python爬虫学习
文章目录
- 一、爬虫的分类
- 二、爬虫的准备工作
- 三、http协议
- 四、requests模块
- 1、使用步骤
- 2、requests get方法
- response对象
- 例子1:获取百度产品页面
- 例子2:获取新浪新闻页面
- 分页如何实现?
- 例子3:爬取贴吧中前十页的内容保存到本地
- 3.requests post请求
- 例子4:破解百度翻译,做到可以查询任意单词效果
- 五、数据的分类
- 1、分类
- (1)结构化数据:能用关系型数据库描述的数据
- (2)半结构化数据:拥有字描述结构数据
- (3)非结构化数据
- 2、json 数据
- (1)json 与 js 关系
- (2)json 数据的处理(重点)
- 六、cookie和session
- 1、什么是cookie和session?
- 2、cookie和session产生的原因:
- 3、cookie原理:
- 4、session原理:
- 5、常见误区:打开浏览器中的一个网页,浏览器关闭,这个网页的session会不会失效?
- 6、cookie的字段
- 7、会话cookie和持久cookie
- 8、用requests登录页面
- 例子5:人人网登录
- 七、代理使用方法
- 1、代理基本原理
- 2、代理的作用
- 3、在requests模块中如何设置代理
- 例子6:高德地图(获取所有城市的天气信息)
- 八、正则表达式
- (一)元字符
- (二)re模块
- 1、re模块使用步骤
- 2、pattern对象的方法
- (1)match方法
- (2)search方法
- (3)findall方法
- (4)finditer方法
- (5)split
- (6)sub
- 3、分组
- 4、贪婪非贪婪模式
- 5、万能正则匹配表达式:.*?
- 例子7:猫眼电影信息爬取
- 例子8:获取淘宝电场商品信息
- 九、Xml、XPath
- 1、什么是xml?
- 2、xml 和 html 的区别
- 3、xpath(语法)
- 4、lxml模块
- 例子9:扇贝单词
- 例子10.网易云音乐歌手信息爬取
- 十、动态html
- 1、反爬策略
- 2、页面中的技术
- 3、selenium 和 phantomjs
- 4、selenium基础知识
- 例子11:豆瓣读书
- 例子12:腾讯招聘
- 爬虫流程图
- 十一、多线程基础
- 1、程序、线程、进程
- 2、什么是多线程?
- 3、并行和并发
- 4、python中的threading模块
- (1)创建多线程的第一种方法
- (2)创建多线程的第二种方法
- 5、多线程和多进程
- 腾信招聘案例
- 单线程
- 多线程(1)
- 多线程(2)队列
- 生产者消费者模型
- 十二、MongoDB
- 1、安装教程
- 2、非关系型数据库和mongo的客户端服务端
- 3、mongo基础命令和插入命令
- MongoDB基础增删改查操作
- 1、增:insert方法
- 2、删除(行):remove
- 3、更新:update
- 4、查: find
- 5、查询表达式:
- 6、聚合 aggregate
- 游标操作
- 索引创建
- MongoDB数据的导入导出
- replaction复制集
- 二、Redis
- 1、数据结构丰富
- 2、可以持久化到硬盘。
一、爬虫的分类
爬虫可以分为通用爬虫和聚焦爬虫
1、通用爬虫:就是将互联网上的数据整体爬取下来保存到本地的一个爬虫程序,是搜索引擎的重要组成部分。
(1)搜索引擎:就是运用特定的算法和策略,从服务器上获取页面信息,并将信息保存到本地为用户提供检索服务的系统。
(2)搜索引擎的工作步骤:
- 第一步:抓取网页
- 第二步:数据存储
- 第三步:预处理
提取文字
中文分词
消除噪音(比如版权声明文字、导航条、广告等……)
除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。 - 第四步:提供检索服务,网站排名
2、聚焦爬虫:在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
二、爬虫的准备工作
(1)robots协议
定义:网络爬虫排除标准
作用:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
写爬虫程序要规避robots协议即可。
(2)网站地图sitemap
sitemap 就是网站地图, 它通过可视化的形式, 展示网站的主要结构。比如:列表页、分类页、tag页,以及内容页面。
网上有很多sitemap生成网站:https://help.bj.cn/
(3)估算网站的大小
可以使用搜索引擎来做,比如在百度中使用site:www.zhihu.com
三、http协议
http协议:超文本传输协议
作用:是一种收发html的【一种规范】。
http端口号:80
https : 安全版的http协议
https端口号:443
SSL(安全套接层)用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
数字签证
http协议的特点:
(1)应用层协议。(最顶层也是和用户交互的层。)
(2)无连接:http协议每次发送请求都是独立的。http 1.1以后有请求头:connection:keep_alive.
(3)无状态:http协议不记录状态,进而产生了两种记录http状态的技术:cookie 和 session。
url:统一资源定位符
-
主要作用:用来定位互联网上的任意资源的位置
-
url 组成:https://www.baidu.com/index.html?username=123&password=abc#top
(1)scheme:协议—https
(2)netloc : 网络地址:ip:port—www.baidu.com
通过ip定位电脑(网卡)
通过port定位应用。例如mysql(3306)、mogono
(3)path:资源路径
(4)query:请求参数:?后面的内容username=123&password=abc
(5)fragment:锚点----top -
url 中特殊符号:
?:get请求的参数在?后面
& : get请求的多个参数用&连接
# : 锚点,用来定位到页面中任意位置----如果url中有锚点,在爬虫程序中尽量去除。 -
python中用来解析 url 的模块。
from urllib import parse
url = https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=baidutop10&wd=python&oq=%25E7%25BA%25BD%25E7%25BA%25A6%25E5%25B7%259E%25E6%2596%25B0%25E5%25A2%259E7917%25E4%25BE%258B&rsv_pq=bf1978c40001323b&rsv_t=734dvlMHLeNpQvWiTURFFV%2BQ3xwarh7lmTJlBpNmlPeoioFYCukHcZwgQwbuDBaVvg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=6&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&inputT=1193&rsv_sug4=1193
result = parse.urlparse(url)
print(result.scheme)
print(result.netloc)
-
http工作过程:
(1)地址解析
(2)封装HTTP请求数据包
(3)封装成TCP包,建立TCP连接(TCP的三次握手)
(4)客户机发送请求命令
(5)服务器响应
(6)服务器关闭TCP连接 -
客户端请求
(1)组成:请求行、请求头、空行、请求数据(实体)四个部分组成
请求行:协议,url,请求方法
请求头:主要的作用就是来限定这个请求的详细信息。
请求数据:post请求的数据是放到这里面的。
(2)重要请求头
user-agent:客户端标识(身份)
cookie:请求的状态信息
referer:表示产生请求的网页来源于哪里(防盗链)
accept:允许传入的文件类型
x-requested-with:ajax请求必须要封装的头
(3)请求方法:
get/post/put(推送——delete(删除)——trace(诊断)——options(性能)——connect(连接,预留字段)
get方法:get获取–从服务器获取资源–条件(请求参数)—请求参数是拼接到url里面的?后面–不安全(容易被别人获取:用户名和密码)—大小受限。
post方法:post传递–向服务器传递数据–请求数据是放在实体里面。----安全—大小不受限 -
服务器响应
(1)组成:状态行:状态码、消息报头、空行、响应正文(html)
(2)响应头
Content-Type: text/html;charset=utf-8:响应的类型
(3)状态码(状态码)
1xx:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
2xx:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
3xx:为完成请求,客户需进一步细化请求。
4xx:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访)
5xx:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。 -
当我们在客户端输入一个url,客户端是如何请求加载出整个页面的?
(1)客户端解析url,封装数据包,发送请求给服务器。
(2)服务器从请求中解析出客户端想要内容,比如 index.html,然后把该页面封装成响应数据包,发送给客户端。
(3)客户端检查该 index.html 中是否有静态资源需要继续请求,比如 js,css,图片,如果有继续请求获取静态资源。
(4)客户端按照html的语法结合静态资源将页面完美的显示出来。
四、requests模块
1、使用步骤
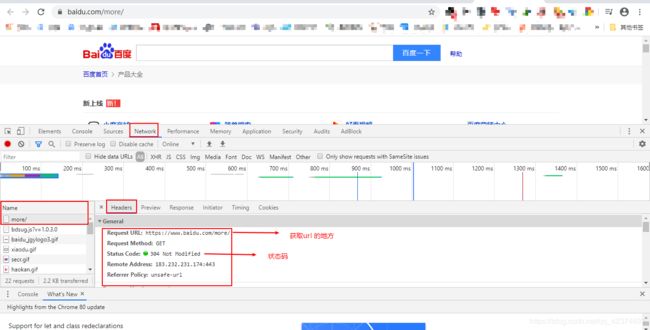
# 导包
import requests
# 确定待爬取的url
base_url = 'https://www.baidu.com/more/'
# 发送请求,获取响应
response = requests.get(base_url)
# 处理响应内容
print(response)
2、requests get方法
requests.get(
url=请求url,
headers =请求头字典,
params = 请求参数字典。
timeout = 超时时长,
)——>response对象
response对象
服务器响应包含:状态行(协议,状态码)、响应头,空行,响应正文
(1)响应正文:
- 字符串格式:response.text
- bytes类型:response.content
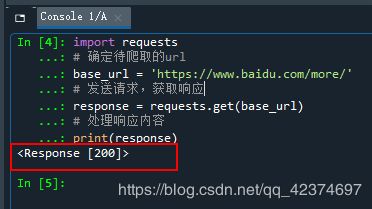
例子1:获取百度产品页面
import requests
# 确定待爬取的url
base_url = 'https://www.baidu.com/more/'
# 发送请求,获取响应
response = requests.get(base_url)
# 处理响应内容
print(response.text) #会出现乱码
#乱码产生的原因:编码和解码的编码格式不一致造成的
#str.encode('编码')---将字符串按指定编码解码成bytes类型
#bytes.decode('编码')---将bytes类型按指定编码编码成字符串。
# 响应正文的乱码问题解决
#第一种方法
response_str = response.content.decode('utf-8')
print(response_str)
#第二种方法
print(response.encoding) #ISO-8859-1
#如果response.text乱码了,可以先给response.encoding设置正确编码,在通过response.text就可以获取正确的页面内容。
response.encoding = 'utf-8'
response_str = response.text
print(response_str)
#保存
with open('index.html','w',encoding='utf-8') as fp:
fp.write(response_str)
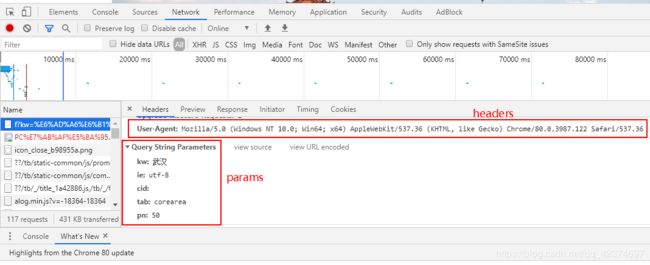
例子2:获取新浪新闻页面
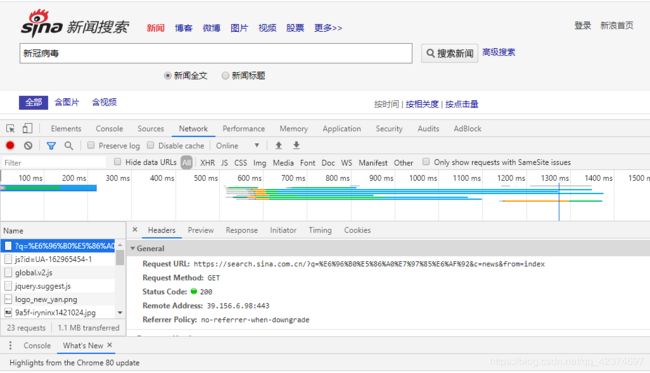
问号之前的(包括问号)为基础url
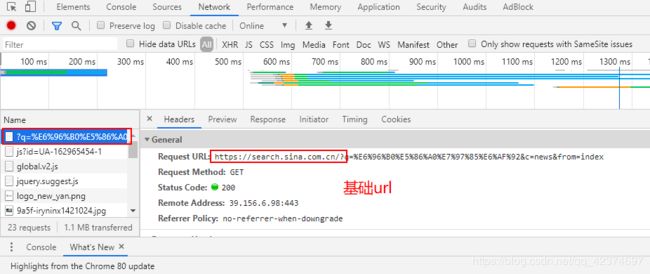
请求头:user-agent

