近段时间AlfaGo 与人的围棋大战进行的非常火热,人间对AI、围棋的讨论都特别的热闹,这是《数学之美》后,又一个来自Google的讯息。突然对写这篇笔记感到激情蓬勃。
几句话的书评:
这是一本科普书,书中介绍了如何应用数学来解决数字领域内的诸多问题,包括自然语言处理、搜索引擎中的诸多问题。我们首先对自然语言处理、搜索引擎有过直观的认识,便更有兴趣去理解这些如此酷的事物中的原理。我想这是能读下这本书,于我来说最大的动力,也是这本书最吸引人的地方——它试图用最直白的语言阐释我们触手可及的玄妙,而且成功的做到了。现代教育中,如果能够引入这样的方式,即,知识和很酷的应用结合,我相信应该会成效颇丰。
接下来的内容,对书中的一些句子做了摘录,并简单描述书中介绍的原理。
从希腊哲学到现代物理学的整个科学史中,不断有人力图把表面上极为复杂的自然现象归结为几个简单的基本概念和关系。这就是整个自然哲学的基本原理——爱因斯坦
简单性和模块化是软件工程的基石;分布式和容错性是互联网的生命。——蒂姆·伯纳斯·李(WWW的发明人)
分布式计算和服务器集群,甚至到磁盘阵列,都利用类似这种分布式的处理概念。而模块化和简单性则是模块复用,提升软件编写效率的基本规则。
数学是上帝描写自然的语言。——伽利略
纯数学使我们能够发现概念和联系这些概念的规律,这些概念和规律给了我们理解自然的钥匙。——爱因斯坦
第一章 文字和语言vs数字和信息
本章介绍了很多信息论相关的知识,在我的脑海中第一次把文字和数字作为信息在概念上进行了统一。
“语言和数学的产生都是为了同一个目的——记录和传播信息。”
文字的起源
“我们的祖先迅速学习新鲜的事物,语言也越来越丰富,越来越抽象。语言描述的共同要素,比如物体、数量和动作便抽象了出来,形成了今天的词汇。当语言词汇多到一定的程度,人类仅靠自己的大脑已经记不住所有的词汇了。这就如同今天没有人能够记住人类所有的知识一样。于是,高效记录信息的需求便产生了,这便是文字的起源。”
概念的聚类以及引发的问题
依据上下文来处理文字聚类带来的歧义性。
在文字的产生过程中,我们不可能为每一个我们遇到的事物创建一个字或者词来描述,因为人们往往很难记住那么多的文字,于是有了文字按照意思来进行聚类,汉语中我们有多音字、多义字也是出于这样的考虑。由此引发的问题,对字词概念的理解时,最终会带来一些歧义。歧义问题的解决多数是依据上下文来进行进一步的处理。(这在后面做自然语言处理时也用到了这样的方式来处理)
文字和数字本身,实际上是对现实世界人类认识的一种编码。
在这里想起了之前看的电视节目《中国成语大会》,由此联想到很多事物的聚类可能比单纯的字词的聚类更复杂,像是“成语”也是一种特殊的事件的抽象。
也想起了一篇文章中关于未来电影桥段的笑话,未来我们对所有的笑话进行编码,当所有人都具备对这些编码理解的知识时,我们说笑话就会是这样:“0851”,就能引起了满堂大笑,就好像现在说个“嘿嘿嘿”也能哄堂大笑一样,而电影将变成一种编码组合的技术。编码是一种抽象,聚类是对这些抽象进行一定规则的整合。
进一步有联想到了《最强大脑》中,记忆高手对记忆事物的编码,用一种自己熟悉的编码方式,把需要记忆物体的特征,进行特定的编码,回忆时进行高效的解码。就比如常用的记忆术中,在教你如何记住一长串无关联的事物时采用的方法:比如说让你记一长串水果的名字,首先让你选一条你最常走、最熟悉的道路,走一段路就和一种水果发生交集,在回忆时就再把那段路在走一遍,实际上使用最熟悉的直观经验抽象,对这些需要记忆的事物做了一个编码。
再回到现在的编程技术中,目前最能规避歧义的抽象语言,应当是各种编程语言了,编程语言和自然语言相比,需要描述的东西较少,仅仅限定在描述“逻辑”和“数理”这件事情上,自然语言需要描述的明显比“逻辑”宽泛很多。不可否认,编程语言的编码方式也在不断向自然语言编码方式靠近,以求可以更简单的让人理解。
本章援引了一些现有技术最初的借鉴。
“罗塞塔石碑”
罗塞塔石碑是一块在罗塞塔这个地方被发现的,使用三种语言记录了托勒密(我也不认识)五世登基的诏书。这块石碑的意义在于:
“
使得近代的考古学家得以有机会对照各语言版本的内容后,解读出已经失传千余年的埃及象形文之意义与结构,而成为今日研究古埃及历史的重要里程碑。”(百度百科)信息冗余,使得这块石碑的内容得以在经过历史这条“信道”进行传承时,保留完整的数据信息,人们对信道编码的冗余进行了思考。(当今很多的翻译软件和服务都叫做“罗塞塔”)

“古犹太人的圣经校验码”
