一个大尺度超文本网络搜索引擎的剖析
【原题】一个大尺度超文本网络搜索引擎的剖析
【译题】The anatomy of a large-scale hypertextual Web search engine
【作者】Sergey Brin , Lawrence Page
【说明】本文是谷歌创始人 Sergey 和 Larry 在斯坦福大学计算机系读博士时的一篇论文。发表于1997年。
Abstract
In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext. Google is designed to crawl and index the Web efficiently and produce much more satisfying search results than existing systems. The prototype with a full text and hyperlink database of at least 24 million pages is available athttp://google.stanford.edu/
To engineer a search engine is a challenging task. Search engines index tens to hundreds of millions of Web pages involving a comparable number of distinct terms. They answer tens of millions of queries every day. Despite the importance of large-scale search engines on the Web, very little academic research has been done on them. Furthermore, due to rapid advance in technology and Web proliferation, creating a Web search engine today is very different from three years ago. This paper provides an in-depth description of our large-scale Web search engine - the first such detailed public description we know of to date.
Apart from the problems of scaling traditional search techniques to data of this magnitude, there are new technical challenges involved with using the additional information present in hypertext to produce better search results. This paper addresses this question of how to build a practical large-scale system which can exploit the additional information present in hypertext. Also we look at the problem of how to effectively deal with uncontrolled hypertext collections where anyone can publish anything they want.
Keywords: World Wide Web; Search engines; Information retrieval; PageRank: Google
1. 介绍
网络对信息检索形成了新的挑战。信息在网上的数量增长迅速,与此同时新用户在网络搜索技艺上缺乏经验。人们喜欢在网上冲浪时使用网络的链接图,这通常始于高质量的人所维护的索引,诸如 Yahoo!或始于搜索引擎。人所维护的列表有效的覆盖了大众话题,但其是主观个人的,构建与维护颇为昂贵,而且不能覆盖所有难懂的话题。依赖于关键字匹配的自动搜索引擎通常返回过多的低质量匹配。甚至让事情更糟的是,某些广告商试图通过误导自动搜索引擎的测度手段(by taking measures meant to mislead automated search engines)获人们的关注。我们已经构造了一个大尺度搜索引擎,其应对的就是许多现存系统的问题。它特别重度的使用了呈现在超文本中的“提供质量高得多的搜索结果”的附加结构。我们把自己的系统名选取为 Google,这是因为该名字是googol (或10100) 的通常拼法,很适合我们的目标:构造一个非常大尺度的搜索引擎。
1.1 网络搜索引擎 – 规模的扩大:1994-2000年
搜索引擎技术随着网络的增长保持着剧烈的扩增。在1994年,头一个网络搜索引擎,万维网蠕虫(World Wide Web Worm , WWWW)【6】拥有 110,000张网页和网络存取文档的一个索引。当在1997年11月时,顶级搜索引擎宣称有从2百万(网络爬虫 [ WebCrawler])到1亿个网络文档(来自搜索引擎)的索引。可以预见的是,到2000年,可以索引的Web文档数量将会超过10亿个。与此同时,搜索引擎所要应付的查询请求也在以难以置信的速度增长。1994年的3,4月间,World Wide Web Worm每天大概接受1500个请求。在1997年的11月,Altavista声称其每天处理约2千万个请求。随着互联网用户和自动请求搜索引擎的系统的增加,到2000年底,一些顶尖搜索引擎很有可能达到日处理2千万个请求的数量级。我们系统的目标是在质量和规模上解决所有由上述趋势所带来的问题。
