论文浅尝 - WSDM20 | 基于弱监督及逐步推理的多关系知识图谱问答
论文笔记整理:刘晓臻,东南大学计算机科学与工程学院本科生。

来源:WSDM ’20
链接:https://dl.acm.org/doi/abs/10.1145/3336191.3371812
动机
知识图谱问答(KG-QA)系统大多包含两个步骤:链接问题中的topic entity到KG,然后识别问题所指的在KG中的最相关的关系。根据获取答案所需的KG三元组的数量,可以将自然语言问题分成单一关系问题和多关系问题两种。
现有的KG-QA方法可以分成两个主流的分支。
第一种主要致力于学习一个能够将非结构化的问题转换为结构化表示的语义解析器(Semantic Parser, SP),其中传统的基于SP的方法利用诸如SPARQL、λ-DCS和λ-calculus之类的逻辑形式,但这就要求用户熟悉这些逻辑形式的语法和后台数据结构,而且预测所得的结构和和KG的结构之间存在的不匹配的情况也会限制模型的表现。因此最近的研究使用query graph来表示问题的语义结构,这样可以取得较好的结果,但以人工标注成本作为代价,因此难以用于其它领域,且依赖于成熟的NLPpipelines,会有错误的叠加。
另外一个分支的方法利用以topic entity为中心的子图获取候选答案,且将问题和每个候选子图编码为同一个嵌入空间的语义向量,利用嵌入相似度排序,其中神经网络可以较好地用以表示问题和KG成分。这一类方法可以端到端地训练,且有泛化到其他领域的可能,但在多关系问题上表现不是很好。
因此,对于后一类方法,最近的研究工作致力于提高多关系问题上的推理能力。然而还有以下几个挑战:(1) 时间复杂度过高,因为现有的方法对于每个问题都需要用到整个以topic entity为中心的子图,使得候选答案个数以指数级上升。(2) 语义信息太复杂,因为多关系问题中的每一个部分都对三元组选择有各自的影响,故需要在不同步骤里关注问题中的不同部分,而许多现有的方法没有对多关系问题作更进一步的分析,因此表现很差。(3) 需要使用弱监督来训练,因为一步步地分析到底如何回答一个多关系问题是不现实的,这需要大量的数据标注。实际的标注只有最终的答案,因此是弱监督的。有些工作使用外部知识(如Wikipediafree text)来丰富分布式表示,但这种操作不适用于没有外部知识的某些特定领域。
针对以上挑战,本文提出了一个基于强化学习的神经网络模型“Stepwise Reasoning Network (SRN)”。贡献如下:
(1) 针对第一个挑战,SRN将多关系问题的回答形式化为一个顺序决策问题,通过学习一个从topic entity开始,在KG中执行路径搜索的策略来得到一个自然语言问题的答案,并使用beam search在每一步获取三元组列表,因此可以不考虑整个以topic entity为中心的子图,进而显著减少对于一个问题的候选答案。
(2) 针对第二个挑战,SRN使用注意力机制决定当前关注哪一个部分以获取问题中不同部分的独特的信息,在每一步使用对应的单层感知机以强调三元组选择的顺序,使用GRU网络来编码决策历史。
(3) SRN使用REINFORCE算法进行端到端训练。针对第三个挑战,特别是在弱监督、多关系问题的情况下存在的一系列问题,SRN使用基于potential 的reward shaping方法来为agent提供额外的rewards,该方法不会使得agent偏离真正的目标,也不需要外部知识。
(4) 通过实验证明了方法的有效性,在3个benchmark数据集上进行了ablationstudy。
方法
1.任务定义
一个KG由G= (E, R)表示,E为实体集合,R为关系集合;KG中每个三元组(es, r, eo)都代表了现实生活中的一个基本事实。对于一个自然语言问题q,一个KG-QA模型返回事实性答案,答案包含存储在KG中的三元组,对于许多复杂问题,要求不止一个三元组。