虔诚的教徒们,为了保证在不抄错圣经,将每一个希伯来字母对应一个数字,每一行的字母相加会得到一个数字,每一列的字母相加相加会得到一个数字。在抄写完一行之后将新的校验码与原文的对照,看是否相同。这样的方式真心累,也就拼音文字这种不直观的表达文字容易出问题。象形文字反倒容易直观的看出来,不过,毕竟象形文字不能简单的数字编码,不可能做这样的编码(汉字有四角码哟,不过操作起来感觉也好累)。

“中国古人的文言文编码”
中国人有一个很直观的概念,文言文比白话文精简、凝练。本书中提出,这样的古文书写方式,是为了在“信道”——竹简、布帛(那时候成本比较高)上尽量承载更多的信息,而对白话文的信息做了一定程度上的压缩编码。我第一次在这个角度上理解中国的文言文。嗯,这一压缩,“丰富”了多少个高中的早自习。
”印度人发明了0-9这10个阿拉伯数字“
”不会唱歌的厨子,不是好司机“
-------------------------------------------------
-------------------------------------------------
-------------------------------------------------
第二章 自然语言处理 从规则到统计
语言,一直被认为是地球上生物中人类的特质。早期人们相信,如果需要处理语言的信息,就必须让机器具有一定的智能。由此本章实际从人工智能这件事情出发来引出自然语言处理。
”图灵测试“
这是个任性的测试,用于定性机器是否具有人工智能,测试的结果很主观,让测试者和机器交流,只要测试者分辨不出与他沟通的是人还是机器,那么ta就具有人工智能。电影《机械姬》就主要就是讲述了一个类似的测试,不过,私下将《机械姬》定义为一部恐怖片。恐怖之处在于,ta 懂人性条件下人的行为模式却没有人性,知道道德体制下人的作为而不知道自己应该受道德的约束,电影中ta成功的欺骗了男主角……关于人工智能和人类的情感互动《她》这部电影中也描述的很好。
”一次伟大的会议“
”达特茅斯夏季人工智能研讨会“ 这场会议中讨论了当时计算机科学领域内没有解决的问题:人工智能、自然语言处理、神经网络等。虽然会议并没有实质上解决什么问题,但是吴军认为”达特茅斯会议的意义超过10位图灵奖“ 与会的10位科学家每一位在各自领域内都做出了非凡的成绩。
“早期的语言处理思路和基于统计的语言处理的提出”
直到前不久,我仍然认为自然语言处理的计算机,至少有了和我们一样的理解语言的能力。而最初的自然语言处理的思路,也是向着让计算机理解句子结构出发来做自然语言处理的。早期的自然语言处理系统的设计如下图所示:
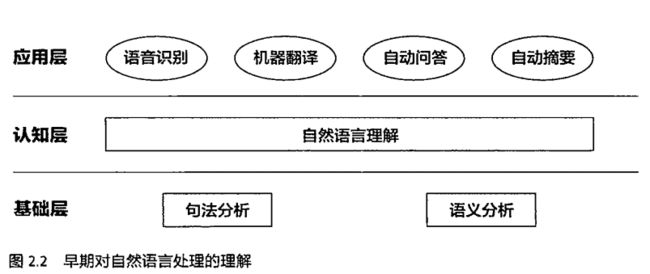
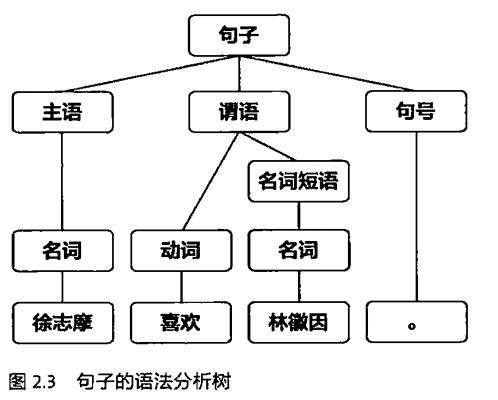
在这样的系统设计之下,即使是一条非常短的句子,也需要一个长长的语法分析树来对句子进行分析。而对于不同的句子,需要有不同的语法分析方式,早期的语法分析规则全是由人工录入的。书中列出了对于文法分析规则中面对到的两个突出问题:
1.首先,要想通过文法规则覆盖哪怕20%的真实语句,文法规则的晒单至少也是几万条。
2.即使写出涵盖所有自然语言现象的语法规则集合也很难用计算机来解析。(基于上下文的文法分析,复杂度是语句长度的六次方)
“可以说,利用计算机处理自然语言的努力直到20世纪70年代初始相当失败的。1970以后的统计语言学的出现使得自然语言处理重获新生,并取得今天非凡的成就。推动这个技术路线转变的关键人物是
Frederick Jelinek
和他领导的IBM华生实验室。”基于统计的方法,使得IBM将当时的语音识别率从70%提升到了90%,同时语音识别的规模从几百单词到几万单词,这样语音识别从实验室走向实际应用的成为可能。
-------------------------------------------------
-------------------------------------------------
第三章 统计语言模型
统计语言模型,直观的表达是:“
看一个句子合理,就看它的可能性大小如何。”(贾里尼克)
语料库中前一个词出现后后一个次出现的概率,一个句子的概率的计算公式如下:
P(S) = P(w1)P(w2|w1)P(w3| w1 w2)…P(wn|w1 w2…wn-1)
这样的方式在计算上比较麻烦,而有了一个较为偷懒的假设“马尔科夫假设”,假设后一个词的出现只与前一个词相关,公式的形状如下:
P(S) = P(w1)P(w2|w1)P(w3|w2)…P(wi|wi-1)…
这种假设的局限性在于:“
在自然语言中,上下文之间的相关性跨度可能很大,甚至可以从一个段落跨到另一个段落。因此即便再怎么提高模型的阶数,对这种情况也无可奈何.
