线上问题排查实战
我们团队组织了线上问题排查实战演练,都是经典题目,在此记录下来方面后续遇到问题使用
题目一:
某服务器的sshd的监听端口是22,如何统计这台服务器的sshd服务各种状态(TIME_WAIT/CLOSE_WAIT/ESTABLISHED)的连接数,以便快速定位问题
题目目的:了解机器连接数情况,便于排查问题
参考答案:

参考博客:http://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316661.html
Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令
题目二:
某服务器中/opt/log/dubbo-access-provider.2017-06-26.log.bz2日志中,有xxxxx关键字的数据有多少条?
题目目的:当前线上日志文件统一要求以bz2 压缩之后保留在本机,当需要查看历史日志时,解压需要耗费大量时间,如何在不解压的情况下直接查看内容
参考答案:
答案比较简单,不做解析
题目三:
打包某服务器的 /opt/web/dianshang_beauty_web 目录,排除掉目录中的logs和work两个目录,打包后的文件名格式:自己的邮箱前缀.tar.gz(例如:zhangsan.gz)。打包好的文件存放在/opt/backup目录下
题目目的:实际应用场景较为频繁,在项目代码需要打包迁移时,常常需要排除掉日志目录
参考答案:
tar -zcvf /opt/backup/manong.tar.gz -exclude\ /opt/web/dianshang_beauty_web/work -exclude\ /opt/web/dianshang_beauty_web/logs/opt/web/logs /opt/web/dianshang_beauty_web
参考:https://www.cnblogs.com/kaynet/p/6410722.html
答案解析:
tar
-c: 建立压缩档案
-x:解压
-t:查看内容
-r:向压缩归档文件末尾追加文件
-u:更新原压缩包中的文件
这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个。下面的参数是根据需要在压缩或解压档案时可选的。
-z:有gzip属性的
-j:有bz2属性的
-Z:有compress属性的
-v:显示所有过程
-O:将文件解开到标准输出
下面的参数-f是必须的
-f: 使用档案名字,切记,这个参数是最后一个参数,后面只能接档案名。
# tar -cf all.tar *.jpg
这条命令是将所有.jpg的文件打成一个名为all.tar的包。-c是表示产生新的包,-f指定包的文件名。
# tar -rf all.tar *.gif
这条命令是将所有.gif的文件增加到all.tar的包里面去。-r是表示增加文件的意思。
# tar -uf all.tar logo.gif
这条命令是更新原来tar包all.tar中logo.gif文件,-u是表示更新文件的意思。
# tar -tf all.tar
这条命令是列出all.tar包中所有文件,-t是列出文件的意思
# tar -xf all.tar
这条命令是解出all.tar包中所有文件,-x是解开的意思
解压
tar -xvf file.tar //解压 tar包
tar -xzvf file.tar.gz //解压tar.gz
tar -xjvf file.tar.bz2 //解压 tar.bz2
tar -xZvf file.tar.Z //解压tar.Z
unrar e file.rar //解压rar
unzip file.zip //解压zip
总结
1、*.tar 用 tar -xvf 解压
2、*.gz 用 gzip -d或者gunzip 解压
3、*.tar.gz和*.tgz 用 tar -xzf 解压
4、*.bz2 用 bzip2 -d或者用bunzip2 解压
5、*.tar.bz2用tar -xjf 解压
6、*.Z 用 uncompress 解压
7、*.tar.Z 用tar -xZf 解压
8、*.rar 用 unrar e解压
9、*.zip 用 unzip 解压
题目4:
查询某服务器运行服务的总线程数
题目目的:当机器线程数超报警阀值时,能快速查出相关进程及线程信息
参考答案
ps -eLf
或pstree -p
参考:http://www.cnblogs.com/wangkangluo1/archive/2011/09/23/2185938.html
题目5:
找出某台服务器最大的文件名中包含log的文件,假设因为该文件导致了磁盘空间报警,并且该文件是某个正在运行的tomcat服务异常产生的日志,需要处理该文件(该文件可进行任意操作包括删除),以释放空间。请给出相关思路
参考答案:
df-h 和 du -sh * 命令结合找到最大的文件,具体命令:du -a | sort -rn | grep log | more