2.强化学习形式化
强化学习常被形式化为一个马尔可夫决策过程(Markov decision process, MDP)。本文将MDP视为从交互中学习到回答基于KG的自然语言问题。如图1,agent是学习者,也是决策者,在一个离散时间决策步骤序列中的每一步,agent和除它之外的一切(环境)交互。
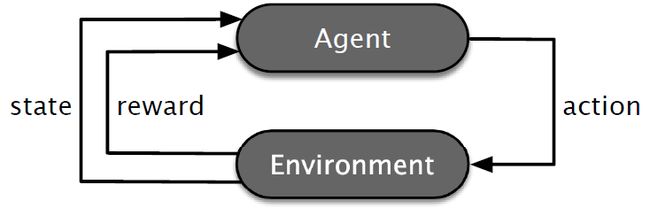
图 1
具体地,一个MDP定义为一个元组(S, A, p, R),S为状态空间,A为行动空间,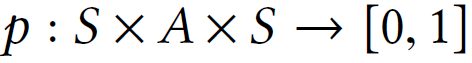 为状态转换概率,
为状态转换概率,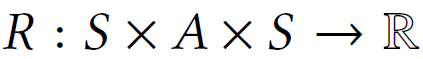 为奖励函数。在每个时间步t,agent观察环境的状态St ∈ S,然后选择一个行动At ∈ A(St)。作为结果,环境转换到一个新的状态St+1,概率为
为奖励函数。在每个时间步t,agent观察环境的状态St ∈ S,然后选择一个行动At ∈ A(St)。作为结果,环境转换到一个新的状态St+1,概率为![]() ,然后根据奖励函数
,然后根据奖励函数![]() ,agent会获得一个数值上的奖励。整个过程如图1。具体到本任务,则有以下定义:对于状态,
,agent会获得一个数值上的奖励。整个过程如图1。具体到本任务,则有以下定义:对于状态,![]() 中,q为问题,es是topic entity,et是从es搜索路径过程中,在时间步t时所访问的实体,ht则为agent之前所做的决策的集合。t时的候选行动集合基于St, A(St)由G中所有et的出边构成,即
中,q为问题,es是topic entity,et是从es搜索路径过程中,在时间步t时所访问的实体,ht则为agent之前所做的决策的集合。t时的候选行动集合基于St, A(St)由G中所有et的出边构成,即![]() 。另外,由于回答一个问题所需的三元组数量未知,故在中A(St)加入一个自环边,表示终止行动,agent在此进入终止状态。对于状态转换,一旦agent选择了行动
。另外,由于回答一个问题所需的三元组数量未知,故在中A(St)加入一个自环边,表示终止行动,agent在此进入终止状态。对于状态转换,一旦agent选择了行动![]() ,状态就变换成
,状态就变换成![]() ,其中
,其中![]() 。最后,奖励是环境传给agent的特殊信号,是agent的目的的形式化表现,在episodic RL任务中,agent在每个时间步都会获得一个奖励,agent的目标就是最大化其所获得的奖励。但由于本文使用的是弱监督,agent只有在得到最终的正确的答案节点时才能获得一个正值终止奖励(通常为1),此时可以视之前的每个决策为正确的,让它们也获得一个正值奖励。但这样会导致奖励延后且稀疏,阻碍训练的收敛。本文利用一个potential 函数来减轻这一问题,后面会详细说明。
。最后,奖励是环境传给agent的特殊信号,是agent的目的的形式化表现,在episodic RL任务中,agent在每个时间步都会获得一个奖励,agent的目标就是最大化其所获得的奖励。但由于本文使用的是弱监督,agent只有在得到最终的正确的答案节点时才能获得一个正值终止奖励(通常为1),此时可以视之前的每个决策为正确的,让它们也获得一个正值奖励。但这样会导致奖励延后且稀疏,阻碍训练的收敛。本文利用一个potential 函数来减轻这一问题,后面会详细说明。
3.策略网络(Policy Network)
本文使用深度神经网络参数化搜索策略,以求解上述的有限MDP。一个参数化的策略π以每一步的状态信息为输入,输出在候选行动上的概率分布,即![]() ,
