Facebook 开源语音识别工具wav2letter环境搭建
wav2letter ++是Facebook AI Research语音团队的快速开源语音处理工具包,它是一个简单高效的端到端自动语音识别(ASR)系统。它完全用C ++编写,使用ArrayFire张量库和flashlight机器学习库来实现最高效率。该软件的目标是促进端到端语音识别模型的研究。
下面我们来搭建wav2letter ++开发环境。
我的环境是ubuntu18.04,GTX1070 GPU下搭建。
首先安装wav2letter所需要的依赖库,flashlight,arrayfire,,libsndlife,MKL,KenLM,gflags,glog,CUDA,CUDNN.CUDA安装CUDA9.2,cudnn 7.4.1.
安装MKL
到英特尔官网下载https://software.intel.com/en-us/mkl MKL库,本文下载的是l_mkl_2018.0.128这个版本.
采用tar -xvzf命令解压安装包

图形安装执行sh install_GUI.sh
按照提示安装即可。
安装完成还需要配置下环境,在.bashrc设置环境:export MKLROOT=/opt/intel/mkl,设置完成执行source ~/.bashrc生效。
安装ArrayFire
执行 git clone https://github.com/arrayfire/arrayfire.git
sudo apt-get install -y build-essential git cmake libfreeimage-dev
sudo apt-get install -y cmake-curses-gui
sudo apt-get install libglfw3-dev libfontconfig1-dev libglm-dev
cd / path / to / dir / arrayfire
mkdir build && cd build
cmake .. -DCMAKE_BUILD_TYPE =Release
sudo make -j4
安装libsndfile
获取源代码 git clone git://github.com/erikd/libsndfile.git
sudo apt install autoconf autogen automake build-essential libasound2-dev \ libflac-dev libogg-dev libtool libvorbis-dev pkg-config python
./autogen.sh
./configure --enable-werror
sudo make -j4
make check
安装flashlight
执行 git clone https://github.com/facebookresearch/flashlight.git下载源码。
# in the flashlight project directory:
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release -DFLASHLIGHT_BACKEND=CUDA # valid backend
make -j4 # (or any number of threads)
sudo make install
安装完成。
安装kenlm
wget -O - https://kheafield.com/code/kenlm.tar.gz |tar xz
mkdir kenlm/build
cd kenlm/build
cmake ..
make -j4
安装wav2letter++
下载代码 git clone https://github.com/facebookresearch/wav2letter.git
# in your wav2letter++ directory
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release -DW2L_CRITERION_BACKEND=CUDA # Replace backend with CUDA or CPU
sudo make -j4 # (or any number of threads) 自此安装完毕. wav2letter++训练模型
准备数据
首先数据进行预处理.
到这个网站http://www.openslr.org/12/下载LibriSpeech语料数据集。
python3 prepare_data.py --src /data/aiwork/data/LibriSpeech/ --dst cleaned_data (对应训练数据路径)
python3 prepare_lm.py --dst cleaned_data
为了使用wav2letter ++训练语音识别模型,我们通常期望以下输入
- Audio and Transcriptions data
- Token dictionary
- Lexicon
- Language Model
每个样本将有4个相应的文件
.flac/.wav- 音频文件。使用-inputflag 指定扩展名。.wrd- 包含转录的单词文件。.tkn- 令牌文件。使用-targetflag 指定扩展名。.id- 文件的标识符。每一行都是由制表符分隔的键值对
训练声学模型
将train.cfg文件中的[...]替换成自己机器的本地路径。

执行/data/aiwork/wav2letter/build/Train train --flagsfile /data/aiwork/wav2letter/tutorials/1-librispeech_clean/train.cfg开始训练声学模型。大概跑了7-8个小时,训练完成。
解码
将decode.cfg文件中的[...]替换成自己机器的本地路径。

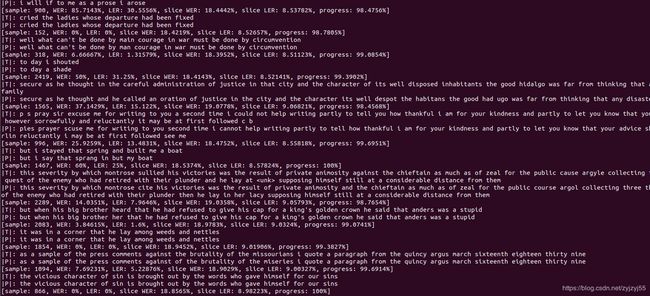
执行/data/aiwork/wav2letter/build/Decoder --flagsfile /data/aiwork/wav2letter/tutorials/1-librispeech_clean/decode.cfg
进行解码。
解码完成.