1.2 Google 抓取网络
建立一个搜索引擎抓取目前的互联网带来了很多挑战,为了能够收集网络文档并保持他们的时效性,一种快速的抓取技术是必须的。存储空间必须被合理利用来存储索引和文档本身;索引系统必须能够有效地处理海量数据(hundreds of gigabytes);请求必须能够以每秒几百甚至几千次的速度被快速地处理。
这些问题随着互联网规模的扩大将会变得越来越困难。然而,硬件性能的改进和成本的降低部分地解决了一些困难。但是,这些硬件的发展也带来了一定程度的副作用,比如说磁盘定位时间和操作系统的健壮性。在设计Google的过程中,我们充分考虑到了互联网增长的速率和技术的变化。Google被设计成可以有效地适应海量的数据集。Google能够有效地利用存储空间来存储索引。为了快速有效地对其数据进行访问,我们优化了它的数据结构(见节 4.2)。除此以外,我们设想,Google索引和存储文档和Html的消耗将最终减少到一个可以接受的数量级。这将为一个像Google一样的中心化系统带来可观的抓取特性。
1.3 设计目标
1.3.1改进的搜索质量
我们的主要目的是为了改进Web搜索引擎的质量。在1994年,一些人相信一个完全索引的搜索引擎将能够很容易的为我们找到所需要的内容。根据数据显示(Thebest navigation service should make it easy to find almost anything on the Web[onceall the data is entered] ,引自Bestof the Web 1994 - Navigators),1997年的Web已经大不相同了。这些年来,任何一个使用了搜索引擎的用户都可以去测试并感知索引的完整性并不是用来衡量搜索结果质量的唯一因素。“垃圾结果(JunkResults)”常常将一些用户感兴趣的结果给掩盖了。事实上,在1997年11月,只有4家顶级的商业搜索引擎能够在搜索结果中找到自己(根据输入自己的名称在自己的搜索结果的前10条记录中返回自己)。一个主要原因是,索引中文档的数量增加了好几个数量级的同时,用户阅读文档的能力却没有相应的增加(thenumber of documents in the indices has been increasing by many orders of magnitude,but the user’s ability to look at documents has not.)。人们还是希望能在结果的前面几十个结果文档中就能找到他们所需要的信息。正因为此,随着集合大小的增加,我们需要一个工具来对结果进行精准的定位(将最为相关的文档在结果的前十个中返回)。当然,我们希望我们所说的“相关”是在结果中仅仅包括从上万个轻度相关的文档中返回最好的文档。这种高度查准率(Precision)哪怕是在牺牲查全率(Recall)的条件下都是尤为重要的。最近有很多的利用更多超文本信息的优化措施用来帮助改善搜索和其他应用程序。特别的,链接结构(linkstructure)和链接文本(linktext)为了做出相关性判断和质量过滤提供了大量有用的信息。Google为达到目标使用了链接结构和锚定文本(anchortext)(见节2.1和2.2)
1.3.2 理论搜索引擎研究
随着时间的变迁,互联网除了飞速增长之外,也变得越来越商业化。在1993年,大概1.5%左右的Web服务器使用的是.Com的域名。这个数字在1997年的时候增长到了60%。与此同时,搜索引擎也从纯粹的理论学院派研究转移到了商业应用上。到目前为止,多数搜索引擎的发展都是由一些公司主导并且很少有相关技术细节的论文发表。这导致了搜索引擎技术被大众认为是一种魔法而且是面向广告的( 参见完整版的附录A )。我们在设计Google的时候就有一个目标,为了给理论中的相关领域带来更多的发展和认识。
另外一个很重要的设计目的是为了能够让更多的人可以实际使用我们的系统。用户的使用对于我们来说是非常重要的,因为我们认为很多有趣的研究都将涉及如何平衡大量数据的使用。例如,每天都有成千上万的搜索。但是,得到这些搜索日志的数据却是非常困难的,因为这些数据常常被认为是有商业用途而不会公开的。
我们的终极设计目的是创建一个这样的架构:这个架构能够支持很多涉及大数据集的新型研究活动(cansupport novel research activities on largescale Web data.)。为了达到这个目的,Google将所有抓取到的文档都已压缩的形式存储了下来。我们设计Google的一个主要目的是建立一个环境:研究人员可以迅速的融入进来,处理网络的大块数据并且得出在其他的环境中很难获得的研究成果。在系统建立的初期,我们已经利用Google的数据库发表了几篇论文,还有许多论文正在进行中。另外一个我们的目的是建立一个类似宇宙空间实验室的环境。在这里,研究员,甚至是学生都可以在我们提供的大规模网络数据集上进行各种各样的有趣的研究计划。
2. 系统特征
Google的两项重要特性帮助Google返回高查准率的搜索结果。第一,Google利用网络的链接结构来计算每一个Web页面的排名。这种排名叫做PageRank,有关这项技术的细节可以参考【7】.第二,Google利用链接来改进搜索结果。
2.1. PageRank:为网络排序
