flink实战教程-集群的部署
文章目录
- MiniCluster
- Standalone
- yarn
- yarn session
- yarn per job
- application模式
- k8s
- 其他
MiniCluster
这种模式我们一般是在用IDE调试程序的时候用到,当我们在本地用IDE开发程序的时候,执行main方法,flink会在本地启动一个包含jobmanager和taskmanager的进程的minicluster,程序运行完成之后,这个cluster进程退出。
Standalone
这种模式就是直接在物理机上启动flink集群。我们可以通过 F L I N K H O M E / b i n / s t a r t − c l u s t e r . s h 命 令 启 动 带 有 一 个 j o b m a n a g e r 和 一 个 t a s k m a n a g e r 的 集 群 , 此 时 使 用 的 f l i n k 的 配 置 是 {FLINK_HOME}/bin/start-cluster.sh 命令 启动带有一个jobmanager和一个taskmanager的集群,此时使用的flink的配置是 FLINKHOME/bin/start−cluster.sh命令启动带有一个jobmanager和一个taskmanager的集群,此时使用的flink的配置是{FLINK_HOME}/conf/flink-conf.yaml.
此外,我们可以用 ${FLINK_HOME}/bin/taskmanager.sh start 再启动一个taskmanager。
这时我们通过jps命令查看一下启动的进程
76085 StandaloneSessionClusterEntrypoint
76331 TaskManagerRunner
76846 TaskManagerRunner
我们看到这时候启动了两个taskmanager

这种部署模式对flink集群的资源管理是flink自己维护的,在生产环境下用的不多,所以我们也不做过多描述.
yarn
yarn session
- 部署在yarn集群上的flink集群都是把资源的管理交给了yarn来管理。
- yarn session的部署模式就是先预先在yarn集群上启动一个flink集群,我们可以把我们写好的flink任务直接提到这个集群上。
启动集群的命令如下:
${FLINK_HOME}/bin/yarn-session.sh
这个命令有很多的参数,可以在后面加 -h 看下,我这里着重介绍一下 -d参数。
加上-d之后,指的是隔离模式,也就是启动之后和客户端就断了联系,如果要停止集群,需要通过yarn application -kill {applicationId} 来停止集群.
-
如果没指定-d,这种情况集群会和客户端一直保持着连接,客户端退出之后,集群也会退出。
-
提交任务
往yarn session集群提交任务,只需要在相应的客户端机器上,通过${FLINK_HOME}/bin/flink run -d user.jar 这样的命令就可以提交到session集群.此外我们还可以通过web ui最后一项来提交任务

-
这种session模式一般适用于批任务,也就是执行一段时间以后可以终止的任务,因为对于这种短时间执行的任务,可以避免在申请资源方面浪费过多时间。
-
集群启动之后,是没有给flink集群分配资源的,当提交任务之后,yarn集群会根据请求再给任务分配资源,任务执行完成之后,系统隔一段时间会释放相应的资源.(这个时间是可配置的,为了防止马上有任务又来了,重新申请资源)
yarn per job
-
我们上面讲了session模式部署集群,这种模式可以在一个集群里跑很多的任务,这些任务共享了flink集群的资源,隔离性做的不是很好,所以flink还提供了另外一种执行模式:yarn per job模式。
-
这种模式会在yarn上为每个flink任务都建立一个单独的集群,优势就是每个任务单独的进行资源管理,和其他任务资源隔离。这种模式适用于对启动时间不太敏感,需要长时间运行的流任务。
-
启动命令
${FLINK_HOME}/bin/flink run -d -p 4 -ys 2 -m yarn-cluster -c com.example.Test userjar.jar arg1 arg2
提交成功之后,我们会在yarn的管理页面看到一个类似的任务
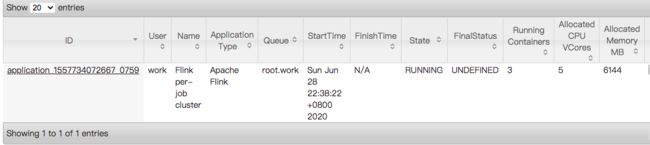
这个启动命令也有很多的参数,我就不一一讲解了,我用大白话讲讲我认为最核心的几个参数。
- -d 采用分离模式
- -p 程序的并行度
- -ys 每个taskmanager有几个slot,我们可以简单的理解为flink会把taskmanager的内存分成几份,在某些条件下,程序可以共用slot,提高效率,至于slot的概念,我们后续再讲,今天就不多说了。用并行度除以这个值,然后就会得到flink会启动几个taskmanager
,所以为了避免有多余的slot,我们最好设置并行度除以这个ys值能整除。 - -c 程序的入口类,我们可以在程序打包的时候指定入口类,如果没有指定或者程序中有很多类,我们就需要通过这个-c参数来指定入口类了。
- 在命令行最后的参数是用户jar包的参数.
- 停止命令
第一,我们可以在flink的页面上通过停止flink的任务来停止集群,在我们停止了flink任务之后,yarn会自动释放相应的资源。

第二,通过命令行来停止:
${FLINK_HOME}/bin/flink stop -m yarn-cluster -yid application_1592386606716_0005 c8ee546129e8480809ee62a4ce7dd91d
这个时候需要指定yarn applicationId和flink job id
第三,通过程序来停止
https://blog.csdn.net/zhangjun5965/article/details/106820591
如果我们做了一个实时平台这样的系统,就不能手工通过命令行来停止了,可以调用相应的api来停止任务.
- 启动流程
当我们执行完相应的命令之后,系统会把flink的jar、相关的配置文件、用户的jar都上传到hdfs
的一个临时目录,默认是/user/{USER}/.flink/{applicationId},
然后再构建flink集群的时候,再去找个目录去获取,程序部署成功之后,删除相应的临时目录
application模式
这种模式是在flink 1.11 版本中提供的,flink的yarn per job模式启动的时候会把本地的flink的jar和用户的jar都上传到hdfs,这个过程非常的消耗网络的带宽,如果同时有多个人提交任务的话,那么对网络的影响就更大,此外,每次提交任务的时候flink的jar包是一样的,也不用每次都拷来拷去的,所以flink提供了一种新的application模式,可以把flink的jar和用户的jar都预先放到hdfs上,这样就能省去yarn per job模式提交任务的jar包拷贝工作,节省了带宽,加快了提交任务的速度.
具体的命令如下:
./bin/flink run-application -p 1 -d -t yarn-application \
-yD yarn.provided.lib.dirs="hdfs://localhost/data/flink/libs/" \
hdfs://localhost/data/flink/user-lib/TopSpeedWindowing.jar
-yD yarn.provided.lib.dirs :用来指定存放flink jar的目录
最后一个参数是用户的jar在hdfs上的路径.
说一下题外话,其实我们当时在做实时平台的时候,这个提交慢的问题我也发现了,当时我的想法是先启动一个flink集群,然后再把程序的JobGraph提交到这个yarn集群,不过后来嘛,由于 *%%$$#^& 的原因,也没弄.
k8s
对于把服务容器化,也越来越成为一种趋势,所以k8s部署也越来越受大家的重视。 对于k8s部署flink这块说实话我研究的不是很深,也就不多说了。
其他
我们还可以将程序部署到mesos或者使用docker,这个我没有去实际调研过,但是从flink的邮件列表大家沟通的问题或者是网上查到的资料看,这种模式部署应该不多,所以这里就不详细描述了。
欢迎关注我的公众号【大数据技术与应用实战】,获取更多大数据实战案例.