完整的 url ,问号之后的就是 params
![]()
import requests
'''
模仿网页中的搜索功能,可以查看任意搜索内容的页面进行保存
'''
def main(kw):
# 1.确定待爬取的url
base_url = 'https://search.sina.com.cn/?'
# 2.发送请求,获取响应
# 准备参数
# 2.1 headers字典
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
}
# 2.2 params字典
# 问号之后的
params = {
'range':'all',
'c':'news',
'q': kw,
'from': 'home',
'ie':'utf-8',
}
response = requests.get(base_url,headers=headers,params=params)
# print(response.encoding)
response_str = response.text
with open('sina_news6.html','w',encoding='GB18030') as fp:
fp.write(response_str)
if __name__ == '__main__':
kw = input("输入搜索关键词:")
main(kw)
print()
print("搜索完成!")
也可以使用parse拼接,url中出现中文,必须将中文用url编码进行转码才可以
import requests
# 用parse对 url 转码
from urllib import parse
'''
对于get请求,我们直接也可以将参数完全拼接到url里面,直接请求url
url中出现中文,必须将中文用url编码进行转码才可以.
'''
def main(kw):
# 1、确定基础url
base_url = 'https://search.sina.com.cn/?'
# 2、发送请求,获取响应
# 准备参数
# 2.1 headers字典
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
# 2.2 params字典
params = {
'q': kw,
'c': 'news',
'from': 'channel',
'ie': 'utf-8',
}
# 通过拼接url的形式来进行请求
url_extend = parse.urlencode(params)
# print(url_extend)
# 完整的 url = 基础 url + 转码后的params
full_url = base_url+url_extend
response = requests.get(full_url,headers=headers)
response_str = response.text
with open('aaa.html','w',encoding='GB18030') as fp:
fp.write(response_str)
if __name__ == '__main__':
kw = input("输入搜索关键词:")
main(kw)
print()
print("搜索完成!")
(2)状态码:response.status_code
(3)响应头:response.headers
分页如何实现?
分页的请求的每一页url基本上都是通过get请求的一个请求参数决定的,所以分页主要是查看每页中,请求参数页码字段的变化,找到变化规律,用for循环就可以做到分页。
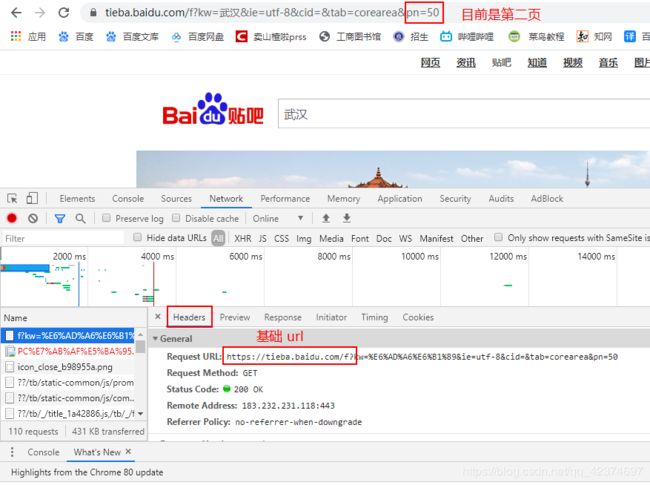
例子3:爬取贴吧中前十页的内容保存到本地
百度贴吧中第一页 参数:pn=0
百度贴吧中第二页 参数:pn=50
百度贴吧中第三页 参数:pn=100
…
import requests
import os
def main():
# 确定基础url
base_url = 'http://tieba.baidu.com/f?'
#准备参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
filename = './tieba/'+kw
# 实现页面保存到每个贴吧名称对应的文件夹中。
if not os.path.exists(filename):
#不存在创建文件夹
os.mkdir(filename)
for i in range(10):
# 页码值
pn = i*50
params = {
'kw': kw,
'ie': 'utf-8',
'tab': 'corearea',
'pn': pn,
}
# 发送请求,获取响应
response = requests.get(base_url,headers= headers,params=params)
with open(filename+'/'+str(i+1)+'.html','w',encoding='utf-8') as fp:
fp.write(response.text)
if __name__ == '__main__':
kw = '武汉'
main()
3.requests post请求
post请求一般返回数据都是json数据。
post请求与get请求又相似的地方
response = requests.post(
url = 请求url地址,
headers = 请求头字典,
data=请求数据字典,
timeout=超时时长,
)---response对象。
例子4:破解百度翻译,做到可以查询任意单词效果
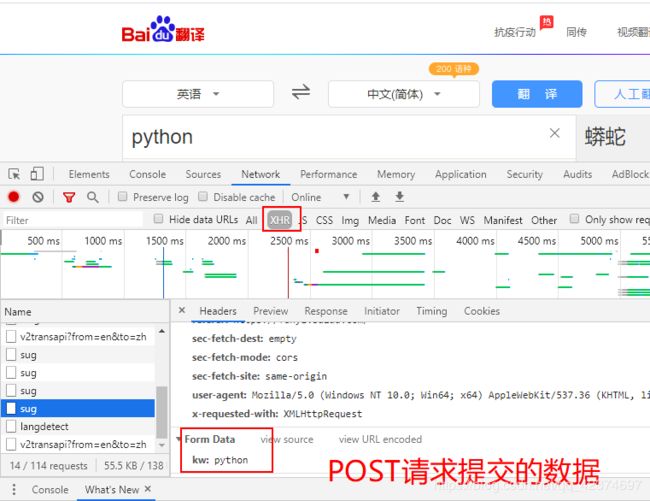
url
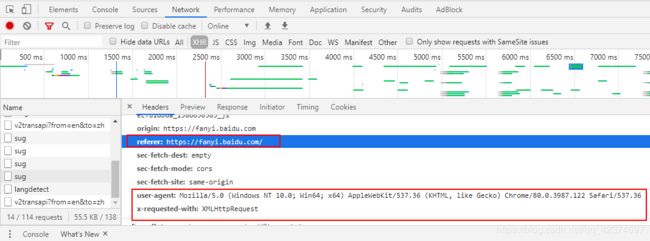
headers字典中需要放入的
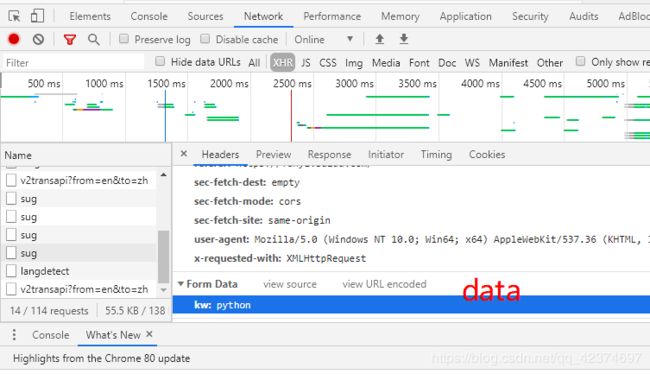
data
import requests
import json
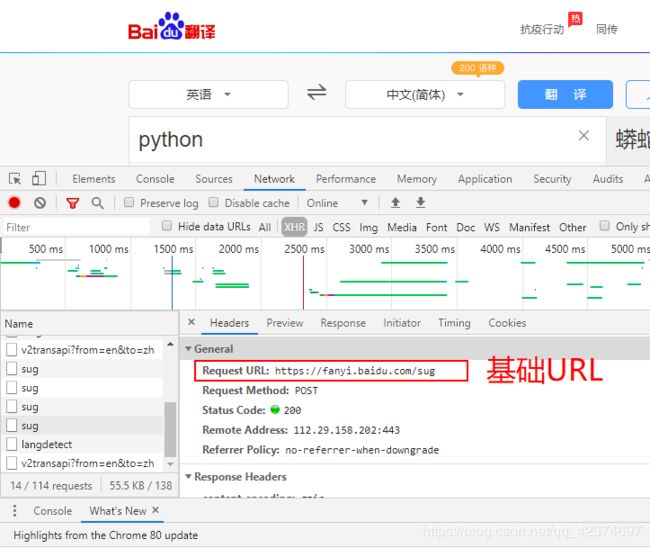
# 1、确定基础url
base_url = 'https://fanyi.baidu.com/sug'
# 2、发送请求,获取响应
# 准备参数
# 2.1 headers字典
headers = {
'content-length': '9',#POST请求数据的长度(字符的个数)
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'referer': 'https://fanyi.baidu.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
# 2.2 data
data = {
'kw': 'python'
}
response = requests.post(base_url, headers=headers, data=data)
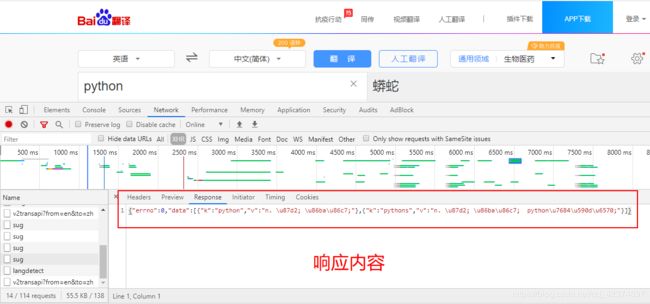
# 得到返回的json数据
print(response.text)
# {"errno":0,"data":[{"k":"python","v":"n. \u87d2; \u86ba\u86c7;"},{"k":"pythons","v":"n. \u87d2; \u86ba\u86c7; python\u7684\u590d\u6570;"}]}
json_data = json.loads(response.text)
print(json_data)
# {'errno': 0, 'data': [{'k': 'python', 'v': 'n. 蟒; 蚺蛇;'}, {'k': 'pythons', 'v': 'n. 蟒; 蚺蛇; python的复数;'}]}
result = ''
for data in json_data['data']:
result += data['v'] + '\n'
print(result)
# n. 蟒; 蚺蛇;
# n. 蟒; 蚺蛇; python的复数;
封装为函数
import requests
import json
def main(kw):
# 1、确定基础url
base_url = 'https://fanyi.baidu.com/sug'
data = {
'kw': kw
}
data_len = len(str(data))
headers = {
'content-length': str(data_len),
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'referer': 'https://fanyi.baidu.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
# 发送请求,获取响应
response = requests.post(base_url, headers=headers, data=data) # 得到返回的json数据
# print(response.text)
json_data = json.loads(response.text)
# print(json_data)
result = ''
for data in json_data['data']:
result += data['v'] + '\n'
return(result)
if __name__ == '__main__':
kw = input("请输入要翻译的内容:")
result = main(kw)
print(result)
五、数据的分类
1、分类
(1)结构化数据:能用关系型数据库描述的数据
特点:数据以行为单位,一行数据表示一个实体的信息,每一行的数据的属性是相同的。
举例:关系数据库中存储的表
处理方法:sql—结构化查询语言—语言—可以在关系型数据库中对数据的操作。
(2)半结构化数据:拥有字描述结构数据
特点:包含相关标记,用来分隔语义元素以及对记录和字段进行分层----也别成为自描述结构
举例:html,xml,json。
处理方法:正则,xpath(xml,html)
(3)非结构化数据
特点:没有固定结构的数据。
举例:文档,图片,视频,音频等等,都是通过整体存储二进制格式来保存的。
如果下载视频,音频。
处理:
response = requests.get(url='视频的地址')
保存response.content即可,文件名称后要注意。
2、json 数据
json(JavaScript Object Notation,JS对象标记)
json是一种数据【交换】的格式。
(1)json 与 js 关系
json是Js对象的字符串表达式,他使用文本形式表示一个Js对象的信息,本质是一个字符串(用来保存对象=字典和数组=列表)
js中的对象:var obj = {name:'zhangsan',age:'10'}----在python中这个可以当成:字典
js中的数组:var arr = ['a','b','c','d']----在python中这个可以当成:list
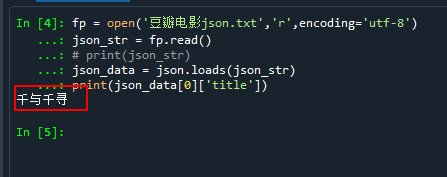
(2)json 数据的处理(重点)
1. 使用json模块处理
json_str 表示 json数据
json.loads(json_str)--->变成--->python的list或者字典
json.dumps(python的list或者字典)--->变成--->json_str
2. requests模块
在requests模块中,response对象有个json方法,可以直接得到相应json字符串解析后的内容
response.json()--->变为--->python的list或者字典
import requests
import json
json_data = {'abc':'0','cc':[1,2,3,4,5]}
# json.dumps(python的list或者字典)--->变成--->json_str
json_str = json.dumps(json_data)
print(json_str)
print(type(json_str))
# {"abc": "0", "cc": [1, 2, 3, 4, 5]}
# 
六、cookie和session
1、什么是cookie和session?
cookie是网站用来辨别用户身份,进行会话跟踪,存储在本地终端上的数据。
session(会话)指有始有终的一系列动作和消息。在web中,session主要用来在服务器端存储特定用户对象会话所需要的信息。
2、cookie和session产生的原因:
http协议是一个无状态协议,在特定操作的时候,需要保存信息,进而产生了cookie和session。
3、cookie原理:
由服务器来产生,浏览器第一次请求,服务器发送给客户端进而保存。
浏览器继续访问时,就会在请求头的cookie字段上附带cookie信息,这样服务器就可以识别是谁在访问了。
但是cookie存在缺陷:
1、不安全–本地保存,容易被篡改。
2、大小受限,本身最大4kb。
cookie虽然在一定程度上解决了‘保持状态’的需求,但是我们希望有一种新的技术可以克服cookie缺陷,这种技术就是session。
4、session原理:
session在服务器保存。----解决安全问题。
问题来了:服务器上的session,但是客户端请求发送过来,服务器如何知道session_a,session_b,到底和那个请求对应。
所以为了解决这个问题:cookie就作为这个桥梁。在cookie有一个sessionid字段,可以用来表示这个请求对应服务器中的哪一个session。
禁用cookie,一般情况下,session也无法使用。特殊情况下可以使用url重写技术来使用session。
url重写技术:将sessionid拼接到url里面。
session的生命周期:服务器创建开始,有效期结束(一般网站设定都是大约30分钟左右),就删除。
cookie和session 配合使用既解决安全问题,又解决大小受限问题
5、常见误区:打开浏览器中的一个网页,浏览器关闭,这个网页的session会不会失效?
不会,服务器到底删除不删除session,由session的生命周期。有效期结束,就会被删除。
6、cookie的字段
(1)Name : 该的名称。一旦创建, 该名称便不可更改。
(2)value : 该cookie 的值。如果值为Unicode 字符, 需要为字符编码。如果值为二进制数据, 则需要使用BASE64 编码。
(3)Domain : 可以访问该cookle 的域名。例如, 如果设置为.zhihu.com , 则所有以zhihu.com 结尾的域名都可以访问该cookie。
(4)MaxAge : 该cookie 失效的时间, 单位为秒, 也常和Expires一起使用, 通过它可以计算出其有效时间。Max Age 如果为正数, 则该cookie 在Max Age 秒之后失效。如果为负数, 则关闭浏览器时cookie 即失效, 浏览器也不会以任何形式保存该cookie 。
(5)Path : 该cookie 的使用路径。如果设置为/path/ , 则只有路径为/ path / 的页面可以访问该cookie 。如果设置为/ , 则本域名下的所有页面都可以访问该cookie
(6)Size 字段: 此Cookie 的大小。
(7)HTTP 字段: cookie 的httponly 属性。若此属性为true , 则只有在HTTP 头中会带有此Cookie 的信息, 而不能通过document.cookie 来访问此Cookie。
(8)Secure : 该cookie 是否仅被使用安全协议传输。安全协议有H TTP s 和SSL 等, 在网络上传输数据之前先将数据加密。默认为false。
7、会话cookie和持久cookie
- 会话cookie:Max Age 为负数,则关闭浏览器时cookie 即失效,保存在内存中的cookie。
- 持久cookie:Max Age 如果为正数, 则该cookie 在Max Age 秒之后失效。保存在硬盘上的cookie
持久化:将内存中数据持久化到硬盘上。其实就是数据保存到文件或者数据库中。
序列化:将对象持久化到硬盘中。
8、用requests登录页面
(1)将登录后的cookie封装到请求头字典中,这样就可以了。
例子5:人人网登录
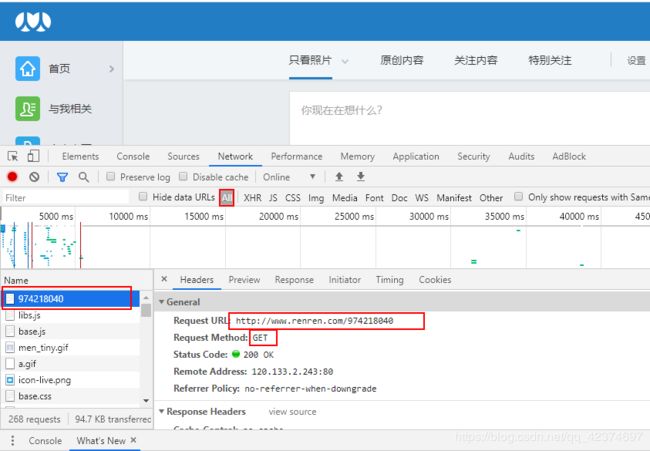
用封装cookie的形式来登录
import requests
def login():
# 确定基础url
base_url = 'http://www.renren.com/974218040'
# 准备参数
headers = {
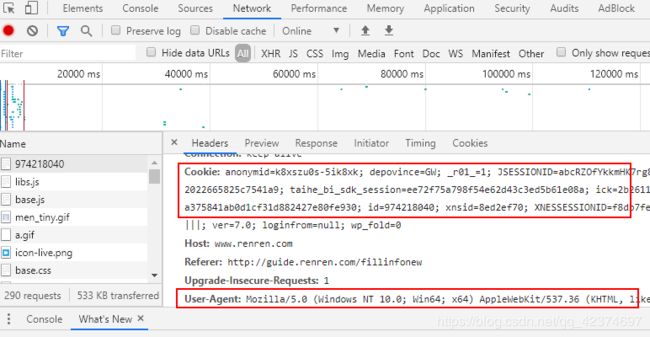
'Cookie':'anonymid=k8xszu0s-5ik8xk; depovince=GW; _r01_=1; JSESSIONID=abcRZOfYkkmHK7rg8kXfx; ick_login=0d09651c-348b-49e2-b0e9-0ec7da7b9519; taihe_bi_sdk_uid=25abb1a4702d8272022665825c7541a9; taihe_bi_sdk_session=ee72f75a798f54e62d43c3ed5b61e08a; ick=2b261181-d2e4-4e59-8054-581a5854ad0a; t=72a375841ab0d1cf31d882427e80fe930; societyguester=72a375841ab0d1cf31d882427e80fe930; id=974218040; xnsid=8ed2ef70; XNESSESSIONID=f8db7fe06bf4; WebOnLineNotice_974218040=1; jebecookies=af052275-8990-44b5-99fb-439ae01d98d6|||||; ver=7.0; loginfrom=null; wp_fold=0',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
# 发送请求,获取响应
response = requests.get(base_url, headers=headers)
if '小谭' in response.text:
return True
else:
return False
if __name__ == '__main__':
result = login()
if result:
print('登陆成功')
else:
print('登录失败!')

用requests模块的session对象,使用用户名和密码登录
import requests
'''
用requests模块的session对象,使用用户名和密码登录
'''
def login():
#确定url
#from 标签中action
login_url = 'http://www.renren.com/PLogin.do'
# 创建一个session(会话)对象:可以记录登录后的状态。
session = requests.session()
#用session对象来进行登录操作,这个对象就会记录登录的状态。
#准备登录请求的参数
data = {
'email':'1********8',
'password':'123456789',
}
#登录
session.post(login_url,headers=headers,data=data)
return session
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537',
}
session = login()
index_url = 'http://www.renren.com/974218040'
response = session.get(index_url,headers = headers)
if '小谭' in response.text:
print('登录成功!')
else:
print('登录失败!')
七、代理使用方法
1、代理基本原理
代理可以说是网络信息中转站(中间人)。实际上就是在本机和服务器之间架了一座桥。
2、代理的作用
(1)突破自身ip访问现实,可以访问一些平时访问不到网站。
(2)访问一些单位或者团体的资源。
(3)提高访问速度。代理的服务器主要作用就是中转,所以一般代理服务里面都是用内存来进行数据存储的。
(4)隐藏ip。
3、在requests模块中如何设置代理
proxies = {
'代理服务器的类型':'代理ip'
}
response = requests.get(proxies = proxies)
代理服务器的类型:http,https,ftp
代理ip:http://ip:port
例子6:高德地图(获取所有城市的天气信息)
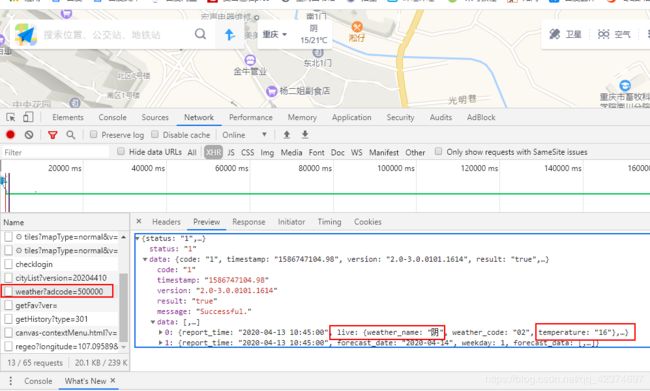
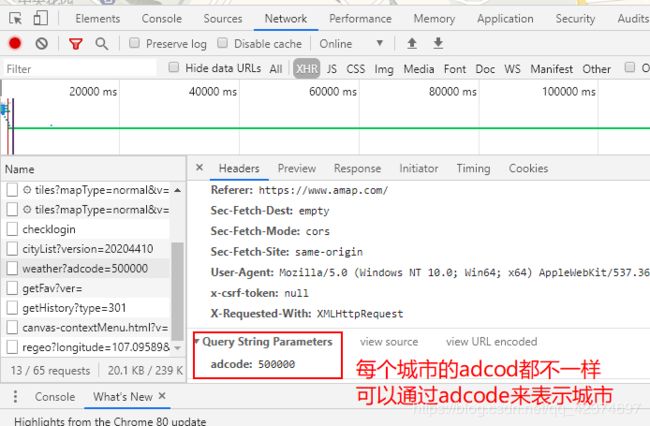
下一步获取全国城市的adcode
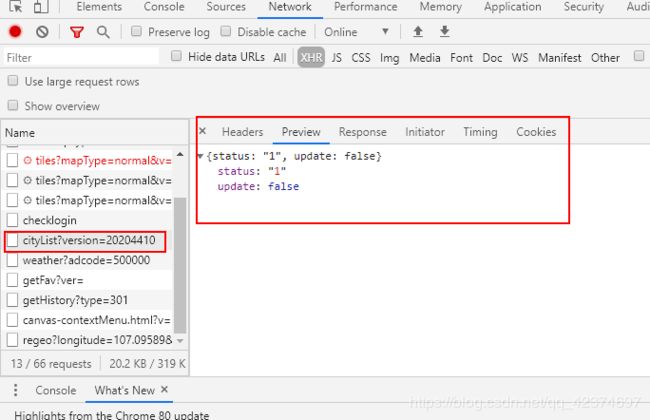
发现并没有
可以先清空缓存,在重新请求刷新页面。
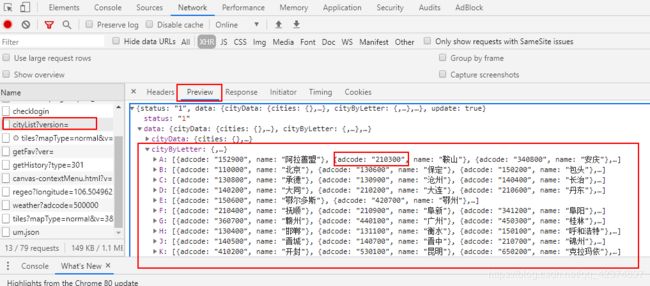
获取城市
获取天气
import requests
#获取城市以及对应的adcode
def get_city():
#确定url
base_url = 'https://www.amap.com/service/cityList?'
# 发送请求
response = requests.get(base_url,headers=headers)
# print(response.text)
#解析json数据
json_data = response.json()
# print(json_data) 得到的json数据放到在线json解析网站中,方便分析结构
#获取adcode
#热门城市
city_adcode = []
for data in json_data['data']['cityData']['hotCitys']:
city_adcode.append((data['adcode'],data['name']))
#其他城市
for data in json_data['data']['cityData']['otherCitys']:
city_adcode.append((data['adcode'],data['name']))
return city_adcode
def get_weather(adcode,city_name):
'''
获取城市天气
Query String Parameters
adcode:500000
'''
#基础url
base_url = 'https://www.amap.com/service/weather?adcode={}'.format(adcode)
response = requests.get(base_url, headers=headers) #发送请求,获取响应
json_data = response.json() #获取json数据
#通过得到的json数据,在在线解析网站中解析后,分析其结构,找到要获取的在哪一个字典或者列表列表
#分层的取出来即可
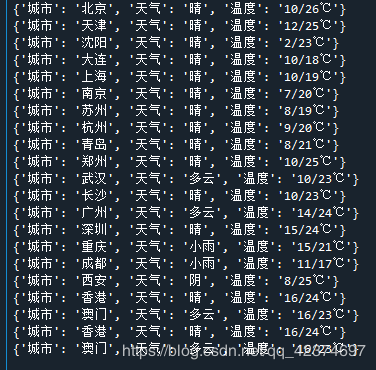
if json_data['data']['result']=='true':
weather = json_data['data']['data'][0]['forecast_data'][0]['weather_name'] #当前天气
#最大温度
max_temp = json_data['data']['data'][0]['forecast_data'][0]['max_temp']
#最小温度
min_temp = json_data['data']['data'][0]['forecast_data'][0]['min_temp']
# print(weather, max_temp, min_temp)
dic = {}
dic['城市'] = city_name
dic['天气'] = weather
dic['温度'] = '{}/{}℃'.format(min_temp,max_temp)
print(dic)
def main():
city_adcode = get_city()
# print(city_adcode)
#将每个城市的adcode传给get_weather
#city_adcode有城市和adcode
for i in city_adcode:
adcode = i[0]
city_name = i[1]
get_weather(adcode,city_name)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537',
'X-Requested-With': 'XMLHttpRequest',
}
main()
八、正则表达式


