31机器学习项目实战-用户流失预警
唐宇迪《python数据分析与机器学习实战》学习笔记
31机器学习项目实战-用户流失预警
1.数据简单介绍
挽留一个老客户的费用<扩展一个新用户费用,所以通过预测给部分老用户大礼包让其留下来。
这里使用的数据为一个国外的电信商数据:
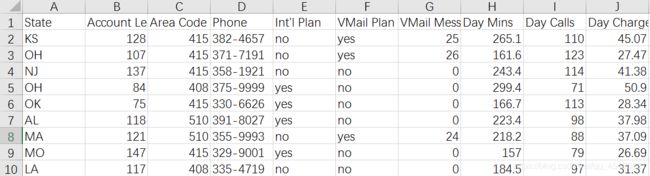
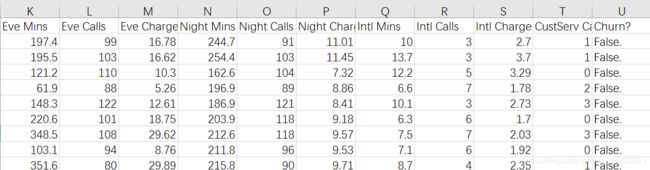
这个小项目没做特征工程,大致走一下流程,所以这里只简单谈一下数据:D手机号码、E/F参加某个计划、H/I/J白天打了多少时间/个数/话费,K/L/M下午,N/O/P晚上,Q/R/S国际长途,U就是Label:用户是否流失了。False没流失、True流失了。
2.数据导入及简单筛选
#模块导入
from __future__ import division
import pandas as pd
import numpy as np
#数据读取
churn_df = pd.read_csv('churn.csv')
col_names = churn_df.columns.tolist()
print "Column names:"
print col_names
to_show = col_names[:6] + col_names[-6:]
print "\nSample data:"
churn_df[to_show].head(6)
数据的丢除、转换、归一化
churn_result = churn_df['Churn?']
y = np.where(churn_result == 'True.',1,0)
# 丢除无用列
to_drop = ['State','Area Code','Phone','Churn?']
churn_feat_space = churn_df.drop(to_drop,axis=1)
# 把Yes/No转换为布尔值1/0
yes_no_cols = ["Int'l Plan","VMail Plan"]
churn_feat_space[yes_no_cols] = churn_feat_space[yes_no_cols] == 'yes'
# 拿出之后使用的特征
features = churn_feat_space.columns
X = churn_feat_space.as_matrix().astype(np.float)
#把数值归一化处理,不同特征间的数值上的巨大差异会影响我们的分析,有些压缩到[0-1]本质是(x-min)/(max-min)
#也可以压缩到自己设定的区间,这里是[-1,2]
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
print ("Feature space holds %d observations and %d features" % X.shape)
print( "Unique target labels:", np.unique(y))
print( X[0])
print (len(y[y == 0]))
Feature space holds 3333 observations and 17 features
Unique target labels: [0 1]
[ 0.67648946 -0.32758048 1.6170861 1.23488274 1.56676695 0.47664315 1.56703625 -0.07060962 -0.05594035 -0.07042665 0.86674322 -0.46549436 0.86602851 -0.08500823 -0.60119509 -0.0856905 -0.42793202]
2850
这里看出,总共3333个,可能流失的为2850个,不流失的只有500多个,数据出现了不均衡。
3.尝试多种分类器效果
这里定义一个函数,根据你输入的分类器及参数,交叉验证训练模型并预测
from sklearn.model_selection import KFold
#交叉验证函数:X是特征数据,y是label,clf_class分类器,kwargs分类器参数
def run_cv(X,y,clf_class,**kwargs):
kf = KFold(n_splits=5,shuffle=True)#数据分为5份,4份训练1份测试,如此轮流
y_pred = y.copy()
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train = y[train_index]
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)#训练分类器
y_pred[test_index] = clf.predict(X_test)#预测
return y_pred
训练:SVM、随机森林、K近邻,并计算准确率
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier as RF
from sklearn.neighbors import KNeighborsClassifier as KNN
def accuracy(y_true,y_pred):