网络的引用图(Thecitation [link] graph of the Web)是一项非常重要的资源但是却常常被当今的一些搜索引擎忽略了。我们创建了一个包括了5亿1千八百万类似于这样的超链接的地图。这些地图使我们可以快速的计算一个Web页面的PageRank值。PageRank是某个Web页面引用重要性的客观量度。这种重要性与人们主观上关于重要性认识是一致的。正是基于此,PageRank是一种把搜索结果根据Web关键词搜索排序的绝佳途径。对于众多热门的主题,在使用了PageRank对结果进行了排序以后(demp可以在google.stanford.edu获得),一个简单的对Web页面标题的严格文本匹配搜索就可以获得绝佳的性能。对于Google系统中的全文搜索而言,PageRank更是起到了重要的作用。
2.1.1 PageRank计算描述:
学术上的引用文献方法被应用到了Web上,很大程度上被用来计算一个给定页面的被引用的次数和向后链接(backlinks)。这种方法可以给出一个页面重要程度和质量的估计值。PageRank对这种方法进行了延伸:并不是对来自于所有页面的链接进行相等的相加,而是对一个页面上的链接数进行规格化。PageRank定义如下:
假设页面A有页面T1…TN的指向。参数 d 作为一个阻尼因子,它的值可以设定为0到1之间。我们通常设为0.85。下一节中我们将有关于d 的更多细节。C(A)被定义为页面 A 指向其他页面的链接个数。页面 A 的PageRank计算如下:
PR(A)=(1-d)+d ( PR(T1)/C(T1) + …. + PR(Tn)/C(Tn) )
注意到PageRank在Web页面上组成了一个概率分布。所以我们不难得出所有Web页面的PageRank和为1。
PageRank可以通过一个简单的迭代算法来进行计算,而且这是符合Web链接规格化矩阵的主特征向量的。同样的,一个关于2千6百万Web页面的PageRank计算可以在一台中等规模的工作站上只用几个小时就计算完成。更多关于PageRank计算的细节超出了本文的讨论范围。
2.1.2 直觉地判断
PageRank可以被认为是用户习惯的模型。我们假设存在一个“随机冲浪者”,我们随机给他一个Web页面,让他持续的点击其中的链接,我们的冲量者从来不会返回,但是他最终会感到疲倦然后从另外一个随机页面开始新一轮的冲浪。随机冲浪者访问一个页面的概率就是这个页面的PageRank值。而且阻尼系数d值是随机冲浪者在每个页面上感到厌倦选择新的随机页面的概率。一个重要的变化因素是仅仅为一个单独的页面或者一组页面增加d值。这种方式允许个性化并且使得故意误导系统使获得高排名的企图几乎不可能实现。我们对于PageRank还有一些其他的扩充,同样可以参考【7】。
另外的一种直觉判断是这样的,一个页面如果拥有很高的PageRank那么表明肯定有很多页面指向它。直观地,被互联网上多处引用的页面一定是值得访问的。同样的,如果一个页面仅仅被一个页面引用,但是这个引用页面是类似于Yahoo首页这样的页面,我们认为这样的页面同样是值得去访问的。如果一个页面不具有高质量或者是一个坏链接,通常像Yahoo首页这样的页面是不会有这样的链接的。PageRank通过Web的连接结构递归的传递权值(betweenby recursively propagating weights through the link structure of the Web)来处理上述的两个问题。
2.2 锚定文本
链接的文本在我们的搜索引擎中被特殊的处理了,大多数的搜索引擎将链接的文本和该页面联系起来。我们除了进行这些处理以外,我们还把这些文本与链接指向的页面联系了起来。这样做有几个好处。第一,这些文本通常提供了比Web页面本身更加精准的对于页面内容的描述性文字。第二,Anchors描述了一些不能被文本搜索引擎索引的文档,比如说图片,程序,数据库等等。这些信息将有可能返回没有被抓取的Web页面的地址。注意到那些没有被抓取的页面可能带来的问题:因为它们的有效性在返回给用户之前永远不可能得到验证。在这种情况下,搜索引擎很有可能返回一个实际上根本不存在的但却有超链接链接到的页面。然而,通过对结果的排序,这个问题在实际中很少会发生。
这种通过锚定文本本身对Web页面进行描述的思想最早在World Wide Web Worm【6】中得以特别地实现因为它帮助搜索非文本信息并扩展了搜索的覆盖度,提供了少数几种可下载文档的信息。我们使用这种思想主要是因为 Anchor Text 可以帮助提供更好的搜索质量。考虑到大量必须被处理的数据量,有效的利用AnchorText在技术上是十分困难的。在我们目前抓取的2千4百万页面中,我们索引了超过2亿5千9百万的Anchor文本。
3. 相关工作
互联网上的搜索研究历史短暂而简明。WWWW【6】是第一代搜索引擎中的一个。紧跟其后的是一些学院派搜索引擎,很多现在已经公司化了。同Web的发展和搜索引擎的重要性比起来,很少有关于最近搜索引擎技术的文档【8】。照 Michael Mauldin (Lycos 公司的首席科学家 )的话,“各种服务(包括Lycos)密切的保护这些数据库的细节)”。然而,还是有相当一部分关于搜索引擎某一特性的工作在进行中。特别值得一提的是目前搜索引擎中对搜索结果进行预后处理得到最终结果,或者得到一个小规模的个性化搜索引擎。最后,还有相当多的关于信息检索系统领域的研究,特别在受约束集合的范围下【11】。
然而,所有基于信息检索系统的研究都是在基于很小范围内的同类型受约束集合中,诸如文本会议检索【10】。很多在TREC上可以获得很好结果的方法并不能在Web上得以适用。比如说,标准向量空间模型(standard vector space model)对文档和查询根据其中单词的出现来定义其向量。在Web上,这种方法通常返回非常短小的文档,这些文档通常是查询的关键字加上少许单词。比如说,我们曾看到一个主流的搜索引擎在我们输入“BillClinton”查询时返回了一个只包含一句“Bill Clinton Sucks”和一张图片的页面。通过这个例子,我们相信,为了能够更好的处理网络上的信息,传统的信息检索工作需要进行扩展。
