Kaggle数据集之电信客户流失数据分析(二)
上篇:Kaggle数据集之电信客户流失数据分析(一)
采用整体流失率作为标准,用于后面分析各维度的流失率做对比。
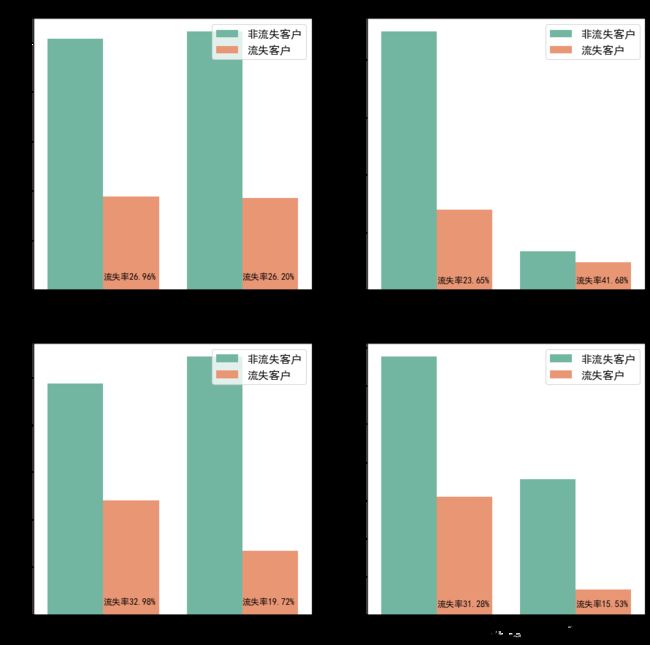
人口统计指标:‘gender’,‘SeniorCitizen’,‘Partner’,'Dependents’
fig,axes=plt.subplots(2,2,figsize=(15,15)) #画多子图,函数返回一个figure图像和子图axes的array列表
for i,j in enumerate(['gender','SeniorCitizen','Partner','Dependents']): #enumerate将数据对象组合为索引序列
plt.subplot(2,2,i+1) #i从0开始,子图的第i+1个图
ax=sns.countplot(x=j,hue='Churn',data=df,palette="Set2",order=df_Churn.groupby(j)['Churn'].value_counts().index.levels[0])
plt.title(str(j),fontsize=20)
plt.xlabel('Churn',fontsize=15)
plt.xticks(fontsize=15)
plt.legend(fontsize=15)
lent=df_Churn.groupby(j)['Churn'].value_counts().shape[0]
for p in range(lent):
Rate=df_Churn.groupby(j)['Churn'].value_counts()[p]/df.groupby(j,as_index=False)['Churn'].size()[p]
plt.text(p,100,'流失率{:.2%}'.format(Rate),fontsize=12)
i+=1
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
举例子理解groupby
例1
import pandas as pd
df1 = pd.DataFrame(data={'books':['bk1','bk1','bk1','bk2','bk2','bk3'], 'price': [12,12,12,15,15,17],'num':[2,1,1,4,2,2]})
print(df1)
print(df1.groupby('books',as_index=True).sum())
print(df1.groupby('books',as_index=False).sum())
print(df1.groupby('books',as_index=False)['num'].size()) #统计
print(df1.groupby('books',as_index=False)['price'].size()) books price num
0 bk1 12 2
1 bk1 12 1
2 bk1 12 1
3 bk2 15 4
4 bk2 15 2
5 bk3 17 2
price num
books
bk1 36 4
bk2 30 6
bk3 17 2
books price num
0 bk1 36 4
1 bk2 30 6
2 bk3 17 2
books
bk1 3
bk2 2
bk3 1
dtype: int64
books
bk1 3
bk2 2
bk3 1
dtype: int64
例2
df2 = pd.DataFrame({'A': ['a', 'b', 'a', 'c', 'a', 'c', 'b', 'c'],
'B': [2, 8, 1, 4, 3, 2, 5, 9],
'C': [102, 98, 107, 104, 115, 87, 92, 123]})
df2| A | B | C | |
|---|---|---|---|
| 0 | a | 2 | 102 |
| 1 | b | 8 | 98 |
| 2 | a | 1 | 107 |
| 3 | c | 4 | 104 |
| 4 | a | 3 | 115 |
| 5 | c | 2 | 87 |
| 6 | b | 5 | 92 |
| 7 | c | 9 | 123 |
df2.groupby('A').mean() #按A列分组,获取其他列的均值| B | C | |
|---|---|---|
| A | ||
| a | 2.0 | 108.000000 |
| b | 6.5 | 95.000000 |
| c | 5.0 | 104.666667 |
df2.groupby(['A','B']).mean() #按多列进行分组| C | ||
|---|---|---|
| A | B | |
| a | 1 | 107 |
| 2 | 102 | |
| 3 | 115 | |
| b | 5 | 92 |
| 8 | 98 | |
| c | 2 | 87 |