”
模型的训练
一个直观的表达是:“
通过对语料进行统计得到上面公式中所有的条件概率。
”的过程即为模型训练。
大数定理告诉我们:“
在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。
”使得当语料库越庞大时,我们能获得越精准的条件概率。就好像,我们对一个事情发展的预估,往往和我们在这件事情上的直观经验的积累相关。
对于语料库中没有出现过的词的组合
古德-图灵估计:
“对于没有看见过的事件,我们不能认为它发生的概率就是零,因此我们从概率的总量中,分配一个很小的比例给这些没有看见的事件。”
-------------------------------------------------
-------------------------------------------------
第四章 谈谈分词
分词的概念,即表达出什么样的组合算是一个“词”,从句子中把“词”提取出来。
分词的尝试如下:
查字典法:“把句子从左到右扫一遍,发现字典里有的词就标注出来,遇到复合词就用最长的词来匹配,遇到不认识的字串就分割为单字词,于是简单的分词就完成了。”(无法处理复杂情况)
统计语言模型的分词方法
假定一个句子有多种分词方法,那么我们看看这几种分词方式出现的概率有多大,采用出现概率最大的分词方式。
分词在中文、韩文、手写英文识别中尤为重要。
"分词的不一致性分为错误和颗粒度不一致两种,错误分为两类,一类是越界型错误,另一类是覆盖型错误。"
-------------------------------------------------
-------------------------------------------------
第五章 隐含马尔科夫模型
隐含马尔科夫模型最初应用于通信领域,继而推广到语音和语言处理中,成为连接自然语言处理和通信的桥梁。同时,隐含马尔科夫模型也是机器学习的主要工具之一。和几乎所有的机器学习模型一样,它需要一个训练算法(鲍姆-韦尔奇算法)和使用时的解码算法(维特比算法),掌握了这两类算法,就基本上可以使用隐含马尔科夫模型这个工具了。
“
隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度
分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。”
所以,隐 马尔可夫模型
是一个双重随机过程----具有一定状态数的隐 马尔可夫链
和显示随机函数集。自20世纪80年代以来,HMM被应用于 语音识别
,取得重大成功。到了90年代,HMM还被引入计算机文字识别和移动通信核心技术“多用户的检测”。HMM在生物信息科学、故障诊断等领域也开始得到应用。——《百度百科》
暂时没有看懂算法,先在这做个记录,有个直观的感受。
1.它的状态不能直接观察到
2.能通过观测向量序列观察状态
隐含马尔科夫链是一种缺失了某些状态信息的马尔科夫链,需要通过特定的方式找出这些参数信息。
知乎上有一篇帖子: 如何用简单易懂的例子解释隐马尔可夫模型
-------------------------------------------------
-------------------------------------------------
第六章 信息的度量和作用
1.“自古以来,信息和消除不确定性是有联系的。”
2.“从某种程度来说,信息量就是不确定性的多少。” (香农定理)
3.“网页搜索本质上也是利用信息消除不确定性的过程。”
“合理的利用信息,而非玩弄什么公式和机器学习的算法,是做好搜索的关键。”
互信息
互信息(Mutual Information)是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
一种直观的表述是:一件事情发生可能会对另一件事情的发生提供参考,即提供有用的辅助信息。
互信息在自然语言处理的使用:
主要用于在处理多义词的识别时,利用上下文中的词的信息来确定多义词在本文中是什么意思。
书中的一个例子是:人名“布什”(Bush)的翻译,它可以译为人名也可以译为“小树丛”。那么如何确定要译为什么呢?一种方法是:分别列出和人名Bush以及“小树丛”Bush出现在一起的概率最大的词(互信息值最大),在检查看看上下文中那类词出现的次数多,哪个多久翻译为哪一个。
哈哈,万一有个植物学家Bush喜欢在小树丛里闲逛那就有点麻烦了吧?
-------------------------------------------------
-------------------------------------------------
第八章 简单之美 布尔代数和搜索引擎
这一章中讲述了一个搜索引擎大致做的工作,也在这里第一次对搜索引擎有了一个技术上的概念。
在此处引入布尔代数,主要是因为其中定义了二进制的逻辑运算方式。
“搜索引擎的原理其实非常简单,建立一个搜索引擎大致需要做这样几件事情:自动下载尽可能多的网页;建立快速有效的索引;根据相关性对网页进行公平准确的排序。”
书中分开几章来介绍,如何下载,如何索引以及如何排序的问题。
一个直观的搜索过程是,输入一个“词”比如说:“辛尼玛是个大傻瓜。”搜索引擎在已经下载好的所有网页中,进行不同颗粒度的“句词”匹配。看哪些网页中有整个句子或者这些搜索词“辛尼玛”“是个”“大傻瓜”,采用特定的网页排序方式对拥有这些关键词的网页进行排名,最终看到的便是我们看到的搜索结果。

整件事情和布尔代数相关的地方在于,布尔代数中定义的逻辑值“true”和“faulse”的运算,可以用非常简单的方法表征出一个网页是否有特定的关键词。并能进行有效的逻辑运算,而布尔代数的逻辑运算在计算机的实现上是非常简单的。
书中介绍了一种简单的索引方式,在这写一个简单的例子:
假如整个互联网有5个网页,我们需要从这5个网页中搜索出“辛尼玛”相关的网页,如何从5个网页中挑选出和我输入的搜索词相关的网页呢?
