Kaggle数据集之电信客户流失数据分析(三)之决策树分类
一、导入数据
import pandas as pd
df=pd.read_csv(r"D:\PycharmProjects\ku_pandas\WA_Fn-UseC_-Telco-Customer-Churn.csv")
df| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | ... | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | ... | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7038 | 6840-RESVB | Male | 0 | Yes | Yes | 24 | Yes | Yes | DSL | Yes | ... | Yes | Yes | Yes | Yes | One year | Yes | Mailed check | 84.80 | 1990.5 | No |
| 7039 | 2234-XADUH | Female | 0 | Yes | Yes | 72 | Yes | Yes | Fiber optic | No | ... | Yes | No | Yes | Yes | One year | Yes | Credit card (automatic) | 103.20 | 7362.9 | No |
| 7040 | 4801-JZAZL | Female | 0 | Yes | Yes | 11 | No | No phone service | DSL | Yes | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.60 | 346.45 | No |
| 7041 | 8361-LTMKD | Male | 1 | Yes | No | 4 | Yes | Yes | Fiber optic | No | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 74.40 | 306.6 | Yes |
| 7042 | 3186-AJIEK | Male | 0 | No | No | 66 | Yes | No | Fiber optic | Yes | ... | Yes | Yes | Yes | Yes | Two year | Yes | Bank transfer (automatic) | 105.65 | 6844.5 | No |
7043 rows × 21 columns
本数据集描述了电信用户是否流失以及其相关信息,共包含7043条数据,共21个字段,分别介绍如下:
- customerID : 用户ID
- gender:性别(Female & Male)
- SeniorCitizen :老年用户(1表示是,0表示不是)
- Partner :伴侣用户(Yes or No)
- Dependents :亲属用户(Yes or No)
- tenure : 在网时长(0-72月)
- PhoneService : 是否开通电话服务业务(Yes or No)
- MultipleLines: 是否开通了多线业务(Yes 、No or No phoneservice 三种)
- InternetService:是否开通互联网服务(No, DSL数字网络,fiber optic光纤网络 三种)
- OnlineSecurity:是否开通网络安全服务(Yes,No,No internetserive 三种)
- OnlineBackup:是否开通在线备份业务(Yes,No,No internetserive 三种)
- DeviceProtection:是否开通了设备保护业务(Yes,No,No internetserive 三种)
- TechSupport:是否开通了技术支持服务(Yes,No,No internetserive 三种)
- StreamingTV:是否开通网络电视(Yes,No,No internetserive 三种)
- StreamingMovies:是否开通网络电影(Yes,No,No internetserive 三种)
- Contract:签订合同方式(按月,一年,两年)
- PaperlessBilling:是否开通电子账单(Yes or No)
- PaymentMethod:付款方式(bank transfer,credit card,electronic check,mailed check)
- MonthlyCharges:月费用
- TotalCharges:总费用
- Churn:该用户是否流失(Yes or No)
二、数据描述分析
1. 查看数据
df.shape #显示数据的格式(7043, 21)
df.dtypes #输出每一列对应的数据类型customerID object
gender object
SeniorCitizen int64
Partner object
Dependents object
tenure int64
PhoneService object
MultipleLines object
InternetService object
OnlineSecurity object
OnlineBackup object
DeviceProtection object
TechSupport object
StreamingTV object
StreamingMovies object
Contract object
PaperlessBilling object
PaymentMethod object
MonthlyCharges float64
TotalCharges object
Churn object
dtype: object
df.isnull().sum().values.sum() #查找缺失值0
df.nunique() #查看每一列有几个不同值customerID 7043
gender 2
SeniorCitizen 2
Partner 2
Dependents 2
tenure 73
PhoneService 2
MultipleLines 3
InternetService 3
OnlineSecurity 3
OnlineBackup 3
DeviceProtection 3
TechSupport 3
StreamingTV 3
StreamingMovies 3
Contract 3
PaperlessBilling 2
