分隔符进行拆解
split(context,'\s')
hive ql提交执行以后会生成mr作业,并在yarn上运行
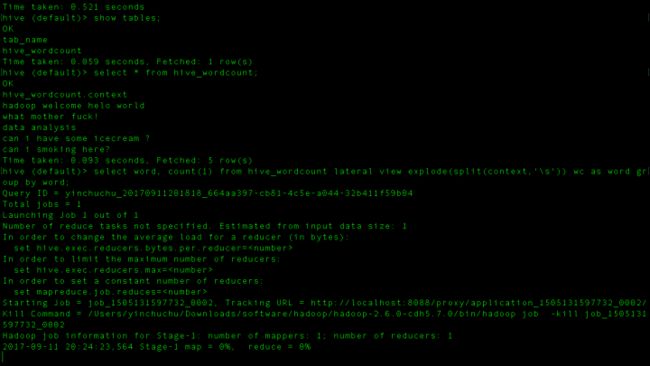
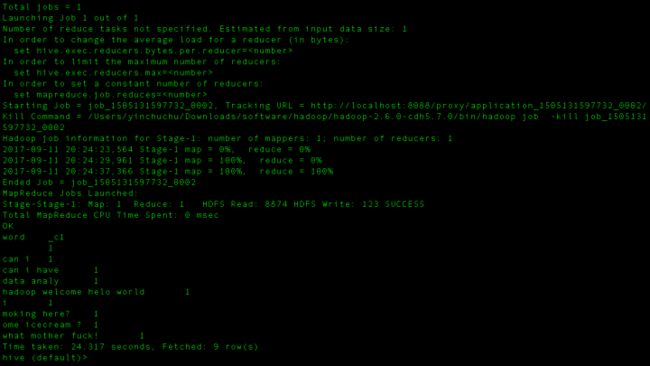

上面是正常运行的截图,但是很多人可能会卡在mapreduce开始job的时候,这个时候就停掉把debug调出来,然后查错误,这个时候肯定会报错的,找到错误的那一条,可能是org.apache.hadoop.util.NativeCodeLoader.buildSupportsOpenssl()Z也可能是java.Uknown等等之类的错误,总之如果卡在开始很可能你的hosts文件有问题,或者你的hadoop配置文件,core-site.xml这些文件配置有问题!google上有很多很多的解决方案。报错不用着急,找错误并且解决掉也是成长的一种方式!
其实到这里应该就能知道,hiveql提交执行以后会生成mapreduce作业,并在yarn上运行,
这就是hive的好处,你只需要写sql语句就能够对文件系统中的数据使用SQL的方式来进行大数据的统计和分析。
到这一步来看使用hive和mapreduce哪个简单?肯定是hive简单,只需要sql语句就能完成对大数据的统计和分析!
*创建一个案例
我们再创建一个公司部门的表来进一步讲述hive的使用。
一个是员工表 emp.txt
一个是部门表dept.txt
首先来看员工表 emp.txt
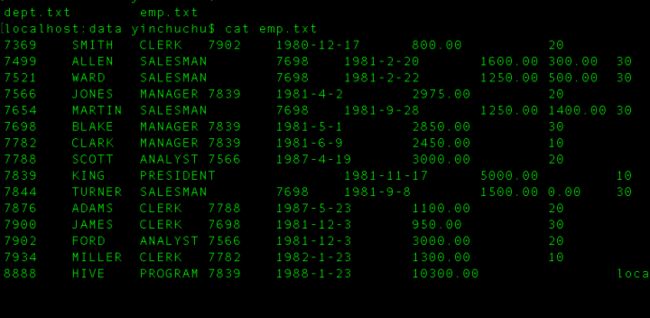
从第一列开始是员工编号、员工名称、员工岗位、员工上级领导的编号、员工入职的时间、员工的工资、员工经贴(有的有有的没有)、员工的部门编号。
然后再来看部门表。

从第一列开始是部门编号、部门名称、部门地址。
根据这两张表创建我们的表。
首先是员工表
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
然后是部门表
create table dept(
deptno int,