1.字符类
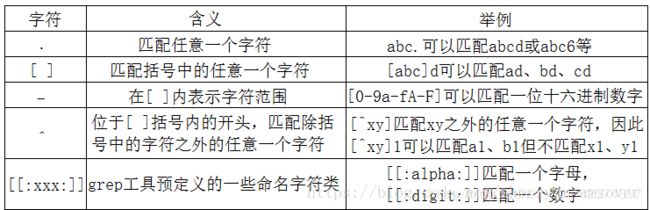
2.数量限定符
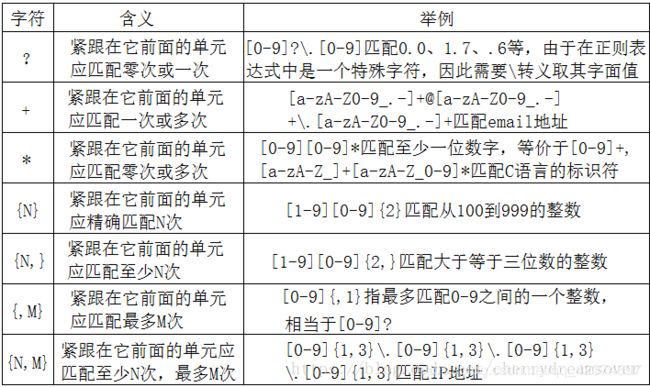
3.位置限定符
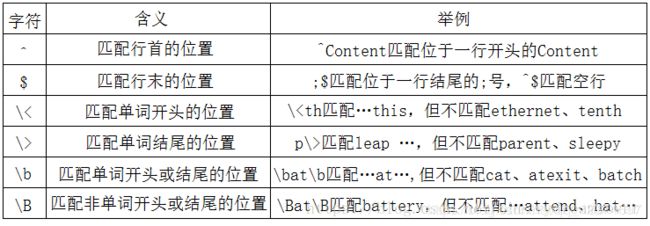
4.特殊符号

5.其他普通字符集及其替换

(一)元字符
1、匹配边界
^ ---行首
$---行尾
2、表示重复次数
? ---0或者1
* ---->=0
+ --- >=1
{n,}--->=n
{n,m}---》n,《m
{n}---n次
3、匹配文字
[]----表示匹配单字符
[abc]--匹配a或者b或者c中的其中一个
[a-zA-Z0-9]---匹配所有小写,大写和数字中的一个
\b---单词的边界
\d---表示数字
\w--数字、字母、下划线
\s---空白字符(空格,换行,制表)
. ---除换行以外的任意字符
非负整数 0 90 ^\d+$
匹配正整数 100 29 ^[1-9]\d*$
非正整数 0 -20 ^[0-]\d*$
qq邮箱:qq号5位---14 [1-9]\d{4,13}@qq\.com
首位1到9 \d==0到9 重复4到13次
匹配11位电话号码:第一位是1,第二位是3-9第三位开始不限定 1[3-9]\d{9}
匹配日期:比如:2019-12-19 ^[1-9]\d{3}-(1[0-2]|0?[1-9])-(3[01]|[12]\d|0?[1-9])$
以数字 (1到9 0到9重复3次) 开头
10、11、12 或者 01 02 03 ... 09
30 31 或者 10 11 ... 19 20 21 .. 29 或者01 02 ... 09 结尾
长度为8-10的用户密码:开头字母:必须大写,每一位可以是数字,字母,_ [A-Z]\w{7,9}
(二)re模块
1、re模块使用步骤
#1、导包
import re
#2、将正则表达式编译成一个pattern对象
pattern = re.complie(
r'正则表达式',
'匹配模式'
)
正则匹配模式:
re.S----.可以匹配换行符
re.I---忽略大小写
#3、pattern对象的方法(match,search、findall)匹配字符串。
import re
#正则表达式中r的作用
path1 = 'C:\\a\\b\\c'
print(path1)
path2 = r'C:\a\b\c'
print(path2)
2、pattern对象的方法
(1)match方法
默认从头开始,只匹配一次,返回一个match对象。
Match对象 = pattern.match(
string , #要匹配的目标字符串
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
) # ——>match对象
a、match对象的属性
match.group()---获取匹配内容
match.span()--匹配的范围
match.start()---开始位置
match.end()---结束位置
b、这些方法都可以带一个参数0,但是不能写1(有分组的情况才写1)
match.group(0)---获取匹配内容。
match.span(0)--匹配的范围
match.start(0)---开始位置
match.end(0)---结束位置
match.groups()--将所有分组的内容,按顺序放到一个元组中返回
练习
import re
pattern = re.compile(r'\d+')
content = 'one12twothree34four'
#默认从头开始匹配,只匹配一次,返回一个match对象
m1 = pattern.match(content)#从0位置开始匹配
m2 = pattern.match(content,2,10)#从e位置开始匹配
m3 = pattern.match(content,3,10)#从1位置开始匹配
print(m1) #None
print(m2) #None
print(m3) #(2)search方法
从任意位置开始匹配(全文匹配),只匹配一次,返回一个match对象
match对象 = pattern.search(
string , #要匹配的目标字符串
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
) # ——>match对象
match对象的属性与match方法一样
import re
pattern = re.compile(r'\d+')
content = 'one12twothree34four'
#(全文匹配),只匹配一次,返回一个match对象
m1 = pattern.search(content)
print(m1) #(3)findall方法
全文匹配,匹配多次,将每次匹配到的结果放到list中返回。
list = pattern.findall(
'匹配的目标字符串',
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
) # ——>list
import re
# 将正则表达式编译成一个pattern对象
pattern = re.compile('we')
#全文匹配,匹配多次,返回一个list
m = pattern.findall('we work well welcome')
print(m) #['we', 'we', 'we']
#findall配合分组,他会只会取分组中得内容以此放入元组中,list中存储的就是所有的元组
pattern = re.compile('(w)(e)') #[('w', 'e'), ('w', 'e'), ('w', 'e')]
pattern = re.compile('(w)e') #['w', 'w', 'w'] 只会将分组的放在list中
(4)finditer方法
全文匹配,匹配多次,返回一个迭代器。
pattern.finditer(
'匹配的目标字符串',
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
) #——>list # finditer主要用匹配内容比较多的情况下。
什么是迭代器?
当有一种数据或者内容比较多的时候,可以将其分装迭代器。---通过for循环来使用这个迭代器就可以获取其中的每一个数据。
有__next__和__iter__。
可迭代对象?有__iter__方法对象。
str
bytes
list
dict
tuple
文件流
练习
import re
pattern = re.compile(r'\d+')
content1 = 'hello 123456 789'
content2 = 'one1two2three3four4'
result_iter1 = pattern.finditer(content1)
result_iter2 = pattern.finditer(content2,0,10)
print(type(result_iter1))
print(type(result_iter2))
print('result1......')
for m1 in result_iter1:
print('matching string:{},position:{}'.format(m1.group(),m1.span()))
#matching string:123456,position:(6, 12)
#matching string:789,position:(13, 16)
print('result2......')
for m2 in result_iter2:
print('matching string:{},position:{}'.format(m2.group(),m2.span()))
#matching string:1,position:(3, 4)
#matching string:2,position:(7, 8)
(5)split
按正则方法表示内容进行分割字符串,返回分割后子串list
pattern.split(
'要切分的字符串',
'切分字数',默认是全部分。
) # ——>list
练习
import re
p = re.compile(r'[\s\,\;]+') #空格、换行、制表符 或者逗号 或者分号 重复至少一次
a = p.split('a,b; ;c d')
print(a) #['a', 'b', 'c', 'd']
(6)sub
按照正则表示的内容替换字符串(重要的)
Pattern.sub(
repl, #替换成什么
String,#替换什么
Count#替换次数,可选,默认全部替换
)--->替换后的字符串
(1)repl字符串
import re
p = re.compile(r'(\w+) (\w+)')
s = 'hello 123,hello 456'
#提前用p去匹配目标串,找到能匹配出来的内容,就是替换找出来的这个内容的。
print(p.sub(r'hello world',s))#使用‘hello world'替换'hello 123'和'hello 456'
#结果:hello world,hello world
print(p.sub(r'\2 \1',s))#引用分组
(2)当repl是一个函数的时候,这个函数是有要求的:
a、必须带一个参数,这个参数其实就是提前用p去匹配目标串,得到match对象。
b、这个函数必须有返回值,返回值是一个字符串,这个字符串将来就作为替换的内容。
练习
'''
a、必须带一个参数,这个参数其实就是提前用p去匹配目标串,得到match对象。
b、这个函数必须有返回值,返回值是一个字符串,这个字符串将来就作为替换的内容。
'''
def func(m):
print(m.group(2))#123 456
return 'hi'+' '+m.group(2)
g = func()
print(g)
# print(p.sub(func,s))
# print(p.sub(func,s,1))
'''
公司:所有员工工资都是记录在一个txt
zhangsan:2000,lisi:3000
'''
content = 'zhangsan:2000,lisi:3000'
#张三工资涨1000
p2 =re.compile(r'zhangsan:(\d+)')
def func1(m):
return 'zhangsan:'+str(int(m.group(1))+1000)
print(p2.sub(func1,content)) # zhangsan:3000,lisi:3000
#每个人涨1000
p3 =re.compile(r'(\d+)')
def func2(m):
return str(int(m.group(1))+1000)
print(p3.sub(func2,content)) #zhangsan:3000,lisi:4000
3、分组
分组在正则表达式中就是用()来表示的。一个括号就是一个分组。
分组的作用主要有以下两个:
(1)筛选特定内容
(2)引用分组
import re
content = '{name:"zhangsan",age:"10",hobby:["basktball","football","read"]}'
pattern = re.compile(r'{name:"(\w+)",age:"(\d+)".+')
#正则使用技巧:全串匹配,使用分组获取特定内容,括号两遍的边界一定要指定。
match = pattern.search(content)
print(match.group(0)) #{name:"zhangsan",age:"10",hobby:["basktball","football","read"]}
print(match.group(1))#zhangsan
print(match.group(2))#10
s = "正则表达式
"
# . ---除换行以外的任意字符
# *重复》0
pattern = re.compile(r'<(html)><(h1)>(.*)') # \1指的是html(以分组) 相应的\2
match = pattern.search(s)
print(match.group(3)) #获取分组3的内容 正则表达式
中文匹配
import re
title = '你好,hello,世界'
pattern = re.compile('[\u4e00-\u9fa5]+') #\u 指unicode编码
result = pattern.findall(title)
print(result) #['你好', '世界']
4、贪婪非贪婪模式
(1)贪婪是用*来控制,python默认是贪婪模式,所以默认所有的数量控制符都是取所能匹配的最大值。
(2)非贪婪是用?来控制的,?放在数量控制符后面,表示数量控制符匹配最小的次数。
import re
#贪婪:尽可能多,python默认,就是取范围的右边界
pattern = re.compile(r'ab*') #[0-3] *只作用b不作用a
result = pattern.findall('abbbc')
print(result) #['abbb'] 尽可能多的匹配
#非贪婪:?作用于数量控制符,数量控制符又作用与前面的单个字符 比如 *? 或者 {n}?
#在数量控制符后的?才表示采用非贪婪模式
#尽可能少匹配:取值范围的最小值
pattern = re.compile(r'ab*?') #[0,3]加了?之后只取左边界 0
result = pattern.findall('abbbc')
print(result) #['a'] 尽可能少的匹配
pattern = re.compile(r'ab{2,5}?') #不加问号b最大重复3次 加了问号b重复次数取左边界2
result = pattern.findall('abbbc')
print(result) #['abb']
pattern = re.compile(r'ab??')#第一个?表示数量作用符 b重复0次或者1次 [0,1],第二个?限制为只取左边界 0
result = pattern.findall('abbbc')
print(result) #['a']
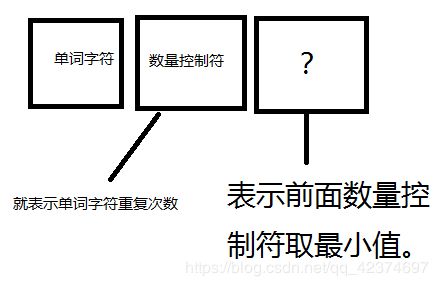
5、万能正则匹配表达式:.*?
(尽可能少匹配任意内容) 配合re.S(re.S ----.可以匹配换行符)
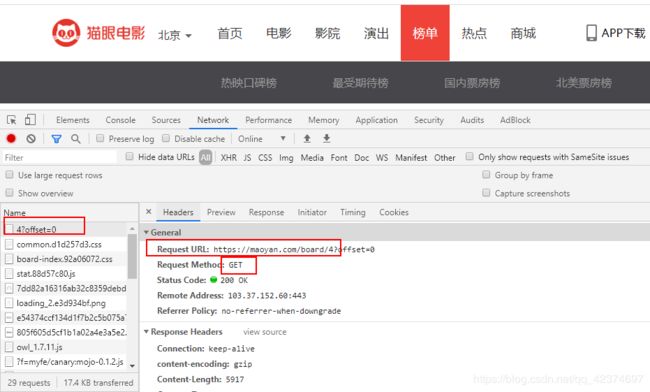
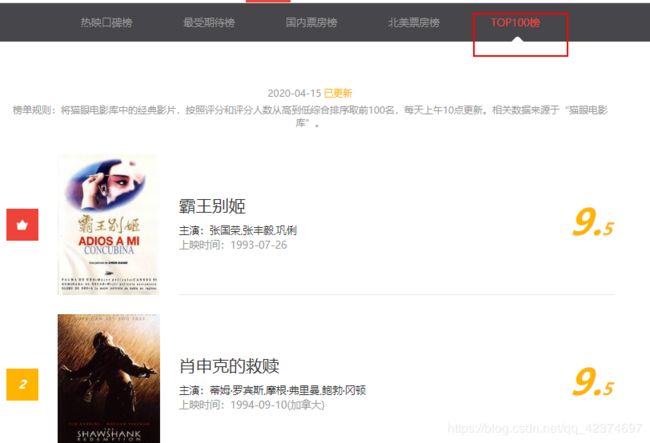
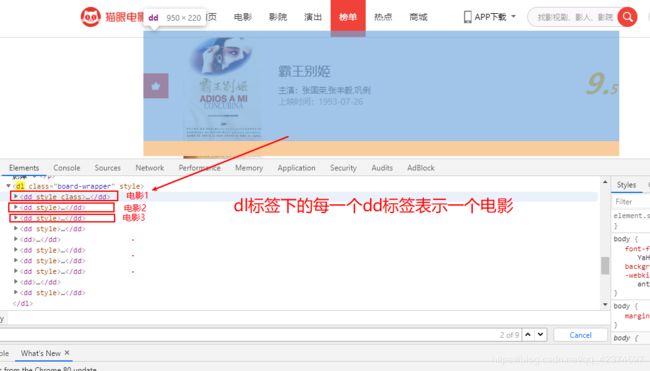
例子7:猫眼电影信息爬取
获取电影名称、演员、上映时间以及详情信息
分析网页源代码,找到要获取的标签位置
找到
- .*? ',re.S) # findall方法:全文匹配,匹配多次,将每次匹配到的结果放到list中返回。 dd_list = dd_p.findall(dl_c) #拿到所有dd(电影信息),放在list中 #三、获取电影名称、演员、上映时间以及详情信息 for d in dd_list: #获取电影名称 movie_title_p = re.compile(r'title="(.*?)" class=',re.S) #分析网页代码 左边界title=" 右边界" class= movie_title = movie_title_p.search(d).group(1) #获取分组1内容 .*?匹配到的 # print(movie_title) #获取演员 movie_actor_p = re.compile(r'
- 定义:可扩展标记性语言
- 特定:xml是具有自描述特性的半结构化数据。(半结构化数据:html、xml、json)
- 作用:xml主要用来传输数据
- 语法要求不同:xml的语法要求更严格。
(1)html不区分大小写的,xml区分。
(2)html有时可以省却尾标签。xml不能省略任何标签,严格按照嵌套首位结构。
(3)只有xml中有自闭标签(没有内容的标签,只有属性。)
(4)在html中属性名可以不带属性值。xml必须带属性值。
(5)在xml中属性必须用引号括起来,html中可以不加引号。
(6)xml文档中,空白部分不会被解析器自动删除,但是html是过滤掉空格的 - 作用不同
html主要设计用来显示数据
xml主要设计宗旨就是用传输数据 - 标记不同
(1)html使用固有的标记,xml没有固有标记
(2)html标签是预定义的,xml标签是自定义的、可扩展的。 - 什么xpath?
xpath是一种筛选 html 或者 xml 页面元素的【语法】
就相当于一个路径一样 - xml和html的一些名词
元素
标签
属性
内容 - xml的两种解析方法
dom和sax - xpath的语法
(1)选取节点 - 通过位置限定
[数字]选取第几个----//body/div[3]
[last()]:选取最后一个//body/div[last()]
[last()-1]:选取倒数第二个//body/div[last()]
[position()>2]—跳过前两个。 - 通过属性限定
[@class=‘属性值’]:选取class属性等于属性值的。----//div[@class=“container”]
[contains(@href,‘baidu’)]:选取属性名为href的属性值包含baidu的标签–//a[contains(@href,“1203”)] - 通过子标签的内容来限定
//book[price>35]–选取book标签的price字标签的内容大于35的book标签。 - 通配符
* —匹配任意节点
@* —匹配任意属性 - 选取若干路径
| —左边和右边的xpath选的内容都要—and - first item
- second item
- span_text1
- test fourth itemspan_text2
- fifth item
- 标签 li_list = html.xpath('//ul/li') print(li_list) # [
- 标签的所有 class属性 #遍历li_list for li in li_list: li_class = li.xpath('.//@class') #找当前节点下的所有class属性 ['item-0', 'a_class1']、['item-1']、['item-inactive', 'bold', 'span_item1']、['item-1', 'span_item2']、['item-0'] # li_class = li.xpath('./@class') #从根节点开始找 ['item-0']、['item-1']、['item-inactive']、['item-1']、['item-0'] print(li_class) #等价 li_classes = html.xpath('//ul/li/@class') print(li_classes) #['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0'] #3.继续获取
- 标签下href为 link1.html 的标签 a = html.xpath('//ul/li/a[@href="link1.html"]') print(a) #[
- 标签下的所有 标签(包括孙子span)
span = html.xpath('//li//span')
print(span) #[
, #5.获取] - 标签下的标签里的所有 class
class_a = html.xpath('//li/a//@class') print(class_a) #6.获取最后一个- 的 的 href
last_a = html.xpath('//ul/li[last()]/a/@href') print(last_a) #7.获取倒数第二个元素的内容 #使用通配符 result = html.xpath('//*[last()-1]/text()') print(result) #8.获取 class 值为 bold 的标签名 result = html.xpath('//*[@class="bold"]')[0] print(result.tag) - 同步请求(客户端发送请求,等待服务器响应;返回响应)
- 异步请求(客户端发送请求后,不会等待服务器响应,服务器和客户端之间有一个代理对象(XmlHttpRequest)代理对象主要负责对相应数据的处理和解析。
1客户端委托代理对象向服务器发送请求==》
2代理对象向服务器发送请求==》
3服务器返回响应数据给代理对象==》
4代理对象将数据更新到页面中) - 程序:一个应用就可以理解为一个程序
- 进程(process):程序运行资源分配的最小单位,一个程序可以有多个进程。
- 线程(thread):cpu最小的调度单位,必须依赖进程存在。线程是没有独立资源的,所有的线程共享他所在进程的所有资源。(线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务)
- 并行:程序多个执行流在同一时刻同时执行。
- 并发:就是cpu在同一时刻只处理一个任务,当时间间隔非常小的时候,多个任务相当于在同时执行。
- 在python中只能用多进程来实现并行。多线程就是并发。
- 增加单个文档(行),并指定_id
- 插入多条文档(行)
在js中多是用数组来表示的。—>[ ]—就是用来表示多的方法 -
SQL的语法是select 列 from 表 where …,注意对比
-
查询的列:{列名a:1,列名b:0} 0表示不显示,1表示显示
-
_id 不存储关系,所以可以任意插入数据,字段不固定,但是有主键,_id就是默认的主键,可以不指定,也可以指定但是不能重复
- limit():
- skip()
- sort()
- count()
- 等于:{key:value}—>key=value
查找 goods_id 为6 的 - 不等于:{key:{$ne:value}} —>key !=value
-
小于等于:{key:{$lte:value}}
-
大于:{key:{$gt:value}}
-
大于等于:{key:{$gte:value}}
-
小于:{key:{$lt:value}}
- $in:所查询的字段在数组中的值都会查询出来。
- $nin:不在多个值(数组)中条件(not in)
- $exists
- $all:指数组所有单元匹配,就是指我指定的内容都要有,通过一个list来指定
- $nor:所有的条件都不满足
- $and:所有的条件都满足
- $or:满足其中一个就可以了
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。——类似having
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
用正则表达式,提取内容