PaymentMethod 4
MonthlyCharges 1585
TotalCharges 6531
Churn 2
dtype: int64
# 查看表格某列中有多少个不同值,并计算每个不同值在该列中有多少重复值
df.Churn.value_counts() #value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用No 5174
Yes 1869
Name: Churn, dtype: int64
说明一共有1869个流失客户,5174个非流失客户
2. 数据清洗
(1). 简化属性值
- 将InternetService中的DSL数字网络,fiber optic光纤网络替换为Yes
- 将MultipleLines中的No phoneservice替换成No
- 将TotalCharges转换为数字型
# 将InternetService中的DSL数字网络,fiber optic光纤网络替换为Yes
# 将MultipleLines中的No phoneservice替换成No
replace_list=['OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies']
for i in replace_list:
df[i]=df[i].str.replace('No internet service','No')
df['InternetService']=df['InternetService'].str.replace('Fiber optic','Yes')
df['InternetService']=df['InternetService'].str.replace('DSL','Yes')
df['MultipleLines']=df['MultipleLines'].str.replace('No phone service','No')
# 将TotalCharges转换为数字型
df.TotalCharges=pd.to_numeric(df.TotalCharges,errors="coerce") #.to_numeric()将参数转换为数字类型,其中coerce表示无效的解析将设置为NaN
df.TotalCharges.dtypesdtype('float64')
3. 数据可视化
具体见
- Kaggle数据集之电信客户流失数据分析(一)
- Kaggle数据集之电信客户流失数据分析(二)
三、用决策树分类
根据(二)中的可视化结果,有11个特征与客户流失率的高低相关,分别是
- SeniorCitizen :是否老年用户
- Partner :是否伴侣用户
- Dependents :是否亲属用户
- tenure: 在网时长
- InternetService:是否开通互联网服务
- OnlineSecurity:是否开通网络安全服务
- TechSupport:是否开通了技术支持服务
- Contract:签订合同方式 (按月,一年,两年)
- PaperlessBilling:是否开通电子账单(Yes or No)
- PaymentMethod:付款方式(bank transfer,credit card,electronic check,mailed check)
- MonthlyCharges:月费用
接下来通过样本数据训练一个决策树模型,使模型能够根据输入特征预测客户是否为潜在的流失对象。
1. 特征工程
df| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No | Yes | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | Yes | Yes | ... | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.50 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | Yes | Yes | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No | Yes | Yes | ... | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Yes | No | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7038 | 6840-RESVB | Male | 0 | Yes | Yes | 24 | Yes | Yes | Yes | Yes | ... | Yes | Yes | Yes | Yes | One year | Yes | Mailed check | 84.80 | 1990.50 | No |
| 7039 | 2234-XADUH | Female | 0 | Yes | Yes | 72 | Yes | Yes | Yes | No | ... | Yes | No | Yes | Yes | One year | Yes | Credit card (automatic) | 103.20 | 7362.90 | No |
| 7040 | 4801-JZAZL | Female | 0 | Yes | Yes | 11 | No | No | Yes | Yes | ... | No | No | No | No | Month-to-month | Yes | Electronic check | 29.60 | 346.45 | No |
| 7041 | 8361-LTMKD | Male | 1 | Yes | No | 4 | Yes | Yes | Yes | No | ... | No | No | No | No | Month-to-month | Yes | Mailed check | 74.40 | 306.60 | Yes |
| 7042 | 3186-AJIEK | Male | 0 | No | No | 66 | Yes | No | Yes | Yes | ... | Yes | Yes | Yes | Yes | Two year | Yes | Bank transfer (automatic) | 105.65 | 6844.50 | No |
7043 rows × 21 columns
第一类特征的数据内容为:‘yes’ or ‘no‘
