用机器学习来提升你的用户增长:第一步,了解你的目标
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Barış KaramanFollow
编译:ronghuaiyang
正文共:10130 字 24 图
预计阅读时间:29 分钟
导读
这一系列的文章通过了一个实际的案例,向大家介绍了如何使用机器学习的方式来对公司的用户增长做提升,如果你对用户增长这部分不是很了解的话,这篇文章会带你走过整个流程,包括了数据分析,编程,以及机器学习各个方面。
第一部分:了解你的指标

我们都记得加勒比海盗中杰克船长的著名的罗盘,它显示了他最想要的东西的位置。在我们的用户增长中,没有北极星指标,这就是我们的增长方式。我们想要更多的客户,更多的订单,更多的收入,更多的注册,更高的效率……
在写代码之前,我们需要了解究竟什么是北极星指标。如果你已经了解并跟踪了北极星指标,这篇文章可以帮助您你入分析Python。如果你不知道,首先你应该找到你的北极星指标(可能你已经在跟踪它,但没有把它命名为北极星指标)。Sean Ellis是这样描述的:
北极星指标是指可以最好的抓住你的产品交付给客户的核心价值的单个指标。
这个指标取决于你公司的产品、定位、目标等等。Airbnb的北极星指标是预定的天数,而Facebook的指标是每日活跃用户数。
在我们的例子中,我们会使用一个在线零售的数据集。对于在线零售,我们可以选择我们的月收入作为北极星指标。
月收入
让我们从导入我们需要的库开始,然后使用pandas从CSV中读取数据:
# import libraries
from datetime import datetime, timedelta
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from __future__ import division
import plotly.plotly as py
import plotly.offline as pyoff
import plotly.graph_objs as go
#initiate visualization library for jupyter notebook
pyoff.init_notebook_mode()
tx_data = pd.read_csv('data.csv')
tx_data.head(10)
我们的数据看起来是这样的:
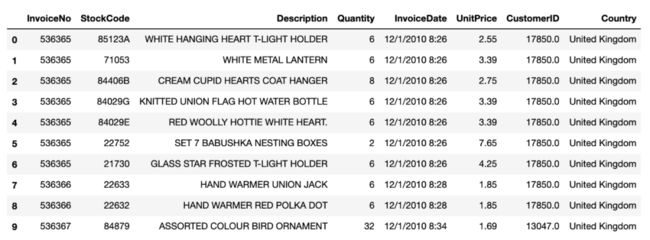
我们有我们需要的所有重要信息:
客户ID
单价
数量
订单日期
有了所有这些特征,我们可以建立我们的北极星指标方程:
月收入 = 活跃用户数量 * 订单数量 * 平均订单价格
我们现在可以动手试试了。我们希望看到每月的收入,但不幸的是,没有免费的午餐。我们对数据做一些处理:
#converting the type of Invoice Date Field from string to datetime.
tx_data['InvoiceDate'] = pd.to_datetime(tx_data['InvoiceDate'])
#creating YearMonth field for the ease of reporting and visualization
tx_data['InvoiceYearMonth'] = tx_data['InvoiceDate'].map(lambda date: 100*date.year + date.month)
#calculate Revenue for each row and create a new dataframe with YearMonth - Revenue columns
tx_data['Revenue'] = tx_data['UnitPrice'] * tx_data['Quantity']
tx_revenue = tx_data.groupby(['InvoiceYearMonth'])['Revenue'].sum().reset_index()
tx_revenue
好了,现在我们有了一个显示我们每月收入的dataframe:

下一步,可视化,画个折线图就可以了:
#X and Y axis inputs for Plotly graph. We use Scatter for line graphs
plot_data = [
go.Scatter(
x=tx_revenue['InvoiceYearMonth'],
y=tx_revenue['Revenue'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Montly Revenue'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)