dname string,
location string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';注:ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';这一句表示字段之间的分隔符用制表符tab键
然后把这两段sql语句在hive中执行
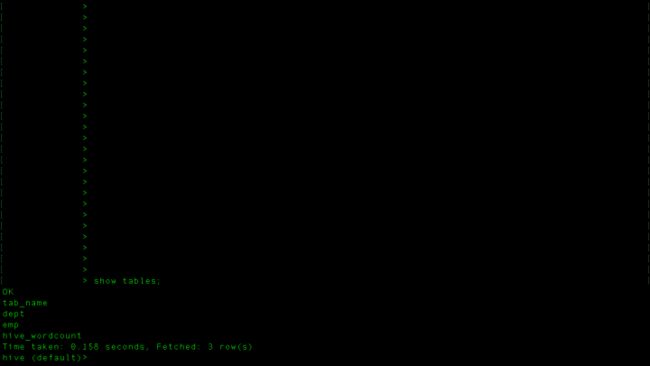
执行完了之后表中还没有数据,我们要导入数据,和上面导入数据到hive中一样。
load data local inpath '/Users/yinchuchu/Downloads/software/hadoop/SparkSql/data/emp.txt' into table emp;
load data local inpath '/Users/yinchuchu/Downloads/software/hadoop/SparkSql/data/dept.txt' into table dept;
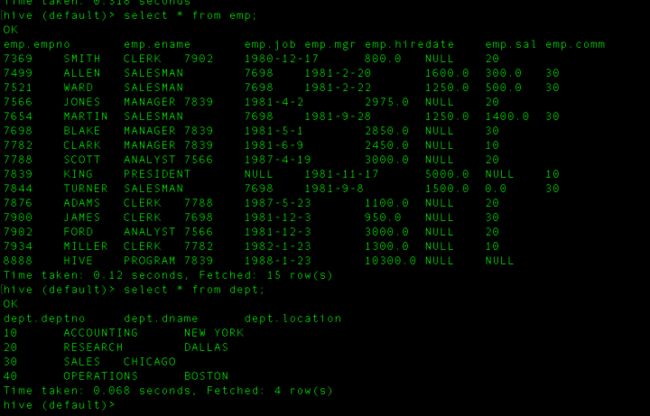
现在数据进来了,我们利用这个数据进行简单的统计,统计每个部门员工人数,这个只需要emp表就能完成。
sql语句这样写
select deptno, count(1) from emp group by deptno;这句sql表示按照deptno(部门编号)进行分组,求每个部门的人数count(1)
可以看到,执行开始自动提交mapreduce作业!
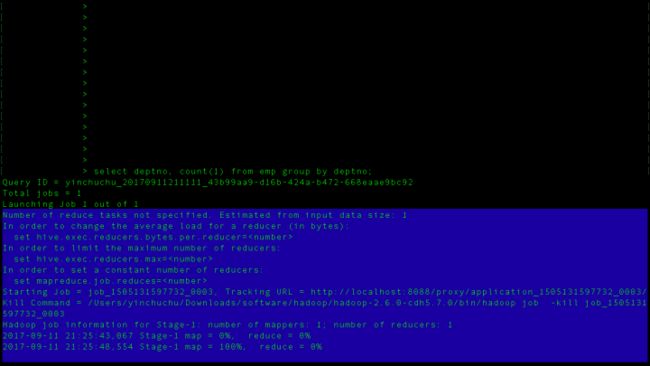
然后我们打开yarn页面来看看。
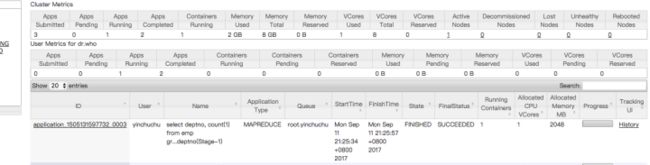
这就是一个mapreduce作业嘛!我们看执行结果!
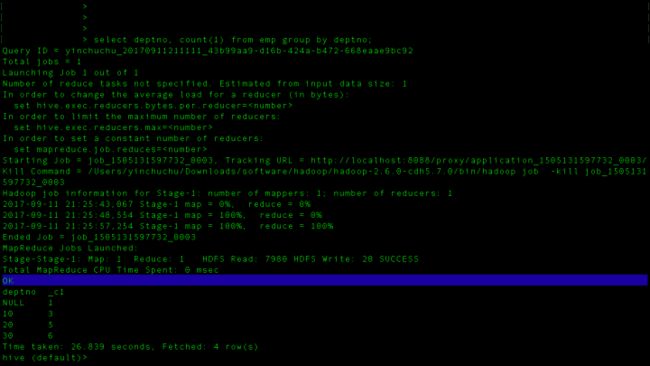
结果出来了!我们的数据量虽然很小,但是mapreduce花的时间可一点都不少!
好了,到此数据仓库Hive的使用就写到这里吧!