| 4 | 104 | |
| 9 | 123 |
g=df2.groupby('A')
g['B'].sum() #分组后选择列进行运算A
a 6
b 13
c 15
Name: B, dtype: int64
g.agg({'B':'mean','C':'sum'}) #针对不同的列选用不同的聚合方法,分组运算方法agg| B | C | |
|---|---|---|
| A | ||
| a | 2.0 | 324 |
| b | 6.5 | 190 |
| c | 5.0 | 314 |
例3:聚合方法size()和count()
统计本列中的元素出现频次
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
df3 = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
"City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
"Val":[4,3,3,np.nan,np.nan,4]})
df3| Name | City | Val | |
|---|---|---|---|
| 0 | Alice | Seattle | 4.0 |
| 1 | Bob | Seattle | 3.0 |
| 2 | Mallory | Portland | 3.0 |
| 3 | Mallory | Seattle | NaN |
| 4 | Bob | Seattle | NaN |
| 5 | Mallory | Portland | 4.0 |
df3.groupby(["Name","City"],as_index=False)['Val'].count()| Name | City | Val | |
|---|---|---|---|
| 0 | Alice | Seattle | 1 |
| 1 | Bob | Seattle | 1 |
| 2 | Mallory | Portland | 2 |
| 3 | Mallory | Seattle | 0 |
df3.groupby(["Name","City"],as_index=False)['Val'].size()Name City
Alice Seattle 1
Bob Seattle 2
Mallory Portland 2
Seattle 1
dtype: int64
df3.groupby(["Name","City"],as_index=False)['Val'].size().reset_index()| Name | City | 0 | |
|---|---|---|---|
| 0 | Alice | Seattle | 1 |
| 1 | Bob | Seattle | 2 |
| 2 | Mallory | Portland | 2 |
| 3 | Mallory | Seattle | 1 |
df3.groupby(["Name","City"],as_index=False)['Val'].size().reset_index(name='Size')| Name | City | Size | |
|---|---|---|---|
| 0 | Alice | Seattle | 1 |
| 1 | Bob | Seattle | 2 |
| 2 | Mallory | Portland | 2 |
| 3 | Mallory | Seattle | 1 |
- reset_index():重新分配索引
参考文章:groupby 的妙用(注意size和count)
将value_counts()和value_counts().index.levels打印出来
for i,j in enumerate(['gender']):
print (i,j)
print(1,df_Churn.groupby(j)['Churn'].value_counts()) #df_Churn=df[df['Churn']=='流失客户']
print(2,df_Churn.groupby(j)['Churn'].value_counts().index.levels)0 gender
1 gender Churn
Female 流失客户 939
Male 流失客户 930
Name: Churn, dtype: int64
2 [['Female', 'Male'], ['流失客户']]
sns.countplot()
即seaborn.countplot()
seaborn.countplot(x=None,y=None, hue=None, data=None, order=None,palette=None)
- x: x轴上的条形图,以x标签划分统计个数
- y: y轴上的条形图,以y标签划分统计个数
- hue: 在x或y标签划分的同时,再以hue标签划分统计个数
- data: DataFrame或array或array列表,用于绘图的数据集,x或y缺失时,data参数为数据集,同时x或y不可缺少,必须要有其中一个。