这清楚地表明我们的收入在增长,尤其是在2011年8月11日以后(我们12月的数据是不完整的)。绝对数字是好的,让我们看看我们的月收入增长率是多少:
#using pct_change() function to see monthly percentage change
tx_revenue['MonthlyGrowth'] = tx_revenue['Revenue'].pct_change()
#showing first 5 rows
tx_revenue.head()
#visualization - line graph
plot_data = [
go.Scatter(
x=tx_revenue.query("InvoiceYearMonth < 201112")['InvoiceYearMonth'],
y=tx_revenue.query("InvoiceYearMonth < 201112")['MonthlyGrowth'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Montly Growth Rate'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
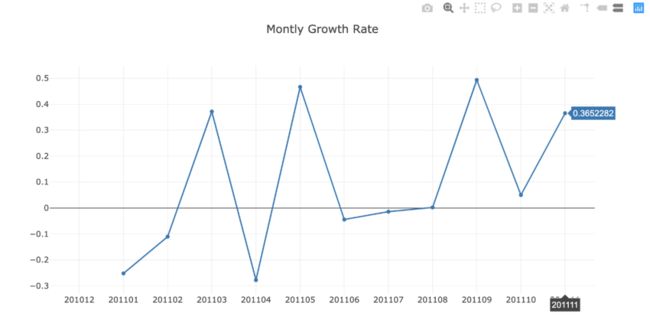
一切看起来都很好,上个月我们看到了36.5%的增长(12月没有包含在代码中,因为它还没有完成)。但我们需要看看4月份到底发生了什么。是由于客户的活跃度降低,还是我们的客户的订单减少?也许他们只是开始买更便宜的产品了?如果不做深入的分析,我们什么也不知道。
月活跃客户
要查看每月活跃客户的详细信息,我们将按照我们对每月收入所做的步骤进行操作。从这一部分开始,我们将只关注英国的数据(记录最多的国家)。我们可以通过计算唯一的CustomerIDs来获得每月的活跃客户。代码和输出如下:
#creating a new dataframe with UK customers only
tx_uk = tx_data.query("Country=='United Kingdom'").reset_index(drop=True)
#creating monthly active customers dataframe by counting unique Customer IDs
tx_monthly_active = tx_uk.groupby('InvoiceYearMonth')['CustomerID'].nunique().reset_index()
#print the dataframe
tx_monthly_active
#plotting the output
plot_data = [
go.Bar(
x=tx_monthly_active['InvoiceYearMonth'],
y=tx_monthly_active['CustomerID'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Active Customers'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
每个月的活跃客户以及柱状图:


4月份,月活跃客户数量从923个降至817个(-11.5%)。我们还会看到订单数量的同样趋势。
月订单数量
我们对 Quantity字段使用同样的代码:
#create a new dataframe for no. of order by using quantity field
tx_monthly_sales = tx_uk.groupby('InvoiceYearMonth')['Quantity'].sum().reset_index()
#print the dataframe
tx_monthly_sales
#plot
plot_data = [
go.Bar(
x=tx_monthly_sales['InvoiceYearMonth'],
y=tx_monthly_sales['Quantity'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Total # of Order'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
月订单数量以及柱状图:
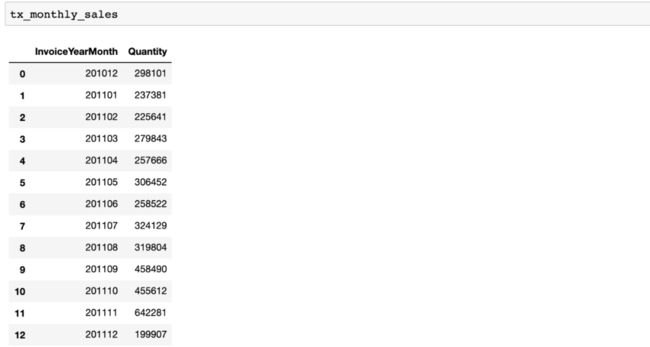

