Python笔记【二】
之前分享过一次我在学习Python的笔记,Python笔记【一】,最近有些新的收获,分享一下;
random.sample() 随机不重复的数
工作中,有时候是需要在数据库手动去造些数据的,有些字段类似 order_id ,一般都是不重复的(在不考虑有退款等其他异常的情况下),若要造超多数量、不重复的order_id,该如何来做?
推荐使用random.sample();实际 在遇到生成随机整数的时候,我第一反应就是random.randint(),我们对比下:

循环random.randint(),实际会有重复的元素,而使用 range() + random.sample() 不会重复
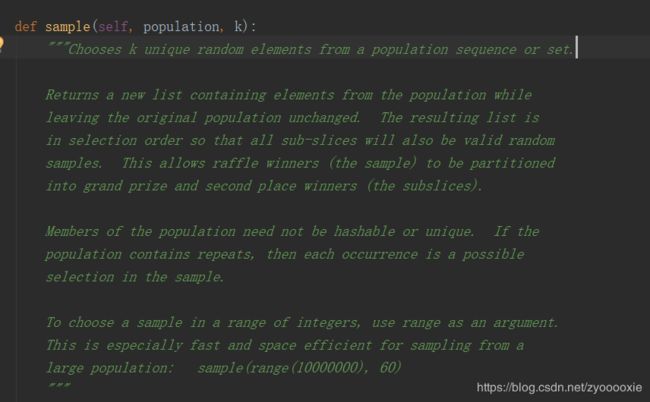
【请注意:这个用法 sample(range(10000000), 60) 是本身就给了一个没有重复元素的range】
【若给了一个有重复元素的population,实际筛选出来的元素还是 会重复的】
a = [1, 1, 1, 1, 23, 213, 1322, 41, 111, 'zyoo1111ooxie', 'zyooooxie', 213, 1323, 213, 'zyooooxie', 'zyooooxie', 'zyooooxie', 1322, 41, 111, 'csdn', 'zyooooxie']
print(a)
print(random.sample(a, 7))
print({(ele, a.count(ele))for ele in a})
执行结果如下:

实际有set 后有10个,我就单单取7个,可结果是有3个相同的1;
rfind() 从右边开始查找 第一次出现的位置
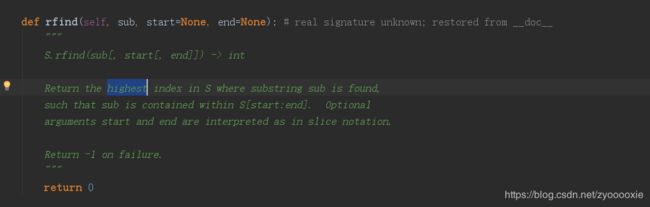
说2个好笑的: 1. 上图我标注的 Return the highest index in S where substring sub is found。 看到 有地方介绍 rfind()是 会返回某字符串最后一次出现的位置,我的第一想法:从右边开始 最后一次,那不就是 从左边 首次出现吗?好像不对呀。 然后才明白:那儿的意思是 从左边最后一次,不正是我想的从右边 first嘛 【和注释也对得上】。 2. 既然有rfind() ,是不是也有lfind() ,为啥没有啊? = =
字符串find() != -1
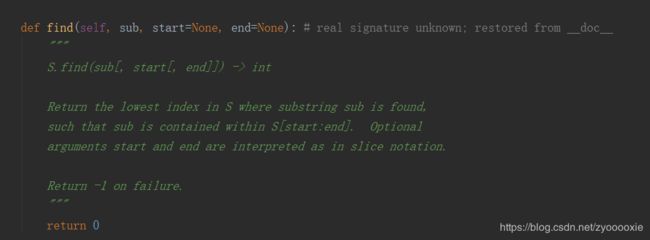
find() 检测字符串中是否包含子字符串 sub,如果指定 start 和 end 范围,则在指定范围内 检查是否包含。不传start 和end,是从最开始-左侧开始find, 这不正是lfind() ?
这儿主要是想说下 :Return -1 on failure
因为 我往往不能确定子字符串的index,反而使用 str_xx.find('xxxx) != -1 会更多。
字符串开头、结尾 startswith() \endwith()
有时候确定 某字符串是否以某子字符串为开头、结尾,就要用到startswith()、 endswith();
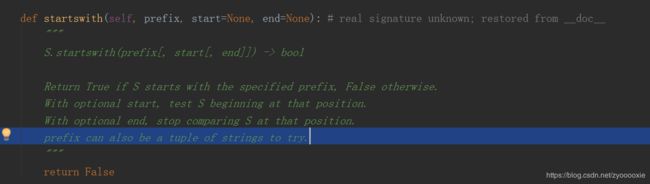
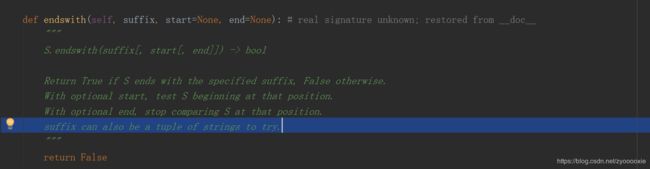
这儿要说的是上面2图 鼠标所在那行 prefix can also be a tuple of strings to try 。suffix传参一个 全都为str的tuple,可以用来判断N个元素。