- order:对x或y的字段排序,排序的方式为列表
- palette:使用不同的调色板
Python数据可视化-seaborn库之countplot
结论1
- 性别对客户流失率无显著影响,与整体流失率相当
- 老年用户、未婚用户、非亲属用户的流失率比较高
用户活跃度:'tenure’
fig=plt.figure(num=3,figsize=(15,15))
ax1=fig.add_subplot(2,2,1)
ax1=sns.boxplot(df_Churn["tenure"],palette="Set2",orient="v") #箱线图,orient:"v"|"h" 用于控制图像是水平还是竖直显示
plt.title('流失用户在网时长')
ax2=fig.add_subplot(2,2,2)
ax2=sns.boxplot(df["tenure"],palette="Set2",orient="v")
plt.title('整体用户在网时长')
ax3=fig.add_subplot(2,2,3)
ax3=sns.countplot(x='tenure_group',hue='Churn',data=df,palette="Set2")
plt.title('流失用户在网时长分布')
grouped_values=df_Churn.groupby('tenure_group').sum().reset_index() #df_Churn=df[df['Churn']=='流失客户']
tenure_churn_per=df_Churn.groupby('tenure_group')['Churn'].count()/df_Churn.groupby('tenure_group')['Churn'].count().sum()
ax4=fig.add_subplot(2,2,4)
ax4=tenure_churn_per.plot(linestyle='dashed',marker='o')
ax4.axhline(y=Rate_Churn,ls=":",c="red") #绘制水平线
ax4.annotate(s='整体流失率均值{:.2%}'.format(Rate_Churn),xy=(0.28,0.25),fontsize=15)
plt.title('流失客户各在网时段流失率均值分布')
for index,row in grouped_values.iterrows():
plt.text(index+0.025,tenure_churn_per.values[index],'{:.2%}'.format(tenure_churn_per.values[index],2),fontsize=12)
df_Churn| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | ... | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | tenure_group | MonthlyCharges_group | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3668-QPYBK | Male | No | No | No | 2 | Yes | No | Yes | Yes | ... | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | 流失客户 | 0.5年 | 60 |
| 4 | 9237-HQITU | Female | No | No | No | 2 | Yes | No | Yes | No | ... | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | 流失客户 | 0.5年 | 80 |
| 5 | 9305-CDSKC | Female | No | No | No | 8 | Yes | Yes | Yes | No | ... | Yes | Yes | Month-to-month | Yes | Electronic check | 99.65 | 820.50 | 流失客户 | 1年 | 100 |
| 8 | 7892-POOKP | Female | No | Yes | No | 28 | Yes | Yes | Yes | No | ... | Yes | Yes | Month-to-month | Yes | Electronic check | 104.80 | 3046.05 | 流失客户 | 2.5年 | 120 |