import requests
import re
import json
def get_content(url):
'''
发起响应,获取响应内容
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537',
}
response = requests.get(url,headers=headers)
# if response.status_code == '200':
return response.text
def parse_html(html_str):
'''
通过正则表达式,不断缩小匹配范围,先从最大的html所有标签中匹配dl标签
再从dl标签中匹配dd标签
再从dd标签的获取电影名称、演员、上映时间以及详情信息
'''
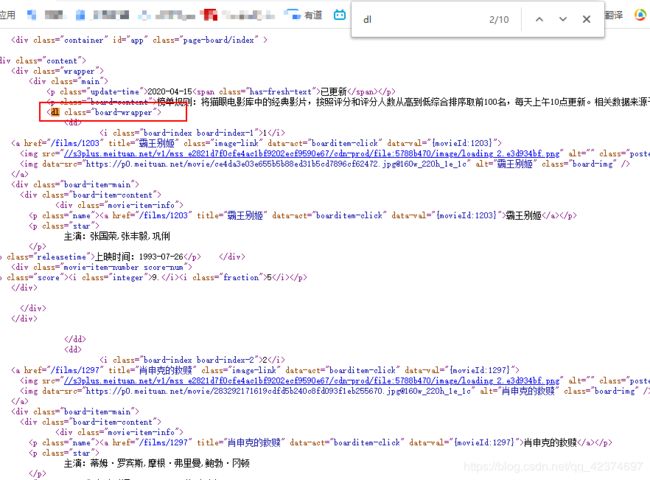
#一、获取dl标签
dl_p = re.compile(r'.*?
',re.S) #尽可能少的匹配任意内容,配合re.S(re.S ----.可以匹配换行符)
# search方法从任意位置开始匹配(全文匹配),只匹配一次,返回一个match对象
dl_c = dl_p.search(html_str).group()
#二、获取每一个dd标签
dd_p = re.compile(r'(.*?)
',re.S) #分析网页代码 左边界 右边界
movie_actor = movie_actor_p.search(d).group(1).strip() #获取分组1内容 .*?匹配到的 去除两边的空格
# print(movie_actor)
#上映时间
date_p = re.compile(r'(.*?)
', re.S)
date = date_p.search(d).group(1).strip()
# print(date)
# 评分
scores_p = re.compile(r'(.*?)(.*?)', re.S)
scores = scores_p.search(d).group(1)+scores_p.search(d).group(2)
# print(scores)
#详情页链接
detail_p = re.compile(r'+detail_p.search(d).group(1)
# print(detail)
#将一页所有要获取的信息放在字典中
item = {}
item['movie_title'] =movie_title
item['movie_actor'] =movie_actor
item['date'] =date
item['scores'] =scores
item['detail'] =detail
# print(item)
#将每一页信息放在movie_list
movie_list.append(item)
def write_to_json(movie_list):
with open('C:/movies_json','w',encoding='utf-8') as fp:
json.dump(movie_list,fp)
print('写入成功!')
def main():
base_url = 'https://maoyan.com/board/4?offset=%s'
#获取每一页,一共10页
#分页
for i in range(10):
html_str = get_content(base_url%(i*10))
#解析html
parse_html(html_str)
#写入json文件
write_to_json(movie_list)
if __name__ == '__main__':
movie_list = []
main()

例子8:获取淘宝电场商品信息
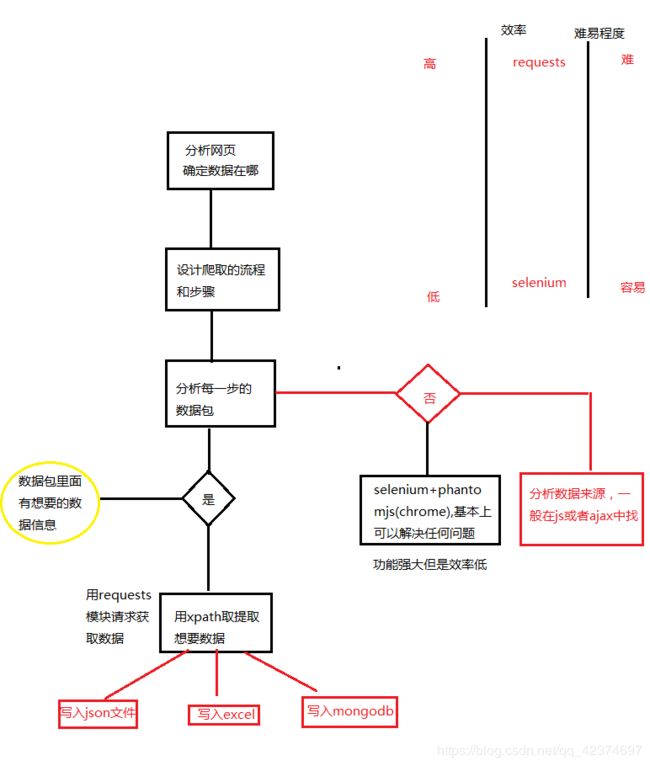
如果在页面中没有数据,此时应该关注js或者ajax,也可以使用selenium+phantomjs。
所以并不是所有的网站的数据都是写死在页面中的。
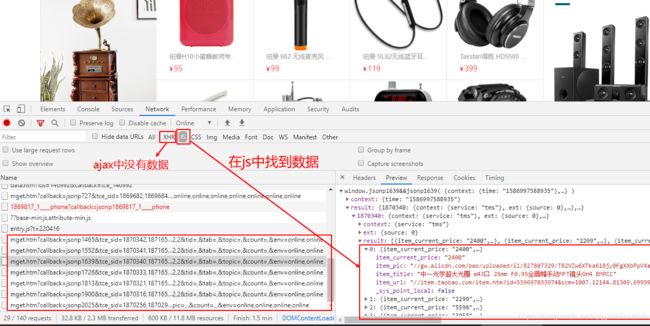
把每一条有数据url取出来
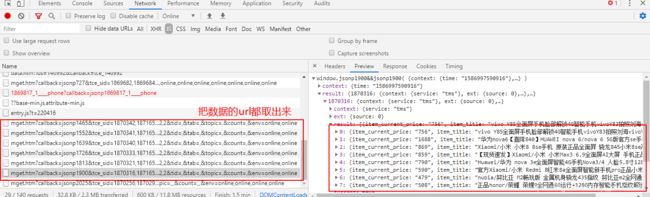
将返回的json数据进行在线解析,分析想要的数据在哪一个位置,然后提取就行

import re,json,requests
def get_content(url):
'''
请求给定url的页面,返回页面内容
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
}
response = requests.get(url,headers=headers)
return response.text
def parse_response(respose_str):
'''
分析返回的response_str ,发现其实是json数据,
window.jsonp1465&&jsonp1465(
{"context":{"time":"1586999267065"},........数据........}
因此先用正则将json部分({}内的数据)提取出来
'''
p = re.compile(r'{.*}')
#左边界是{,右边界是},这里不能用.*?,因为中间还有很多{},这里应该要使用贪婪模式,尽可能匹配多的,将整个花括号中的内容匹配出来,即{"context":{"time":"1586999267065"},........数据........}
#同样不分组,因为要形成一个字典{a:{},b:{},c:{}},方便取数据
#findall方法:全文匹配,匹配多次,将每次匹配到的结果放到list中返回。
result = p.findall(respose_str)[0]
# print(result)
#解析json
json_data = json.loads(result)
# print(json_data)
# #分析源代码
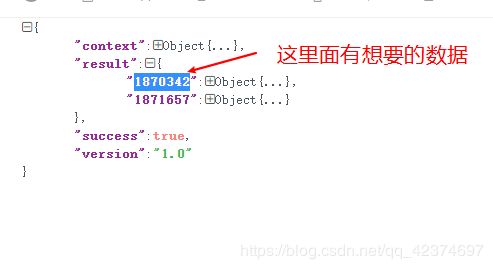
# 这里的拿出其url_1返回的json_data进行分析,结构如下:
# {
# "context":Object{...},
# "result":{
# "1870342":Object{...},
# "1871657":Object{...}
# },
# "success":true,
# "version":"1.0"
# }
#有数据的在result中的1871657
#每一个url的result都有两个18开头的,到底哪一个有数据?
#可以使用try过滤,处理这样的问题
json_result = json_data['result']
# print(json_result)
#Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。
# 遍历字典列表
for key,values in json_result.items():
# print(key) 12个18开头的 (6组)
# print(values)
result = values['result']
for i in result:
#异常:代码如果不处理,就会使得程序中断
try:
item = {}
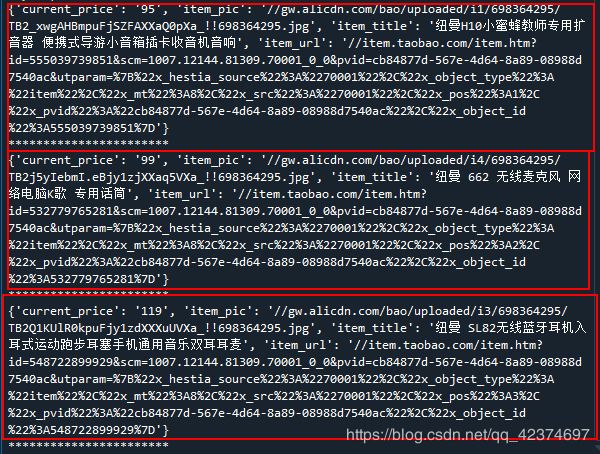
item['current_price'] = i['item_current_price']
item['item_pic'] = i['item_pic']
item['item_title'] = i['item_title']
item['item_url'] = i['item_url']
item['item_url'] = i['item_url']
print(item)
print('***********************')
#保存json文件
except Exception:
pass
def main():
#在js中,把所有有数据的url提取出来
url_1='https://tce.taobao.com/api/mget.htm?callback=jsonp1465&tce_sid=1870342,1871657&tce_vid=2,2&tid=,&tab=,&topic=,&count=,&env=online,online'
url_2='https://tce.taobao.com/api/mget.htm?callback=jsonp1552&tce_sid=1870341,1871659&tce_vid=2,2&tid=,&tab=,&topic=,&count=,&env=online,online'
url_3='https://tce.taobao.com/api/mget.htm?callback=jsonp1639&tce_sid=1870340,1871656&tce_vid=2,2&tid=,&tab=,&topic=,&count=,&env=online,online'
url_4='https://tce.taobao.com/api/mget.htm?callback=jsonp1726&tce_sid=1870333,1871655&tce_vid=2,2&tid=,&tab=,&topic=,&count=,&env=online,online'
url_5='https://tce.taobao.com/api/mget.htm?callback=jsonp1813&tce_sid=1870321,1871654&tce_vid=2,2&tid=,&tab=,&topic=,&count=,&env=online,online'
url_6='https://tce.taobao.com/api/mget.htm?callback=jsonp1900&tce_sid=1870316,1871653&tce_vid=2,2&tid=,&tab=,&topic=,&count=,&env=online,online'
#存放在list中
url_list = [url_1,url_2,url_3,url_4,url_5,url_6]
#依次发送请求,获取响应
for url in url_list:
respose_str = get_content(url)
# print(respose_str)
#解析返回的数据
parse_response(respose_str)
if __name__ == '__main__':
main()
九、Xml、XPath
1、什么是xml?
2、xml 和 html 的区别
3、xpath(语法)
| 表达式 | 描述 |
|---|---|
| nodename | 选取此标签及其所有字标签 |
| / | 从根节点开始选 |
| // | 从文档中的任意位置 |
| . | 当前节点开始找 |
| .. | 代表父节点 |
| @属性名 | 选取属性名所对应的属性值 |
| text() | 取标签中的值 |
例如:
| bookstore | 选取bookstore元素的所有子节点 |
|---|---|
| /bookstore | 选取根元素bookstore |
| bookstore/book | 选取属于bookstore 的子元素的所有book元素 |
| //book | 选取所有book子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于bookstore元素后代的所有book元素。而不管它们位于bookstore之下的什么位置 |
| /@lang | 选取名为lang的所有属性。 |
(2)谓语:起限定的作用,限定他前面的内容。
使用插件