Web是一个完全不受约束同类文档的大型集合。Web文档在文档结构本身抑或是外部的元数据中就存在有很多变化。两个文档在大小、质量、流行度和可信值上可以存在许多维度的差异。所有这些都对网络上的有效搜索构成了重要挑战。在某种程度上它们被辅助数据的可用性所调和,诸如超链接和格式化,而Google就试图利用这两者。
4. 系统剖析
4.1 Google 体系结构概览
在这一节中,我们会对如图1 中的整个系统如何工作给出一个高层概览。下一节将讨论本节中未提及的应用和数据结构。谷歌大多数用的软件用C 或 C++实现,是因为效率的原因,代码同时可跑在Solaris或Linux上。
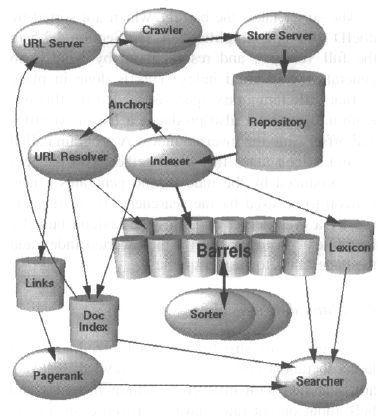
图1:Google体系架构概览
在Google中,Web抓取(Web Crawling)(下载Web页面)是通过多个分布式的抓取器完成的。URL服务器(URLServer)发送待抓取页面的URL给抓取器。收集到的Web页面被送到存储服务器(storeserver),存储服务器(storeserver)压缩并把Web页面存放在知识库(Repository)中。每一个页面都有一个与之联系的ID号叫做DocID。这个ID是在一个页面中新的URL被解析出来的时候分配的。索引(indexing)的功能由索引器(indexer)和排序器(sorter)完成。索引器有若干功能,它读取知识库中的页面,解压文档然后对文档进行解析。每一个文档都被转换为一组字词的存在集合,我们把这个集合叫做Hits。Hits记录字词,文档中的位置,字体的大小和大小写。索引器将这些hits分配到一组称为“桶”的结构中,并由此创建一个部分排序的前向索引(Forward Index)。索引器另外一个重要功能是解析每个页面中的链接并把相关重要的信息存放在锚文件(AnchorFile)中。这个文件包含足够的信息来确定每一个链接来源与指向以及连接的文本。
URL解析器(URLResolver)读取这些锚文件然后将这些相对URL路径转换成为绝对路径并依次分配DocID。URL解析器将AnchorText以及由AnchorText指向的DocID放入前向索引中。同时,URL解析器也产生一个链接的数据库,这个数据库中包含有一组组的DocID。链接数据库用来计算所有文档的PageRank值。
排序器(Sorter)使用按照DocID排序的桶(这是一个简化的说法,可参见完全版中的4.2.5节)来根据WordID的顺序产生倒排索引。一些临时的存储空间需要用来进行此项操作。排序器同时也在倒排索引(inverted index)中产生一组WordID和偏移量。一个叫做DumpLexion的程序将这些链表与由索引器产生的词典关联起来然后产生一个新的词典供搜索器使用。搜索器在Web服务器上运行并且利用由DumpLexicon产生的词典,倒排索引和PageRank来回答查询。
4.2 主要的数据结构
优化了的Google数据结构可以以最小的消耗来处理海量文档的抓取,索引和搜索。虽然CPU和大数据块的输入输出这些年来已经有很大改善,磁盘的定位仍然需要大概10毫秒的时间才能完成。Google被设计为无论何时总是避免不必要的磁盘定位,这种思想对我们数据结构的设计起了极大的作用。这篇论文的完全版就包含了对此数据结构的一个详细讨论。在此我们仅给出一个简短的概述。
4.2.1 大文件
大文件BigFiles是指虚拟文件生成的多文件系统,用长度是64位的整型数据寻址。多文件系统之间的空间分配是自动完成的。BigFiles包也处理已分配和未分配文件描述符。由于操纵系统不能满足我们的需要,BigFiles也支持基本的压缩选项。
4.2.2 知识库
Repository Data Structure 知识库包含每个网页的全部HTML。每个网页用zlib(见RFC1950)压缩。压缩技术的选择既要考虑速度又要考虑压缩率。我们选择zlib的速度而不是压缩率很高的bzip。知识库用bzip的压缩率接近4:1。而用zlib的压缩率是3:1。文档一个挨着一个的存储在知识库中,前缀是docID, 长度,URL,见图2。访问知识库不需要其它的数据结构。这有助于数据一致性和升级。用其它数据结构重构系统,我们只需要修改知识库和crawler错误 列表文件。
4.2.3 文件索引
文件索引保存了有关文档的一些信息。索引以docID的顺序排列,定宽 ISAM(Index sequential access mode)。每条记录包括当前文件状态,一个指向知识库的指针,文件校验和,各种统计表。如果一个文档已经被抓到,指针指向docinfo文件,该文件的 宽度可变,包含了URL和标题。否则指针指向包含这个URL的URL列表。这种设计考虑到简洁的数据结构,以及在查询中只需要一个磁盘寻道时间就能够访问一条记录。还有一个文件用于把URL转换成docID。它是URL校验和与相应docID的列表,按校验和排序。要想知道某个URL的docID,需要计算URL的校验和,然后在校验和文件中执行二进制查找,找到它的docID。通过对这个文件进行合并,可以把一批URL转换成对应的docID。URL分析器用这项技术把URL转换成docID。这种成批更新的模式是至关重要的,否则每个链接都需要一次查询,假如用一块磁盘,322,000,000个链接的数据集合将花费一个多月的时间。
4.2.4 词典
