R中的线性回归函数比较简单,就是lm(),比较复杂的是对线性模型的诊断和调整。这里结合Statistical Learning和杜克大学的Data Analysis and Statistical Inference的章节以及《R语言实战》的OLS(Ordinary Least Square)回归模型章节来总结一下,诊断多元线性回归模型的操作分析步骤。
1、选择预测变量
因变量比较容易确定,多元回归模型中难在自变量的选择。自变量选择主要可分为向前选择(逐次加使RSS最小的自变量),向后选择(逐次扔掉p值最大的变量)。个人倾向于向后选择法,一来p值比较直观,模型返回结果直接给出了各变量的p值,却没有直接给出RSS;二来当自变量比较多时,一个个加比较麻烦。
Call:
lm(formula = Sales ~ . + Income:Advertising + Age:Price, data = Carseats)
Residuals:
Min 1Q Median 3Q Max
-2.9208 -0.7503 0.0177 0.6754 3.3413
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.5755654 1.0087470 6.519 2.22e-10 ***
CompPrice 0.0929371 0.0041183 22.567 < 2e-16 ***
Income 0.0108940 0.0026044 4.183 3.57e-05 ***
Advertising 0.0702462 0.0226091 3.107 0.002030 **
Population 0.0001592 0.0003679 0.433 0.665330
Price -0.1008064 0.0074399 -13.549 < 2e-16 ***
ShelveLocGood 4.8486762 0.1528378 31.724 < 2e-16 ***
ShelveLocMedium 1.9532620 0.1257682 15.531 < 2e-16 ***
Age -0.0579466 0.0159506 -3.633 0.000318 ***
Education -0.0208525 0.0196131 -1.063 0.288361
UrbanYes 0.1401597 0.1124019 1.247 0.213171
USYes -0.1575571 0.1489234 -1.058 0.290729
Income:Advertising 0.0007510 0.0002784 2.698 0.007290 **
Price:Age 0.0001068 0.0001333 0.801 0.423812
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 1.011 on 386 degrees of freedom
Multiple R-squared: 0.8761, Adjusted R-squared: 0.8719
F-statistic: 210 on 13 and 386 DF, p-value: < 2.2e-16
构建一个回归模型后,先看F统计量的p值,这是对整个模型的假设检验,原假设是各系数都为0,如果连这个p值都不显著,无法证明至少有一个自变量对因变量有显著性影响,这个模型便不成立。然后看Adjusted R2,每调整一次模型,应该力使它变大;Adjusted R2越大说明模型中相关的自变量对因变量可解释的变异比例越大,模型的预测性就越好。
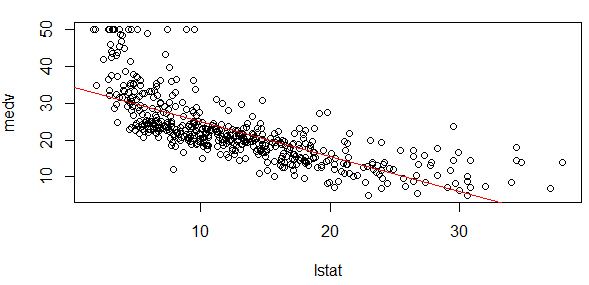
构建了线性模型后,如果是一元线性回归,可以画模型图初步判断一下线性关系(多元回归模型不好可视化):
par(mfrow=c(1,1))
plot(medv~lstat,Boston)
fit1=lm(medv~lstat,data=Boston)
abline(fit1,col="red")
2、模型诊断
确定了回归模型的自变量并初步得到一个线性回归模型,并不是直接可以拿来用的,还要进行验证和诊断。诊断之前,先回顾多元线性回归模型的假设前提(by Data Analysis and Statistical Inference):
