python破解滑块验证码
目录
前言
验证码样本
破解思路
完整代码如下:
运行截图
截屏异常修正
模拟人拖到路径优化
拖动距离优化
前言
这里所讲述的技能借鉴了崔庆才《python3网络爬虫开发一书》,但又有些许不同,因为爬虫具有时效性,感谢崔提供的技术指导。
验证码样本
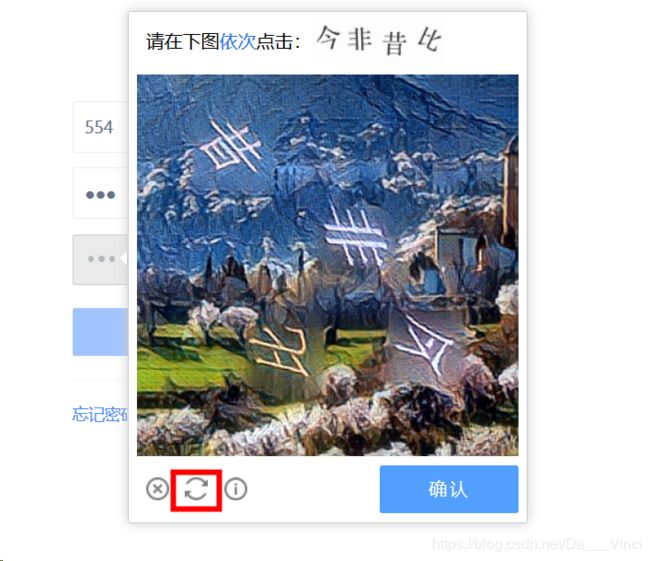
本次实验的对象是极验验证,连接如下 https://account.geetest.com/login

极验验证点击按钮,就会有一点概率进入验证码,这个按钮也是智能的,原理不甚了解,如果能一次性进去更好,不过我们的目的就是破解验证码吗,点击中间那里,进入概率大一些。如果出现的是文字验证码,那么连续点击下面的刷新即可。一般代码模拟点击会一次性出现滑块验证码。


破解思路
第一步:使用selenium加载,输入账号,密码,点击验证,出现滑块验证码。
第二步:我们人眼可以直接找到缺口,但这个过程是复杂的,大致如下,看到图片--看到滑块--看到缺口--寻找按钮--拖动按钮--刚刚开始快速逼近--接近时减速逼近--划过了可以左右调整。事实上人脑是在不断计算的,人眼的信号传输是非连续的,这个过程是一个高速的调整逼近过程,只不过我们司空见惯而已。
电脑就不一样的,电脑没有人眼这样的传感器,也不能动态调整,只能按照规定的计划执行任务。
说回来,这个验证码本身时有两张图片的,我们滑动滑块,最后两张图片做对比,相似度大于某个阈值,即可通过,所以我们非常需要获得这两张图片,然后找出缺口的位置。
第三步:获得两张图片,进入浏览器开发者模式,查看验证码元素。我们可以看到这是一个画布元素,那么可以通过截图来获取图片。但问题是只有一张图片,不急,我们看查看器,不难看到有三个canvas元素,重叠在一起了。前面两个是显示的,第三个隐藏了,那么前两个就是这个滑块和带缺口的图片了,第三个就是完整图片。依次设置前面两个隐藏,第三个显示即可