词典有几种不同的形式。和以前系统的重要不同是,词典对内存的要求可以在合理的价格内。现在实现的系统,一台256M内存的机器就可以把词典装入到内存中。现在的词典包含14000000词汇(虽然一些很少用的词汇没有加入到词典中)。它执行分两部分—词汇表(用null分隔的连续串)和指针的哈希表。不同的函数,词汇表有一些辅助信息,这超出了本文论述的范围。
4.2.5 hit list
hit list是一篇文档中所出现的词的列表,包括位置,字号,大小写。Hit list占很大空间,用在正向和反向索引中。因此,它的表示形式越有效越好。我们考虑了几种方案来编码位置,字号,大小写—简单编码(3个整型数),紧凑 编码(支持优化分配比特位),哈夫曼编码。Hit的详细信息见图3。我们的紧凑编码每个hit用2字节。有两种类型hit,特殊hit和普通hit。特殊 hit包含URL,标题,链接描述文字,meta tag。普通hit包含其它每件事。它包括大小写特征位,字号,12比特用于描述词在文档中的位置(所有超过4095的位置标记为4096)。字号采用相对于文档的其它部分的相对大小表示,占3比特 (实际只用7个值,因为111标志是特殊hit)。特殊hit由大小写特征位,字号位为7表示它是特殊 hit,用4比特表示特殊hit的类型,8比特表示位置。对于anchor hit八比特位置位分出4比特用来表示在anchor中的位置,4比特用于表明anchor出现的哈希表hash ofthe docID。短语查询是有限的,对某些词没有足够多的anchor。我们希望更新anchorhit的存储方式,以便解决地址位和docIDhash域位数不足的问题。
因为搜索时,你不会因为文档的字号比别的文档大而特殊对待它, 所以采用相对字号。 Hit 表的长度存储在hit前。为节省空间hit表长度,在正向索引中和wordID结合在一起,在反向索引中和docID结合存储。这就限制它相应地只 占8到5比特(用些技巧,可以从wordID中借8bit)如果大于这些比特所能表示的长度,用溢出码填充,其后两字节是真正的长度。
Figure 3. Forward and Reverse Indexes andthe Lexicon
4.2.6 正向索引
实 际上,正向索引已经部分排序。它被存在一定数量的barrel中(我们用64个barrels)。每个barrel装着一定范围的wordID。如果一篇 文档中的词落到某个barrel,它的docID将被记录到这个barrel中,紧跟着那些词(文档中所有的词汇,还是落入该barrel中的词汇)对应 的hitlist。这种模式需要稍多些的存储空间,因为一个docID被用多次,但是它节省了桶数和时间,最后排序器进行索引时降低编码的复杂度。更进一步的措施是,我们不是存储docID本身,而是存储相对于该桶最小的docID的差。用这种方法,未排序的barrel的docID只需24 位,省下8位记录hitlist长。
4.2.7 反向索引
除了反向索引由sorter加工处理之外,它和正向索引包含相 同的桶。对每个有效的docID,字典包含一个指向该词所在桶的指针。它指向由docID和它的相应hitlist组成的doclish,这个 doclist代表了所有包含该词的文档。 doclist中docID的顺序是一个重要的问题。最简单的解决办法是用doclish排序。这种方法合并多个词时很快。另一个可选方案是用文档中该词出现的次数排序。这种方法回答单词查询,所用时间微不足道。当多词查询时几乎是从头开始。并且当用其它Rank算法改进索引时,非常困难。我们综合了这两 种方法,建立两组反向索引barrel,一组barrels的hitlist只包含标题和anchor hit,另一组barrel包含全部的hitlist。我们首先查第一组索引桶,看有没有匹配的项,然后查较大的那组桶。
4.3 抓网页运行
网络爬行机器人是一项具有挑战性的任务。执行的性能和可靠性甚至更重要,还有一些社会焦点。网络爬行是一项非常薄弱的应用,它需要成百上千的web服务器和各种域名服务器的参与,这些服务器不是我们系统所能控制的。为了覆盖几十亿的网页,Google拥有快速的分布式网络爬行系统。一个URL服务器给若干个 网络爬行机器人(我们采用3个)提供URL列表。URL服务器和网络爬行机器人都是用Python实现的。每个网络爬行机器人可以同时打开300个链接。 抓取网页必须足够快。最快时,用4个网络爬行机器人每秒可以爬行100个网页。速率达每秒600K。执行的重点是找 DNS。每个网络爬行机器人有它自己的DNS cache,所以它不必每个网页都查 DNS。每一百个连接都有几种不同的状态:查DNS,连接主机,发送请求,接收回答。这些因素使网络爬行机器人成为系 统比较复杂的部分。它用异步IO处理事件,若干请求队列从一个网站到另一个网站不停的抓取网页。运行一个链接到500多万台服务器的网页爬行机器人,产生 1千多万登陆口,导致了大量的Email和电话。因为网民众多,总有些人不知道网络爬行机器人是何物,这是他们看到的第一个网络爬行机器人。几乎每天我们都会收到这样的Email“哦,你从我们的网站看了太多的网页,你想干什么?”还有一些人不知道网络搜索机器人避免协议(the robots exclusion protocol),以为他们的网页上写着“版权所有,勿被索引”的字样就会被保护不被索引,不必说,这样的话很难被web crawler理解。因为数据量如此之大,还会遇到一些意想不到的事情。例如,我们的系统曾经企图抓一个在线游戏,结果抓到了游戏中的大量垃圾信息。解决这个问题很简单。但是我们下载了几千万网页后才发现了这个问题。因为网页和服务器的种类繁多,实际上不在大部分Internet上运行它就测试一个网页爬行机器人是不可能。总是有几百个隐含的问题发生在整个web的一个网页上,导致网络爬行机器人崩溃,或者更糟,导致不可预测的不正确的行为。能够访问大部分Internet的系统必须精力充沛并精心测试过。由于象crawler这样大型复杂的系统总是产生这样那样的问题,因此花费一些资源读这些Email,当问题发生时解决它,是有必要的。