# NumPy interprets True and False as 1. and 0.
return np.mean(y_true == y_pred)
print("支持向量机:")
print("%.3f" % accuracy(y, run_cv(X,y,SVC)))
print("随机森林:")
print("%.3f" % accuracy(y, run_cv(X,y,RF)))
print("K近邻:")
print("%.3f" % accuracy(y, run_cv(X,y,KNN)))
Support vector machines:
0.920
Random forest:
0.954
K-nearest-neighbors:
0.893
四、结果衡量指标的意义
准确率意义:看预测与实际是否相同,但是数据不平衡,假设95个为0、5个为1,你全部预测为0精度95%,无意义
这个项目重点关注的是:我预测客户不会流失,但是客户流失了。所以这里引进**“召回率”**,表示的是样本中的正例有多少被预测正确。
召回率R = TP/(TP+FN) 。
个人备注:准确率A(Accuracy)=TP+TN/(TP+FP+TN+FN);**精确率(Precision)P=TP/(TP+FP)**表示预测为正的样本中有多少是实际的正样本;F1值(H-mean值)= 精确率 * 召回率 * 2 / ( 精确率 + 召回率)=2TP/(2TP+FP+FN)。

采用多个指标 去衡量模型。Map(Multiple Average Precision)其实就是取PR和的平均值。
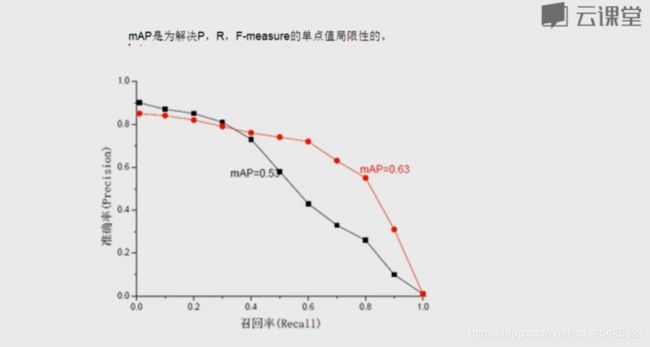
五、应用阀值得出结果
有些用户可能80%丢失、有些70%丢失,肯定先管大概率丢失用户,因此阀值的设定很关键。把之前所算转化为概率值。
def run_prob_cv(X, y, clf_class, **kwargs):
kf = KFold(n_splits=5,shuffle=True)
y_prob = np.zeros((len(y),2))
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train = y[train_index]
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)
# 预测概率,而不是分类
y_prob[test_index] = clf.predict_proba(X_test)
return y_prob
import warnings
warnings.filterwarnings('ignore')
# 建立10棵树,这样预测值都是0.1的倍数
pred_prob = run_prob_cv(X, y, RF, n_estimators=10)
print (pred_prob[0])
pred_churn = pred_prob[:,1]
is_churn = y == 1
# Number of times a predicted probability is assigned to an observation
counts = pd.value_counts(pred_churn)
print(counts)
# 计算真实准确率
true_prob = {}
for prob in counts.index:
true_prob[prob] = np.mean(is_churn[pred_churn == prob])
true_prob = pd.Series(true_prob)
# pandas-fu
counts = pd.concat([counts,true_prob], axis=1).reset_index()
counts.columns = ['pred_prob', 'count', 'true_prob']
counts
[0.9 0.1]
0.0 1761
0.1 708
0.2 270
0.3 110
0.7 81
0.8 71
0.4 71
0.6 69
0.9 67
0.5 66
1.0 59
dtype: int64
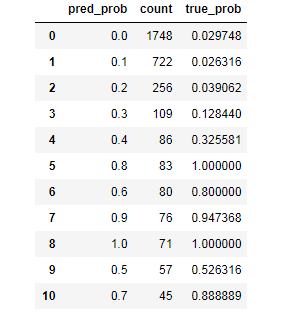
通过观测以上数据选择阀值进行预警,这里可以选择0.7,以上的管,以下的不管。