list.index() == -1 【错误用法】
标题是错误的(我在遇到第2次,才反应过来);
一直以来,访问列表的最后一个元素,我用的是list[-1],不知不觉就和list.index()用乱了。
list.index(obj):从列表中找出某个值第一个匹配项的索引位置
我之所以用list.index(obj) == -1, 是想当然认为 list的最后一个元素的索引是-1; 但实际索引是从0开始【大于等于0】;
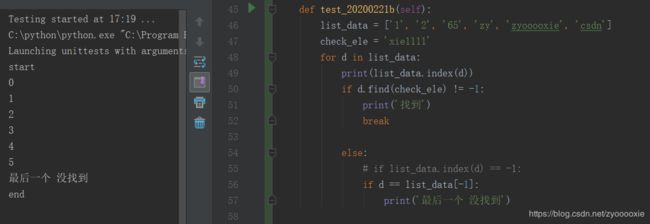
def test_20200221b(self):
list_data = ['1', '2', '65', 'zy', 'zyooooxie', 'csdn']
check_ele = 'xie1111'
for d in list_data:
print(list_data.index(d))
if d.find(check_ele) != -1:
print('找到')
break
else:
if list_data.index(d) == -1:
# if d == list_data[-1]:
print('最后一个 没找到')
拿这个用例来做个说明,想看下list_data下面哪个元素可以find(check_ele),如果找到就结束for循环;如果最后那个元素也不符合,就 print没找到;
实际执行结果:

为什么没有 print‘没找到’? 实际就是 else里面 if判断出了问题【列表的索引 不会等于 -1】;
字符串 replace() 可控替换次数
先看下源码: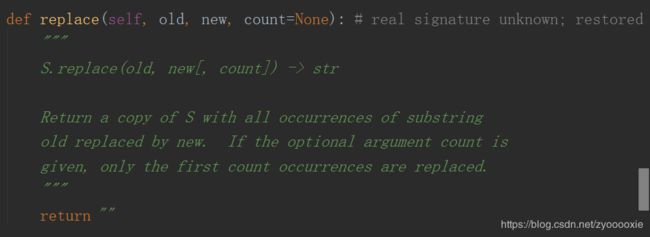
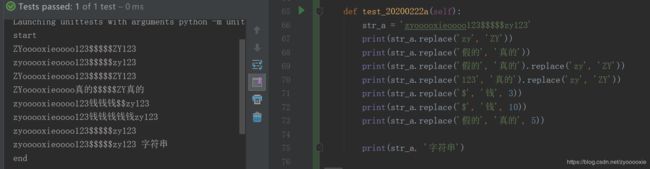
我是很喜欢用replace() 的,总结:
1.replace() 返回一个字符串的副本,其中出现的旧字符(old)被替换为新的(new),可选地将替换数count限制为最大值;
2.不传count,会把当前所有符合的old都替换为new ;
3.old的参数不存在,不报错,生成的新字符串和原 string 保持一致 ;
4.可以多次replace() ;
5.replace 不会改变原 string 的内容;
6.count 传超过 实际替换次数,也不会报错;
递归
说起递归,就想起以前面试的时候遇到过2次这样的考题,很有印象的;
这儿说一个情景:我今天发生5笔交易【-10,+20,-15,+124,-156】,最初手上是50块钱,每笔交易之后我手上多少钱?
思路:50-10 为第一笔交易后的钱【期初 + 第一笔】; 50-10+20 为第二笔交易的钱【第一笔交易后的钱 + 第二笔】; 50-10+20-15 为第三笔交易的钱【第二笔交易后的钱 + 第三笔】,依此类推;
def fun_recursive(self, x, amount_list, opening):
if x == 0:
return round(opening + amount_list[0], 2)
else:
return round(self.fun_recursive(x - 1, amount_list, opening) + amount_list[x], 2)