对于每一个词有一个5bit的二进制数,来表示5个网页中是否有这个词。
例如:
辛尼玛:11011 那么表示只有第三个网页中没有这个词的出现。
在索引时就将四个有“辛尼玛”这个关键词的网页列出来,至于列出后如何排序则是本书后面的章节要说的内容。
“常见的搜索引擎通常会对所有的词进行索引” 意味针对每一个词都有一个这样的二进制数,所以实际搜索引擎面对的就是这样一个二进制数表来进行字词的搜索。我们可以想象互联网上有多少个网页,书中假定当互联网上有100亿个网页时,保守估计词汇表的大小为30万,索引的大小是100亿×30万 = 3000万亿。通常的索引中会存更多的信息,因此这个大小会更大。一个服务器的内存是不可能存下整个索引的,因此,普遍的做法是:“根据网页的序号将索引分成很多份,分别存储在不同的服务器上。” OK,至此,重温下这句:“
简单性和模块化是软件工程的基石;分布式和容错性是互联网的生命。——蒂姆·伯纳斯·李(WWW的发明人)”
听起来,搜索引擎使用了一个很笨的办法来做搜索,与一个图书馆做对比的话,实际上是它把图书馆所有的书都记住了,并为每一个词写了一张数万亿列的表,每次有人问他,这个词在哪些书中有的时候,他就把表拿出来找一下,根据他的经验丢一堆书给你。 当然,往往是你给定的修饰词越多他给出的答案就越准确(就是你给出的信息量越大,他给出的答案越准确,因为你消除了一定的不确定性,霍霍,好像绕回到信息论了)。不过,谁让人家有数以万计的脑袋,转速还比你快呢。哈哈
说到这,突然想起之前一直想学习下图书馆学,这个冲动来源于一个这样的认识:任何一个知识体系、事物的组织体系,总是从事物的分类和关联来组织的,想要去见识下人类对知识和事物的分流方式以及处理他们的关联的方式,我想一定可以在图书馆学中找到一些有用的信息。
-------------------------------------------------
-------------------------------------------------
第九章 图论和网络爬虫
这一章讲搜索引擎用了什么样的数学原理,把整个互联网下载下来。
这件事情和图论相关的地方在于,需要利用图论中的遍历算法(Traverse)来下载整个互联网中的网页。
没学过图论,尴尬不过这有一篇文章我觉的挺好,我粗翻了一遍,有个大概的认识: 图论算法 有图有代码 万字总结 向前辈致敬
能够和图论关联起来,实际上是出于这样一个认知:多数互联网网站必定能通过其他网页链接到。就是说这些网站总能从某个网站上的链接,链接过去,形成一条通路。这个时候就回到了从“七桥问题”出发的图论问题。像有一张网,一只小虫子要走过网上所有的点。
相关细节请看:“网络爬虫”
(不行了,想起惨痛的数模竞赛打酱油的经历,泣不能言)

-------------------------------------------------
-------------------------------------------------
感觉时间花太多了……还是几句话总结下使用了什么方法解决什么问题吧。
-------------------------------------------------
-------------------------------------------------
第十章 PageRank google的民主表决式网页排名技术
“在互联网上,如果一个网页被很多的其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。这就是pagerank的核心思想。当然谷歌的PageRank算法实际要复杂很多。” 详情见 google pagerank 百度百科
“网页排名算法的高明之处在于它把整个互联网当作一个整体来对待。”
-------------------------------------------------
-------------------------------------------------
第十一章 如何确定网页和查询的相关性
使用一个词在文章中出现的频率做出一个相关性的评价,同时将这个词的“主题”性价值作为权重加入到这个评价的生成过程中。
