你要知道的Java8 匿名内部类、函数式接口、lambda表达式与Stream API都在这里
转载自:
https://blog.csdn.net/u014205968/article/details/71484312
https://blog.csdn.net/u014205968/article/details/71484374
转载请注明出处 http://blog.csdn.net/u014205968/article/details/71484312
本文主要讲解Java8 Stream API,但是要讲解这一部分需要匿名内部类、lambda表达式以及函数式接口的相关知识,本文将分为两篇文章来讲解上述内容,读者可以按需查阅。
- Java 匿名内部类、lambda表达式与函数式接口
- Java Stream API
本文是该系列博文的第一篇Java 匿名内部类、lambda表达式与函数式接口,主要讲解Java的匿名内部类、lambda表达式以及函数式接口,第二篇文章Java Stream API主要讲解Java Stream API。
匿名内部类
匿名内部类适用于那些只需要使用一次的类,比如设计模式下的命令模式,往往通过定义一系列接口进行调用,有时有的命令只会执行一次就不再执行,这个时候如果单独定义一个类就显得过于复杂并且编译会生成这个类的.class文件,不利于管理,这种情况下使用匿名内部类就能够很好的简化编程并且不会编译生成单独的.class文件。
接下来看一个例子:
interface Programmer
{
void listLanguages();
void introduceMyself();
}
class MyProgrammer implements Programmer
{
public void listLanguages() {
System.out.println("Objective-C Swift Python Go Java");
}
public void introduceMyself() {
System.out.println("My Name is Jiaming Chen");
}
}
public class HelloWorld
{
static void info(Programmer programmer)
{
programmer.listLanguages();
programmer.introduceMyself();
}
public static void main(String[] args)
{
info(new MyProgrammer());
}
}上面这个例子为了执行info函数定义了一个实现了Programmer接口的类MyProgrammer,如果它只执行一次这样就显得过于复杂,如果采用匿名内部类就会在很大程度上简化编程,首先介绍一下匿名内部类的基础语法:
new 需要实现的接口() | 父类构造器()
{
//需要实现的方法或重载父类的方法
}匿名内部类的语法很简单,必须要实现一个接口或者继承一个类,可以看到使用了new关键词,因此在创建匿名内部类的同时会创建一个该类的实例,并且只能创建一个实例,创建完成后这个匿名内部类就不能再使用,因此,匿名内部类不能是抽象类,由于匿名内部类没有类名所以也不能定义构造函数,但是可以在定义匿名内部类的时候调用父类的有参构造器也可以定义初始化块用于初始化父类的成员变量。下面这个栗子是将上述代码修改为匿名内部类的实现方式:
class MyProgrammer implements Programmer
{
public void listLanguages() {
System.out.println("Objective-C Swift Python Go Java");
}
public void introduceMyself() {
System.out.println("My Name is Jiaming Chen");
}
}
public class HelloWorld
{
static void info(Programmer programmer)
{
programmer.listLanguages();
programmer.introduceMyself();
}
public static void main(String[] args)
{
info(new Programmer(){
public void listLanguages() {
System.out.println("Objective-C Swift Python Go Java");
}
public void introduceMyself() {
System.out.println("My Name is Jiaming Chen");
}
});
}
}通过对比发现,使用匿名内部类比重新定义一个新类更加简洁,在创建匿名内部类的时候可以调用父类的有参构造函数,栗子如下:
abstract class Programmer
{
protected String name;
public Programmer(String name)
{
this.name = name;
}
public abstract void listLanguages();
public abstract void introduceMyself();
}
public class HelloWorld
{
static void info(Programmer programmer)
{
programmer.listLanguages();
programmer.introduceMyself();
}
public static void main(String[] args)
{
int age = 22;
Programmer p = new Programmer("Jiaming Chen"){
public void listLanguages()
{
System.out.println("Objective-C Swift Python Go Java");
}
public void introduceMyself()
{
System.out.println("My Name is " + this.name + " and I'm " + age + " years old.");