这样就可以得到: 每笔交易后 手上的钱数 40, 60, 45, 169, 13。
若干笔交易,是不是也很容易得到结果呢?
实际,递归次数太多,会报错 maximum recursion depth exceeded;

针对这问题,咋解决? 手动设置 递归次数限制:
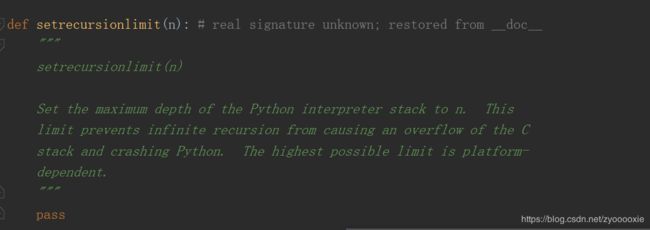
代码如下:
import sys
sys.setrecursionlimit(10000)
这儿虽然设置为10000次,但我电脑在3200次左右,内存差不多吃不消;【下图和前面的是同一条用例,只是设置了setrecursionlimit】

倘若 交易量真为数千笔呢?数万笔呢?
def test_20200222_abc(self):
amount_list = random.sample(range(6000, 600000000000), 359162)
# 单笔交易Amount在6000-600000000000,共发生359162笔交易;期初设置为500
opening = 500
if len(amount_list) <= 3000: # 将3000作为1次递归的长度
# dg_last_value = self.fun_Recursive(len(amount_list) - 1, amount_list, opening)
# print(dg_last_value)
dg_value = [self.fun_Recursive(d, amount_list, opening) for d in range(len(amount_list))]
Log.info(dg_value)
else:
# ci_shu = math.ceil(len(amount_list) / 3000)
ci_shu = int(math.ceil(len(amount_list) / 3000)) # 加不加int一样
last_list = [list() for o in range(ci_shu)]
for a in range(ci_shu):
if a == 0:
print(a * 3000, (a+1) * 3000)
new_list = amount_list[a * 3000:(a+1) * 3000]
dg_value_0 = [self.fun_Recursive(i, new_list, opening) for i in range(len(new_list))]
last_list[a].extend(dg_value_0)
else:
print(a * 3000, (a+1) * 3000)
new_list = amount_list[a * 3000:(a+1) * 3000]
dg_value_other = [self.fun_Recursive(i, new_list, last_list[a - 1][-1]) for i in range(len(new_list))]
last_list[a].extend(dg_value_other)
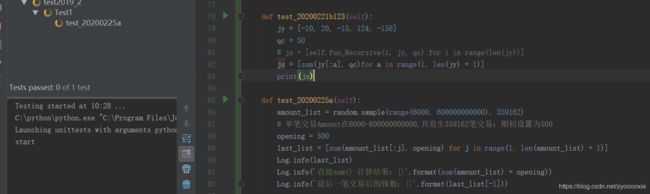
Log.info('每一笔交易后的钱数, 以3000笔为一组, {}'.format(last_list))
Log.info('直接sum() 计算结果:{}'.format(sum(amount_list) + opening))
Log.info('多次递归,最后一组 最后一笔交易后的钱数:{}'.format(last_list[-1][-1]))
计算过程:

最后的结果:
期初设置为500;单笔交易Amount在6000-600000000000,共发生359162笔交易;

这儿是 以3000笔为一组,实际我只想看到balance_list,
def get_balance_list_data(self, amount_list, opening_balance):
import math
import sys
sys.setrecursionlimit(5000)
# Log.info(amount_list)
if len(amount_list) <= 3000: # 将3000作为1次递归的长度
balance_list = [self.fun_recursive(d, amount_list, opening_balance) for d in range(len(amount_list))]
else:
ci_shu = int(math.ceil(len(amount_list) / 3000))
balance_list = list()
for a in range(ci_shu):
if a == 0:
new_list = amount_list[a * 3000:(a + 1) * 3000]
dg_value_0 = [self.fun_recursive(i, new_list, opening_balance) for i in range(len(new_list))]
balance_list.extend(dg_value_0)
else:
# Log.info('计算中。。。')
new_list = amount_list[a * 3000:(a + 1) * 3000]
dg_value_other = [self.fun_recursive(i, new_list, balance_list[-1]) for i in
range(len(new_list))]
balance_list.extend(dg_value_other)
Log.info('迭代结束')
Log.info(balance_list)
sum()
前面递归那一块的代码,最后面我写的是 ‘直接sum() 计算结果:{}’.format(sum(amount_list) + opening),
现在再看下 sum()
result=sum(iterable[, start])
sum() 是返回序列iterable的总和,可选参数start表示从该值开始加起来,默认为0;
换个角度想,sum()来做这个需求是不是更好呢?
【某一笔的交易后的钱数,都是amount_list此元素之前all元素的和 + 期初】