影响搜索引擎质量的诸多因素,出了用户点击数据之外,都可以归纳成下面四大类问题:
1. 完备的索引。俗话说巧妇难为无米之炊,如果一个网页不再索引中,那么再好的算法也找不到。
2.对网页质量的度量,比如PageRank。现在看来PageRank 的作用比十年前已经小了很多。今天对网页质量的衡量是全方位的,比如对网页内容权威性的衡量,一些八卦网站的PageRank可能很高,但是他们内容的权威性很低。
3.用户偏好。因为不同用户的喜好不同,因此一个好的搜索引擎会针对不同的用户,对相同的搜索给出不同的排名。
4.确定一个网页和某个查询相关性的方法。
文中说了一个TF-IDT的方式,即看一个词在整篇文章中出现的词频。
一个小漏洞是,对于通用词比如说“应用”和专业词汇“原子能”这样的词汇,通用词的词频一定会比主题词的词频高。这个时候就需要对不同的词进行权重的设定。
1. 一个词预测主题的能力越强,权重越大,反之越小。
2.停止词的权重为0 。
如何使通用词获得较低权重,文中描述了这样的方式:如果一个词w在Dw个网页中出现过,Dw越大则w的权重越小,反之亦然。在信息检索中,使用最多的权重是“逆文本频率指数”IDF。
-------------------------------------------------
-------------------------------------------------
第十二章 有限状态机和动态规划——地图与本地搜索的核心技术
状态机在数字电路设计中使用的很多,刚好在课设中做过DTW的HDL设计,这一章和我的经历还蛮相关的。
在有限状态机中介绍了,地址信息的解析方式:
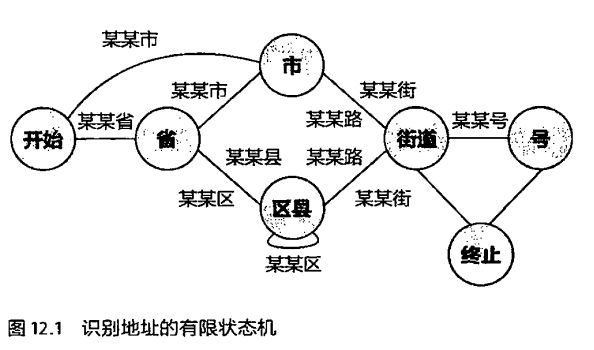
但是在当用户地址不太标准或者有错别字时,有限状态机就会束手无策,因为它只能进行严格的匹配。为此科学家们提出了基于概率的有限状态机。
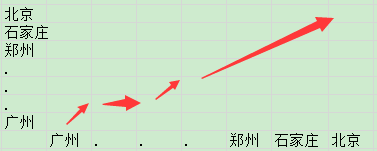
要寻找北京到广州的最短路径,使用的动态规划问题实际和DTW很像。
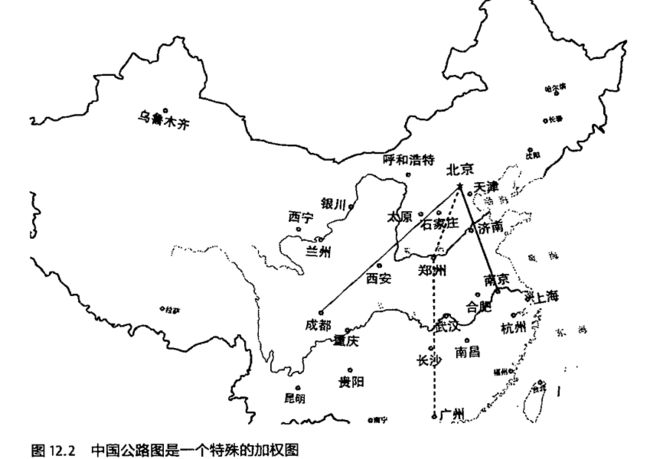
先计算出从北京出发到这条线上所有的城市的最短路径,最后得到一个到达广州的最短路径。
-------------------------------------------------
-------------------------------------------------
第十三章 Google AK-47 的设计者——阿密特·辛格博士
-------------------------------------------------
-------------------------------------------------
第十四章 余弦定理和新闻分类
余弦定理在新闻分类中的使用,实际是利用两篇新闻的主题词组成的向量之间的夹角的大小来确定新闻的归类。
在使用中有一个简单的认定,相类似的主题词出现的概率越相似的新闻,那么他们之间的相似性越大,可进行归类。如何评价多个主题词之间的相似性呢?见下文:


如何应用余弦定理呢?假设,整个网络中有64000个词,那么将这64000个词进行编号,组成一个64000维的空间,每一篇文章中指定词出现的TF/IDF值作为该文章在该空间中指定方向上的坐标值。那么,一篇文章中所有的主题词的TF/IDF值组成了这篇文章在这个64000维度空间中的一个向量。将两篇文章组成的两个向量放在一起,我们计算两个向量的夹角,以确定这两篇文章的相似性。当余弦值越接近于1时,两篇文章越相似,反之越接近于0,则越不相似。
-------------------------------------------------
-------------------------------------------------
第十五章 矩阵运算和文本处理中的两个分类问题
本章解决一个问题:如果使用第十四章中引入的向量距离的方法,对数以亿计的网页进行距离计算,计算量过于巨大,而引入了矩阵的运算来计算新闻之间的相似性,一次性把多个新闻的相似性计算出来。利用了矩阵运算中的奇异值分解。
(有没有联想到《线性代数》中矩阵之间向量的线性相关的运算?)
