python3_scrapy爬取斗鱼手机端数据包(颜值模块主播照片)
1.手机端数据包的抓取(响应教程可自行百度)
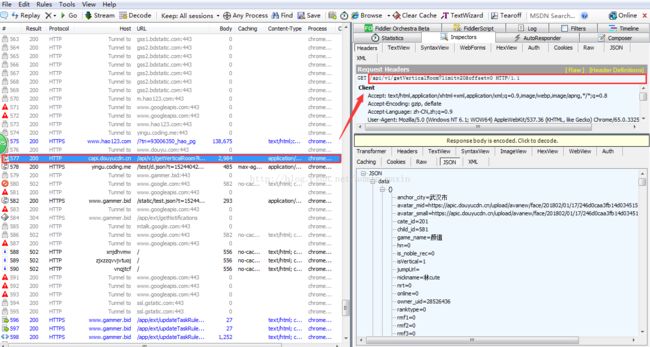
2.具体程序编写
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DouyuItem(scrapy.Item):
# define the fields for your item here like:
# 1.主播所在版块
game_name = scrapy.Field()
# 2.主播房间号
room_id = scrapy.Field()
# 3.主播链接
vertical_src = scrapy.Field()
# 4.主播昵称
nickname = scrapy.Field()
# 存储照片名称信息5.
message = scrapy.Field()
douyu.py
# -*- coding: utf-8 -*-
import scrapy
import json
from Douyu.items import DouyuItem
class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['douyucdn.cn']
# 0.抓取斗鱼手机端app中颜值分类的数据包
baseURL = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset="
offset = 0
start_urls = [baseURL+str(offset)]
def parse(self, response):
# 1.将已经编码的json字符串解码为python对象(此处的Python对象时一个字典)
# 1.data键对应的值是一个列表,列表中每一个元素又是一个字典
data_list = json.loads(response.body)["data"]
# 2.判断data是否为空(为空终止,不为空继续翻页)
if not data_list:
return
for data in data_list:
item = DouyuItem()
item["game_name"] = data["game_name"]
item["room_id"] = data["room_id"]
item["vertical_src"] = data["vertical_src"]
item["nickname"] = data["nickname"]
item["message"] = data["game_name"]+data["room_id"]+data["nickname"]
# 3.返回item对象给管道进行处理
yield item
# 4.JSON文件只能通过翻页来爬取,不能通过xpath()提取
self.offset += 20
# 5.将请求发回给引擎,引擎返回给调度器,调度器将请求入队列
yield scrapy.Request(self.baseURL+str(self.offset), callback=self.parse)
pipelines.py
# -*- coding: utf-8 -*-
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# 1.导入scrapy包中pipelines文件夹下images.py文件中ImagesPipeline类
import os
import scrapy
from Douyu.settings import IMAGES_STORE as images_store
from scrapy.pipelines.images import ImagesPipeline
class DouyuPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
"""图片下载"""
image_link = item["vertical_src"]
# 2.管道将图片链接交给下载器下载
yield scrapy.Request(image_link)
def item_completed(self, results, item, info):
"""图片重命名"""
# 3.取出results中图片信息中:图片的存储路径
# results是一个列表,列表中一个元组,元组中两个元素,第二个元素又是一个字典 / md5码
# 推导式写法取值(最外层的列表相当于results列表)
img_path = [x["path"] for ok, x in results if ok]
# 4.为下载图片重命名
# 4.os.rename(src_name, dst_name)
os.rename(images_store+img_path[0], images_store + item["message"]+".jpg")
return item
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for Douyu project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'Douyu'
SPIDER_MODULES = ['Douyu.spiders']
NEWSPIDER_MODULE = 'Douyu.spiders'
# 1.设置保存下载图片的路径images_store
# 1.另外一种路径方式IMAGES_STORE = "E:\\Python\\课程代码\\Douyu\\Douyu\\spiders\\"
IMAGES_STORE = "E:/Python/课程代码/Douyu/Douyu/spiders/"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 2.配置手机移动端user_agent
USER_AGENT = 'Mozilla/5.0 (iPhone 84; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.0 MQQBrowser/7.8.0 Mobile/14G60 Safari/8536.25 MttCustomUA/2 QBWebViewType/1 WKType/1'
# Obey robots.txt rules
# 3.禁用robots协议(设置为False或者直接注释掉)
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Douyu.middlewares.DouyuSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'Douyu.middlewares.DouyuDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# 4.启用管道文件
ITEM_PIPELINES = {
'Douyu.pipelines.DouyuPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
start.py
# -*- coding:utf-8 -*-
from scrapy import cmdline
cmdline.execute("scrapy crawl douyu".split())
3.图片爬取结果展示