如果跑几十万的amount呢?
出现了数据量太大【将近36w】,迟迟拿不到结果的情况;(可能是我电脑配置不够的原因)
把每次传的amount_list 改动下:
def test_20200225a(self):
amount_list = random.sample(range(6000, 600000000000), 173219)
# 单笔交易Amount在6000-600000000000,共发生173219笔交易;期初设置为500
opening = 500
last_list = list()
if len(amount_list) >= 10000:
cishu = int(math.ceil(len(amount_list) / 10000))
for i in range(cishu):
if i == 0:
print(i * 10000, (i+1) * 10000)
new_list = [sum(amount_list[0: a], opening) for a in range(1, 10001)]
last_list.extend(new_list)
else:
print(i * 10000, (i + 1) * 10000)
new_list = [sum(amount_list[i * 10000: i * 10000 + a], last_list[-1]) for a in range(1, 10001)]
last_list.extend(self.delete_repeat(new_list)) # 删除重复元素
else:
last_list = [sum(amount_list[:a], opening) for a in range(1, len(amount_list) + 1)]
# Log.info(last_list)
# Log.info(len(last_list))
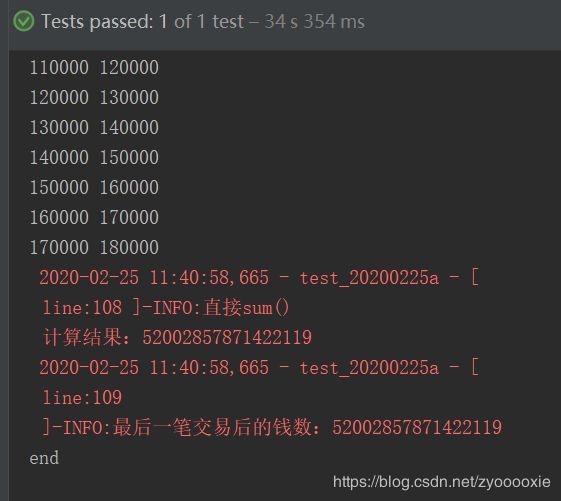
Log.info('直接sum() 计算结果:{}'.format(sum(amount_list) + opening))
Log.info('最后一笔交易后的钱数:{}'.format(last_list[-1]))
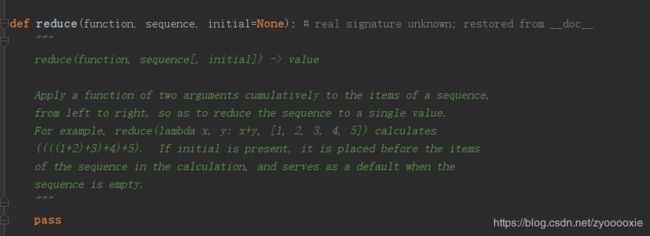
reduce()
reduce() 函数会对参数序列中元素进行累积。
传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果
来尝试下用 reduce()来实现前面的需求。
def get_balance_list(self, amount_list, opening_balance):
from functools import reduce
balance_list = list()
for r in amount_list:
r_index = amount_list.index(r)
amount = amount_list[0:r_index + 1]
# Log.info(amount)
balance = reduce(lambda x, y: x+y, amount, opening_balance)
# Log.info(balance)
balance_list.append(balance)
Log.info(balance_list)
Log.info(balance_list[-1])
实际我用着 算某次结果或最后的结果 reduce()函数 是最快的。但是 所有交易后的 balance_list 就有点慢了。
def test_11a(self):
from functools import reduce
last = reduce(lambda x, y: x + y, range(0, 3000000), 10)
Log.info(last)
但代码真的简洁呀
def get_balance_list_1(self, amount_list, opening_balance):
from functools import reduce
balance_list = [reduce(lambda x, y: x + y, amount_list[0:amount_list.index(a) + 1], opening_balance)for a in amount_list]
Log.info(balance_list)
Log.info(balance_list[-1])
交流技术 欢迎+ QQ\微信 153132336 zy
个人博客 https://blog.csdn.net/zyooooxie