目前属于这类特征的变量有:‘Partner’, ‘Dependents’,‘InternetService’,‘OnlineSecurity’, ‘TechSupport’,‘PaperlessBilling’, ‘Churn’。可以直接采用0-1变量进行编码。其中’1‘代表’yes‘,’0‘代表’no‘
Te_data=df
#将'Partner', 'Dependents','InternetService','OnlineSecurity', 'TechSupport','PaperlessBilling', 'Churn'转化为0-1编码
SeniorCitizen=list(Te_data['SeniorCitizen'])
Partner=list(Te_data['Partner'])
Dependents=list(Te_data['Dependents'])
InternetService=list(Te_data['InternetService'])
OnlineSecurity=list(Te_data['OnlineSecurity'])
TechSupport=list(Te_data['TechSupport'])
PaperlessBilling=list(Te_data['PaperlessBilling'])
Churn=list(Te_data['Churn'])
for i in range(Te_data.shape[0]):
if Partner[i]=='Yes':
Partner[i] = 1
else :
Partner[i] = 0
if Dependents[i]=='Yes':
Dependents[i] = 1
else :
Dependents[i] = 0
if InternetService[i]=='Yes':
InternetService[i] = 1
else :
InternetService[i] = 0
if OnlineSecurity[i]=='Yes':
OnlineSecurity[i] = 1
else :
OnlineSecurity[i] = 0
if TechSupport[i]=='Yes':
TechSupport[i] = 1
else :
TechSupport[i] = 0
if PaperlessBilling[i]=='Yes':
PaperlessBilling[i] = 1
else :
PaperlessBilling[i] = 0
if Churn[i]=='Yes': #流失客户为1
Churn[i] = 1
else :
Churn[i] = 0第二类特征的数据为标称型数据
标称型数据只提供了足够信息区分对象,而本身不具有任何顺序或数值计算的意义。目前属于这类特征的变量有:‘Contract’、‘PaymentMethod’。这类变量采用One-Hot的方式进行编码,构造虚拟变量。
Contract=Te_data['Contract']
Contract_dummies=pd.get_dummies(Contract)
PaymentMethod=Te_data['PaymentMethod']
PaymentMethod_dummies=pd.get_dummies(PaymentMethod)
PaymentMethod_dummies| Bank transfer (automatic) | Credit card (automatic) | Electronic check | Mailed check | |
|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 0 | 1 |
| 3 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... |
| 7038 | 0 | 0 | 0 | 1 |
| 7039 | 0 | 1 | 0 | 0 |
| 7040 | 0 | 0 | 1 | 0 |
| 7041 | 0 | 0 | 0 | 1 |
| 7042 | 1 | 0 | 0 | 0 |
7043 rows × 4 columns
第三类特征是数值型
数值型数据具备顺序以及加减运算的意义,目前属于这类特征的变量有:tenure,MonthlyCharges。
可以采用连续特征离散化的处理方式,因为离散化后的特征对异常数据有更强的鲁棒性,可以降低过拟合的风险,使模型更稳定,预测的效果也会更好。
数据离散化也称为分箱操作,其方法分为有监督分箱(卡方分箱、最小熵法分箱)和无监督分箱(等频分箱、等距分箱)。这里采用无监督分箱中的等频分箱进行操作。
tenure=list(Te_data['tenure'])
tenure_cats=pd.qcut(tenure,6)
tenure_dummies=pd.get_dummies(tenure_cats)
MonthlyCharges=list(Te_data['MonthlyCharges'])
MonthlyCharges_cats=pd.qcut(MonthlyCharges,5)
MonthlyCharges_dummies=pd.get_dummies(MonthlyCharges_cats)
tenure_dummies| (-0.001, 4.0] | (4.0, 14.0] | (14.0, 29.0] | (29.0, 47.0] | (47.0, 64.0] | (64.0, 72.0] | |
|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... |
| 7038 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7039 | 0 | 0 | 0 | 0 | 0 | 1 |
| 7040 | 0 | 1 | 0 | 0 | 0 | 0 |
| 7041 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7042 | 0 | 0 | 0 | 0 | 0 | 1 |
7043 rows × 6 columns
MonthlyCharges_dummies| (18.249, 25.05] | (25.05, 58.83] | (58.83, 79.1] | (79.1, 94.25] | (94.25, 118.75] | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... |
| 7038 | 0 | 0 | 0 | 1 | 0 |
| 7039 | 0 | 0 | 0 | 0 | 1 |