//age = 2;
}
};
info(p);
//age = 23;
}
}上述栗子首先定义了一个抽象父类,并且该抽象父类只有一个构造函数,因此在创建匿名内部类的时候需要显示调用该构造函数,这样就可以在匿名内部类内部使用父类定义的成员变量了,匿名内部类也可以使用外部变量,在Java8中上述栗子中的age会自动声明为final类型,这称为effectively final,只要匿名内部类访问了一个局部变量,这个局部变量无论是否被final修饰它都会自动被声明为final类型,不允许任何地方进行修改,Java与其他语言相比在闭包内访问外部变量的局限更大,因为只能是final类型,比如OC在block内部也可以捕获外部变量,swift也有一套闭包值捕获机制,都可以对捕获的值进行修改或权限的设置,Java的局限性太大。
lambda表达式
Java8引入了lambda表达式,在其他语言中,比如python、swift都支持lambda表达式,这个特性用起来也非常方便和简洁。接下来举一个常见的对一个列表进行排序的例子:
class MyComparator implements Comparator<String>
{
public int compare(String o1, String o2)
{
return o1.compareTo(o2);
}
}
public class HelloWorld
{
public static void main(String[] args)
{
ArrayList list = new ArrayList<>();
list.add("Objective-C");
list.add("Swift");
list.add("Python");
list.add("Golang");
list.add("Java");
list.sort(new MyComparator());
list.forEach(System.out::println);
/*
输出:(下面的代码的输出结果是一致的,不再赘述)
Golang
Java
Objective-C
Python
Swift
*/
}
} 在开发中经常会对一个集合类型进行排序操作,调用集合的sort方法时需要传入一个实现了Comparator接口的参数,因此上述栗子就定义了一个类MyComparator并且这个类实现了Comparator接口,因此可以创建一个MyComparator的对象用于排序操作,不难发现这样做非常复杂需要重新定义一个全新的类,经过前文的介绍这里完全可以用匿名内部类来代替,关于最后一行代码list.forEach(System.out::println);在后文会介绍,这里先卖个关子,它的作用就是遍历整个集合并输出。接下来看一下使用匿名内部类实现的方式:
public class HelloWorld
{
public static void main(String[] args)
{
ArrayList list = new ArrayList<>();
list.add("Objective-C");
list.add("Swift");
list.add("Python");
list.add("Golang");
list.add("Java");
list.sort(new Comparator(){
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
list.forEach(System.out::println);
}
} 结果同上,显而易见,采用了匿名内部类更加的方便了,代码简洁明了,那有没有再简介一点的办法呢?答案当然是肯定的,那就是使用lambda表达式,栗子如下:
public class HelloWorld
{
public static void main(String[] args)
{
ArrayList list = new ArrayList<>();
list.add("Objective-C");
list.add("Swift");
list.add("Python");
list.add("Golang");
list.add("Java");
list.sort((String o1, String o2)->{
return o1.compareTo(o2);
});
list.forEach(System.out::println);
}
} 通过上述代码发现,sort函数传入的参数是一个lambda表达式,整个代码非常类似前文中我们实现的compare函数,但是我们不需要再写new Comparatorlambda表达式可以很好的替代匿名内部类,不难发现lambda表达式由三部分组成:
- 首先是参数列表,这个参数列表与要实现的方法的参数列表一致,因为系统已经知道了你需要实现哪一个方法因此可以省略形参类型,当只有一个参数时也可以省略圆括号,但是当没有形参时圆括号不可以省略
- 接下来是一个
->符号,该符号用于分隔形参列表与函数体,该符号不允许省略。 - 最后就是代码体了,如果代码体只有一行代码就可以省略掉花括号,并且如果方法需要有返回值连
return关键词都可以省略,系统会自动将这一行代码的结果返回。
通过上面的讲解,我们就可以写一个更加简洁lambda表达式了,栗子如下:
public class HelloWorld
{
public static void main(String[] args)
{
ArrayList list = new ArrayList<>();
list.add("Objective-C");
list.add("Swift");
list.add("Python");
list.add("Golang");
list.add("Java");
list.sort((s1, s2)->s1.compareTo(s2));
list.forEach(System.out::println);
}
} 上面的代码我们省略了形参的类型,由于只有一行我们同时省略了花括号和return语句,整个代码相比使用匿名内部类更加简洁了。到这里有同学可能会问了,lambda表达式是怎么知道我们实现的是接口的哪一个方法?