| 13 | 0280-XJGEX | Male | No | No | No | 49 | Yes | Yes | Yes | No | ... | Yes | Yes | Month-to-month | Yes | Bank transfer (automatic) | 103.70 | 5036.30 | 流失客户 | 4.5年 | 120 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7021 | 1699-HPSBG | Male | No | No | No | 12 | Yes | No | Yes | No | ... | Yes | No | One year | Yes | Electronic check | 59.80 | 727.80 | 流失客户 | 1年 | 60 |
| 7026 | 8775-CEBBJ | Female | No | No | No | 9 | Yes | No | Yes | No | ... | No | No | Month-to-month | Yes | Bank transfer (automatic) | 44.20 | 403.35 | 流失客户 | 1年 | 60 |
| 7032 | 6894-LFHLY | Male | Yes | No | No | 1 | Yes | Yes | Yes | No | ... | No | No | Month-to-month | Yes | Electronic check | 75.75 | 75.75 | 流失客户 | 0.5年 | 80 |
| 7034 | 0639-TSIQW | Female | No | No | No | 67 | Yes | Yes | Yes | Yes | ... | Yes | No | Month-to-month | Yes | Credit card (automatic) | 102.95 | 6886.25 | 流失客户 | 6年 | 120 |
| 7041 | 8361-LTMKD | Male | Yes | Yes | No | 4 | Yes | Yes | Yes | No | ... | No | No | Month-to-month | Yes | Mailed check | 74.40 | 306.60 | 流失客户 | 0.5年 | 80 |
1869 rows × 23 columns
grouped_values| tenure_group | tenure | MonthlyCharges | TotalCharges | |
|---|---|---|---|---|
| 0 | 0.5年 | 1800 | 49896.10 | 121523.95 |
| 1 | 1年 | 2354 | 19058.15 | 177683.80 |
| 2 | 1.5年 | 2707 | 13614.45 | 206776.20 |
| 3 | 2年 | 2523 | 9467.20 | 203288.65 |
| 4 | 2.5年 | 2567 | 7837.15 | 214140.35 |
| 5 | 3年 | 2859 | 7330.80 | 243238.75 |
| 6 | 3.5年 | 3277 | 6994.85 | 276657.15 |
| 7 | 4年 | 2821 | 5299.70 | 241983.10 |
| 8 | 4.5年 | 3503 | 6069.45 | 312797.90 |
| 9 | 5年 | 2981 | 4512.45 | 258740.50 |
| 10 | 5.5年 | 2749 | 4133.05 | 265102.20 |
| 11 | 6年 | 3462 | 4917.50 | 340994.35 |
tenure_churn_pertenure_group
0.5年 0.419476
1年 0.135367
1.5年 0.094703
2年 0.062600
2.5年 0.050294
3年 0.046014
3.5年 0.044409
4年 0.033173
4.5年 0.036383
5年 0.027822
5.5年 0.023007
6年 0.026752
Name: Churn, dtype: float64
axhline()函数
ax4.axhline(y=Rate_Churn,ls=":",c=“red”)
函数功能: 绘制平行于x轴的水平参考线
调用签名: plt.axhline(y=0.0, c=“r”, ls="–", lw=2)
- y:水平参考线的出发点
- c:参考线的线条颜色
- ls:参考线的线条风格
- lw:参考线的线条宽度
- 平移性:上面的函数,同样适用于axvline()函数
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0.05, 10, 1000)
y = np.sin(x)
plt.plot(x, y, ls="-.", lw=2, c="c", label="plot figure")
plt.legend()
plt.axhline(y=0.0, c="r", ls="--", lw=2) #水平线
plt.axvline(x=4.0, c="r", ls="--", lw=2) #竖直线
plt.show()
annotate()函数