,![]() 。本文使用双向GRU网络来将q转换为向量,并在每个时间步使用单层感知机转换向量,以将问题中的不同部分用不同步骤来区分。使用注意力机制来让表示中能包含关系信息。最终,概率分布基于包含了关系嵌入、能够感知到关系的问题表示和所编码的决策历史的语义得分。
。本文使用双向GRU网络来将q转换为向量,并在每个时间步使用单层感知机转换向量,以将问题中的不同部分用不同步骤来区分。使用注意力机制来让表示中能包含关系信息。最终,概率分布基于包含了关系嵌入、能够感知到关系的问题表示和所编码的决策历史的语义得分。
具体地,对于一个长度为n个词的问题![]() ,使用密集词嵌入初始化每个词
,使用密集词嵌入初始化每个词![]() ,并将q中的topicentity的提及用token“<< span="">e>”替换,并且预先使用一个topic entity linker标注好此提及。之后,将这一串词嵌入输入一个双向GRU网络并得到一系列d维输出状态
,并将q中的topicentity的提及用token“<< span="">e>”替换,并且预先使用一个topic entity linker标注好此提及。之后,将这一串词嵌入输入一个双向GRU网络并得到一系列d维输出状态![]() ,
,![]() ,其中每个wi由正向和反向两个GRU分别的的d/2维输出拼接得到。在每个时间步t,q通过学习到的单层感知机转换成一个能感知到步骤的表示
,其中每个wi由正向和反向两个GRU分别的的d/2维输出拼接得到。在每个时间步t,q通过学习到的单层感知机转换成一个能感知到步骤的表示![]() ,
,![]() 。进一步地,通过将前一步决策所得的关系输入一个GRU网络来编码决策历史
。进一步地,通过将前一步决策所得的关系输入一个GRU网络来编码决策历史![]() ,具体为
,具体为![]() ,其中
,其中![]() ,
,![]() 为Aj-1中的关系。H0和r0都是零向量。
为Aj-1中的关系。H0和r0都是零向量。
根据状态St获取行动空间A(St),对于所有的![]() ,计算一个能够感知关系的问题表示,计算方法为:首先将r*投射到qt的嵌入空间上,计算r*与
,计算一个能够感知关系的问题表示,计算方法为:首先将r*投射到qt的嵌入空间上,计算r*与![]() 的相似度然后将结果传给一个SoftMax层,得到一个在
的相似度然后将结果传给一个SoftMax层,得到一个在![]() 上的注意力分布。通过以下公式得到这些向量的加权和
上的注意力分布。通过以下公式得到这些向量的加权和![]() ,作为关系r*和问题q之间的交互:
,作为关系r*和问题q之间的交互:
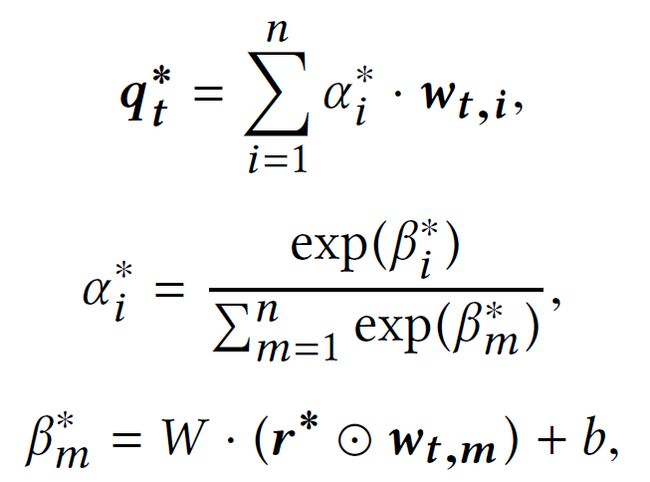
其中![]() 为关系r*的嵌入,
为关系r*的嵌入,![]() 都是学得的参数,⊙是Hadamard乘。然后,使用用以下公式描述的感知机计算at的语义得分:
都是学得的参数,⊙是Hadamard乘。然后,使用用以下公式描述的感知机计算at的语义得分:
![]()
其中两个W都是学得的参数。基于相似度,选择at的概率值通过一个SoftMax层计算:
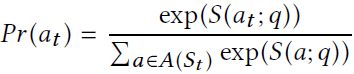
然后根据概率分布从A(St)中抽样出行动At。注意到,KG中存在一对多的关系,故关系相同的候选行动将会被以相同度概率抽样。
因此,以下算法展示了一个agent如何通过该策略网络对给定的问题获取一个决策轨迹,预测的回答为节点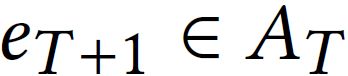 :
:

综上,对于一个示例问题“Where was the father of Sylvia Brett’s other half born?”,本文的推理框架如下图2:
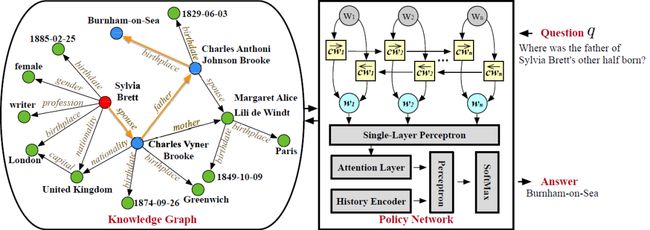