右键第一个canvas,添加属性style="display: none; opacity: 1;",可以看到消失的是缺口图片,所以第一个canvas就是缺口图片
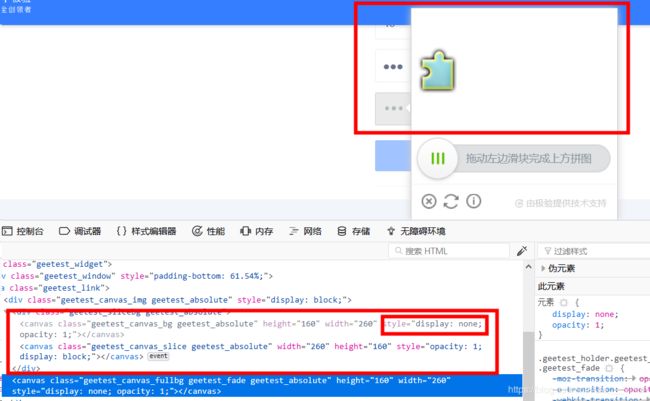
递推,隐藏第二个canvas,滑块消失了。
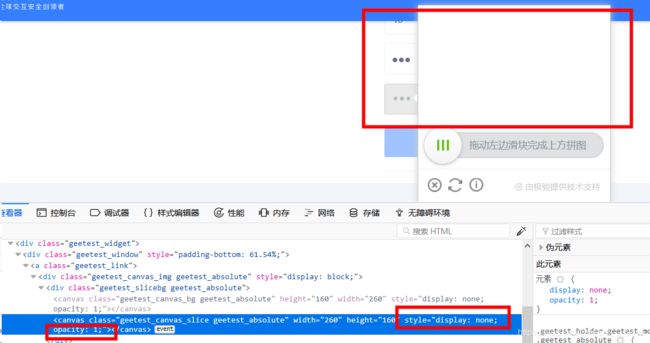
继续,删除第三个canvas的style属性,直接双击backspace即可,就此三个canvas身份确认。
第四步:我们要获得两张截图并将一切还原,顺序如下:
- 隐藏滑块
- 对canvas对象截图,获得缺口图片
- 隐藏缺口图片
- 显示完整图片
- 对canvas对象截图,获得完整图片
- 隐藏完整图片
- 显示缺口图片
- 显示滑块
第五步:对比两张图片的像素值,找出差距过大的位置,这里选择的是60,然后校准滑块和缺口间距离
第六步:拖动滑块完成验证,失败再次尝试。
完整代码如下:
import time
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
class SVC:
def __init__(self):
self.url = 'https://account.geetest.com/login'
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driverwait = WebDriverWait(self.driver, 20)
self.email = 'EMAIL'
self.password = 'PASSWORD'
self.location = {}
self.size = {'width':260,'height':160}
self.BORDER = 40
def __del__(self):
self.driver.close()
def setAttribute(self,elementObj, attributeName, value):
# 封装设置页面对象的属性值的方法
# 调用JavaScript代码修改页面元素的属性值,arguments[0]-[2]分别会用后面的
# element、attributeName和value参数值进行替换,并执行该JavaScript代码
self.driver.execute_script("arguments[0].setAttribute (arguments[1],arguments[2])", elementObj, attributeName, value)
def removeAttribute(self, elementObj, attributeName):
# 封装删除页面元素属性的方法
# 调用JavaScript代码删除页面元素的指定的属性,arguments[0]-[1]分别会用后面的
# element、attributeName参数值进行替换,并执行该JavaScript代码
self.driver.execute_script("arguments[0].removeAttribute(arguments[1])", elementObj, attributeName)
def get_geetest_button(self):
"""
获取初始验证按钮
:return:
"""
#button = self.driver.find_element_by_xpath('//*[@id="captcha"]/div/div[2]/div[1]/div[3]')
button = self.driverwait.until(EC.element_to_be_clickable((By.CLASS_NAME,'geetest_radar_tip')))
return button
def get_slider(self):
"""
获取滑块
:return: 滑块对象
"""
slider = self.driverwait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'geetest_slider_button')))
return slider
def open(self):
"""
打开网页输入用户名密码
:return: None
"""
self.driver.get(self.url)
email = self.driver.find_element_by_xpath('//*[@id="email"]')
password = self.driver.find_element_by_xpath('//*[@id="password"]')
#email = self.driverwait.until(EC.presence_of_element_located((By.ID, 'email')))
#password = self.driverwait.until(EC.presence_of_element_located((By.ID, 'password')))
email.send_keys(self.email)
password.send_keys(self.password)
def get_screenshot(self):
"""
获取网页截图
:return: 截图对象
"""
screenshot = self.driver.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_geetest_image(self, name):
"""
获取验证码图片 captcha.png
:return: 图片对象
"""
left, top, right, bottom = (self.location['x']+177,self.location['y']+44,self.location['x']+self.size['width']+235,self.location['y']+self.size['height']+80)
print('验证码位置', left, top, right, bottom)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
def getImg(self):
time.sleep(3)
ele = self.driver.find_elements_by_tag_name('canvas')
self.location = ele[0].location
self.setAttribute(ele[1],'style','display: none;') #移除小方框
self.get_geetest_image('captcha_up.png')
self.setAttribute(ele[0],'style','display: none;') #移除上面图片
self.removeAttribute(ele[2],'style') #移除隐藏属性以显示地面图片
self.get_geetest_image('captcha_down.png')
self.removeAttribute(ele[0], 'style')
time.sleep(0.5)
self.removeAttribute(ele[1], 'style')
time.sleep(0.5)
self.setAttribute(ele[2], 'style', 'display: none;')
def get_gap(self, image1,image2):
"""
获取缺口偏移量
:param image1: 不带缺口图片
:param image2: 带缺口图片
:return:
"""
left = 0
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
def is_pixel_equal(self, image1, image2, x, y):
"""
判断两个像素是否相同
:param image1: 图片1
:param image2: 图片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取两个图片的像素点
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
print(pixel1, pixel2)
return False
def get_track(self, distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
list1 = []
list2 = []
list3 = []
# 当前位移
for i in range(round(distance/4)):
list1.append(1)
list2.append(2)
list2.append(1)
return list1+list2
def move_to_gap(self, slider, track):
"""
拖动滑块到缺口处
:param slider: 滑块
:param track: 轨迹
:return:
"""
ActionChains(self.driver).click_and_hold(slider).perform()
for x in track:
ActionChains(self.driver).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(self.driver).release().perform()
def start(self):
# 输入用户名密码
self.open()
# 点击验证按钮
button = self.get_geetest_button()
button.click()
def crack(self):
self.getImg()
Image2 = Image.open('captcha_down.png')
Image1 = Image.open('captcha_up.png')
gap = self.get_gap(Image1, Image2)
print('缺口位置', gap)
# 减去缺口位移
if gap<45:
gap -= 5
elif gap<55:
gap -= 15
elif gap<125:
gap -= 25
elif gap<165:
gap -= 35
elif gap <185:
gap -= 40
else:
gap -= 45
track = self.get_track(gap)
print('滑动轨迹', track)
slider = self.get_slider()
self.move_to_gap(slider, track)
time.sleep(1)
success = False
try:
success = self.driverwait.until(EC.text_to_be_present_in_element((By.CLASS_NAME, 'geetest_success_radar_tip_content'), '验证成功'))
except:
print('失败')
# 失败后重试
if not success:
time.sleep(0.1)
self.crack()
else:
print('成功')
self.login()
def login(self):
"""
登录
:return: None
"""
submit = self.driverwait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'login-btn')))
submit.click()
print('登录成功')
if __name__ == '__main__':
svc = SVC()
svc.start()
svc.crack()
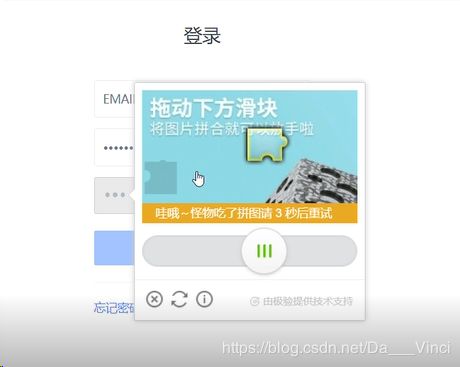
运行截图