4、lxml模块
python用来解析xml和html模块,用这个模块就可以使用xpath语法。
第三方模块:pip install lxml
(1)解析字符串类型xml
xpath方法返回的都是列表,查找元素或标签的时候,list 装的是elemnt对象,查找属性或元素的时候,list 装的是字符串
from lxml import etree
'''
html文档的解析方法
'''
#html页面内容
text = """
"""
#lxml的使用方法:将xml或者html解析成element对象
#使用的html方式进行解析的,将来解析的内容就是html文档。
#如果内容没有html标签,就会自动补全
# DOM解析 将html解析成一个document(文本结构——>树形结构)
html = etree.HTML(text) #返回值就是一个element对象
print(html) #]
#选取第一个li的属性值
li_class = html.xpath('//ul/li[1]/@class')
print(li_class) #['item-0']
#选取内容
a_text = html.xpath('//ul/li[1]/a/text()')
print(a_text) #['first item']
#选取class属性为item-1的li下面的a标签的内容
a_contents = html.xpath('//li[@class="item-1"]/a/text()')
print(a_contents) #['second item', 'fourth item']
练习
from lxml import etree
text='''
'''
#将html_str 转换为 html(element对象)
html = etree.HTML(text)
#1. 获取所有的 , , , , ]
#2.继续获取]
#4.获取(2)解析xml或者html文件
from lxml import etree
#parse方法是按照xml的方式来解析,如果语法出问题,就会报错。
tree = etree.parse('demo.html')
print(tree) #_ElementTree
li_texts = tree.xpath('//li/a/text()')
print(li_texts)
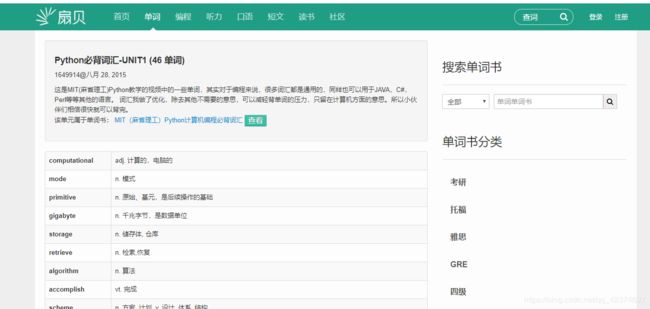
例子9:扇贝单词
https://www.shanbay.com/wordlist/110521/232414/?page=1


import re,json,requests
from lxml import etree
import xlwt
def get_xpath(url):
'''
请求给定url的页面,返回页面内容
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
'cookie': '__utma=183787513.714285480.1587170299.1587170299.1587170299.1; __utmc=183787513; __utmz=183787513.1587170299.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); csrftoken=9KZJEVQqKu994UX8o8vlMb4JEETgAVRg; _ga=GA1.2.714285480.1587170299; _gat=1; sajssdk_2015_cross_new_user=1; userid=225764056; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22zoshvn%22%2C%22first_id%22%3A%221718acadddce-0fffce366c7136-4313f6b-1049088-1718acadddd69e%22%2C%22props%22%3A%7B%7D%2C%22%24device_id%22%3A%221718acadddce-0fffce366c7136-4313f6b-1049088-1718acadddd69e%22%7D; auth_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6MjI1NzY0MDU2LCJleHAiOjE1ODgwMzYwNDksImRldmljZSI6IiIsInVzZXJuYW1lIjoiUGhvbmVfYmE4ODM2MGM2NjNmZmUxZSIsImlzX3N0YWZmIjowfQ.QQBKomr0ZZ2hL5F6EGKSoxxUSw2ByLbKK0rdsf9EiKk; __utmt=1; __utmb=183787513.5.10.1587170299',
}
response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
return html
def pase_html(html):
tr_list = html.xpath('//tr')
for tr in tr_list:
try:
#xpath返回都是一个列表
en_word = tr.xpath('.//strong/text()')[0]
zh_word = tr.xpath('.//td[@class="span10"]/text()')[0]
item = {}
item['英文'] = en_word
item['中文'] = zh_word
# print(item)
word_list.append(item)
except Exception:
pass
def write_to_excel(filename,sheetname,word_list):
try:
# 创建workbook
workbook = xlwt.Workbook(encoding='utf-8')
# 给工作表添加sheet表单
sheet = workbook.add_sheet(sheetname)
# 设置表头
head = []
for i in word_list[0].keys():
head.append(i)
# print(head) #['英文', '中文']
# 将表头写入excel,即A1和B1
for i in range(len(head)):
sheet.write(0, i, head[i])
# 写内容
i = 1
for item in word_list:
for j in range(len(head)):
sheet.write(i, j, item[head[j]]) #1-0(A2),1-1(B2);2-0(A3),2-1(B3)....
i += 1
# 保存
workbook.save(filename)
print('写入excle成功!')
except Exception as e:
print(e)
print('写入失败!')
def main():
#一共有4页
base_url = 'https://www.shanbay.com/wordlist/110521/232414/?page=%s'
for i in range(1,4):
html = get_xpath(base_url % i)
pase_html(html)
#保存到excel
write_to_excel('python_word.xls','python单词',word_list)
if __name__ == '__main__':
word_list = []
main()

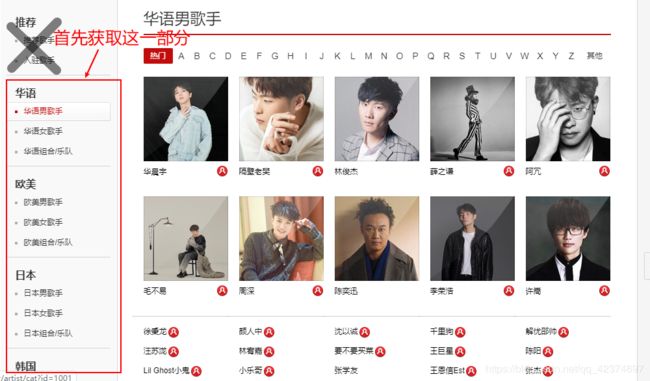
例子10.网易云音乐歌手信息爬取
Url:http://music.163.com/discover/artist
第一步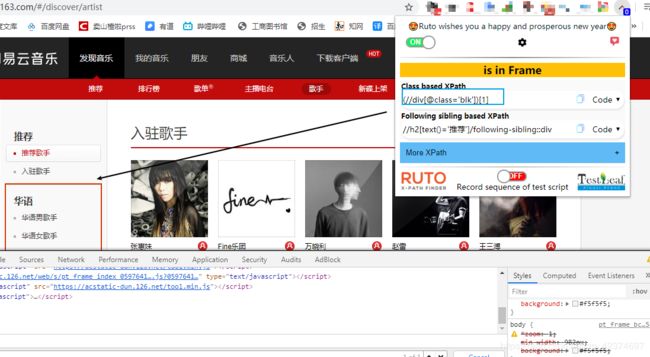
xpath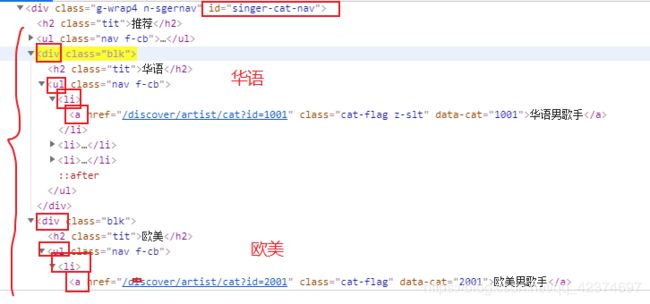
第二步
第三步
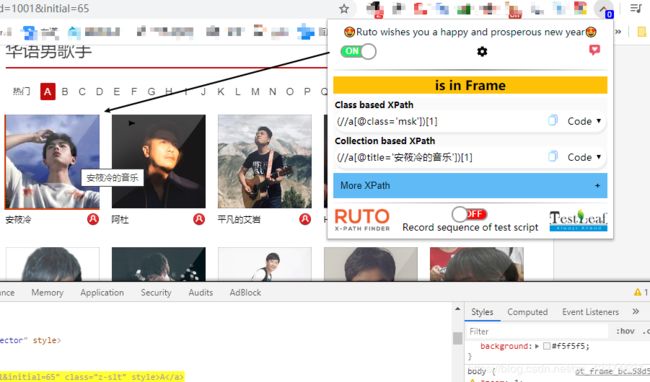



import requests
from lxml import etree
class WangYiMusic(object):
def __init__(self,url):
self.url = url
self.main()
def get_xpath(self,url):
'''
请求给定url的页面,返回页面内容
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
}
response = requests.get(url,headers=headers)
# print(response.text)
html = etree.HTML(response.text)
return html
def get_singer_list(self,url):
html = self.get_xpath(url)
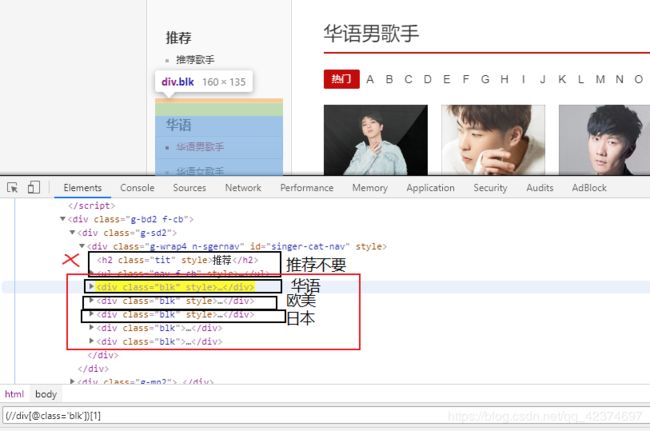
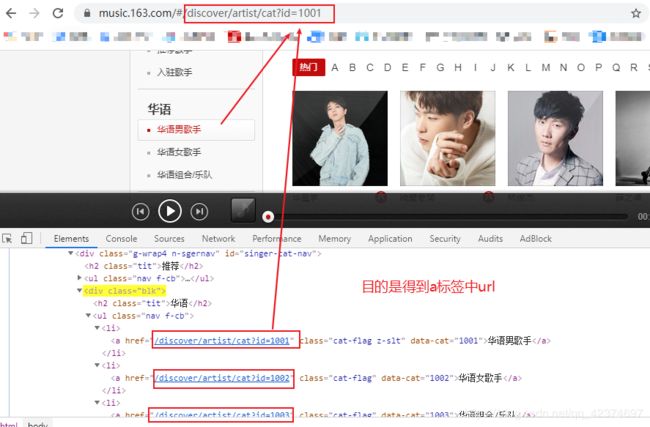
C_list = html.xpath('//div[@id="singer-cat-nav"]/div/ul/li/a/@href')
# print(C_list)
# ['/discover/artist/cat?id=1001', '/discover/artist/cat?id=1002', '/discover/artist/cat?id=1003', '/discover/artist/cat?id=2001', '/discover/artist/cat?id=2002', '/discover/artist/cat?id=2003', '/discover/artist/cat?id=6001', '/discover/artist/cat?id=6002', '/discover/artist/cat?id=6003', '/discover/artist/cat?id=7001', '/discover/artist/cat?id=7002', '/discover/artist/cat?id=7003', '/discover/artist/cat?id=4001', '/discover/artist/cat?id=4002', '/discover/artist/cat?id=4003']
return C_list
def main(self):
#第一步:获取分类歌手列表
C_list = self.get_singer_list(self.url) #返回的是一个装有url的列表(华语男歌手、华语女歌手...)
for i in C_list:
#拼接http://music.163.com + i
new_url_1 = 'http://music.163.com'+i
new_html_1 = self.get_xpath(new_url_1)
#第二步,获取字母列表,同样的套路
#不要热门,用li[position()>1]跳过第一个
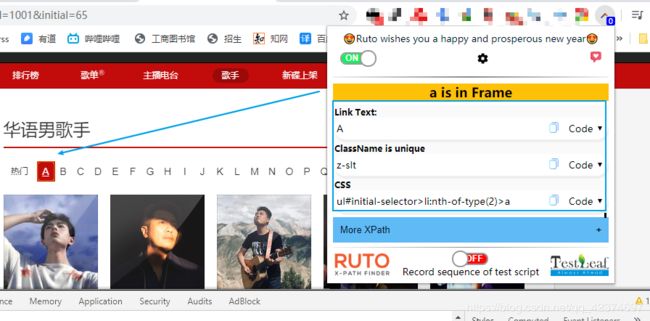
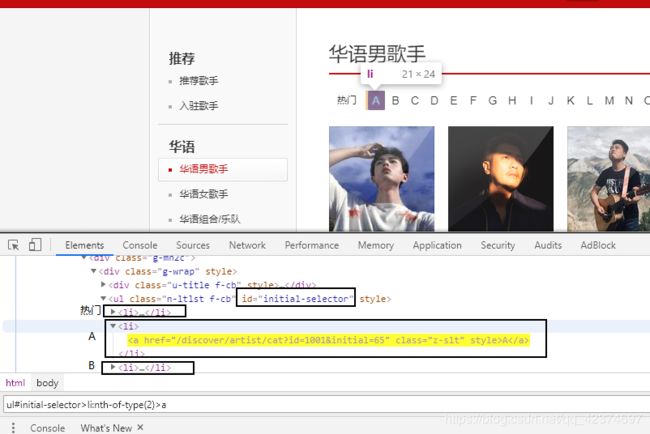
singer_word_list = new_html_1.xpath('//ul[@id="initial-selector"]/li[position()>1]/a/@href')
# print(singer_word_list) 返回也是一个列表
#['/discover/artist/cat?id=1001&initial=65', '/discover/artist/cat?id=1001&initial=66', '/discover/artist/cat?id=1001&initial=67', '/discover/artist/cat?id=1001&initial=68',....]
for j in singer_word_list:
#拼接
new_url_2 = 'http://music.163.com'+j
new_html_2 = self.get_xpath(new_url_2)
#第三步,获取字母列表中歌手信息,同样套路
li_list = new_html_2.xpath('//ul[@id="m-artist-box"]/li')
# print(li_list)
for li in li_list:
try:
# 歌手姓名和url
# | 表示左边和右边都要(有p标签和没有的)
singer_name = li.xpath('.//p/a[1]/text()|./a/text()')[0]
singer_url = li.xpath('.//p/a[1]/@href|./a/@href')[0]
# print(singer_name)
item = {}
item['歌手名'] =singer_name
item['歌手连接'] =singer_url
print(item)
except Exception:
pass
if __name__ == '__main__':
base_url = 'https://music.163.com/discover/artist'
WangYiMusic(base_url)

前面所有的方法都是数据包有响应,有些情况是数据包没有响应
十、动态html
1、反爬策略
(1)通过user-agent客户端标识来判断是不是爬虫。
解决的办法:封装请求头:user-agent
(2)封 ip
设置代理ip,封ip最主要的原因就是请求太频繁。
(3)通过访问频率来判断是否是非人类请求。
解决的办法:设置爬取间隔和爬取策略。
(4)验证码
解决办法:识别验证码
(5)页面数据不再直接渲染,通过前端js异步获取
解决办法:
a. 通过selenium+phantomjs来获取数据
b. 找到数据来源的接口(ajax接口)
(6)能获取列表页,就不获取详情页,为了避免增加请求的数量。将详情放到每条数据电心,第一次爬取先爬取列表第二次在从数据库中常出详情豆链接,在做第二次爬取。
(7)能一次清获取,就不分页获取,正对ajax请求。|可以将每一页获取数量调大
2、页面中的技术
(1)js:一种语言。
获取页面的元素,可以对这些页面元素做些操作。
网络数据的获取
(2)jquery:是一个js库,这个库可以使得js编程变得轻松容易。
(3)ajax:
3、selenium 和 phantomjs
如果想要解决页面js的问题,主要需要一个工具,这个工具(具备浏览器的功能)可以帮助我们来运行获取到的js。
1、什么是selenium?
selenium是一个web自动化测试工具。【但是他本身不具备浏览器的功能】,这个工具就相当于一个驱动程序,通过这工具可以帮助我们自动操作一些具有浏览器功能外部应用。
2、什么是phantomjs?
phantomj是一个内置无界面浏览器引擎。–无界面可以提高程序运行速度。因为phantomjs是一个浏览器引擎,所以它最大的功能就是它可以像浏览器那样加载页面,执行页面的js代码。
chromedriver.exe是谷歌浏览器驱动程序,通过这个程序可以使得selenium可以调用chrome浏览器。—有界面浏览器。
3、selenium 和 phantomjs的安装。
(1)下载phantomjs和chromedriver.exe

一定要找对应的谷歌浏览器版本号
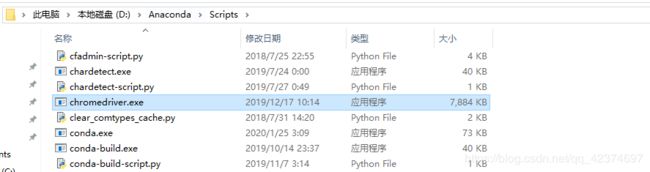
(2)安装:
解压
找到两个压缩包中exe文件,将其复制到anaconda/Scripts目录下面就ok了。
(3)测试:
在cmd中输入:
phantomjs
chromedriver