lambda表达式的类型也被称为目标类型 target type,该类型必须是函数式接口 Functional Interface,函数式接口代表有且只有一个抽象方法,但是可以包含多个默认方法或类方法的接口,因此使用lambda表达式系统一定知道我们实现的接口的哪一个方法,因为实现的接口有且只有一个抽象方法供我们实现。
函数式接口可以使用注释@FunctionalInterface来要求编译器在编译时进行检查,是否只包含一个抽象方法。Java提供了大量的函数式接口这样就能使用lambda表达式简化编程。lambda表达式的目标类型必须是函数式接口,lambda表达式也只能为函数式接口创建对象因为lambda表达式只能实现一个抽象方法。
前文介绍了在使用lambda表达式时,如果代码体只有一行代码可以省略花括号,如果有返回值也可以省略return关键词,不仅如此,lambda表达式在只有一条代码时还可以引用其他方法或构造器并自动调用,可以省略参数传递,代码更加简洁,引用方法的语法需要使用::符号。lambda表达式提供了四种引用方法和构造器的方式:
- 引用对象的方法
类::实例方法 - 引用类方法
类::类方法 - 引用特定对象的方法
特定对象::实例方法 - 引用类的构造器
类::new
举个栗子:
public class HelloWorld
{
public static void main(String[] args)
{
ArrayList list = new ArrayList<>();
list.add("Objective-C");
list.add("Swift");
list.add("Python");
list.add("Golang");
list.add("Java");
//list.sort((s1, s2)->s1.compareTo(s2));
list.sort(String::compareTo);
list.forEach(System.out::println);
}
} 对比上述两行代码,第一个sort函数传入了一个lambda表达式用于实现Comparator接口的compare函数,由于该实现只有一条代码,因此可以省略花括号以及return关键字。第二个sort方法则直接引用了对象的实例方法,语法规则为类::实例方法,系统会自动将函数式接口实现的方法的所有参数中的第一个参数作为调用者,接下来的参数依次传入引用的方法中即自动进行s1.compareTo(s2)的方法调用,明显第二个sort函数调用更加简洁明了。
最后一行代码list.forEach(System.out::println);则引用了类方法,集合类的实例方法forEach接收一个Consumer接口对象,该接口是一个函数式接口,只有一个抽象方法void accept(T t);,因此可以使用lambda表达式进行调用,这里引用System.out的类方法println,引用语法类::类方法,系统会自动将实现的函数式接口方法中的所有参数都传入该类方法并进行自动调用。
再举一个栗子:
@FunctionalInterface
interface Index
{
int index(String subString);
}
@FunctionalInterface
interface Generator
{
String generate();
}
public class HelloWorld
{
static int getIndex(Index t, String subString)
{
return t.index(subString);
}
static String generateString(Generator g)
{
return g.generate();
}
public static void main(String[] args)
{
String str = "Hello World";
System.out.println(getIndex(str::indexOf, "e"));
System.out.println(generateString(String::new).length());
}
}这个栗子似乎没有任何实际意义,就是为了演示引用特定对象的实例方法和引用类的构造器。接口Index和Generator都是函数式接口,因此可以使用lambda表达式。对于getIndex方法需要传入一个实现Index接口的对象和一个子串,在调用时首先定义了一个字符串Hello World,然后引用了这个对象的实例方法indexOf,这个时候系统会自动将这个特定对象作为调用者然后将所有的参数因此传入该实力方法。
引用构造器的方法也很简单类::new,不再赘述。
总结
本文主要讲解匿名内部类、lambda表达式、函数式接口以及lambda表达式的方法引用和构造器引用,通过几个例子逐步深入,逐步简化代码的编写,可以发现Java8提供的lambda表达式是如此的强大。接下来的一篇文章会对Java8新增的Stream API进行讲解,Stream的流式API支持并行,对传统编程方式进行了改进,可以编写出更简洁明了的高性能代码。有兴趣的读者可以阅读Java Stream API。
你要知道的Java8 匿名内部类、函数式接口、lambda表达式与Stream API都在这里
转载请注明出处 http://blog.csdn.net/u014205968/article/details/71484374