图 2
4.基于Potential的Reward Shaping
前面已经提到了弱监督带来的奖励的延后和稀疏问题,针对这个问题,比较便利的方法是对原始的MDP提供额外的奖励,但这样可能会使得agent被困在子目标中,无法达成真正的目标。因此,有文献提出了基于potential的rewardshaping,文献中提到,一个shaping reward function ![]()
![]() 是基于potential的指的是对所有的
是基于potential的指的是对所有的![]() 存在
存在![]()
![]() ,其中s0指的是像终止状态一样的吸收状态,γ是discountfactor。可以证明,当F是基于potential的时候,
,其中s0指的是像终止状态一样的吸收状态,γ是discountfactor。可以证明,当F是基于potential的时候,![]() 中的每个最有策略都是
中的每个最有策略都是![]() 中的一个最优策略,反之亦然。
中的一个最优策略,反之亦然。
本文基于以上定理提出了一个基于potential函数![]() 的rewardshaping函数
的rewardshaping函数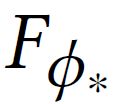 。ϕ*用来衡量给定问题的多少语义信息被agent之前所做出的决策包含。这里,正确的决策指含KG中的一个关系,该关系能覆盖到问题中的部分语义信息。本文的ϕ*计算如下:
。ϕ*用来衡量给定问题的多少语义信息被agent之前所做出的决策包含。这里,正确的决策指含KG中的一个关系,该关系能覆盖到问题中的部分语义信息。本文的ϕ*计算如下:

其中Qt是前一步中的每个词向量的和,Ht是所编码的决策历史,其关系嵌入是用的与训练的KG嵌入矩阵(TransE方法)。因此,该方法不需要除了KG结构信息之外的任何外部先验知识,故可以用于其他领域。本文修改了原始的reward 函数,对于基于potential的rewardshaping函数 ![]() ,本文的reward函数为:
,本文的reward函数为:
![]()
5.训练
对于所有的参数θ,训练目标为在所有问题-答案对上最大化预期reward:
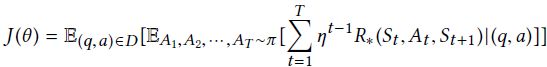
其中η为discountfactor,D为训练集,(q, a)是D中的一个问题-答案对。使用经典的策略梯度法(REINFORCE算法)优化。
实验
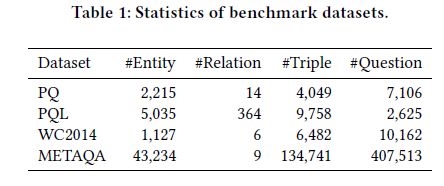
本文在三个benchmark数据集上评估SRN的效果,分别是通用领域的PathQuestion (含PQ和PQL两种)、足球领域的 WC2014 (其中单一关系问题集为WC-1H,2关系问题集为WC-2H,前面两个集问题集的混合集为WC-M,合取型问题集为WC-C)和电影领域的METAQA (原数据集有纯人工构建集Vanilla,也有使用机器翻译得到的其他数据集,本文仅使用Vanilla和Vanilla-EU,EU指未标注topic-entity。)。数据集的细节如下表1。
Baseline有IRN、VRN、MemNN、KV-MemNN和MINERVA,其中MINERVA是一个使用RL的知识图谱补全模型。