(4)selenium安装:pip isntall selenium
4、selenium基础知识
from selenium import webdriver
# 1.创建一个驱动
# driver = webdriver.phantomjs() #无界面的
driver = webdriver.Chrome() #谷歌 有界面的
# driver = webdriver.firefox() #火狐
# 2.请求url
driver.get('http://www.baidu.com/')
# 3.进行操作
'''
driver.find_element_by_id() #通过id属性查找 id是唯一的
driver.find_element_by_xpath() #通过xpath路径查找
driver.find_element_by_css_selector() #通过css选择器查找
'''
# input_ = driver.find_element_by_id('kw')
print(input_) #返回一个webelement对象 这个对象可以做很多事情
# 例子11:豆瓣读书
使用插件,用xpath找到要获取内容的位置
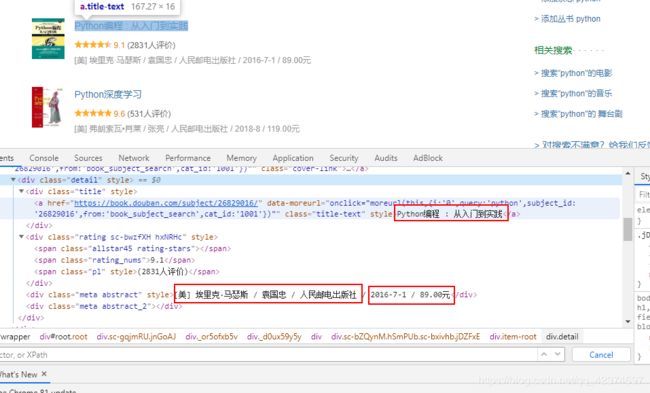
每一个div就是一本书的专栏

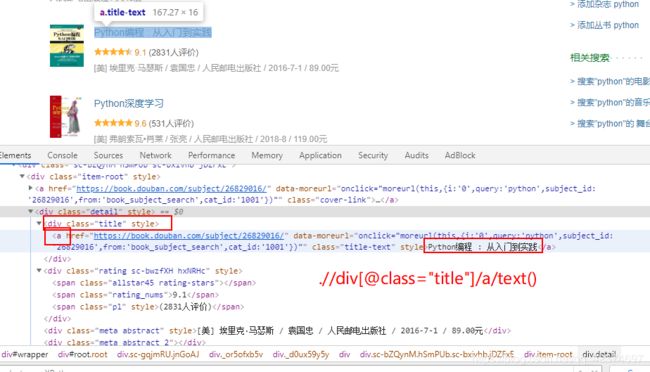
import time,os
from selenium import webdriver
from lxml import etree
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC#seleniunm内置一些条件
from selenium.webdriver.common.by import By
import requests
from excle_wirte import ExcelUtils
class DoubanReader(object):
def __init__(self,url):
self.url = url
# self.driver = webdriver.PhantomJS() #无界面驱动
self.driver = webdriver.Chrome() #有界面驱动
self.filename = 'C:/豆瓣python书籍.xls'
self.main()
#定义两个获取内容的函数
#一个是之前学的方法 header+response
#另一个是通过selenium创建驱动(浏览器),获取内容
#调用的时候,先用第一个,如果没有返回数据,就调用另外一个
def get_xpath(self,url):
#准备参数
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}
response = requests.get(url,headers=headers)
return response.text
def get_content_by_selenium(self,url):
#1,创建驱动
# 这一步放在程序全局变量中,每次都只打开一个浏览器界面进行操作
#2请求url
self.driver.get(url)
#3、等待 (重要,要等页面加载完)
#(1)强制等待:弊端:死板,而且有的时候还可能等待不够,造成数据的缺失
# time.sleep(3)
#(2)隐式等待:相当于页面在等待到转圈圈结束,页面完全加载出来位置。
#弊端:等待的还是太久了。
# driver.implicitly_wait(10)#10秒钟还没有全部加载完成的话,就会报超时异常
#(3)显示等待:可以聚焦到页面中特定元素出现就等待结束。
# 使用显示等待步骤
#①创建等待对象
# 20:显示等待的最大等待时长,20秒还没等待到特定元素加载出来,就报一个超时异常
#driver:表示这个等待对象监听到那个驱动浏览器程序上
wait = WebDriverWait(self.driver,20)
# ②用wait对象来进行条件判断
'''
EC.presence_of_element_located(定位器)
定位器是一个元祖(用什么定位器:id,xpath,css,'对应的选择器的语法')
'''
wait.until(EC.presence_of_element_located((By.XPATH,'//div[@id="root"]')))#等到啥时候为止。等到我想要的元素加载出来为止
#4、获取页面内容(网页源代码)
return self.driver.page_source
def parse_div(self,div_list):
'''
解析每个div,获取书籍
:param div_list:
:return:
'''
info_list=[]
for div in div_list:
#异常功能
try:
#书籍名称
book_title = div.xpath('.//div[@class="title"]/a/text()')[0]
# print(book_title)
#作者\出版社\价格\出版日期
book_ =div.xpath('.//div[@class="meta abstract"]/text()')
# print(book_)
li = book_[0].split(r'/')
#去掉空格
for i in range(len(li)):
li[i] = li[i].strip()
# print(li)
#作者
li_author = li[0]
#出版社
li_publish = li[-3]
#出版日期
li_date = li[-2]
#价格
li_price = li[-1]
#详情页链接
book_link = div.xpath('.//div[@class="title"]/a/@href')[0]
item = {}
item['作者'] = li_author
item['出版社'] = li_publish
item['出版日期'] = li_date
item['价格'] = li_price
item['详情页链接'] = book_link
# print(item)
info_list.append(item)
except Exception:
pass
if os.path.exists(self.filename):
#如果文件存在就追加
ExcelUtils.write_to_excel_append(self.filename,info_list)
else:
#不存在就新建
ExcelUtils.write_to_excel(self.filename,'python书籍',info_list)
def main(self):
#分页请求
i = 0
while True:
html_str = self.get_content_by_selenium(self.url %(i*15))
# print(html_str)
#页面内容转成element对象就可以使用xpath语法来进行获取页面内容
html = etree.HTML(html_str)
#获取
div_list = html.xpath('//div[@id="root"]/div/div[2]/div/div/div[position()>1]')
# xpath方法返回的是一个list,里面存储的是筛选出来的所有内容(一个一个的div)
# print(div_list)
if not div_list:
break
self.parse_div(div_list)
i+=1
if __name__ == '__main__':
#基础url (豆瓣读书)
base_url = 'https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=%s'
DoubanReader(base_url)
将爬取的结果写入/追加到excel(将下面的代码文件同上面的代码文件放在一个文件夹中)
import xlwt
import xlrd
from xlutils.copy import copy
class ExcelUtils(object):
#工具类的方法:不适用外部变量
#静态方法:直接可以用类名.方法名来调用
# @staticmethod
#类变量:
#实例变量
#类方法
@staticmethod
def write_to_excel(filename,sheetname,word_list):
'''
写入excel
:param filename: 文件名
:param sheetname: 表单名
:param word_list: [item,item,{}]
:return:
'''
try:
# 创建workbook
workbook = xlwt.Workbook(encoding='utf-8')
# 给工作表添加sheet表单
sheet = workbook.add_sheet(sheetname)
# 设置表头
head = []
for i in word_list[0].keys():
head.append(i)
# print(head)
# 将表头写入excel
for i in range(len(head)):
sheet.write(0, i, head[i])
# 写内容
i = 1
for item in word_list:
for j in range(len(head)):
sheet.write(i, j, item[head[j]])
i += 1
# 保存
workbook.save(filename)
print('写入excle成功!')
except Exception as e:
print(e)
print('写入失败!')
@staticmethod
def write_to_excel_append(filename,infos):
'''
追加excel的方法
:param filename: 文件名
:param infos: 【item,item】
:return:
'''
#打开excle文件
work_book = xlrd.open_workbook(filename)
#获取工作表中的所有sheet表单名称
sheets = work_book.sheet_names()
#获取第一个表单
work_sheet = work_book.sheet_by_name(sheets[0])
#获取已经写入的行数
old_rows = work_sheet.nrows
#获取表头的所有字段
keys = work_sheet.row_values(0)
print('===================',keys)
#将xlrd对象转化成xlwt,为了写入
new_work_book = copy(work_book)
#获取表单来添加数据
new_sheet = new_work_book.get_sheet(0)
i = old_rows
for item in infos:
for j in range(len(keys)):
new_sheet.write(i, j, item[keys[j]])
i += 1
new_work_book.save(filename)
print('追加成功!')
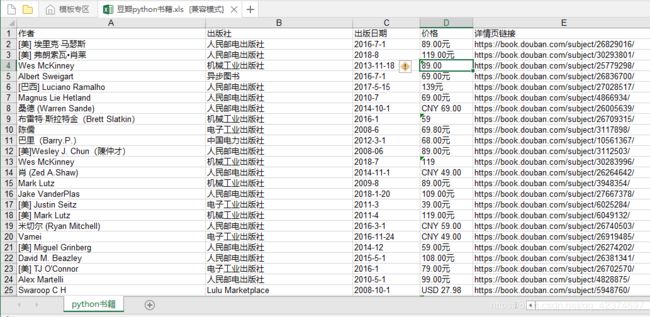
爬取结果
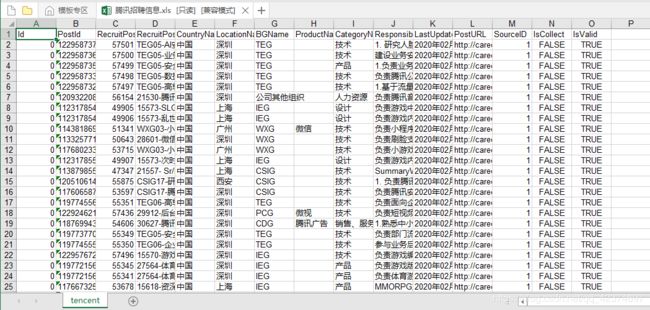
例子12:腾讯招聘
import os
import requests
from excle_wirte import ExcelUtils
def main():
#确定ajax的url
base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1581994304097&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
}
for i in range(1,10):
response = requests.get(base_url.format(i),headers= headers)
# print(response.text)
json_data = response.json()
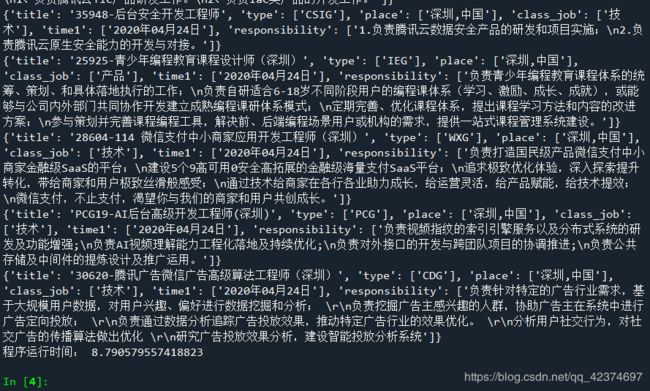
for data in json_data['Data']['Posts']:
#获取json数据的时候,直接全部存储
infos = json_data['Data']['Posts']
if os.path.exists(filename):
ExcelUtils.write_to_excel_append(filename,infos)
else:
ExcelUtils.write_to_excel(filename,'tencent',infos)
if __name__ == '__main__':
filename = '腾讯招聘信息.xls'
main()
爬虫流程图
十一、多线程基础
1、程序、线程、进程
2、什么是多线程?
程序中包含多个并行的线程来完成不同的任务。
程序运行速度---->主要是由cpu(大脑)来决定。
想要提高程序的运行速度----->提高cpu利用率。
提高cpu的利用率由两种途径:
1、让cpu不休息。cpu每时每刻都在处理任务,这个任务可以理解为线程。这种情况就叫做多线程。 2、cpu的多核的。每个核就是一个小脑袋。可以理解一心多用。让每个核都作用起来,去干不同的事情,这种方法是就叫多进程。
3、并行和并发
4、python中的threading模块
(1)创建多线程的第一种方法
import threading
t = threading.Thread(
target = 方法名,
args = (,) # 参数列表,元组
)
t.start() # 启动线程
例子
import threading
import time
import random
#单线程爬虫
def download(fileName):
print(f"{fileName}文件开始下载")
time.sleep(random.random()*10)
print(f"{fileName}文件完成下载")
#单线程 默认主线程
if __name__ == '__main__':
#创建5个线程,每个线程
for i in range(5):
# download(i)
t = threading.Thread(target=download,args = (i,))
t.start()
(2)创建多线程的第二种方法
(1)python的继承
①继承是通过在定义类的时候,类后面的()中添加父类来实现的。
②被继承的类称为父类,继承的类称为子类。
③子类继承父类所有非私有的属性及方法。
④如果子类重写父类的属性和方法,子类默认是优先拿自己的。
程序在运行时,当子类调用一个方法或者属性的时候,先去子类中找,如果找不到,就一层层向上,取父类中找。(继承具有传递性)
(2)自定义线程类
a、继承threading.Thread–拥有功能
b、保证父类的init方法能够被调用。
调用父类的init方法有两种方法
super().__init__()
threading.Tread.__init__(self)
(3)用自定义线程的步骤
①继承threading.Thread
②重写run方法:
③实例化这个类,就相当于创建了一个线程。
④如果自定义线程类要实现init方法,必须先调动父类的init方法。
t = MyThread()
t.start()---默认执行就是run方法里面的内容。
(4)线程的名称:可以帮我们测试时那个线程做的哪件事。
线程对象.name查看:默认是Thread-1,Thread-2…
自定名称:其实就是给self.name赋值
(5)查看线程的数量:threading.enumerate()
enumerate(
可迭代对象,
i, # 表示索引从i开始。
) # python的内置函数:枚举可迭代对象,同时获取迭代对象的每个值和其索引。
#主线程代码:
if __name__ == '__main__':
#打印晚会开始时间(可读)
print(f'晚会开始:{time.ctime()}')
#分别创建执行sing和dance函数的线程
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
#主线程
t1.start()
t2.start()
# 主线程不终止
while True:
# 查看线程数量(包括主线程,至少含有一个主线程)
length = len(threading.enumerate())
# 主线程加上两个子线程的线程,一共三个线程
print(f'当前运行的线程数为:{length}')
time.sleep(0.1)
if length <= 1:
break
例子
import threading
import time
import random
#第一步继承threading.Thread
class Mythred(threading.Thread):
def __init__(self,filename,name):
super().__init__()#调用父类的init方法
self.name = name
self.filename = filename
# 第二步重写run方法(既要继承父类的一些功能(Thread),又要有自己的创新(run))
# run方法就是线程启动后执行的方法,start--->run
def run(self):
self.download(self.filename)
def download(self,fileName): #单线程爬虫
print(f"{fileName}文件开始下载@{self.name}") #@{self.name}:查看线程名称,可以帮我们测试时那个线程做的哪件事。
time.sleep(random.random()*10)
print(f"{fileName}文件完成下载@{self.name}")
if __name__ == '__main__': #单线程 默认主线程
#创建5个线程,自定义线程名称
name_list = ['a','b','c','d','e']
for i in range(5):
#第三步实例化这个类,就相当于开始创建线程。
t = Mythred(i,name = name_list[i])
t.start() #启动线程

(6)线程的五种状态
线程的执行顺序是混乱:线程是cup调度的最小单位,线程的执行完全是由cpu调度所决定的。cpu如何来调度呢?是由线程状态决定。
(7)线程间公用数据的共享问题
多个线程多全局变量的更改,容易造成数据的混乱。
解决办法:将线程对公有数据更改部分,用互斥锁锁起来,这两就可以解决这种问题。
多线程避免多个线程同时处理公有变量。——解耦。
当列表作为线程任务函数参数,如果对列表做一些更改,需要拷贝一份作为遍历的内容
(8)死锁
产生死锁的两中情况
1、同一个线程,先后获取两次锁对象,就会产生死锁。
2、A获取锁1,B获取锁2,A在不释放锁1的情况试图获取锁2,B在不释放锁2的情况下试图获取锁1,此时就会产生死锁。
5、多线程和多进程
(1)功能:
进程:能够完成多任务,比如在一台能够同时运行多个QQ。
线程:能够完成多任务,比如一个QQ中的多个聊天窗口。线程必须依赖进程存在
(2)定义:
进程是系统进行资源分配和调试的一个独立单位。
线程是进程的一个实体,是CPU调用和分派的基本单位,它是比进程更小的能独立运行的基本单位。
(3)区别:
一个程序至少有一个进程,一个进程至少有一个线程,线程的划分尺度小于进程(资源比进程少),使得多线程程序并发性更高。
进程在执行过程中拥有独立的内存单元,线程没有独立资源,不能独立运行,必需依存进程。
(4)优缺点:
线程:执行开销小,但不利于资源的管理和保存,线程自己基本上不拥有系统资源,但是它可以与同属于一个进程的其它线程共享进程所拥有的全部资源。。
进程:多个进程之间相互独立,不利于进程间信息交互。进程拥有独立资源。
(5)如何选择:
在实际开发中,选择多线程还是多进程,应该从具体实际开发来进行选择。最好是多进程和多线程结合,即根据实际的需求,每个cpu开启一个子进程,这个子进程开启多个线程进程数据处理。在涉及数据交互频繁的场景,多进程比多线程更加适合。在并发程度上,多进程比多线程的效率更高。
腾信招聘案例
单线程
from selenium import webdriver
from lxml import etree
import threading
import time
def main():
driver = webdriver.PhantomJS()
for i in range(5):
driver.get(f'https://careers.tencent.com/search.html?index={i}&keyword=python')
tree = etree.HTML(driver.page_source)
div_list = tree.xpath('//div[@class="recruit-list"]')
for div in div_list:
##提取
title = div.xpath('./a/h4/text()')[0]
type = div.xpath('./a/p/span[1]/text()')
place = div.xpath('./a/p/span[2]/text()')
class_job = div.xpath('./a/p/span[3]/text()')
time1 = div.xpath('./a/p/span[4]/text()')
responsibility = div.xpath('.//p[@class="recruit-text"]/text()')
#获取到的信息放入字典
item = {}
item['title'] = title
item['type'] = type
item['place'] = place
item['class_job'] = class_job
item['time1'] = time1
item['responsibility'] = responsibility
print(item)
if __name__ == '__main__':
start_time = time.time()
main()
print('程序运行时间:',time.time()-start_time)