再用rm命令删除文件,重启tomcat
答案解析:
http://www.cnblogs.com/chyong168/archive/2012/03/23/2413349.html
du命令用来查看目录或文件所占用磁盘空间的大小。常用选项组合为:du -sh
-h:以人类可读的方式显示
-a:显示目录占用的磁盘空间大小,还要显示其下目录和文件占用磁盘空间的大小
-s:显示目录占用的磁盘空间大小,不要显示其下子目录和文件占用的磁盘空间大小
-c:显示几个目录或文件占用的磁盘空间大小,还要统计它们的总和
--apparent-size:显示目录或文件自身的大小
-l :统计硬链接占用磁盘空间的大小
-L:统计符号链接所指向的文件占用的磁盘空间大小
使用示例:
du -a:使用此选项时,显示目录和目录下子目录和文件占用磁盘空间的大小
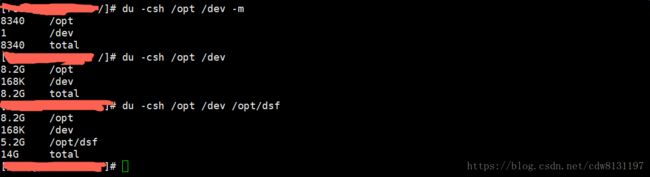
du -s /opt -m 显示opt文件夹占用磁盘空间大小,单位为M
du -s /opt --apparent-size -m 显示文件夹自身大小,非占用磁盘空间大小
du -csh /opt /dev 使用此选项时,不仅显示几个文件或目录各自占用磁盘空间的大小,还统计它们的总和
加上-c选项后,du不仅显示两个目录各自占用磁盘空间的大小,还在最后一行统计它们的总和
-b:忽略每行前面开始出的空格字符
-c:检查文件是否已经按照顺序排序
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符
-f:排序时,将小写字母视为大写字母
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符
-m:将几个排序号的文件进行合并
-M:将前面3个字母依照月份的缩写进行排序
-n:使用『纯数字』进行排序(默认是以文字型态来排序的)
-o<输出文件>:将排序后的结果存入制定的文件
-r:以相反的顺序来排序
-u:就是 uniq ,相同的数据中,仅出现一行代表
-t<分隔字符>:指定排序时所用的栏位分隔字符
+<起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位
2.假如/etc/passwd 内容是以:来分隔的,想以第三栏来排序,该如何
cat /etc/passwd | sort -t ':' -k 3
3.默认是以字符串来排序的,如果想要使用数字排序:
cat /etc/passwd | sort -t ':' -k 3n
4.默认是升序排序,如果要倒序排序
cat /etc/passwd | sort -t ':' -k 3nr
5.如果要对/etc/passwd,先以第六个域的第2个字符到第4个字符进行正向排序,再基于第一个域进行反向排序
cat /etc/passwd | sort -t ':' -k 6.2,6.4 -k 1r
题目六:
提取某服务器上/opt/log/dubbo_access.log-20170609【访问日志】 访问前10的IP地址及访问次数
题目目的:cat,awk,uniq,sort,head命令结合使用,日常日志分析中用到的比较多
参考答案
cat /opt/log/dubbo_access.log-20170609|awk '{print $2}' | sort | uniq -c |sort -rn |head -n 10
答案解析:
http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858385.html
uniq
uniq命令可以去除排序过的文件中的重复行,因此uniq经常和sort合用
-i:忽略大小写字符的不同;
-c:进行计数
-u:只显示唯一的行
直接删除未经排序的文件,将会发现没有任何行被删除,通常情况与sort一起使用
cat xxx |sort |uniq
排序之后删除了重复行,同时在行首位置输出该行重复的次数
cat xxx |sort |uniq -c
仅显示存在重复的行,并在行首显示该行重复的次数
cat xxx |sort |uniq -dc
仅显示不重复的行
cat xxx |sort |uniq -u
题目七:
显示某服务器 /opt/log/server.conf文件不以#号开头的行
题目目的:了解grep/sed的用法
参考答案
sed -n '/^[#]/!p'/opt/log/server.conf
grep -v "^#" /opt/log/server.conf
答案解析:
https://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856896.html
https://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856901.html
后面还有三个题目,会在下一篇博客整理出来