- (数值型)自变量要与因变量有线性关系;
- 残差基本呈正态分布;
- 残差方差基本不变(同方差性);
- 残差(样本)间相关独立。
一个好的多元线性回归模型应当尽量满足这4点假设前提。
用lm()构造一个线性模型fit后,plot(fit)即可返回4张图(可以par(mfrow=c(2,2))一次展现),这4张图可作初步检验:
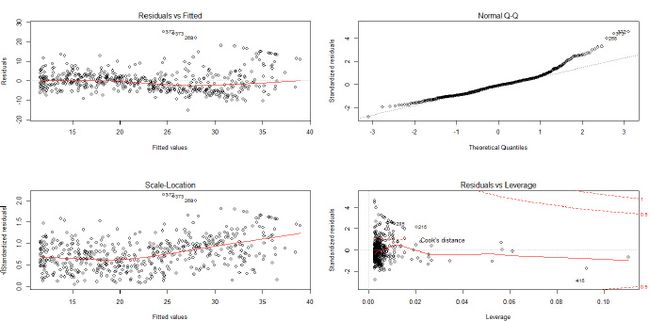
左上图用来检验假设1,如果散点看不出什么规律,则表示线性关系良好,若有明显关系,则说明非线性关系明显。右上图用来检验假设2,若散点大致都集中在QQ图中的直线上,则说明残差正态性良好。左下图用来检验假设3,若点在曲线周围随机分布,则可认为假设3成立;若散点呈明显规律,比如方差随均值而增大,则越往右的散点上下间距会越大,方差差异就越明显。假设4的独立性无法通过这几张图来检验,只能通过数据本身的来源的意义去判断。
右下图是用来检验异常值。异常值与三个概念有关:
- 离群点:y远离散点主体区域的点
- 杠杆点:x远离散点主体区域的点,一般不影响回归直线的斜率
- 强影响点:影响回归直线的斜率,一般是高杠杆点。
对于多元线性回归,高杠杆点不一定就是极端点,有可能是各个变量的取值都正常,但仍然偏离散点主体。
对于异常值,可以谨慎地删除,看新的模型是否效果更好。
《R语言实战》里推荐了更好的诊断方法,总结如下。
1、多元线性回归假设验证:
gvlma包的gvlma()函数可对拟合模型的假设作综合验证,并对峰度、偏度进行验证。
states <- as.data.frame(state.x77[, c("Murder", "Population",
"Illiteracy", "Income", "Frost")])
fit <- lm(Murder ~ Population + Illiteracy + Income +
Frost, data = states)
library(gvlma)
gvmodel <- gvlma(fit)
summary(gvmodel)
Call:
gvlma(x = fit)
Value p-value Decision
Global Stat 2.7728 0.5965 Assumptions acceptable.
Skewness 1.5374 0.2150 Assumptions acceptable.
Kurtosis 0.6376 0.4246 Assumptions acceptable.
Link Function 0.1154 0.7341 Assumptions acceptable.
Heteroscedasticity 0.4824 0.4873 Assumptions acceptable.
最后的Global Stat是对4个假设条件进行综合验证,通过了即表示4个假设验证都通过了。最后的Heterosceasticity是进行异方差检测。注意这里假设检验的原假设都是假设成立,所以当p>0.05时,假设才能能过验证。
如果综合验证不通过,也有其他方法对4个假设条件分别验证:
- 线性假设
library(car)
crPlots(fit)
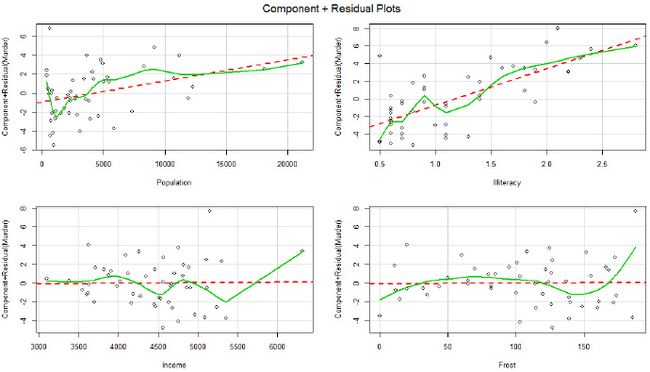
返回的图是各个自变量与残差(因变量)的线性关系图,若存着明显的非线性关系,则需要对自变量作非线性转化。书中说这张图表明线性关系良好。
- 正态性
library(car)
qqPlot(fit,labels = row.names(states),id.method = "identify",simulate = TRUE,main = "Q-Q Plot")
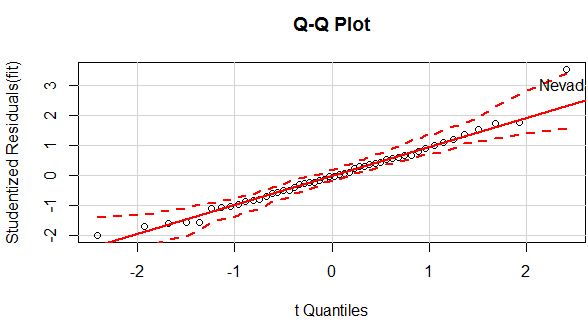
qqPlot()可以生成交互式的qq图,选中异常点,就返回该点的名称。该图中除了Nevad点,其他点都在直线附近,可见正态性良好。
- 同方差性
library(car)
ncvTest(fit)
Non-constant Variance Score Test