本文主要讲解Java8 Stream API,但是要讲解这一部分需要匿名内部类、lambda表达式以及函数式接口的相关知识,本文将分为两篇文章来讲解上述内容,读者可以按需查阅。
- Java 匿名内部类、lambda表达式与函数式接口
- Java Stream API
本文是本系列文章的第二篇,主要讲解Stream API,在学习Stream API之前要求读者有一定的lambda表达式基础,如果相关知识不了解可以参考本系列文章的第一篇Java 匿名内部类、lambda表达式与函数式接口。
Stream API
Java8新增的stream功能非常强大,这里的stream和Java IO中的stream是完全不同概念的两个东西。本文要讲解的stream是能够对集合对象进行各种串行或并发聚集操作,Stream API依赖于前一篇文讲解的 ,只有当两者结合时才能极大的提高编程效率并且代码更易理解和维护。
lambda表达式Stream API支持串行和并发的集合操作,这也是响应了现在多核处理器的需求,Stream API的并发采用的是我们熟悉的fork/join模式,手动编写并行代码很复杂也很容易出错,但是采用Stream API来进行集合对象上的并发操作你不需要编写任何多线程代码就能够轻而易举的实现并发操作,从而提高代码的运行效率,也极大的简化了编程难度。
聚集操作
在实际开发中,我们经常对一个集合内的对象进行一系列的操作,比如排序、查找、过滤、重组、数据统计等操作,通常情况下我们可能会采用for循环遍历的方式来逐一进行操作,这样的代码即复杂又难以维护,如果对性能有要求再进行多线程代码的编写就更加的复杂了,同时也更容易出错。
下面举一个栗子:
class User
{
private String userID;
private boolean isVip;
private int balance;
public User(String userID, boolean isVip, int balance)
{
this.userID = userID;
this.isVip = isVip;
this.balance = balance;
}
public boolean isVip()
{
return this.isVip;
}
public String getUserID()
{
return this.userID;
}
public int getBalance()
{
return this.balance;
}
}
public class HelloWorld
{
public static void main(String[] args)
{
ArrayList users = new ArrayList<>();
users.add(new User("2017001", false, 0));
users.add(new User("2017002", true, 36));
users.add(new User("2017003", false, 98));
users.add(new User("2017004", false, 233));
users.add(new User("2017005", true, 68));
users.add(new User("2017006", true, 599));
users.add(new User("2017007", true, 1023));
users.add(new User("2017008", false, 9));
users.add(new User("2017009", false, 66));
users.add(new User("2017010", false, 88));
//普通实现方式
ArrayList tempArray = new ArrayList<>();
ArrayList idArray = new ArrayList<>(3);
for (User user: users)
{
if (user.isVip())
{
tempArray.add(user);
}
}
tempArray.sort(new Comparator(){
public int compare(User o1, User o2) {
return o2.getBalance() - o1.getBalance();
}
});
for (int i = 0; i < 3; i++)
{
idArray.add(tempArray.get(i).getUserID());
}
for (int i = 0; i < idArray.size(); i++)
{
System.out.println(idArray.get(i));
}
//Stream API实现方式
//也可以使用parallelStream方法获取一个并发的stream,提高计算效率
Stream stream = users.stream();
List array = stream.filter(User::isVip).sorted((t1, t2) -> t2.getBalance() - t1.getBalance()).limit(3).map(User::getUserID).collect(Collectors.toList());
array.forEach(System.out::println);
}