这种方式,将多个新闻的向量组成的矩阵分解为三个小矩阵相乘,
使得计算存储量和计算量小了三个数量级以上。
效果:只要对新闻关联性矩阵进行一次奇异值分解,既可同时完成近义词分类和文章的分类。
计算方法:庞大的网页量,使得计算量非常大,因此需要很多的计算机并行处理。
google中国的张智威博士实现了奇异值分解的并行算法。
-------------------------------------------------
-------------------------------------------------
第十六章 信息指纹及其应用
“所谓信息指纹,可以简单的理解为将一段信息,随机的映射到一个多维二进制空间中的一个点(一个二进制数字)。只要这个随机函数做得好,那么不同信息对应的这些点就不会重合,因此,这些二进制数字就成了原来的信息所具有的独一无二的指纹。”
本章中大略介绍了信息之为在如下领域内的应用:
- 网页消重。
- 网络加密传输。
- 搜索中集合相同的判定。
- 检查文章抄袭的问题。
- YouTube的反盗版。
1.网页消重
为所有的不定长的网址随机的映射为一个128bit的二进制数。
“
把网址内存需求量降低到原来的1/6不到。”这个就是网址的信息指纹。“可以证明,只要产生随机数的算法足够好,就能保证几乎不可能有两个字符串的指纹相同,就如同不可能有两个人的指纹相同一样。”
网页的信息指纹计算的方法: 1. 将网址字符串看成一个特殊的、很长的整数。2.使用伪随机数产生器算法(PRNG)将这个整数转换成为固定长度的伪随机数。(提及了PRNG算法和梅森旋转)
2.网络加密传输
“信息指纹的一个特征是其不可逆性,就是说无法根据信息指纹推断出原有的信息。这种性质正是网络加密传输所需要的。”
一个网站可以根据用户本地客户端的cookie识别不同的用户,而cookie本身即为一种信息指纹。但是网站无法根据信息指纹了解用户的身份。
cookie 本身没有加密,因此通过分析cookie可以知道用户访问了哪些网站。(不知道在做购物广告推送时,有没有用到这样的方式来偷瞄我的cookie,然后推送我搜索过的内容到我看的网页上。)
HTTPS 可以对cookie进行加密,可以保障用户的隐私。
3.搜索中集合相同的判定
用于解决:“北京 星巴克 中关村”
“
中关村
北京 星巴克 ”判定为同一个搜索的问题。
方法1. 对集合中的元素一一对比。
方法2. 将两个集合中的元素进行排序,然后顺序比较。
方法3.完美的计算方法是,计算两个集合的指纹。
4.检查文章抄袭的问题
刚好临近毕业,查重是所有的论文需要面对的问题,了解下。
”将每一篇文章切成小的片段,然后上述方法条熏这些片段的特征词集合,并计算它的指纹。只要比较这些指纹,就能找到大段相同的文字,最后根据时间先后找出原创和抄袭。“
5.YouTube的反盗版
用信息指纹来编码关键帧信息,而关键帧信息对于视频的重要性就如同主题词对于新闻的重要性一样。
-------------------------------------------------
-------------------------------------------------
第十七章 谈谈密码学的数学原理
”不管怎样,我们今天用的所谓的最可靠的加密方法“……”无非是找几个大素数做一些乘除和乘方运算“
之前表哥分配给了我一个关于AES加密的FPGA小项目的任务,可惜具体的知识都忘记了。大约记得矩阵乘来乘去的。
-------------------------------------------------
-------------------------------------------------
第十八章 谈谈搜索引擎反作弊问题和搜索结果的权威性问题
搜索引擎的作弊,实际是利用搜索引擎的搜索排名规则,人为的提升网页的排名的方式。
”有了网页排名(pagerank)后,作弊者发现一个网页被引用的链接越多,排名家可能越靠前,于是有了专门卖链接的生意。“
提到的方法:
1.判断一个网站提供的外链的相关性。如果几乎不相关,那么认定这个网站在卖链接。当然实际的处理方法更加复杂。
-------------------------------------------------
-------------------------------------------------
第十九章 谈谈数学模型的重要性
- 一个正确的数学模型应当在形式上是简单的。(托勒密的模型显然太复杂。)
- 一个正确的模型在它开始的时候可能还不如一个精雕细琢过的错误的模型来的准确, 但是如果我们认定大方向是对的,就应该坚持下去。(日心说开始并没有地心说准确。)
- 大量准确的数据对研发很重要。
- 正确的模型也可能受噪音干扰,而显得不准确;这时我们不应该用一种凑合的修正方法来弥补它,而是要找到噪音的根源,这也许能通往重大发现。
来源: http://www.cnblogs.com/hold/archive/2011/07/27/2286793.html
-------------------------------------------------
-------------------------------------------------
第二十章 谈谈最大熵模型
- 最大熵原理:说白了,就是要保留全部的不确定性,将风险降到最小。
- “不要把鸡蛋放在一个篮子里,是最大熵原理的一种朴素说法。”
- 最大熵原理指出,当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。(不做主观假设这 点很重要。)
- 最大熵模型存在的【证明】:匈牙利著名数学家、信息论最高奖香农奖得主希萨(Csiszar)证明,对任何一组【不自相矛盾】的信息,这个最大熵模型不仅存在,而且是唯一的。而且它们都有同一个非常简单的形式 -- 指数函数。
- 书提到的最大熵原理【应用】:
- 拼音和汉字的转换:1.根据语言模型:wang-xiao-bo 可以转换为:王小波 和 王晓波两种情况。2.根据主题,王小波是作家《黄金时代》的作者,而王晓波是研究两岸关系的学者。根据这两种信息创建一个最大熵模型。