| 7040 | 0 | 1 | 0 | 0 | 0 |
| 7041 | 0 | 0 | 1 | 0 | 0 |
| 7042 | 0 | 0 | 0 | 0 | 1 |
7043 rows × 5 columns
2. 得到输入、输出特征
将所有输入合并,最终得到模型的输入特征以及1个输出特征。
import numpy as np
#模型输出y
Churn_y=np.array(Churn).reshape(-1,1) #.reshape转换成1列
#模型输入x:'SeniorCitizen', 'Partner', 'Dependents','InternetService','OnlineSecurity', 'TechSupport','PaperlessBilling','Contract','PaymentMethod','tenure',MonthlyCharges
SeniorCitizen_x=np.array(SeniorCitizen).reshape(-1,1)
Partner_x=np.array(Partner).reshape(-1,1)
Dependents_x=np.array(Dependents).reshape(-1,1)
InternetService_x=np.array(InternetService).reshape(-1,1)
OnlineSecurity_x=np.array(OnlineSecurity).reshape(-1,1)
TechSupport_x=np.array(TechSupport).reshape(-1,1)
PaperlessBilling_x=np.array(PaperlessBilling).reshape(-1,1)
Contract_x=Contract_dummies.values
PaymentMethod_x=PaymentMethod_dummies.values
tenure_x=tenure_dummies.values
MonthlyCharges_x=MonthlyCharges_dummies.values
X=np.concatenate([SeniorCitizen_x,Partner_x,Dependents_x,InternetService_x,OnlineSecurity_x,TechSupport_x,TechSupport_x,Contract_x,PaymentMethod_x,tenure_x,MonthlyCharges_x],axis=1)
至此,输入矩阵X是1个只包含0,1的矩阵。
3. 训练与测试
模型直接使用scikit-learn中的DecisionTreeClassifier实现:
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 产生训练和测试样本,测试样本比例为30%
x_train, x_test, y_train, y_test = train_test_split(X, Churn_y, test_size=0.3, random_state=42)
# 构建模型
tree = DecisionTreeClassifier(max_depth=6,random_state=0) #树的深度设置为6
dt_tree=tree.fit(x_train,y_train)
#评估模型使用十次交叉验证
score = cross_val_score(tree, X, Churn_y, cv=10, scoring='accuracy')
print("training set score:{:.3f}".format(tree.score(x_train,y_train)))
print("test set score:{:.3f}".format(tree.score(x_test,y_test)))
print("ten cross-validation score:{:.3f}".format(np.mean(score)))
print("Feature importances : \n{}".format(tree.feature_importances_)) ##系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大training set score:0.797
test set score:0.780
ten cross-validation score:0.789
Feature importances :
[1.30884609e-02 7.46172977e-03 2.65487591e-03 6.18699745e-02
3.03670616e-02 1.79474957e-03 4.03171408e-03 5.33581539e-01
5.75912046e-03 1.52947662e-02 6.16748742e-03 3.26401250e-03
1.06356948e-01 9.07157615e-05 8.69506935e-02 1.82148495e-02
4.46274400e-03 1.92808846e-03 1.95735200e-03 0.00000000e+00
1.81965175e-02 3.19784327e-02 0.00000000e+00 0.00000000e+00
4.45281658e-02]
DecisionTreeClassifier()函数
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
函数为创建一个决策树模型,其函数的参数含义如下所示:
- criterion: gini或者entropy,前者是基尼系数,后者是信息熵,默认是gini,即CART算法
- splitter: best or random 前者是在所有特征中找最好的切分点,后者是随机的在部分划分点中找局部最优的划分点,默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。
- max_features:None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
- max_depth: int or None, optional (default=None) 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。