多线程(1)
from selenium import webdriver
from lxml import etree
import threading
import time
def parse_page(page):
driver = webdriver.PhantomJS() #创建一个驱动
driver.get(f'https://careers.tencent.com/search.html?index={i}&keyword=python')
tree = etree.HTML(driver.page_source)
div_list = tree.xpath('//div[@class="recruit-list"]')
for div in div_list:
##提取
title = div.xpath('./a/h4/text()')[0]
type = div.xpath('./a/p/span[1]/text()')
place = div.xpath('./a/p/span[2]/text()')
class_job = div.xpath('./a/p/span[3]/text()')
time1 = div.xpath('./a/p/span[4]/text()')
responsibility = div.xpath('.//p[@class="recruit-text"]/text()')
#获取到的信息放入字典
item = {}
item['title'] = title
item['type'] = type
item['place'] = place
item['class_job'] = class_job
item['time1'] = time1
item['responsibility'] = responsibility
print(item)
if __name__ == '__main__':
start_time = time.time()
#定义一个用来存储线程的list
crawl_list = []
for i in range(5):
# 开启线程方法,在爬虫里面有很大弊端,很难控制线程数量。
#每一页创建一个线程,获取数据
t = threading.Thread(target=parse_page,args=(i,))
#开启线程
t.start()
#把线程添加到list中
crawl_list.append(t) #存放的是5个线程实例,等一个线程完后才能往后面走,也就是循环一次等待一次,等待5次,
for t in crawl_list:
#join方法的作用就是阻塞当前线程,知道调用他的这个t执行完毕为止。
t.join()
print('程序运行时间:',time.time()-start_time)
多线程(2)队列
队列
from queue import Queue
#创建一个队列:可以让原本有序的东西,在出队的过程中保存原来顺序。
queue_num = Queue()
for i in range(200):
#入队操作
queue_num.put(i)
while not queue_num.empty():
#出队
print(queue_num.get()
from queue import Queue
#创建一个队列:可以让原本有序的东西,在出队的过程中保存原来顺序。
queue_num = Queue()
for i in range(200):
#入队操作
queue_num.put(i)
for i in range (1000):
# block = False,表示get方法变成非阻塞方法,当队列为空的时候,就抛出一个queue.Empty
# block = True(默认),表示get方法是一个阻塞方法,当队列为空的时候,就阻塞当前线程。
print(queue_num.get())
先改为类
from selenium import webdriver
from lxml import etree
import threading
import time
from queue import Queue
class tencent:
def __init__(self,url):
self.url=url
self.parse_page()
def parse_page(self):
driver = webdriver.PhantomJS() #创建一个驱动
driver.get(self.url)
tree = etree.HTML(driver.page_source)
div_list = tree.xpath('//div[@class="recruit-list"]')
for div in div_list:
##提取
title = div.xpath('./a/h4/text()')[0]
type = div.xpath('./a/p/span[1]/text()')
place = div.xpath('./a/p/span[2]/text()')
class_job = div.xpath('./a/p/span[3]/text()')
time1 = div.xpath('./a/p/span[4]/text()')
responsibility = div.xpath('.//p[@class="recruit-text"]/text()')
#获取到的信息放入字典
item = {}
item['title'] = title
item['type'] = type
item['place'] = place
item['class_job'] = class_job
item['time1'] = time1
item['responsibility'] = responsibility
print(item)
if __name__ == '__main__':
for i in range(5):
base_url = 'https://careers.tencent.com/search.html?index={}&keyword=python'.format(i)
tencent(base_url)
再继续改
from selenium import webdriver
from lxml import etree
import threading
import time
from queue import Queue
#第一步继承threading.Thread
class Tencent(threading.Thread):
def __init__(self,url,queue_page,name):
super().__init__() #调用父类的init方法
self.url=url
self.queue_page=queue_page
self.name=name
# 第二步重写run方法(既要继承父类的一些功能(Thread),又要有自己的创新(run))
def run(self):
#一个类就相当于一个线程
#现在创建5个线程干20个任务,只能每个线程做多件事
#重复不断的取做:从【队列】中取出一i个页码,爬取,解析
while True:
# 一定要先做跳出循环的条件准备
if self.queue_page.empty(): #如果队列中页码为空了,就跳出循环
break
#取页码
page = self.queue_page.get() #出队操作
print('===============第{}================@线程{}'.format(page,self.name))
#请求+解析
self.parse_page(page) #page=0,1,2,...,9
def parse_page(self,page):
driver = webdriver.PhantomJS() #创建一个驱动
driver.get(self.url.format(page))
tree = etree.HTML(driver.page_source)
div_list = tree.xpath('//div[@class="recruit-list"]')
for div in div_list:
##提取
title = div.xpath('./a/h4/text()')[0]
type_ = div.xpath('./a/p/span[1]/text()')
place = div.xpath('./a/p/span[2]/text()')
class_job = div.xpath('./a/p/span[3]/text()')
time1 = div.xpath('./a/p/span[4]/text()')
responsibility = div.xpath('.//p[@class="recruit-text"]/text()')
#获取到的信息放入字典
item = {}
item['title'] = title
item['type_'] = type_
item['place'] = place
item['class_job'] = class_job
item['time1'] = time1
item['responsibility'] = responsibility
# print(item)
if __name__ == '__main__':
start = time.time()
#基础url
base_url = 'https://careers.tencent.com/search.html?index={}&keyword=python'
#第一步:创建任务队列并初始化
queue_page = Queue()
for i in range(10):
queue_page.put(i) #入队操作 就是 0,1,2,3,4,...,9 页码
#第二步:创建线程list,这个list的长度就是创建线程的数量,内容就是将来线程名称
#创建5个线程,自定义线程名称
name_list = ['a','b','c','d','e']
thread_list = []
for i in name_list:
#创建线程
#queue_page:将创建好的队列传进去
#传线程名称
t = Tencent(base_url,queue_page,i)
t.start()
thread_list.append(t)
#阻塞主线程,保证每个都执行完成之后,来测试程序的执行时间
for t in thread_list:
t.join()
print('程序执行的时间:',time.time()-start)
生产者消费者模型
from queue import Queue
from selenium import webdriver
from lxml import etree
import threading
'''
生产者生产每一页的html页面,也就是生产者负责请求---class Producter
消费者消费html,解析---class Consumer
缓冲区:队列来做
'''
# 三个‘生产者’线程——获取页面
#继承
class Producter(threading.Thread):
def __init__(self,url,queue_page,name):
super().__init__()
self.queue_page = queue_page
self.name = name
self.url = url
#重写run函数
def run(self):
while True:
# 如果“页码”队列为空,就跳出循环的条件
if self.queue_page.empty():
break
#获取页码 出队
page = self.queue_page.get()
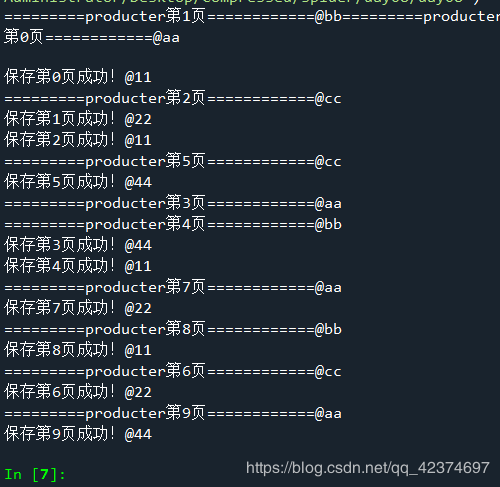
html_str = self.get_html(page) # 调用get_html函数,获取页面
print('=========producter第{}页============@{}'.format(page,self.name))
#将生产数据放入公共缓冲队列 即将获取的页面放入队列(公共缓冲区)中
queue_html.put((page,html_str))
def get_html(self,page):
'''
获取一页页面内容
:param i: 页码
:return:页面的字符串内容
'''
driver = webdriver.PhantomJS()
driver.get(self.url.format(page)) #传入页码
return driver.page_source
# 四个‘消费者’线程——解析页面
#继承
class Consumer(threading.Thread):
def __init__(self,name):
super().__init__()
self.name = name
#重写run函数
def run(self):
while True:
# 保证生产者都生产完了(即页面全部获取),
# 同时页面队列(公共缓冲区)为空了,就跳出循环(消费者才停止消费)
if queue_html.empty() and flag :
break
try:
# block = False,表示get方法变成非阻塞方法,当队列为空的时候,就抛出一个queue.Empty
# block = True(默认),表示get方法是一个阻塞方法,当队列为空的时候,就阻塞当前线程。
page, html_str = queue_html.get(block=False) #获取页码和html
self.parse_html(html_str) #调用解析函数
print('保存第{}页成功!@{}'.format(page, self.name))
except Exception:
pass
def parse_html(self,html_str):
'''
解析页面
'''
tree = etree.HTML(html_str)
div_list = tree.xpath('//div[@class="recruit-list"]')
for div in div_list:
##提取
title = div.xpath('./a/h4/text()')[0]
type = div.xpath('./a/p/span[1]/text()')
place = div.xpath('./a/p/span[2]/text()')
class_job = div.xpath('./a/p/span[3]/text()')
time1 = div.xpath('./a/p/span[4]/text()')
responsibility = div.xpath('.//p[@class="recruit-text"]/text()')
item = {}
item['title'] = title
item['type'] = type
item['place'] = place
item['class_job'] = class_job
item['time1'] = time1
item['responsibility'] = responsibility
# print(title)
# 主线程
if __name__ == '__main__':
# 1、创建一个页面队列(公共缓冲区),用来存页面数据
queue_html = Queue()
# 2、创建一个页码队列,用来存页码
queue_page = Queue()
# 3、初始化
for i in range(10):
queue_page.put(i) #入队(页码)0,1,2,,,9
# 4、设置轮询参数
flag = False#表示生产者没有生产完成
# 基础url
base_url = 'https://careers.tencent.com/search.html?index={}&keyword=python'
#-----------------------------------------------
P_threads_name = ['aa', 'bb', 'cc'] # 创建三个(生产者)线程
#定义一个用来存储线程的list
p_threads = []
for i in P_threads_name:
# 实例化这个类,就相当于开始创建线程。
t = Producter(base_url,queue_page,i)
# 启动线程
t.start()
#把线程添加到list中,存放的是10个线程实例,等一个线程完后才能往后面走,也就是循环一次等待一次,等待10次,
p_threads.append(t)
#-----------------------------------------------
C_threads_name = ['11', '22', '33','44'] # 创建四个(消费者)线程
for name in C_threads_name:
t = Consumer(name)
t.start()
# 将生产者都加入阻塞join()
for p in p_threads:
p.join()
# 表示生产者生产完成
flag = True
十二、MongoDB
1、安装教程
https://www.runoob.com/mongodb/mongodb-tutorial.html
安装
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
新建一个data文件夹,在该文件夹下创建db和logs文件夹

然后
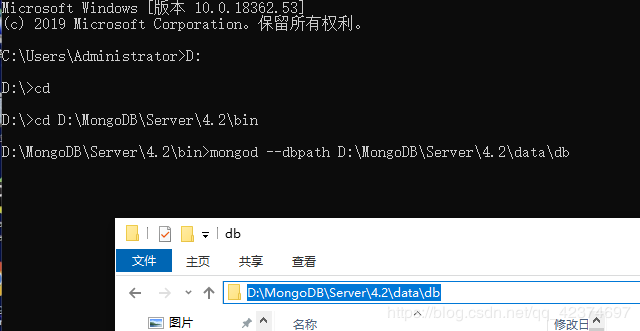
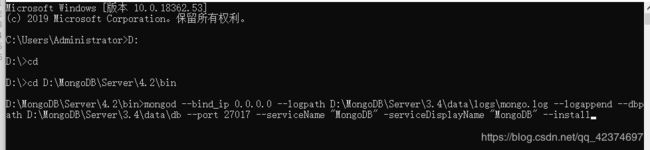
在执行下面这条命令
mongod --bind_ip 0.0.0.0 --logpath D:\MongoDB\Server\3.4\data\logs\mongo.log --logappend --dbpath D:\MongoDB\Server\3.4\data\db --port 27017 --serviceName “MongoDB” -serviceDisplayName “MongoDB” --install
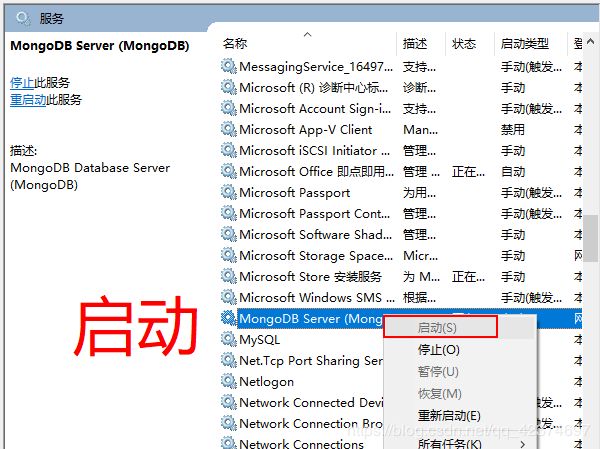
在配置环境变量
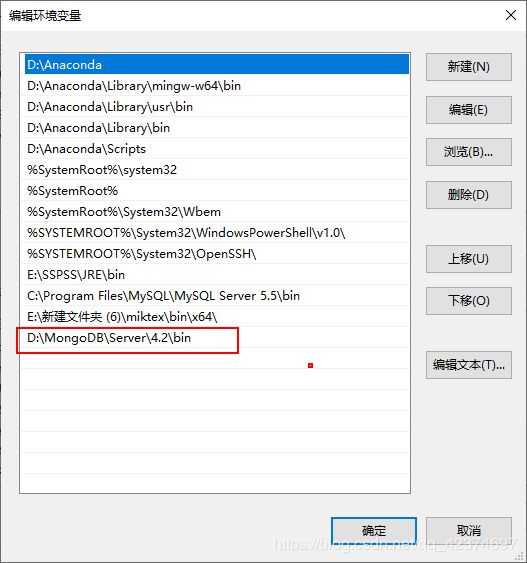
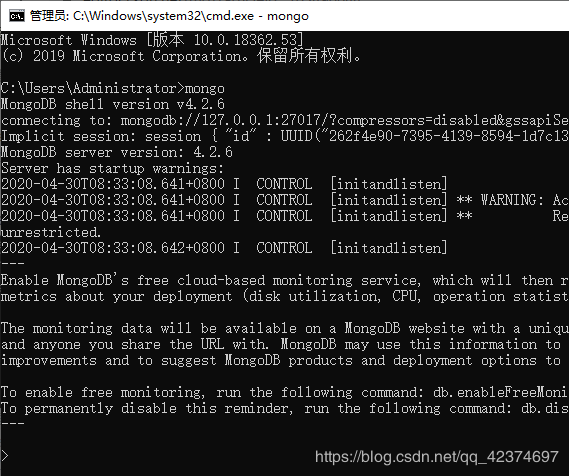
2、非关系型数据库和mongo的客户端服务端
Mongodb数据库
mongodb:非关系型数据库,也是一个文档型数据库,和mysql一样,都是将数据存储在硬盘。
mongodb 文档数据库,存储的是文档(Bson->json的二进制化),json数据存储的就是js中对象和数组
1、mongodb内部执行引擎是js,所以可以使用js代码
2、服务端客户端命令
mongo:客户端
mongo --host-h --port-p

mongod:服务端
mongod --dbpath(数据库存放数据的位置)
3、mongo基础命令和插入命令
注意:
mongo中
表称为------集合
行数据称为------文档
列字段称为-----域
show dbs 查看当前的数据库
use databaseName 选库
show collections 查看当前库下的collection(表),show tables