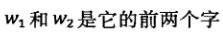

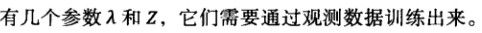
- 最大熵模型应用于信息处理优势的第一次验证:
 应用最大熵原理,创建了当时世界上最好的词性标识系统和句法分析器。其做法即为使用最大熵模型成功的将上下文信息、词性、名词、动词、形容词等句子成分、主谓宾统一了起来。
应用最大熵原理,创建了当时世界上最好的词性标识系统和句法分析器。其做法即为使用最大熵模型成功的将上下文信息、词性、名词、动词、形容词等句子成分、主谓宾统一了起来。 - 2000年以后,句法分析、语言模型和机器翻译,都开始使用最大熵模型。
- 对冲基金使用最大熵。
孪生兄弟的达拉皮垂他们在九十年代初贾里尼克离开 IBM 后,也退出了学术界,而到在金融界大显身手。他们两人和很多 IBM 语音识别的同事一同到了一家当时还不大,但现在是世界上最成功对冲基金(hedge fund)公司----文艺复兴技术公司 (Renaissance Technologies)。我们知道,决定股票涨落的因素可能有几十甚至上百种,而最大熵方法恰恰能找到一个同时满足成千上万种不同条件的模型。达拉皮 垂兄弟等科学家在那里,用于最大熵模型和其他一些先进的数学工具对股票预测,获得了巨大的成功。
来源: http://www.cnblogs.com/KevinYang/archive/2009/02/01/1381798.html
- 计算量庞大的【GIS】:GIS 最早是由 Darroch 和 Ratcliff 在七十年代提出的。
GIS 算法每次迭代的时间都很长,需要迭代很多次才能收敛,而且不太稳定,即使在 64 位计算机上都会出现溢出。因此,在实际应用中很少有人真正使用 GIS。大家只是通过它来了解最大熵模型的算法。 - 改进的迭代算法【IIS】:
八十年代,孪生兄弟的达拉皮垂(Della Pietra)在 IBM 对 GIS 算法进行了两方面的改进,提出了改进迭代算法 IIS(improved iterative scaling)这使得最大熵模型的训练时间缩短了一到两个数量级。这样最大熵模型才有可能变得实用。即使如此,在当时也只有 IBM 有条件是用最大熵模型。 - 吴军的改改进和他的论文:(链接在此)
发现一种数学变换,可以将大部分最大熵模型的训练时间在 IIS 的基础上减少两个数量级
-------------------------------------------------
-------------------------------------------------
第二十一章 拼音输入法的数学原理
这一章实际把我们所熟悉知道的中文输入法梳理了一遍:
这一章实际把我们所熟悉知道的中文输入法梳理了一遍:
五笔、全拼、双拼
可惜没有分析手机端的 9宫格输入法,九个键覆盖所有可能的拼音组合,其实真的还比较神奇。
主要引入的数学原理是,
- 中文输入法 的击键次数的数学原理
【香农第一定理】指出:对于一个信息,任何【编码长度】都不小于它的【信息熵】。因此,上面的平均编码长度的最小值就是汉字的信息熵,任何输入法不能突破信息熵给定的极限。
【汉字信息熵的计算】在GB2312中一共有6700左右个常用汉字。
a. 假定每个汉字出现的相对频率为: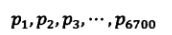
b. 编码长度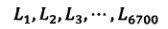
c. 平均编码长度:
d. 得出汉字的信息熵: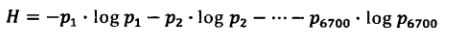 不考虑上下文的关系,信息熵的大小大约为【10bit】
不考虑上下文的关系,信息熵的大小大约为【10bit】
e. 单个字母代表的信息熵:假定输入法只能要我26个字母来输入,那么每个字母可以代表log26 = 4.7 比特的信息,也就是说,一个汉字的输入,平均需要10/4.7 约为2.1 次击键。
f.组成词后信息熵减少: 如果把汉字组成词组,再以词为单位统计信息熵,那么每个汉字的平均信息熵就会减少。如果不考虑上下文关系,汉字的信息熵大约是8bit,以词为单位每个汉字平均只需要8/4.7 = 1.7次击键
g. 考虑上下文信息信息熵进一步减少:如果考虑上下文关系对汉语建立一个基于词的统计语言模型,可以将汉字的信息熵降低到6bit左右。此时平均需要的击键次数约为:6/4.7 1.3次击键 。如果一种输入法能够做到这一点那么汉字的输入就比英文快多了。(我觉得手机的9宫格汉字输入法挺给力的。)
【全拼输入法的信息熵】汉语全拼平均长度为2.98,只要基于上下文能彻底就解决一音多字的问题,平均每个汉字的输入应该在3个键以内。可以实现汉字拼音输入一部分后提示出相应的汉字。
如何利用上下文呢? - 拼音转汉字的动态规划算法
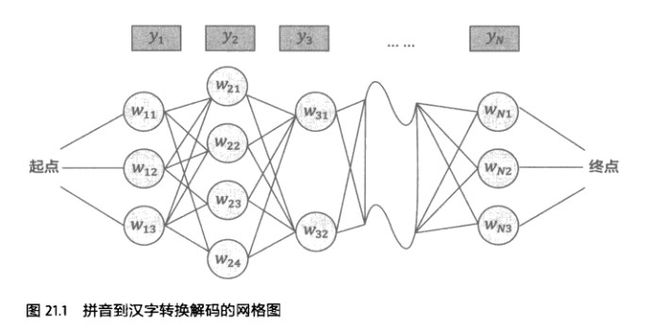
【输入法做的事情】是:按照输入的序列,查找该条件下的句子。
图中 y 代表输入的拼音字符串,w代表输出候选汉字。每一个句子和途中的一条路径对应。
拼音输入法的问题,变成了一个寻找最优路径的问题。
【最优路径】 和计算城市间的最优路径不同,其中的距离是实际上的一个点到另一个点的距离,而在拼音输入法的路径中,两个候选词之间的距离是w伸向下一级w的概率。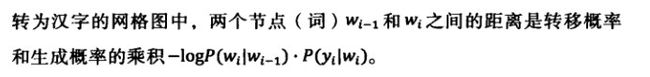
实际上输入法作出的计算是这样,输入一串拼音字母字符,软件通过模型计算出与词拼音对应的出现概率最大的汉字候选结果。
关于【双拼】:
因为我刚好是双拼爱好者,哈哈,刚好对文中对双拼的评价比较在意:
首先,书中说了这样几点哈~:
- 双拼的出现比全拼要早;
- 而五笔输入法这种敲键次数多,编码难记忆的输入法早期的成功完全是开发者市场做的好。
- 现在主导地位的是全拼输入法。
双拼输入法出现的比全拼早,而且击键次数更少,为什么被全拼所替代?