} 上述代码首先定义了一个用户类,这个类保存用户是否是VIP、用户ID以及用户的余额,假如现在有一个需求,将VIP中余额最高的三个用户的ID找出来,传统的思路一般就是创建一个临时的list,然后逐一判断,将所有的VIP用户加入到这个临时的list中,然后调用集合类的sort方法根据余额排序,最后再遍历三次获取余额最高的三个用户的ID等信息。这样的方法看似简单,但代码写出来即混乱也不好看,如果用户量非常大,有几千万甚至几个亿,这样遍历的方式效率就会特别低,如果手工加上多线程的并发操作,代码就更加复杂了。
上述代码的第二部分使用Stream API的方式来计算,首先通过集合类获取了一个普通的stream,如果数据量大可以使用parallelStream方法获取一个并发的stream,这样接下来的计算程序员不需要编写任何多线程代码系统会自动进行多线程计算。获取了stream以后首先调用filter方法找到是否为VIP用户然后对VIP用户进行排序操作,接下来限制只获取三个用户的信息,然后将用户映射为用户ID,最后将该stream转换为集合类,两种实现方式的结果完全一样,但是明显的采用Stream API的代码更加简洁易懂。
Stream API的编写大量依赖lambda表达式以及lambda表达式的引用方法和引用构造器,如果您对这一块不理解可以查阅文章Java 匿名内部类、lambda表达式与函数式接口。
如何使用Stream
A sequence of elements supporting sequential and parallel aggregate operations- 1
上面是Java文档中定义的Stream,可以看出,Stream就是元素的集合,并且可以采用串行或并行的方式进行聚集操作。在使用时我们可以将Stream理解为一个迭代器,只不过这个迭代器更加高级,能够对其中的每一个元素进行我们规定的计算。
当我们要使用Stream API时,首先需要创建一个Stream对象,可以通过集合类的实例方法stream或parallelStream来获取一个普通的串行stream或是并行stream。也可以使用Stream、IntStream、LongStream或DoubleStream创建一个Stream对象,Stream是一个比较通用的流,可以代表任何引用数据类型,其他的则是指特定类型的流。最常用的就是通过一个集合类型来获取相应类型的Stream。
流的操作分为中间操作 Intermediate和结束操作 Terminal:
- 中间操作(Intermediate):一个流可以采用链式调用的方式进行数个中间操作,主要目的就是打开流然后对这个流进行各种过滤、映射、聚集、统计操作等,如上述代码中的
filter、map操作等。每一个操作结束后都会返回一个新的流,并且这些操作都是lazy的,也就是在进行结束操作时才会真正的进行计算,一次遍历就计算出所有结果。 - 结束操作(Terminal):一个流只能执行一个结束操作,当执行了结束操作以后这个流就不能再被执行,也就是说不能再次进行中间操作或结束操作,所以结束操作一定是流的最后一个操作,如上述代码中的
collect方法。当开始执行结束操作的时候才会对流进行遍历并且只一次遍历就计算出所有结果。
Stream的创建
- 通过集合类创建
通过集合创建Stream的方法是我们最常用的,集合类的实例方法stream和parallelStream可以获取相应的流。
ArrayList users = new ArrayList<>();
users.add(new User("2017001", false, 0));
users.add(new User("2017002", true, 36));
users.add(new User("2017003", false, 98));
Stream stream = users.stream(); - 通过数组构造
String[] str = {"Hello World", "Jiaming Chen", "Zhouhang Cheng"};
Stream stream = Stream.of(str); - 通过单个元素构造
Stream<Integer> stream = Stream.of(1, 2, 3, 4);- Stream与Array和Collection的转换
一般我们都会对Stream进行结束操作,用于获取一个数组或是集合类,通过数组和集合类创建Stream前文已经介绍了,这里介绍通过Stream获取数组或集合类。
String[] str = {"Hello World", "Jiaming Chen", "Zhouhang Cheng"};
Stream<String> stream = Stream.of(str);
String[] strArray = stream.toArray(String[]::new);
List<String> strList = stream.collect(Collectors.toList());
ArrayList<String> strArrayList = stream.collect(Collectors.toCollection(ArrayList::new));
Set<String> strSet = stream.collect(Collectors.toSet());上面的代码分别将流转换为数组、List、ArrayList和Set类型,具体的参数可以查看官方API文档。
Stream 常用方法