创建数据库的方法:mongo的数据库是隐式创建
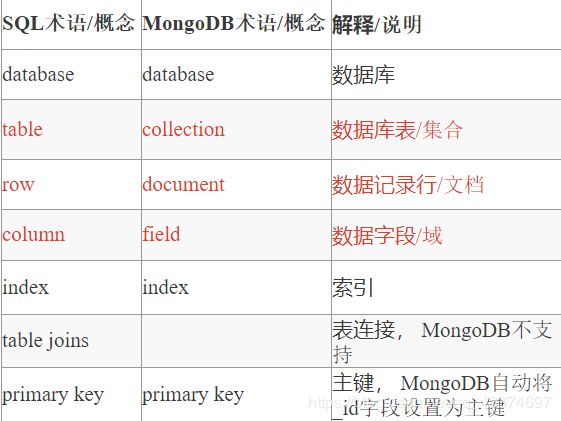
步骤:
1、 use 不存在的库命
2、 在这个库里面创建一个集合或者插入一条数据就创建好了
use dbname ---ues一个不存在的库
db ---代指当前的数据库
db.createCollection(‘collectionName’) ---在该库下面创建集合(表),就可以创建一个数据库
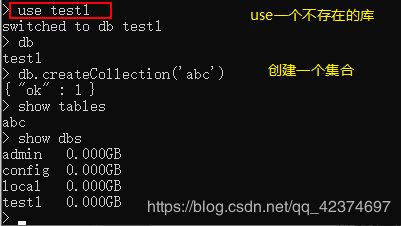
在MongoDB中,collection也是可以隐身创建的
db.collectionName.insert(document) 在集合(表)中插入数据
如何删除数据库和集合(表)?
db.collectionName.drop()//删除集合(表)
db.dropDatabase()//删除数据库
MongoDB基础增删改查操作
1、增:insert方法
首先要明确一点,MongoDB存储的是文档,文档(document)其实就是json格式的对象。
语法:
db.collectionName.insert(document)
增加单篇文档(行):
db.collectionName.insert({title:’nice day’})
db.python.insert({name:'zhangsan',age:9,scores:80}) 当前库下创建python表,在该表中插入数据
db.collectionName.insert({_id:8,age:78,name:’lisi’})
db.collectionName.insert([document1,document2,document3...])
一个document文档就是一个字典
db.python.insert(
[
{time:'friday',study:'mongodb'},
{_id:9,gender:'male',name:'QQ'}
]
)
use stu
db
db.python.insert([name:'zhangsan',age:'10']) #在stu数据库中创建python集合(表),在python集合中插入数据
show dbs
use stu
show tables
![]()
![]()
2、删除(行):remove
db.collection.remove({}, {})
db.collection.remove(查询表达式, 选项)
选项是指 {justOne:true/false},是否只删一行, 默认为false
注意:
1: 查询表达式依然是个json对象 {age:20}
2: 查询表达式匹配的行,将被删掉.
3: 如果不写查询表达式,collections(表)中的所有文档(行)将被删掉
例1:删除stu表中 sn属性值为’001’的文档(行)
db.stu.remove({sn:’001’})
例2: 删除stu表中gender属性为m的文档(行),只删除1行.
db.stu.remove({gender:’m’,true});
3、更新:update
语法:
db.collection.update({},{},{})
db.collection.update(查询表达式,新值,选项)
改谁? --- 查询表达式
改成什么样? -- 新值 或 赋值表达式
操作选项 ----- 可选参数
例:
db.news.update({name:'QQ'},{name:'MSN'});
是指选中news表中,name值为QQ的文档,并把其文档值改为{name:’MSN’},结果: 文档中的其他列也不见了,改后只有_id和name列了,即新文档直接替换了旧文档,而不是修改
如果是想修改文档的某列,可以用$set关键字:
db.collectionName.update({name:'zhangsan'},{$set:{name:'lisi'}})
修改时的赋值表达式
$set 修改某列的值
$unset 删除某个列
$rename 重命名某个列
$inc 增长某个列
Option的作用:{upsert:true/false,multi:true/false}
Upsert---是指没有匹配的行,则直接插入该行.
例:
db.stu.update({name:'wuyong'},{$set:{name:'junshiwuyong'}},{upsert:true});
如果有name=’wuyong’的文档,将被修改,如果没有,将添加此新文档
db.news.update({_id:99},{x:123,y:234},{upsert:true});
没有_id=99的文档被修改,因此直接插入该文档
multi: 是指修改多行(即使查询表达式命中多行,默认也只改1行(默认为F),如果想改多行,可以用此选项(multi=true))
批量更新用的比较多
db.news.update({age:21},{$set:{age:22}},{multi:true});
则把news中所有age=21的文档,都修改
4、查: find
学习之前,可以先安装Robomongo,就是操作MongoDB的一个可视化工具
https://robomongo.org/download

准备数据
goods.txt
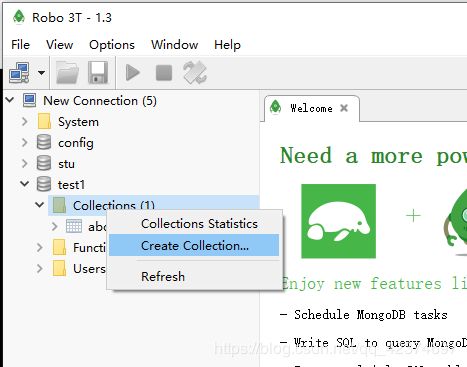
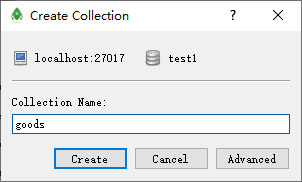
将数据插入
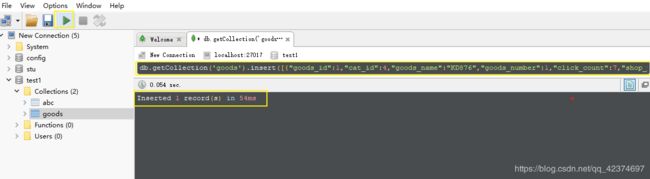

语法:
db.集合(表)名.find({},{});
db.collection.find(查询表达式,查询的列);
db.collections.find(表达式,{列1:1,列2:1}); 最后插入符合条件的列1和列2 后面的1表示显示与否
注意:
例如
查询所有文档 所有内容
db.stu.find()
查询所有文档,的gender属性 (_id属性默认总是查出来)
db.stu.find({},{gendre:1})
查询所有文档的gender属性,且不查询_id属性
db.stu.find({},{gender:1, _id:0})
查询所有gender属性值为male的文档中的name属性
db.stu.find({gender:’male’},{name:1,_id:0});
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。类似于 WHERE 语句:WHERE by=‘优就业’ AND title='MongoDB 教程。
语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
常用方法:
db.COLLECTION_NAME.find().limit(NUMBER)
db.COLLECTION_NAME.find().skip(NUMBER)
db.COLLECTION_NAME.find().sort({KEY:1})
db.mycol.count()
5、查询表达式:
db.getCollection('goods').find({goods_id:6},{_id:0,goods_name:1})
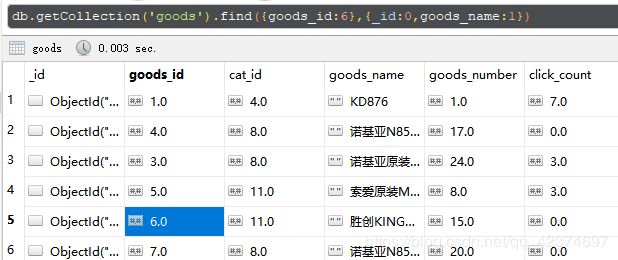
运行之后

db.goods.find({cat_id:{$nq:3}},{cat_id:1,goods_id:1,goods_name:1,_id:0})
//查询cat_id不等3的数据```
db.stu.find({age:{$lt:10}},{name:1,age:1}) 年龄小于10
db.stu.find({age:{$nin:[1,16]}})
语法:
{field:{$exists:1}} 存在
{field:{$exists:0}} 不存在
作用: 查询出含有field字段的文档
db.stu.find({hobby:{$exists:1}})
db.stu.insert({name:'xt',age:99,hobby:['aa','bb']})
db.stu.find({hobby:{$all:['aa','bb']}},{name:1,age:1,_id:0})
{$nor:[{条件1},{条件2},{条件3},...]} 查询所有条件都不满足的
{$and:[{条件1},{条件2},{条件3},...]}
{$or:[{条件1},{条件2},{条件3},...]}
例子
//主键为32的商品
db.goods.find({goods_id:32});

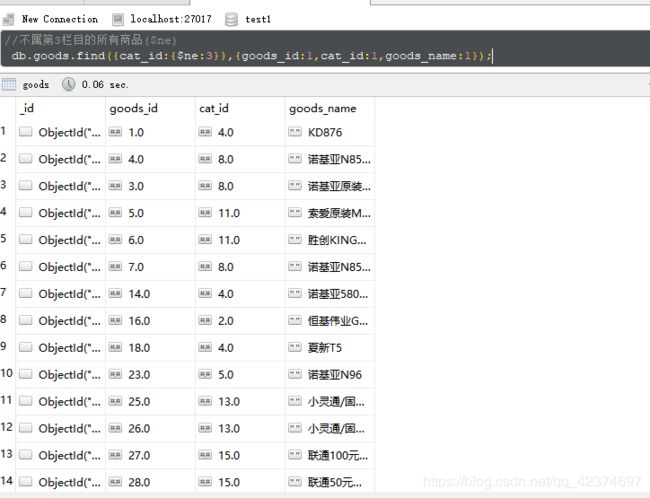
//不属第3栏目的所有商品($ne)
db.goods.find({cat_id:{$ne:3}},{goods_id:1,cat_id:1,goods_name:1});
//本店价格高于3000元的商品{$gt}
db.goods.find({shop_price:{$gt:3000}},{goods_name:1,shop_price:1});

//本店价格低于或等于100元的商品($lte)
db.goods.find({shop_price:{$lte:100}},{goods_name:1,shop_price:1});

//取出第4栏目或第11栏目的商品($in)
db.goods.find({cat_id:{$in:[4,11]}},{goods_name:1,shop_price:1});

//取出100<=价格<=500的商品($and)
db.goods.find({$and:[{price:{$gt:100},{price:{$lt:500}}}]);
//取出不属于第3栏目且不属于第11栏目的商品($and $nin和$nor分别实现)
db.goods.find({$and:[{cat_id:{$ne:3}},{cat_id:{$ne:11}}]} ,{goods_name:1,cat_id:1})
db.goods.find({cat_id:{$nin:[3,11]}},{goods_name:1,cat_id:1});
db.goods.find({$nor:[{cat_id:3},{cat_id:11}]},{goods_name:1,cat_id:1});
//取出价格大于100且小于300,或者大于4000且小于5000的商品()
db.goods.find({
$or:[
{
$and:[
{shop_price:{$gt:100}},
{shop_price:{$lt:300}}
]
},
{
$and:[
{shop_price:{$gt:4000}},
{shop_price:{$lt:5000}}
]
}
]},{goods_name:1,shop_price:1});
//取出goods_id%5 == 1, 即,1,6,11,..这样的商品
db.goods.find({goods_id:{$mod:[5,1]}});
//取出有age属性的文档
db.stu.find({age:{$exists:1}});
含有age属性的文档将会被查出
6、聚合 aggregate
MongoDB中聚合(aggregate)主要用于处理数据(诸如分组求统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
语法:
db.COLLECTION_NAME.aggregate(
[
{管道1},
{管道2},
{管道3},
...
]
)
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作是可以重复的。
聚合框架中常用的几个管道操作:
group中的一下操作表达式:
| 表达式 | 描述 |
|---|---|
| $sum | 计算总和 |
| $avg | 平均值 |
| $min | 最小值 |
| $max | 最大值 |
| $first | 根据资源文档的排序获取第一个文档数据。 |
| $last | 根据资源文档的排序获取最后一个文档数据 |
聚合操作练习:
1.查询每个栏目下的商品数量
db.collection.aggregate(); [{$group:{_id:"$cat_id",total:{$sum:1}}}]
2.查询goods下有多少条商品
db.goods.aggregate([{$group:{_id:null,total:{$sum:1}}}])
3.查询每个栏目下价格大于50元的商品个数
大于50元==》每个栏目下
db.goods.aggregate([{$match:{shop_price:{$gt:50}}}, {$group:{_id:"$cat_id",total:{$sum:1}}}])
4.查询每个栏目下的库存量
db.goods.aggregate([{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}])
5.查询每个栏目下 价格大于50元的商品个数 ,并筛选出"满足条件的商品个数" 大于等于3的栏目
(1)价格大于50:
{$match:{shop_price:{$gt:50}}}
(2)要想查出个数大于3的栏目,必须先对cat_id进行分组:
{$group:{_id:"$cat_id",total:{$sum:1}}}
(3)最后用match来去除大于3个的栏目
{$match:{total:{$gte:3}}}
6.查询每个栏目下的库存量,并按库存量排序
思路:
(1)按栏目的库存量分组(2)排序
{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}
{$sort:{total:1}}
db.goods.aggregate([{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}, {$sort:{total:1}}])
1是正序,-1是逆序
7.查询每个栏目的商品平均价格,并按平均价格由高到低排序
db.goods.aggregate([{$group:{_id:"$cat_id",avg:{$avg:"$shop_price"}}},{$sort:{avg:-1}}])
游标操作
mongo的游标相当于python中的迭代器。通过将查询结构定义给一个变量,这个变量就是游标。通过这个游标,我们可以每次获取一个数据。
索引创建
优化查询的首要考虑的东西就是索引。—降低写入速度。
索引提高查询速度,降低写入速度,[权衡常用的查询字段,不必在太多列上建索引]
在mongodb中,索引可以按字段升序/降序来创建,便于排序
默认是用btree来组织索引文件,2.4版本以后,也允许建立hash索引
常用命令:
(1)查看当前索引状态:db.collection.getIndexes()
(2)创建普通单列索引:db.collection.ensureIndex({field:1/-1})//1为正序,-1为逆序
(3)删除单个索引:db.collection.dropIndex({field:1/-1})
(4)删除所有索引:db.collection.dropIndexes() _id所在的列的索引不能删除。
(5)创建多列索引:db.collection.ensureIndex({field1:1/-1,field2:1/-1})
多列索引的使用范围更广,因为一般情况下,我们都是通过多个字段来进行查询数据的,这时候单列索引其实用不到。
两个列一起建立索引其实就是将两个列绑定到一起,来创建索引
(6)子文档索引:
子文档查询:
1.插入两条带子文档的数据
db.shop. insert({name: 'N0kia' , SPC: {weight: 120 , area: ' taiwan ' } } ) ;
db.shop. insert({name: 'sanxing ' , SPC :{weight: 100 , area: 'hanguo'} } ) ;
2.查询出产地在台湾的手机
db.shop.find({'spc.area':'taiwan'})
给子文档加索引:
db.shop.ensureIndex({'spc.area':1})//子文档就点就可以了
(7) 唯一索引:{unique:true}
db.collection.ensureIndex({field:1/-1},{unique:true})
唯一索引的列不能重复插入
(8)hash索引:
db.collection.ensureIndex({field:'hashed'})
MongoDB数据的导入导出
1、通用选项:
导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
--host host 主机
--port port 端口
-u username 用户名
-p passwd 密码
2、mongoexport 导出json格式的文件
-d 库名
-c 表名
-f field1,field2...列名
-q 查询条件
-o 导出的文件名
--type csv 导出csv格式(便于和传统数据库交换数据)
例1:
mongoexport -d test -c news -o test.json
例2: 只导出goods_id,goods_name列
mongoexport -d test -c goods -f goods_id,goods_name -o goods.json
例3: 只导出价格低于1000元的行
mongoexport -d test -c goods -f goods_id,goods_name,shop_price -q ‘{shop_price:{$lt:200}}’ -o goods.json
注: _id列总是导出
当初csv文件的时候,需要指定导出哪些列。
mongoexport -d shop -c goods -o goods.csv --type csv -f goods_id,cat_id,goods_name,shop_price
3、Mongoimport 导入
-d 待导入的数据库
-c 待导入的表(不存在会自己创建)
--file 备份文件路径
例1: 导入json
mongoimport -d test -c goods --file ./goodsall.json
例2: 导入csv
mongoimport -d test -c goods --type csv -f goods_id,goods_name --file ./goodsall.csv
4、mongodump 导出二进制bson结构的数据及其索引信息
-d 库名
-c 表名
mongodum -d test [-c 表名] 默认是导出到mongo下的dump目录
规律:
导出的文件放在以database命名的目录下
每个表导出2个文件,分别是bson结构的数据文件, json的索引信息
如果不声明表名, 导出所有的表
5、mongorestore 导入二进制文件
mongorestore -d shop -c goods --dir ./dump/shop/goods.bson
mongorestore -d sh
二进制备份,不仅可以备份数据,还可以备份索引,备份数据比较小.速度比较快。
replaction复制集
一般情况下,我们通常在机器上安装了一个数据库,这是我们的数据都是存在这个数据库中的,如果有一天,因为一些不可控因素导致数据库宕机或者数据库的文件丢失,此时损失就很大了。针对于这种问题,我们希望有一个数据库集,在我们其中一个数据库进行插入的时候,其他数据库也能插入数据,这样其中一台服务器宕机了,也能够使我们的数据正常存取。
在MongoDB中,是通过replaction复制集来实现此功能的。
在Windows下实现复制集的方法:
创建复制集之前,把所有的mongo服务器都关掉
1、创建三个存储数据库的文件夹,用来保存数据文件

2、打开三个cmd窗口,分别启动三个mongodb:启动三个mongo服务端:分别绑定在27017,27018,27019三个端口。
mongod --dbpath C:\MongoDB\Server\3.4\data\m1 --logpath C:\MongoDB\Server\3.4\data\logs\mongo1.log --port 27017 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m2 --logpath C:\MongoDB\Server\3.4\data\logs\mongo2.log --port 27018 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m3 --logpath C:\MongoDB\Server\3.4\data\logs\mongo3.log --port 27019 --replSet rs
其中的–replSet就表示创建的数据集的名称,必须指定相同的名称才可以。
3、配置:用客户端连接27017端口的服务器,在这个下面配置
var rsconf = {
_id:'rs',
members:[
{_id:0,host:'127.0.0.1:27017'},
{_id:1,host:'127.0.0.1:27018'},
{_id:2,host:'127.0.0.1:27019'}
]
}
这时候我们可以打印rsconf来看一下
printjson(rsconf)
接下来需要将配置初始化
rs.initiate(rsconf)
现在我们看到,现在登录客户端已经不是哪台机器,而是rs复制集
我们在主机上插入一条数据,再从机上必须输入rs.slaveOk()之后才能被允许查看数据
在输入rs.status(),可以看到数据集现在又是三个了。
二、Redis
redis数据库运行在内存上,可以持久化到硬盘。 当redis启动的时候,就会从硬盘上读出数据,全部加载到内存中,让用户使用。
1、数据结构丰富
数据结构都有哪几种。每一种的结构要有清晰直观的概念。每种数据结构优势还有作用都有哪些。
hash表:[{},{},{}]
string:key:value
list:[1,2,3,4,5,6]
set:{a1,a2,a3}--不重复
2、可以持久化到硬盘。