截屏异常修正
最开始,我是按照书上的方法,先获取canvas的坐标Z(x,y),然后截取z(x,y)到m(x+宽,y+高)的屏幕截图,但是浏览器不知道发了什么疯,截到的图片都是像下面的图片那样,后来我以为坐标位置有误,亲自安装了坐标插件,将图片的左上角坐标替换Z,得到的结果依旧和下面一样,索性手动修正,试了好久最终确定可通过如下坐标获得完整截图。
点(z['x']+177 , z['y']+44)到点(z['x']+width+235 , z['y']+height+80) 即可获得完整截图。



模拟人拖到路径优化
在原书在作者说明,如果匀速,匀加速,匀减速拖动,都不能通过,这个我也试过,但是拿到代码,总是有一些偏差,不能准确对其,作者使用了物理模型,先加速后减速就能通过,代码如下。在最后那里使用了track.append(round(move))添加位移路径,
def get_track(self, distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track但是有一个问题,当你的move较小时,就会变成0,move较大,就会变成1,积累下来,就会难以对其,所以我换了一种简易算法。将路径分为四分,第一份和最后一份以1像素速度拖动,中间以2像素速度拖动。亦能模仿先加速后减速。
def get_track(self, distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
list1 = []
list2 = []
list3 = []
# 当前位移
for i in range(round(distance/4)):
list1.append(1)
list2.append(2)
list3.append(1)
return list1+list2+list3拖动距离优化
先前截图失败,就觉得这次破解不会太顺利,拖动验证码,距离短的会不到位,距离远的又会超出,所以在最后计算距离时,再次手动修订了一次,下面的判断点,都是正好镶嵌的点。
if gap<45:
gap -= 5
elif gap<55:
gap -= 15
elif gap<125:
gap -= 25
elif gap<165:
gap -= 35
elif gap <185:
gap -= 40
else:
gap -= 45