4.4 Web索引分析
任何运行在整个Web上的分析器必须能够处理可能包含错误的大型集合。范围从HTML标记到标记之间几K字节的0,非ASCII字符,几百层HTML标记的嵌套,各种各样令人难以想象的错误。为了获 得最大的速度,我们没有采用YACC产生上下文无关文法CFG分析器,而是采用灵活的方式产生词汇分析器,它自己配有堆栈。分析器的改进大大提高了运行速度,它的精力如此充沛完成了大量工作。把文档装入barrel建立索引—分析完一篇文档,之后把该文档装入barrel中,用内存中的hash表—字典, 每个词汇被转换成一个 wordID。当hash表字典中加入新的项时,笨拙地存入文件。一旦词汇被转换成wordID,它们在当前文档的出现就转换成hitlist,被写进正 向barrel。索引阶段并行的主要困难是字典需要共享。
我们采用的方法是,基本字典中有140万个固定词汇,不在基本字典中的词汇写入日志,而不是共享字典。这种方法多个索引器可以并行工作,最后一个索引器只需处理一个较小的额外词汇日志。排序—为了建立反向索引,排序器读取每个正向 barrel,以 wordID排序,建立只有标题anchor hit的反向索引barrel和全文反向索引barrel。这个过程一次只处理一个barrel,所以只需要少量暂存空间。排序阶段也是并行的,我们简单地同时运行尽可能多的排序器,不同的排序器处理不同的桶。由于barrel不适合装入主存,排序器进一步依据wordID和docID把它分成若干篮子,以便适合装入主存。然后排序器把每个篮子装入主存进行排序,并把它的内容写回到短反向barrel和全文反向barrel。
4.5搜索
搜索的目标是提供有效的高质量的搜索结果。多数大型商业搜索引擎好像在效率方面花费了很大力气。因此我们的研究以搜索质量为重点,相信我们的解决方案也可以用到那些商业系统中。
Google查询评价过程见图4。
1. 分析查询。
2. 把词汇转换成wordID。
3. 在短barrel中查找每个词汇doclist的开头。
4. 扫描doclist直到找到一篇匹配所有关键词的文档
5. 计算该文档的rank 6. 如果我们在短barrel,并且在所有doclist的末尾,开始从全文barrel的doclist的开头查找每个词,goto 第四步
7. 如果不在任何doclist的结尾,返回第四步。
8. 根据rank排序匹配文档,返回前k个。图4 Google查询评价在有限的响应时间内,一旦找到一定数量的匹配文档,搜索引擎自动执行步骤8。这意味着,返回的结果是子优化的。我们现在研究其它方法 来解决这个问题。过去根据PageRank排序hit,看来能够改进这种状况。
4.5.1 Ranking系统
Google 比典型搜索引擎保存了更多的web信息。每个hitlist包括位置,字号,大小写。另外,我们还考虑了链接描述文字。Rank 综合所有这些信息是困难的。ranking函数设计依据是没有某个因素对rank影响重大。首先,考虑最简单的情况—单个词查询。为了单个词查询中一个文 档的rank,Goole在文档的hitlist中查找该词。Google认为每个hit是几种不同类型(标题,链接描述文字anchor,URL,普通大字号文本,普通小字号文本,……)之一,每种有它自己的类型权重。类型权重建立了一个类型索引向量。Google计算hitlist中每种hit的数量。然后每个hit数转换成count-weight。Count-weight开始随hit数线性增加,很快逐渐停止,以至于hit数与此不相关。我们 计算count-weight向量和type-weight向量的标量积作为文档的IR值。最后IR值结合PageRank作为文档的最后rank。 对于多词查询,更复杂些。现在,多词hitlist必须同时扫描,以便关键词出现在同一文档中的权重比分别出现时高。相邻词的hit一起匹配。对每个匹配 hit的集合计算相邻度。相邻度基于hit在文档中的距离,分成10个不同的bin值,范围从短语匹配到根本不相关。不仅计算每类hit数,而且要计算每种类型 的相邻度,每个类型相似度对,有一个类型相邻度权type-prox-weight。Count转换成count-weight,计算count- weight、 type-prox-weight的标量积作为IR值。应用某种debug mode所有这些数和矩阵与查询结果一起显示出来。这些显示有助于改进rank系统。
4.5.2 反馈
rank 函数有很多参数象type-weight和type-prox-weight。指明这些参数的正确值有点黑色艺术black art。为此,我们的搜索引擎有一个用户反馈机制。值得信任的用户可以随意地评价返回的结果。保存反馈。然后,当修改rank函数时,对比以前搜索的rank,我们可以看到修改带来的的影响。虽然不是十全十美,但是它给出了一些思路,当rank函数改变时对搜索结果的影响。
5.执行和结果