Variance formula: ~ fitted.values
Chisquare = 1.746514 Df = 1 p = 0.1863156
p值大于0.05,可认为满足方差相同的假设。
- 独立性
library(car)
durbinWatsonTest(fit)
lag Autocorrelation D-W Statistic p-value
1 -0.2006929 2.317691 0.258
Alternative hypothesis: rho != 0
p值大于0.05,可认为误差之间相互独立。
除了以上4点基本假设,还有其他方面需要进行诊断——
2、多重共线性
理想中的线性模型各个自变量应该是线性无关的,若自变量间存在共线性,则会降低回归系数的准确性。一般用方差膨胀因子VIF(Variance Inflation Factor)来衡量共线性,《统计学习》中认为VIF超过5或10就存在共线性,《R语言实战》中认为VIF大于4则存在共线性。理想中的线性模型VIF=1,表完全不存在共线性。
library(car)
vif(fit)
Population Illiteracy Income Frost
1.245282 2.165848 1.345822 2.082547
可见这4个自变量VIF都比较小,可认为不存在多重共线性的问题。
3、异常值检验
- 离群点
离群点有三种判断方法:一是用qqPlot()画QQ图,落在置信区间(上图中两条虚线)外的即可认为是离群点,如上图中的Nevad点;一种是判断学生标准化残差值,绝对值大于2(《R语言实战》中认为2,《统计学习》中认为3)的可认为是离群点。
plot(x=fitted(fit),y=rstudent(fit))
abline(h=3,col="red",lty=2)
abline(h=-3,col="red",lty=2)

which(abs(rstudent(fit))>3)
Nevada
28
还有一种方法是利用car包里的outlierTest()函数进行假设检验:
library(car)
outlierTest(fit)
rstudent unadjusted p-value Bonferonni p
Nevada 3.542929 0.00095088 0.047544
这个函数用来检验最大的标准化残差值,如果p>0.05,可以认为没有离群点;若p<0.05,则该点是离群点,但不能说明只有一个离群点,可以把这个点删除之后再作检验。第三种方法可以与第二种方法结合起来使用。
- 高杠杆点
高杠杆值观测点,即是与其他预测变量有关的离群点。换句话说,它们是由许多异常的预测变量值组合起来的,与响应变量值没有关系。《统计学习》中给出了一个杠杆统计量,《R语言实战》中给出了一种具体的操作方法。(两本书也稍有出入,《统计学习》中平均杠杆值为(p+1)/n,而在《R语言实战》中平均杠杆值为p/n;事实上在样本量n比较大时,几乎没有差别。)
hat.plot <- function(fit){
p <- length(coefficients(fit))
n <- length(fitted(fit))
plot(hatvalues(fit),main = "Index Plot of Hat Values")
abline(h=c(2,3)*p/n,col="red",lty=2)
identify(1:n, hatvalues(fit), names(hatvalues(fit))) #这句产生交互效果,选中某个点后,关闭后返回点的名称
}
hat.plot(fit)
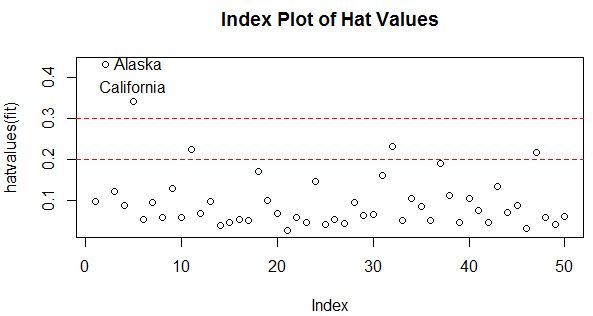
超过2倍或3倍的平均杠杆值即可认为是高杠杆点,这里把Alaska和California作为高杠杆点。
- 强影响点
强影响点是那种若删除则模型的系数会产生明显的变化的点。一种方法是计算Cook距离,一般来说, Cook’s D值大于4/(n-k -1),则表明它是强影响点,其中n 为样本量大小, k 是预测变量数目。
cutoff <- 4/(nrow(states-length(fit$coefficients)-2)) #coefficients加上了截距项,因此要多减1