正如我们所预期的,4月份的订单数量也下降了(279k到257k,下降了8%)。
我们知道活跃客户数量直接影响订单数量的减少。最后,我们还应该检查一下我们的平均订单收入。
平均订单收入
为了得到这个数据,我们需要计算每个月的平均订单收入:
# create a new dataframe for average revenue by taking the mean of it
tx_monthly_order_avg = tx_uk.groupby('InvoiceYearMonth')['Revenue'].mean().reset_index()
#print the dataframe
tx_monthly_order_avg
#plot the bar chart
plot_data = [
go.Bar(
x=tx_monthly_order_avg['InvoiceYearMonth'],
y=tx_monthly_order_avg['Revenue'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Order Average'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
月平均订单收入以及柱状图:

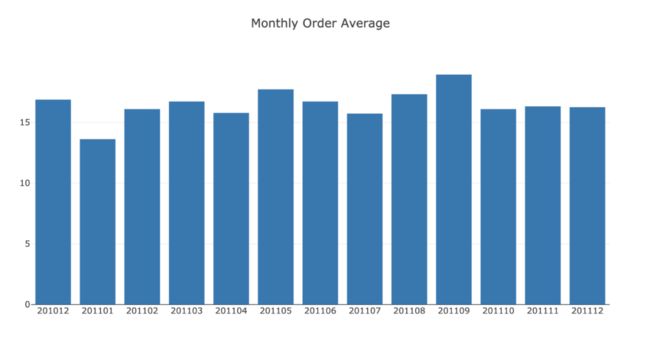
甚至4月份的月平均订单量也下降了(16.7至15.8)。我们观察到影响北极星指标的每一个指标都在下降。
我们已经看到了我们的主要指标。当然还有很多不同的指标,根据行业的不同。让我们继续研究其他一些重要的指标:
新客户比例:如果我们正在失去现有的客户或无法吸引新的客户,这是一个很好的指标
留存率:指标之王。指示在特定时间段内我们保留了多少客户。我们将展示月度留存率和基于群组的留存率的例子。
新客户比例
首先,我们应该定义什么是新客户。在我们的数据集中,我们可以假设新客户是在我们定义的时间窗口中进行第一次购买的人。对于这个例子,我们将按月执行。
我们将使用**.min()**函数来查找每个客户的首次购买日期,并在此基础上定义新客户。下面的代码将应用此函数,并向我们显示每个组每月的收入明细。
#create a dataframe contaning CustomerID and first purchase date
tx_min_purchase = tx_uk.groupby('CustomerID').InvoiceDate.min().reset_index()
tx_min_purchase.columns = ['CustomerID','MinPurchaseDate']
tx_min_purchase['MinPurchaseYearMonth'] = tx_min_purchase['MinPurchaseDate'].map(lambda date: 100*date.year + date.month)
#merge first purchase date column to our main dataframe (tx_uk)
tx_uk = pd.merge(tx_uk, tx_min_purchase, on='CustomerID')
tx_uk.head()
#create a column called User Type and assign Existing
#if User's First Purchase Year Month before the selected Invoice Year Month
tx_uk['UserType'] = 'New'
tx_uk.loc[tx_uk['InvoiceYearMonth']>tx_uk['MinPurchaseYearMonth'],'UserType'] = 'Existing'
#calculate the Revenue per month for each user type
tx_user_type_revenue = tx_uk.groupby(['InvoiceYearMonth','UserType'])['Revenue'].sum().reset_index()
#filtering the dates and plot the result
tx_user_type_revenue = tx_user_type_revenue.query("InvoiceYearMonth != 201012 and InvoiceYearMonth != 201112")
plot_data = [
go.Scatter(
x=tx_user_type_revenue.query("UserType == 'Existing'")['InvoiceYearMonth'],
y=tx_user_type_revenue.query("UserType == 'Existing'")['Revenue'],
name = 'Existing'
),
go.Scatter(
x=tx_user_type_revenue.query("UserType == 'New'")['InvoiceYearMonth'],
y=tx_user_type_revenue.query("UserType == 'New'")['Revenue'],
name = 'New'
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='New vs Existing'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
与首次购买日期合并后的Dataframe的输出:
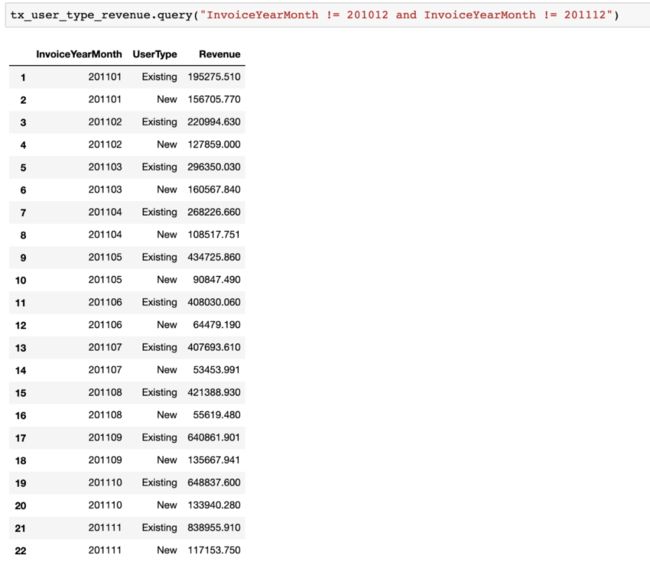
新客户和现有客户的月收入:
把上面画成图表:

现有客户显示出正的趋势,并告诉我们,我们的客户群正在增长,但新客户有轻微的下降趋势。
让我们来看看新客户比例:
#create a dataframe that shows new user ratio - we also need to drop NA values (first month new user ratio is 0)
tx_user_ratio = tx_uk.query("UserType == 'New'").groupby(['InvoiceYearMonth'])['CustomerID'].nunique()/tx_uk.query("UserType == 'Existing'").groupby(['InvoiceYearMonth'])['CustomerID'].nunique()
tx_user_ratio = tx_user_ratio.reset_index()
tx_user_ratio = tx_user_ratio.dropna()
#print the dafaframe
tx_user_ratio
#plot the result
plot_data = [
go.Bar(
x=tx_user_ratio.query("InvoiceYearMonth>201101 and InvoiceYearMonth<201112")['InvoiceYearMonth'],
y=tx_user_ratio.query("InvoiceYearMonth>201101 and InvoiceYearMonth<201112")['CustomerID'],
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='New Customer Ratio'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
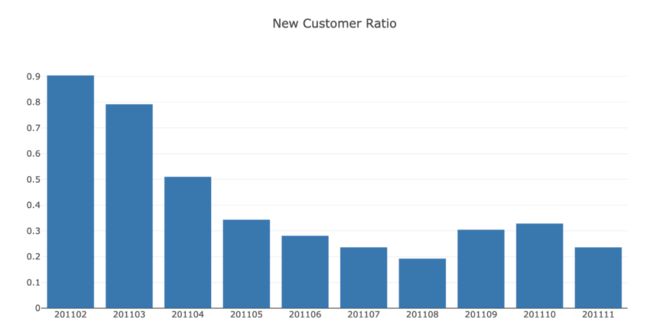
新客户比例如预期般下降(我们在2月时假设所有客户都是新客户),并在20%左右。
月留存率
留存率应该被密切监控,因为它表明了你的服务的黏性,你的产品有多适合市场。为了使月留存率可视化,我们需要计算上个月留存了多少客户。
月留存率 = 上个月的留存客户/总的活跃客户
我们使用pandas中的crosstab()函数,可以非常简单的算出留存率:
#identify which users are active by looking at their revenue per month
tx_user_purchase = tx_uk.groupby(['CustomerID','InvoiceYearMonth'])['Revenue'].sum().reset_index()
#create retention matrix with crosstab
tx_retention = pd.crosstab(tx_user_purchase['CustomerID'], tx_user_purchase['InvoiceYearMonth']).reset_index()
tx_retention.head()
#create an array of dictionary which keeps Retained & Total User count for each month
months = tx_retention.columns[2:]
retention_array = []
for i in range(len(months)-1):
retention_data = {}
selected_month = months[i+1]
prev_month = months[i]
retention_data['InvoiceYearMonth'] = int(selected_month)
retention_data['TotalUserCount'] = tx_retention[selected_month].sum()
retention_data['RetainedUserCount'] = tx_retention[(tx_retention[selected_month]>0) & (tx_retention[prev_month]>0)][selected_month].sum()
retention_array.append(retention_data)
#convert the array to dataframe and calculate Retention Rate
tx_retention = pd.DataFrame(retention_array)
tx_retention['RetentionRate'] = tx_retention['RetainedUserCount']/tx_retention['TotalUserCount']
#plot the retention rate graph
plot_data = [
go.Scatter(
x=tx_retention.query("InvoiceYearMonth<201112")['InvoiceYearMonth'],
y=tx_retention.query("InvoiceYearMonth<201112")['RetentionRate'],
name="organic"
)
]
plot_layout = go.Layout(
xaxis={"type": "category"},
title='Monthly Retention Rate'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
首先,我们创建一个dataframe,显示每个客户的每月总收入:

用**crosstab()**函数转换成留存表:

留存表显示了每个月哪些客户是活跃的(1代表活跃)。
用一个简单的for循环,对于每个月,我们计算前一个月的留存客户数量和总客户数量。
最后,我们得到了我们的留存率dataframe以及折线图,如下:


月留存率从6月到8月显著上升,之后又回到以前的水平。
基于群体的留存率
还有另一种度量留存率的方法可以让你看到每个群体的留存率。这个群体被定义为客户的第一次购买年份-月份。我们将度量每个月第一次购买后留存客户的比例。这个视图将帮助我们了解最近的和过去的客户群体在留存率方面有何不同,以及最近的客户体验变化是否影响了新客户的留存率。
在代码方面,要比其他的复杂一些。
#create our retention table again with crosstab() - we need to change the column names for using them in .query() function
tx_retention = pd.crosstab(tx_user_purchase['CustomerID'], tx_user_purchase['InvoiceYearMonth']).reset_index()
new_column_names = [ 'm_' + str(column) for column in tx_retention.columns]
tx_retention.columns = new_column_names
#create the array of Retained users for each cohort monthly
retention_array = []
for i in range(len(months)):
retention_data = {}
selected_month = months[i]
prev_months = months[:i]
next_months = months[i+1:]
for prev_month in prev_months:
retention_data[prev_month] = np.nan
total_user_count = retention_data['TotalUserCount'] = tx_retention['m_' + str(selected_month)].sum()
retention_data[selected_month] = 1
query = "{} > 0".format('m_' + str(selected_month))
for next_month in next_months:
query = query + " and {} > 0".format(str('m_' + str(next_month)))
retention_data[next_month] = np.round(tx_retention.query(query)['m_' + str(next_month)].sum()/total_user_count,2)
retention_array.append(retention_data)
tx_retention = pd.DataFrame(retention_array)
tx_retention.index = months
#showing new cohort based retention table
tx_retention
Tx_retention就是这个基于群体的留存率视图:

我们可以看到,第一个月的客户留存率最近变得更好了(不考虑12月11日),在近1年的时间里,只有7%的客户留了下来。
现在,我们知道了我们的度量标准以及如何使用Python跟踪/分析它们。
代码链接:https://gist.github.com/karamanbk/314d3d5483b9be1d2cc7f9694368f3bc
后面,我们会尝试划分我们的客户,看看哪些是最好的客户。

—END—
英文原文:https://towardsdatascience.com/data-driven-growth-with-python-part-1-know-your-metrics-812781e66a5b

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!