- min_samples_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_leaf_nodes: 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。
- class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。不适用于回归树。
- min_impurity_split: 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
由结果可知,训练集的拟合优度为0.797,测试集的拟合优度为0.780,10次交叉验证的平均得分为0.789,说明当前输入特征对模型目标的解释性较强,预测效果较好。
train_test_split函数
用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签。
- 格式:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.3, random_state=0)
参数解释:
- train_data:被划分的样本特征集
- train_target:被划分的样本标签
- test_size:如果是浮点数,在0-1之间,表示样本占比;如果是整数的话就是样本的数量
- random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
4. 预测新数据
对于新的与原始数据格式相同的数据,如何根据建立的模型直接给出预测的分类。
- 需要特别注意:对于数值型数据的分箱操作一定要与建立模型的相同,不能直接基于待预测数据继续采用等频分箱的操作。
# 读取待预测数据组成的xlsx文件
import pandas as pd
new_df=pd.read_csv(r"D:/PycharmProjects/ku_pandas/newdata.csv")
# 将上面的过程重来一遍
# 简化属性值
# 将InternetService中的DSL数字网络,fiber optic光纤网络替换为Yes
# 将MultipleLines中的No phoneservice替换成No
replace_list=['OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies']
for i in replace_list:
new_df[i]=new_df[i].str.replace('No internet service','No')
new_df['InternetService']=new_df['InternetService'].str.replace('Fiber optic','Yes')
new_df['InternetService']=new_df['InternetService'].str.replace('DSL','Yes')
new_df['MultipleLines']=new_df['MultipleLines'].str.replace('No phone service','No')
# 将TotalCharges转换为数字型
new_df.TotalCharges=pd.to_numeric(new_df.TotalCharges,errors="coerce") #.to_numeric()将参数转换为数字类型,其中coerce表示无效的解析将设置为NaN
# 特征工程
#将'Partner', 'Dependents','InternetService','OnlineSecurity', 'TechSupport','PaperlessBilling', 'Churn'转化为0-1编码
SeniorCitizen=list(new_df['SeniorCitizen'])
Partner=list(new_df['Partner'])
Dependents=list(new_df['Dependents'])
InternetService=list(new_df['InternetService'])
OnlineSecurity=list(new_df['OnlineSecurity'])
TechSupport=list(new_df['TechSupport'])
PaperlessBilling=list(new_df['PaperlessBilling'])
Churn=list(new_df['Churn'])
for i in range(new_df.shape[0]):
if Partner[i]=='Yes':
Partner[i] = 1
else :
Partner[i] = 0
if Dependents[i]=='Yes':
Dependents[i] = 1
else :
Dependents[i] = 0
if InternetService[i]=='Yes':
InternetService[i] = 1
else :
InternetService[i] = 0
if OnlineSecurity[i]=='Yes':
OnlineSecurity[i] = 1
else :
OnlineSecurity[i] = 0
if TechSupport[i]=='Yes':
TechSupport[i] = 1
else :
TechSupport[i] = 0
if PaperlessBilling[i]=='Yes':
PaperlessBilling[i] = 1
else :
PaperlessBilling[i] = 0
if Churn[i]=='Yes': #流失客户为1
Churn[i] = 1
else :
Churn[i] = 0
# 标称型数据
Contract=new_df['Contract']
Contract_dummies=pd.get_dummies(Contract)
PaymentMethod=new_df['PaymentMethod']
PaymentMethod_dummies=pd.get_dummies(PaymentMethod)
# 数值型数据按照之前建立的模型进行分箱
tenure=list(new_df['tenure'])
tenure_cut=[-0.001,4,14,29,47,64,72]
tenure_cats=pd.cut(tenure,tenure_cut)
tenure_dummies=pd.get_dummies(tenure_cats)
MonthlyCharges=list(new_df['MonthlyCharges'])