搜索结果的质量是搜索引擎最重要的度量标准。完全用户评价体系超出了本文的论述范围,对于大多数搜索,我们的经验说明Google的搜索结果比那些主要的商业搜索引擎好。作为一个应用PageRank,链接描述文字,相邻度的例子,图4给出了Google搜索bill Clinton的结果。它说明了Google的一些特点。服务器对结果进行聚类。这对过滤结果集合相当有帮助。这个查询,相当一部分结果来自 whitehouse.gov域,这正是我们所需要的。现在大多数商业搜索引擎不会返回任何来自whitehouse.gov的结果,这是相当不对的。注意第一个搜索结果没有标题。因为它不是被抓到的。Google是根据链接描述文字决定它是一个好的查询结果。同样地,第五个结果是一个Email地址,当然是不可能抓到的。也是链接描述文字的结果。所有这些结果质量都很高,最后检查没有死链接。因为它们中的大部分PageRank值较高。PageRank 百分比用红色线条表示。没有结果只含Bill没有Clinton或只含Clinton没有Bill。因为词出现的相近性非常重要。当然搜索引擎质量的真实测试包含广泛的用户学习或结果分析,此处篇幅有限,请读者自己去体验Google,http://google.stanford.edu/
5.1存储需求
除了搜索质量,Google的设计可以随着Web规模的增大而有效地增大成本。一方面有效地利用存储空间。表1列出了一些统计数字的明细表和Google存 储的需求。由于压缩技术的应用知识库只需53GB的存储空间。是所有要存储数据的三分之一。按当今磁盘价格,知识库相对于有用的数据来说比较便宜。搜索引擎需要的所有数据的存储空间大约55GB。大多数查询请求只需要短反向索引。文件索引应用先进的编码和压缩技术,一个高质量的搜索引擎可以运行在7GB的新PC。
5.2 系统执行
搜索引擎抓网页和建立索引的效率非常重要。Google 的主要操作是抓网页,索引,排序。很难测试抓全部网页需要多少时间,因为磁盘满了,域名服务器崩溃,或者其它问题导致系统停止。总的来说,大约需要9天时 间下载26000000网页(包括错误)。然而,一旦系统运行顺利,速度非常快,下载最后11000000网页只需要63小时,平均每天4000000网 页,每秒48.5个网页。索引器和网络爬行机器人同步运行。索引器比网络爬行机器人快。因为我们花费了大量时间优化索引器,使它不是瓶颈。这些优化包括批量更新文档索引,本地磁盘数据结构的安排。索引器每秒处理54个网页。排序器完全并行,用4台机器,排序的整个过程大概需要24小时。
5.3搜索执行改进
搜索执行不是我们研究的重点。当前版本的Google可以在1到10秒间回答查询请求。时间大部分花费在NFS磁盘IO上(由于磁盘普遍比机器慢)。进一步 说,Google没有做任何优化,例如查询缓冲区,常用词汇子索引,和其它常用的优化技术。我们倾向于通过分布式,硬件,软件,和算法的改进来提高 Google的速度。我们的目标是每秒能处理几百个请求。表2有几个现在版本Google响应查询时间的例子。它们说明IO缓冲区对再次搜索速度的影响。
6 结论
Google设计成可伸缩的搜索引擎。主要目标是在快速发展的World Wide Web上提供高质量的搜索结果。Google应用了一些技术改进搜索质量包括PageRank,链接描述文字,相邻信息。进一步说,Google是一个收集网页,建立索引,执行搜索请求的完整的体系结构。
6.1 未来的工作
大型Web搜索引擎是个复杂的系统,还有很多事情 要做。我们直接的目标是提高搜索效率,覆盖大约100000000个网页。一些简单的改进提高了效率包括请求缓冲区,巧妙地分配磁盘空间,子索引。另一个 需要研究的领域是更新。我们必须有一个巧妙的算法来决定哪些旧网页需要重新抓取,哪些新网页需要被抓取。这个目标已经由实现了。受需求驱动,用代理 cache创建搜索数据库是一个有前途的研究领域。我们计划加一些简单的已经被商业搜索引擎支持的特征,例如布尔算术符号,否定,填充。然而另外一些应用刚刚开始探索,例如相关反馈,聚类(Google现在支持简单的基于主机名的聚类)。我们还计划支持用户上下文(象用户地址),结果摘要。我们正在扩大链接结构和链接文本的应用。简单的实验证明,通过增加用户主页的权重或书签,PageRank可以个性化。对于链接文本,我们正在试验用链接周围的文本加入到链接文本。Web搜索引擎提供了丰富的研究课题。如此之多以至于我们不能在此一一列举,因此在不久的将来,我们希望所做的工作不止本节提到的。
6.2 高质量搜索
当今Web搜索引擎用户所面临的最大问题是搜索结果的质量。结果常常是好笑的,并且超出用户的眼界,他们常常灰心丧气浪费了宝贵的时间。例如,一个最流行的商业搜索引擎搜索“Bill Clillton”的结果是the Bill Clinton Joke of the Day: April 14, 1997。Google的设计目标是随着Web的快速发展提供高质量的搜索结果,容易找到信息。为此,Google大量应用超文本信息包括链接结构和链接文本。Google还用到了相邻性和字号信息。评价搜索引擎是困难的,我们主观地发现Google的搜索质量比当今商业搜索引擎高。通过PageRank 分析链接结构使Google能够评价网页的质量。用链接文本描述链接所指向的网页有助于搜索引擎返回相关的结果(某种程度上提高了质量)。最后,利用相邻性信息大大提高了很多搜索的相关性。
6.3 可升级的体系结构
除了搜索质量,Google设计成可升级的。空间和时间 必须高效,处理整个Web时固定的几个因素非常重要。实现Google系统,CPU、访存、内存容量、磁盘寻道时间、磁盘吞吐量、磁盘容量、网络IO都是 瓶颈。在一些操作中,已经改进的Google克服了一些瓶颈。Google的主要数据结构能够有效利用存储空间。进一步,网页爬行,索引,排序已经足够建 立大部分web索引,共24000000个网页,用时不到一星期。我们希望能在一个月内建立 100000000网页的索引。
6.4 研究工具
Google 不仅是高质量的搜索引擎,它还是研究工具。Google搜集的数据已经用在许多其它论文中,提交给学术会议和许多其它方式。最近的研究,例如,提出了 Web查询的局限性,不需要网络就可以回答。这说明Google不仅是重要的研究工具,而且必不可少,应用广泛。我们希望Google是全世界研究者的资源,带动搜索引擎技术的更新换代。