ax4.annotate(s=‘整体流失率均值{:.2%}’.format(Rate_Churn),xy=(0.28,0.25),fontsize=15)
annotate用于在图形上给数据添加文本注解,而且支持带箭头的划线工具,方便我们在合适的位置添加描述信息。
参考文章:Python学习笔记(4)——Matplotlib中的annotate(注解)的用法
iterrows()函数
python对dataframe处理时可用for循环中的迭代器dataframe.iterrows():
在语句
for index, rows in dataframe.iterrows():
可以调取dataframe里的index以及dataframe的每一行value进行迭代
plt.text()函数
plt.text(index+0.025,tenure_churn_per.values[index],’{:.2%}’.format(tenure_churn_per.values[index],2),fontsize=12)
给图形添加数据标签
plt.text(x,
y,
string,
fontsize=15,
verticalalignment=“top”,
horizontalalignment=“right”
)
-
x,y:表示坐标值上的值
-
string:表示说明文字
-
fontsize:表示字体大小
-
verticalalignment:垂直对齐方式 ,参数:[ ‘center’ | ‘top’ | ‘bottom’ | ‘baseline’ ]
-
horizontalalignment:水平对齐方式 ,参数:[ ‘center’ | ‘right’ | ‘left’ ]
箱线图
在箱线图中,箱子的中间有一条线,代表了数据的中位数。箱子的上下底,分别是数据的上四分位数(Q3)和下四分位数(Q1),这意味着箱体包含了50%的数据。因此,箱子的高度在一定程度上反映了数据的波动程度。上下边缘则代表了该组数据的最大值和最小值。有时候箱子外部会有一些点,可以理解为数据中的“异常值”。
- 偏态
与正态分布相对,指的是非对称分布的偏斜状态。在统计学上,众数和平均数之差可作为分配偏态的指标之一:如平均数大于众数,称为正偏态(或右偏态);相反,则称为负偏态(或左偏态)。或者看密度函数,尾巴在右侧是右偏,尾巴在左侧是左偏。
箱线图中,异常值集中在较大值一侧,则分布呈现右偏态;异常值集中在较小值一侧,则分布呈现左偏态
结论2
- 流失用户的在网时长较短,多为10个月,且呈右偏分布,整体用户在网时长呈正态分布
- 新用户在1年内的流失率高于整体流失率,因此如何在新用户1年期内通过各种优惠活动、政策留住用户是关键
消费产品指标
手机服务:‘PhoneService’,‘MultipleLines’
网络服务:
‘InternetService’,‘OnlineSecurity’,‘OnlineBackup’,‘DeviceProtection’,‘TechSupport’,‘StreamingTV’,‘StreamingMovies’
fig,axes=plt.subplots(3,3,figsize=(18,18))
for i,j in enumerate(['PhoneService','MultipleLines','InternetService','OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies']):
plt.subplot(3,3,i+1)
ax=sns.countplot(x=j,hue='Churn',data=df,palette='Set2',order=df_Churn.groupby(j)['Churn'].value_counts().index.levels[0])
plt.title(str(j),fontsize=15)
plt.xlabel('Churn',fontsize=10)
plt.xticks(fontsize=10)
lent=df_Churn.groupby(j)['Churn'].value_counts().shape[0]
for p in range(lent):
Rate=df_Churn.groupby(j)['Churn'].value_counts()[p]/df.groupby(j,as_index=False)['Churn'].size()[p]
plt.text(p,100,'流失率{:.2%}'.format(Rate),fontsize=12)
i+=1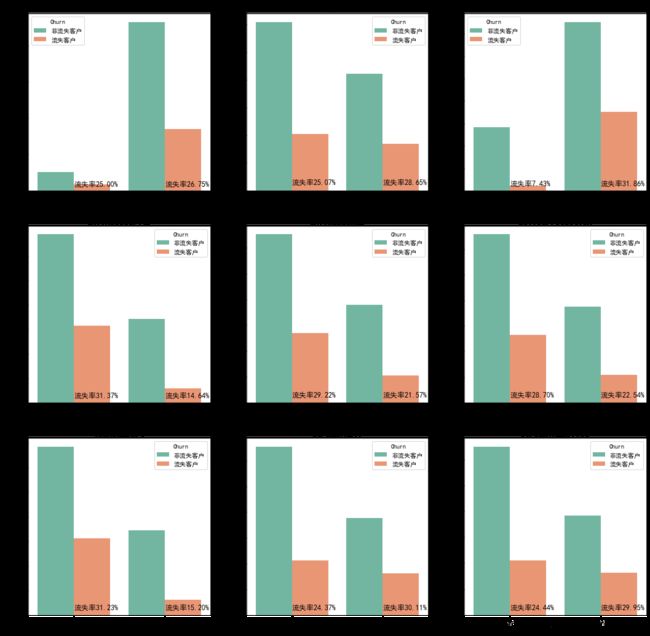
结论3
- 手机服务中,订购PhoneService的用户群流失率基本上与整体流失率(26.58%)持平,订购MultipleLines的流失率比整体流失率高
- 网络服务中
- 其中订购InternetService的用户流失率较整体流失率偏高
- 其中技术性服务(‘OnlineSecurity’,‘OnlineBackup’,‘DeviceProtection’,‘TechSupport’)中订购的用户流失率均比整体流失率低,而未订购的则高出整体流失率不少