MonthlyCharges_cut=[18.249,,25.05,58.83,79.1,94.25,118.75]
MonthlyCharges_cats=pd.qcut(MonthlyCharges,MonthlyCharges_cut)
MonthlyCharges_dummies=pd.get_dummies(MonthlyCharges_cats)
tenure_dummies| (-0.001, 4.0] | (4.0, 14.0] | (14.0, 29.0] | (29.0, 47.0] | (47.0, 64.0] | (64.0, 72.0] | |
|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7 | 0 | 1 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 1 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 1 | 0 |
| 10 | 0 | 1 | 0 | 0 | 0 | 0 |
| 11 | 0 | 0 | 1 | 0 | 0 | 0 |
| 12 | 0 | 0 | 0 | 0 | 1 | 0 |
| 13 | 0 | 0 | 0 | 0 | 1 | 0 |
| 14 | 0 | 0 | 1 | 0 | 0 | 0 |
| 15 | 0 | 0 | 0 | 0 | 0 | 1 |
| 16 | 0 | 0 | 0 | 0 | 1 | 0 |
| 17 | 0 | 0 | 0 | 0 | 0 | 1 |
| 18 | 0 | 1 | 0 | 0 | 0 | 0 |
import numpy as np
#模型输出y
Churn_y=np.array(Churn).reshape(-1,1) #.reshape转换成1列
#模型输入x:'SeniorCitizen', 'Partner', 'Dependents','InternetService','OnlineSecurity', 'TechSupport','PaperlessBilling','Contract','PaymentMethod','tenure',MonthlyCharges
SeniorCitizen_x=np.array(SeniorCitizen).reshape(-1,1)
Partner_x=np.array(Partner).reshape(-1,1)
Dependents_x=np.array(Dependents).reshape(-1,1)
InternetService_x=np.array(InternetService).reshape(-1,1)
OnlineSecurity_x=np.array(OnlineSecurity).reshape(-1,1)
TechSupport_x=np.array(TechSupport).reshape(-1,1)
PaperlessBilling_x=np.array(PaperlessBilling).reshape(-1,1)
Contract_x=Contract_dummies.values
PaymentMethod_x=PaymentMethod_dummies.values
tenure_x=tenure_dummies.values
MonthlyCharges_x=MonthlyCharges_dummies.values
X=np.concatenate([SeniorCitizen_x,Partner_x,Dependents_x,InternetService_x,OnlineSecurity_x,TechSupport_x,TechSupport_x,Contract_x,PaymentMethod_x,tenure_x,MonthlyCharges_x],axis=1)
# 预测类别
y=dt_tree.predict(X)
yarray([1, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
5. 结果可视化与结论
由于X是array格式的,没有列名,首先将X转换为dateframe格式,再加上列名,并将其保存到xlsx表中。
# 首先将array转换为framedata
Te_X = pd.DataFrame(X)
# 加上列名
Te_X.columns=['SeniorCitizen', 'Partner', 'Dependents','InternetService','OnlineSecurity', 'TechSupport','PaperlessBilling',\
'Month-to-month','One year','Two year','Bank transfer (automatic)','Credit card (automatic)','Electronic check','Mailed check',\
'tenure_(0.999, 4.0]','tenure_(4.0, 14.0]','tenure_(14.0, 29.0]','tenure_(29.0, 47.0]','tenure_(47.0, 64.0]','tenure_(64.0, 72.0]',\
'MonthlyCharges_(18.249, 25.05]','MonthlyCharges_(25.05, 58.92]','MonthlyCharges_(58.92, 79.15]','MonthlyCharges_(79.15, 94.3]','MonthlyCharges_(94.3, 118.75]']
Te_X| SeniorCitizen | Partner | Dependents | InternetService | OnlineSecurity | TechSupport | PaperlessBilling | Month-to-month | One year | Two year | ... | tenure_(4.0, 14.0] | tenure_(14.0, 29.0] | tenure_(29.0, 47.0] | tenure_(47.0, 64.0] | tenure_(64.0, 72.0] | MonthlyCharges_(18.249, 25.05] | MonthlyCharges_(25.05, 58.92] | MonthlyCharges_(58.92, 79.15] | MonthlyCharges_(79.15, 94.3] | MonthlyCharges_(94.3, 118.75] | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7038 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 7039 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 7040 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 7041 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 7042 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