7、致谢
Scott Hassan and Alan Steremberg评价了Google的改进。他们的才智无可替代,作者由衷地感谢他们。感谢Hector Garcia-Molina,Rajeev Motwani, Jeff Ullman, and Terry Winograd和全部WebBase开发组的支持和富有深刻见解的讨论。最后感谢IBM,Intel,Sun和投资者的慷慨支持,为我们提供设备。这里所描述的研究是Stanford综合数字图书馆计划的一部分,由国家科学自然基金支持,合作协议号IRI-9411306。DARPA ,NASA,Interva研究,Stanford数字图书馆计划的工业合作伙伴也为这项合作协议提供了资金。
参考
【1】S. Abitehouland V. Vianu,
Queriesand computation on the Web.
in: Proceeding.c of’ the International Conference onDatabase Thery Delphi. Greece, 1997.
【2】J. Cho, H.Garcia-Molina and L. Page.
Efficient crawling through URL ordering.
in: Proc. of’ the 7th Internaitional World Wide WebConfereru (WWW 98). Brisbane. Australia.
April l4-18, 1998: also Compact.Networks ISDNSystem 30( l-7): 161-172 (this volume).
【3】J. Kleinberg.
Authoritativesources in a hyperlinked environment,
in: Proc. ACM-SIAM Synposium on Discrrtret algorifhm.1998.
【4】M. Marchiori.
Thequest for correct information on the Web: hyper search engines,
in: Prvc. of the 6th International WWW Conference (WWW 97). Santa Clara. USA,
AIpril 7-l I, 1997.
【5】Mauldin. M.L..
Lycosdesign choices in an Internet search service.
IEEE Expert Interview. http://www.computer.org/pubs/export/l997/trends/xl1008/mauldin.htm
【6】O-A. McBryan,
GENVLand WWWW: tools for taming the Web.
in: Proc of the 1st InternationalConference on the World Wide Web,
CERN Geneva,Swizerland,May 25-27, 1994 http://www.cs.colorado.edu/home/mcbryan/mypapers/www94.ps
【7】L. Page. S.Brin, R. Motwani and T. Winograd.
The PageRankcitation ranking: bringing order to the Web,
Manuscript in Progress.http://google.stanford.edu/-backrub/pageranksub.ps
【8】B.Pinkerton.
Findingwhat people want: experiences with the Web Crawler.
in: Proc. of thr 2nd Internationd WWW Conference,Chicago, USA, October 17-20 ,1994,
http://info.webcrawler.com/bp/WWW94.html
【9】E. Spertus.
Parasite: mining structural information on the Web,
in: Proc. of‘ the 6th lnternartional WWW Confernce (WWW 97). Santa Clara. USA, April 7-l I. 1997.
【10】D.K. Harman andE.M. Voorhees (Eds.).
Proceedings of fhr FIfth Text REtrieval Conference(TREC-5). Gaithersburg. Maryland, Novermber 20-22, 1996, Department ofCommerce. National Institute of Standards and Technology. 1996: full text at http://trec.nist.gov/
【11】I.H.Witten. A.Moffat. And T.C.Bell.
Managing Gigabytes: Compressing and Indexing Documents and Imanges.
Van Nostrand Reinhold, New York, NY, 1994
(Not End)