- 其中在娱乐性服务(‘StreamingTV’,‘StreamingMovies’)上,订购的流失率比整体的流失率高
消费信息指标
收入指标
fig=plt.figure(num=5,figsize=(15,15))
ax1=fig.add_subplot(3,2,1)
ax1=sns.distplot(df.MonthlyCharges,hist=True,color='green')
ax1.set_ylim(0,0.032)
ax1.set_title("整体客户月消费分布")
ax2=fig.add_subplot(3,2,2)
ax2=sns.distplot(df.TotalCharges,hist=True,color='green')
ax2.set_title("整体客户总消费分布")
ax3=fig.add_subplot(3,2,3)
ax3=sns.distplot(df_Churn['MonthlyCharges'],hist=True)
ax1.set_ylim(0,0.032)
ax3.set_title("流失客户月消费分布")
ax4=fig.add_subplot(3,2,4)
ax4=sns.distplot(df_Churn['TotalCharges'],hist=True)
ax4.set_title("流失客户总消费分布")
grouped_values=df_Churn.groupby('MonthlyCharges_group').sum().reset_index()
MonthlyCharges_churn_per=df_Churn.groupby('MonthlyCharges_group')['Churn'].count()/df_Churn.groupby('MonthlyCharges_group')['Churn'].count().sum()
ax5=fig.add_subplot(3,2,5)
ax5=MonthlyCharges_churn_per.plot(linestyle='dashed', marker='o')
ax5.axhline(y=Rate_Churn,ls=":",c="red")
ax5.annotate(s='整体流失率均值{:.2%}'.format(Rate_Churn),xy=(0.28,0.25),fontsize=15)
plt.title('流失用户月消费流失率均值分布')
for index,row in grouped_values.iterrows():
plt.text(index+0.025,MonthlyCharges_churn_per.values[index],'{:.2%}'.format(MonthlyCharges_churn_per.values[index],2),fontsize=12)
收入相关指标
fig=plt.figure(num=6,figsize=(15,15))
for i ,j in enumerate(["Contract","PaperlessBilling",'PaymentMethod']):
plt.subplot(3,1,i+1)
ax=sns.countplot(x=j,hue='Churn',data=df,palette="Set2",order=df_Churn.groupby(j)['Churn'].value_counts().index.levels[0])
plt.title(str(j), fontsize=15)
plt.xlabel('Churn',fontsize=15)
plt.xticks(fontsize=10)
plt.legend(fontsize=10)
lent=df_Churn.groupby(j)['Churn'].value_counts().shape[0]
for p in range(lent):
Rate=df_Churn.groupby(j)['Churn'].value_counts()[p]/df.groupby(j,as_index=False)['Churn'].size()[p]
plt.text(p+0.1,100,'流失率{:.2%}'.format(Rate),fontsize=10)
i+=1
结论4
- 流失用户的主要来源是月消费80-100元的用户。
- 合同期限上,选择月签的用户流失率最高,达到42.7%,合同期限越长,流失越低。
- 选择无纸账单的用户流失率高于选择纸账单的用户。
- 支付上,选择Electronic check支付方式的用户流失最高,达到45%,其他三种流失率相差无几。
结论
以下用户群的流失率是高于整体流失率的:
- 用户维度:老人,单身,无亲属,在网时长小于10个月。
- 产品维度:开通多线服务,开通光纤网络,不开通技术性增值服务,开通娱乐性服务。
- 消费特征:月消费80-100元,选择月签,Electronic check支付。
参考文章:电信客户流失数据分析