7043 rows × 25 columns
# 同理对Churn_y
Churn_y=pd.DataFrame(Churn_y,columns=['Churn'])
Churn_y| Churn | |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 1 |
| 3 | 0 |
| 4 | 1 |
| ... | ... |
| 7038 | 0 |
| 7039 | 0 |
| 7040 | 0 |
| 7041 | 1 |
| 7042 | 0 |
7043 rows × 1 columns
# 保存dataframe数据到xlsx文件
Te_X.to_excel("tree_data.xlsx", index=0)
Churn_y.to_excel("tree_Y.xlsx", index=0)特征重要性可视化
#特征重要性可视化
import matplotlib.pyplot as plt
def plot_feature_importance(model):
n_features = Te_X.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(range(n_features),Te_X.columns[0:])
plt.xlabel('Features importance')
plt.ylabel('feature')
plot_feature_importance(tree)
plt.show()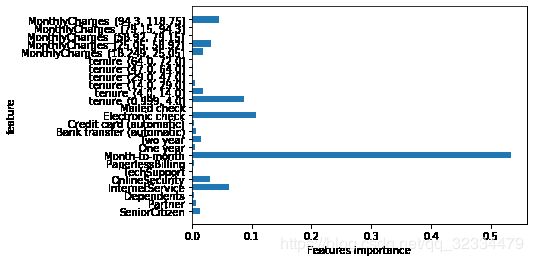
对于模型决策影响较大的指标包括:
- 合同期限是否为‘month to month’
- 顾客是否使用电子支票作为支付方式(electronic check)
- 顾客已使用的年限是否小于4个月
- 是否开通互联网服务(InternetService)
它们都能较好的反映流失客户与非流失客户的区别,从而使模型做出正确的分类。我们也可以将决策树可视化,进一步了解模型的决策过程:
决策树可视化及结论
#决策树可视化
from sklearn.tree import export_graphviz
export_graphviz(tree,out_file='te_tree.dot',class_names=['Churn_yes','Churn_no'],feature_names=Te_X.columns[0:],impurity=False,filled=True)
import graphviz
with open("te_tree.dot") as f:
dot_graph=f.read()
graph=graphviz.Source(dot_graph)
graph.render("tree")'tree.pdf'
决策树以month to month为根节点,左子树几乎均为非流失客户,因此研究右子树更有意义。由于决策树过大,这里只展示局部子树,并从决策过程中得出结论给出建议。
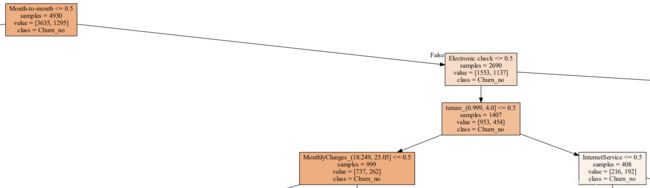
由上图可知,用于建立决策树的样本一共有4930个,其中签订合同方式按月的客户有2690个,其中非流失客户(Churn_no)1553个,流失客户(Churn_yes)1137个。对于签订合同方式按月、付款方式不是electronic check且在网时长不超过4个月的客户,有如下决策子树:

以上子树从是否为网络服务使用者这一分类特征的用户群体发展而来。其中红色系格子和白色格子代表非流失客户,蓝色系格子代表流失客户。可以明显发现,网络服务的使用者更有可能成为流失客户,除非其月费用不在(25.05,58.92]内且申请了网络安全这一附加服务。基于上述分析,给出一个运营建议:
建议1:对于签订合同方式按月、付款方式不是electronic check且在网时长不超过4个月的客户,当用户为网络服务的使用者时,推荐其开通网络安全方面的附加服务,防止其因基础网络问题而成为流失客户。
对于签订合同方式按月、付款方式是electronic check且在网时长超过4个月的客户,有如下决策子树:
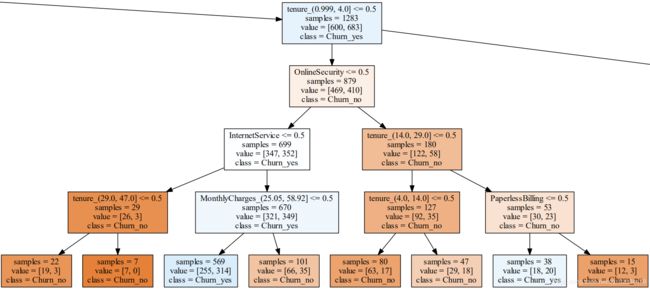
以上子树从是否开通网络安全服务这一分类特征的用户群体发展而来。红色系格子代表非流失客户,蓝色系格子代表流失客户。未开通网络安全服务但是开通了互联网服务的客户更有可能成为流失客户,除非其月消费达到(25.05,58.92]这个区间;开通了网络安全服务的客户基本不会成为流失客户,除非在网时长处于14到29个月,且未开通电子账单的用户。基于上述分析,给出一个运营建议:
建议2:对于签订合同方式按月、付款方式是electronic check且在网时长超过4个月的客户,当开通了网络安全服务且在网时长为14到29个月时,推荐其开通电子账单
对于签订合同方式按月、付款方式是electronic check且在网时长不超过4个月的客户,有如下决策子树:

以上子树从是否开通互联网服务这一分类特征的用户群体发展而来。选择开通互联网服务的客户更易成为流失客户,除非开通了网络安全服务且不是老年人;选择不开通互联网服务但是有孩子的客户更容易流失。基于上述分析,给出一个运营建议:
建议3:对于签订合同方式按月、付款方式是electronic check且在网时长不超过4个月的客户,当用户为网络服务的年轻使用者时,推荐其开通网络安全方面服务。
6. 总结
从整个决策树分析得出一些大致结论:
- 老年客户群体始终是容易发生流失行为的客户,需要及时关注了解其服务需求
- 合同期限越短(month-to-month)的用户越容易发生流失行为。因此需要通过各种优惠政策、活动尽可能与新用户签订一个长期的合同。
- 对于开通了网络服务的客户,应推荐其开通网络安全服务
参考文章:电信客户流失数据分析(二)