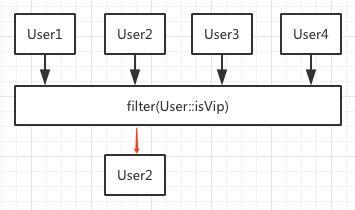
- filter
filter的栗子前面已经举过了,filter函数需要传入一个实现Predicate函数式接口的对象,该接口的抽象方法test接收一个参数并返回一个boolean值,为true则保留,false则剔除,前文举的栗子就是判断是否为VIP用户,如果是就保留,不是就剔除。
原理如图所示:
- map、flatMap
map的栗子前面已经举过了,map函数需要传入一个实现Function函数式接口的对象,该接口的抽象方法apply接收一个参数并返回一个值,可以理解为映射关系,前文举的栗子就是将每一个用户映射为一个userID。
原理如图所示:
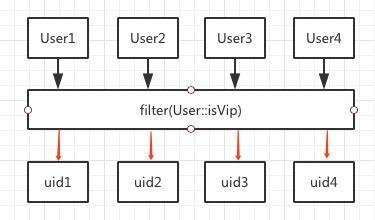
map方法是一个一对一的映射,每输入一个数据也只会输出一个值。 flatMap方法是一对多的映射,对每一个元素映射出来的仍旧是一个Stream,然后会将这个子Stream的元素映射到父集合中,栗子如下:
Stream> inputStream = Stream.of(Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6));
List integerList = inputStream.flatMap((childList) -> childList.stream()).collect(Collectors.toList());
//将一个“二维数组”flat为“一维数组”
integerList.forEach(System.out::println); - limit、skip
limit用于限制获取多少个结果,与数据库中的limit作用类似,skip用于排除前多少个结果。
- sorted
sorted的栗子前面也举过了,sorted函数需要传入一个实现Comparator函数式接口的对象,该接口的抽象方法compare接收两个参数并返回一个整型值,作用就是排序,与其他常见排序方法一致。
- distinct
distinct用于剔除重复,与数据库中的distinct用法一致。
- findFirst
findFirst方法总是返回第一个元素,如果没有则返回空,它的返回值类型是Optional类型,接触过swift的同学应该知道,这是一个可选类型,如果有第一个元素则Optional类型中保存的有值,如果没有第一个元素则该类型为空。
Stream stream = users.stream();
Optional userID = stream.filter(User::isVip).sorted((t1, t2) -> t2.getBalance() - t1.getBalance()).limit(3).map(User::getUserID).findFirst();
userID.ifPresent(uid -> System.out.println("Exists")); - min、max
min可以对整型流求最小值,返回OptionalInt。 max可以对整型流求最大值,返回OptionalInt。
这两个方法是结束操作,只能调用一次。
- allMatch、anyMatch、noneMatch
allMatch:Stream中全部元素符合传入的predicate返回 true
anyMatch:Stream中只要有一个元素符合传入的predicate返回 true
noneMatch:Stream中没有一个元素符合传入的predicate返回 true
- reduce
reduce方法用于组合Stream元素,它可以提供一个初始值然后按照传入的计算规则依次和Stream中的元素进行计算,因此上文介绍的min、max都可以看做是reduce的一种实现。
举个栗子:
IntStream is = IntStream.range(0, 10);
System.out.println(is.reduce(0, Integer::sum));
IntStream intStream = IntStream.range(0, 10);
System.out.println(intStream.reduce((o1, o2) -> o1 + o2));
Stream stream = Stream.of("Hello", "World", "Jiaming", "Chen");
System.out.println(stream.reduce("", String::concat)); 第一个IntStream调用的reduce方法设置了一个初始值,因此最终reduce计算的结果一定有值,该方法调用Integer的类方法sum用于计算Stream的总和。
第二个IntStream调用reduce方法时没有设置初始值,因此最终reduce计算的结果不一定有值,所以返回值类型是Optional类型,没有提供初始值时会自动将第一个和第二个元素先进行计算,但有可能不存在第一个或第二个元素,因此返回值是Optional类型。
Stream API的性能
这篇文章详细测试了Stream API的性能Java Stream API性能测试。
总的来说,对于复杂计算并且拥有多核CPU来说,使用Stream API进行并发计算速度最快,也推荐使用。对于计算比较简单,手工外部迭代性能更加。单核CPU尽量不要使用并发的Stream API计算。如果没有太高的性能要求,想要编写出简洁的代码还是推荐使用Stream API。