书中中指出了它的三个缺点:
- 首先双拼输入法增加了编码上的歧义性,很多韵母不得不公用一个按键,增加歧义性的后果是:从更多的汉字候选中选择自己想输入的字。下图为双拼的编码表。(比五笔字根容易多了吧?想起小时候背字根的痛苦经历?还好我没背~哟西)

- 增加了每一次击键的时间,理由是,你每次都需要去想该按哪个键。(哎,其实对于初学者来说,记住键盘都难,不是每个人都会左右手食指摸点(FJ)盲打的。这个比五笔简单一万倍,该数字没有经过科学验证啊)
- 对拼音的容错性不好,就是说,地域性的口音,使得前鼻音后鼻音、l、n之类的混淆词不好即时纠错。(现在想想五笔真就是一坨屎,它估计从来没有考虑过忘记字形的人的想法吧。)
来说下,我这个具有双拼输入法几年使用经验的人的看法哈。
就我个人技能上来说:
- 拼音能力还不错,虽然说话l,n部分,但是打字会注意。
- 在键盘上摸点后,可以准确盲打主键盘区域任何按键。
好,以这两点为基础,我们来说明双拼对与我的好处,也说三点:
- 速度很快:真的就两个键出一个完整的拼音,虽然真的只有编码输对了才能出正确的拼音,但是实际的打字速度比双拼快非常多。你在输入 chang 的时候,我 输入 ih 就行了,还要排除单个字的全拼多次击键出错的情况下回删的情况。
- 精确输入拼音,回删时间比较少:想想是输入 chang 5个字母的拼音出错的概率大,还是输入2个字母 ih 的错误概率大(这个的前提是两种情况下,对两种按键的编码都熟悉,在同样的键盘条件下使用),如果错误概率一样,那么如果出错后修正,哪个的时间会比较少?
- 学起来实际上很快,它和全拼,在效果上实际是一个意思,就是完整输入拼音。而且现在的双拼支持在双拼条件下使用全拼,你记不起来就全拼输入就好啦。(快来和我一起用双拼吧)
-------------------------------------------------
-------------------------------------------------
第二十二章 自然语言处理的教父马库斯和他的优秀弟子们
-------------------------------------------------
-------------------------------------------------
第二十三章 布隆过滤器
-------------------------------------------------
-------------------------------------------------
第二十四章 马尔科夫链的扩展——贝叶斯网络
-------------------------------------------------
-------------------------------------------------
第二十五章 条件随机场、文法分析及其他
-------------------------------------------------
-------------------------------------------------
第二十六章 维比特和他的维比特算法
-------------------------------------------------
-------------------------------------------------
第二十七章 期望最大化算法
-------------------------------------------------
-------------------------------------------------
第二十八章 逻辑回归和搜索广告
-------------------------------------------------
-------------------------------------------------
第二十九章 各个击破算法和google云计算的基础
-------------------------------------------------
-------------------------------------------------
第三十章 google 大脑和人工神经网络
-------------------------------------------------
-------------------------------------------------
第三十一章 大数据的威力
其实一直对怎么写读书笔记这个问题比较困扰,本想去找些书看看别人是怎么做的,后来觉得一方面,别人感兴趣的东西可能本身对我来说吸引力不大,希望可以只记录下我觉得有趣的东西,然后把它们和我知识体系尽可能做一些关联;另一方面,本来是件很随性的事情,不希望套在条条框框里。
怎么做读书笔记?看一本书需要记录什么东西?知乎的这一篇文章给了一些启示: 怎么提高信息转化率?需要记录的事情我觉的有三类:
1. 概念,一些精辟、准确的对概念的陈述。
你需要几句话来知道这个事情是什么。
2. 方法,用什么方法解决了什么问题。方法,是发现事物之间联系的过程。
文学里面的比喻,用什么方法来喻事。科学里解决问题的设计,是精巧的事物联系。
谁做了这个事情,个人认为没那么重要。不过如果要对一个问题做深入的追踪,那么记录领域内的牛人也是必不可少的。毕竟,他们不是在这个领域那种只出现两集的小龙套,这些人基本会活到最后一集。
3. 对事情的看法,包括预测、评论、总结等等,是这件事情之于未来、现在和过去的意义。
对于人类这种在自我迷惘中不断寻求意义的生物来说,个人觉得第三点反倒是最重要的。
来自为知笔记(Wiz)