实现细节上,首先,词嵌入用预训练的嵌入初始化,KG嵌入使用基于TransE的预训练结果,两种嵌入的维数都是300。用于编码问题的双向GRU有2层,隐藏层维数为150。用于编码历史的单向GRU有3个300维的隐藏层。对GRU都使用dropout,dropout率为0.3。对于神经网络种的层,使用Xavier初始化。对于基于potential的rewardshaping,discount factorγ为0.95,对于REINFORCE算法,本文将discountfactor η调节在(0.9, 1.0)之间。训练时的beam size为1,即贪心搜索;测试时的beamsize则为32。对于参数优化,使用ADAM optimizer,初始学习率lr为0.001,使用验证集上的表现来确定所有超参。(PQ, PQL, 和WC2014)的训练/验证/测试比为8:1:1,衡量在5次不同的划分结果上的平均表现。对于METAQA,使用其标准划分,但同样做5次平均。METAQA论文种的模型和IRN模型都是给定了回答问题所需的三元组数量的(对应的数据集为PQ、PQL和METAQA),本文认为这是不现实的,因此本文混合了这些问题,得到了PQ-M、PQL-M、Vanilla-Mix和Vanilla-EU-Mix。
实验结果如下表2和表3。

根据结果,可以看出SRN在来自不同领域的多关系问题上超越了所有baseline。本文认为这种差距是因为baseline都是考虑整个以topic entity为中心的子图,而这可能会导致topic entity的T跳之内的其他knowledgeitem会误导训练和测试。注意到同样使用RL的MINERVA在更复杂的问题上表现不好,本文认为这也是因为它考虑整个以topic-entity为中心的子图,导致了reward的延后和稀疏问题。注意到所有的方法都在Vanilla-EU上表现更差,因为该数据集没有标注topic entity,而topic entity链接是这一切的基础。本文使用了一个topic-entity linker,而VRN使用了一个基于全连接神经网络的topic entity recognizer,且将topic entity的处理和多跳推理放在一起同时训练。然而实验结果表明这种方法表现不好,尤其是在3跳问题上。本文认为这是由于VRN有reward的延后和稀疏问题,导致其设计的topic entity recognizer接收到了更少的正信号,因此训练可能不充分。另外,注意到IRN-weak在PQL和Vanilla上表现不好,本文认为这可能是由于它所用的多任务训练策略,即KG嵌入的训练和其他QA参数的训练交替进行,而这种策略在更大的KG上既花太多时间,又可能会让损失函数误导QA任务。
最后,本文还做了ablationstudy。首先,本文尝试去掉了策略网络中的注意力机制,结果如表2和表3。可以看出,没有了注意力机制的模型在所要求的三元组数量未知的情况下表现远不如原始SRN。然后,本文去掉了感知机,计算相似度改用余弦相似度。结果同样见表2和表3,可以看见在PQL这样的KG更大的数据集上表现不好。在Vanilla上,这样的模型在所要求的三元组数量已知的情况下表现还行,但未知的情况下则表现下降许多。另外,本文还在6个三跳数据集评估了去掉基于potential的reward shaping的SRN的训练过程,如图3,图种红线是原始SRN在验证集上的表现,蓝线是去掉基于potential的reward shaping的SRN在验证集上的表现。可以看出这一策略的确会加快收敛。
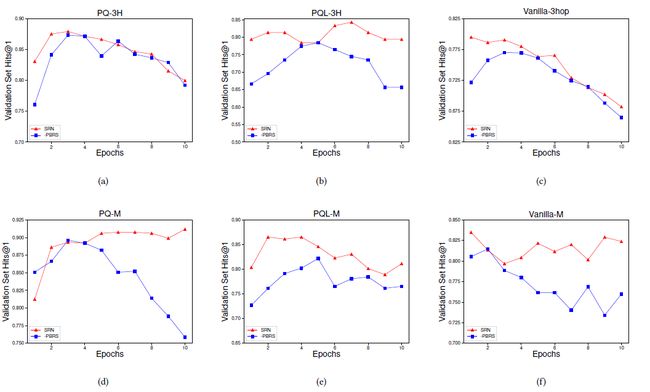
图 3
总结
本文针对多关系的知识图谱问答提出了一个基于深度强化学习的模型SRN,主要的特点为将多关系问答视为RL中的顺序决策问题,使用beamsearch来显著降低候选答案,使用注意力机制和神经网络来决定当前步骤中应该关注问题中的哪个部分,最后,提出了基于potential的reward shaping策略缓解来弱监督带来的reward的延后和稀疏问题。实验证明了SRN的有效性。最后,本文还指出了SRN存在缺陷,即不能很好地回答推理路径上含限制的问题,如“Which player is the highest in NBA?”。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。