plot(fit,which=4,cook.levels = cutoff)
abline(h=cutoff,lty=2,col="red")
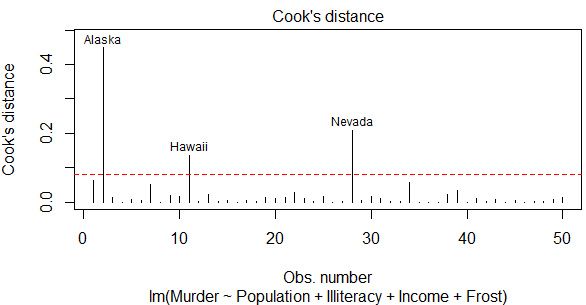
实际上这就是前面诊断的4张图之一,语句还是plot(fit),which=4表示指定第4张图,cook.levels可设定标准值。红色虚线以上就返回了强影响点。
car包里的influencePlot()函数能一次性同时检查离群点、高杠杆点、强影响点。
library(car)
influencePlot(fit,id.method = "identity", main="Influence Plot",
sub="Circle size is proportional to Cook's distance")
StudRes Hat CookD
Alaska 1.753692 0.43247319 0.4480510
Nevada 3.542929 0.09508977 0.2099157

纵坐标超过+2或小于-2的点可被认为是离群点,水平轴超过0.2或0.3的州有高杠杆值(通常为预测值的组合)。圆圈大小与影响成比例,圆圈很大的点可能是对模型参数的估计造成的不成比例影响的强影响点。
3、模型调整
到目前为止,《统计学习》中提到的多元线性回归模型潜在的问题,包括4个假设不成立、异常值、共线性的诊断方法在上面已经全部得到解决。这里总结、延伸《R语言实战》里提到的调整方法——
- 删除观测点
对于异常值一个最简单粗暴又高效的方法就是直接删除,不过有两点要注意。一是当数据量大的时候可以这么做,若数据量较小则应慎重;二是根据数据的意义判断,若明显就是错误就可以直接删除,否则需判断是否会隐藏着深层的现象。
另外删除观测点后要与删除之前的模型作比较,看模型是否变得更好。
- 变量变换

在进行非线性变换之前,先看看4个假设是否成立,如果成立可以不用变换;没必要追求更好的拟合效果而把模型搞得太复杂,这有可能出现过拟合现象。如果连假设检验都不通过,可以通过变量变换来调整模型。这里只讨论线性关系不佳的情况,其他情况遇到了再说。
(1)多项式回归
如果残差图中呈现明显的非线性关系,可以考虑对自变量进行多项式回归。举一个例子:
library(MASS)
library(ISLR)
fit1=lm(medv~lstat,data=Boston)
plot(fit1,which = 1)
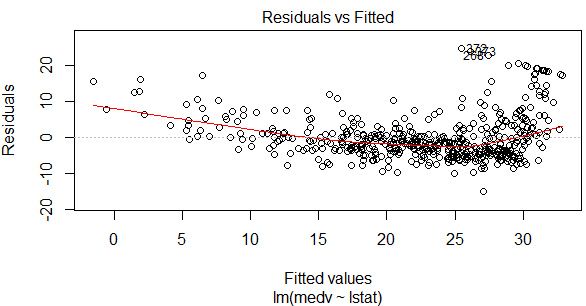
可以看到这个一元线性回归模型的残差图中,散点的规律还是比较明显,说明线性关系较弱。
fit1_1 <- lm(medv~poly(lstat,2),data = Boston)
plot(fit1_1,which = 1)

将自变量进行2次多项式回归后,发现现在的残差图好多了,散点基本无规律,线性关系较明显。
再看看两个模型的整体效果——
summary(fit1)

summary(fit1_1)

可见多项式回归的模型Adjusted R2也增大了,模型的解释性也变强了。
多项式回归在《统计学习》后面的非线性模型中还会提到,到时候再讨论。
(2)Box-Tidwell变换
car包中的boxTidwell() 函数通过获得预测变量幂数的最大似然估计来改善线性关系。
library(car)
boxTidwell(Murder~Population+Illiteracy,data=states)
Score Statistic p-value MLE of lambda
Population -0.3228003 0.7468465 0.8693882
Illiteracy 0.6193814 0.5356651 1.3581188
iterations = 19
#这里看lambda,表示各个变量的幂次数
lmfit <- lm(Murder~Population+Illiteracy,data=states)
lmfit2 <- lm(Murder~I(Population^0.87)+I(Illiteracy^1.36),data=states)
plot(lmfit,which = 1)
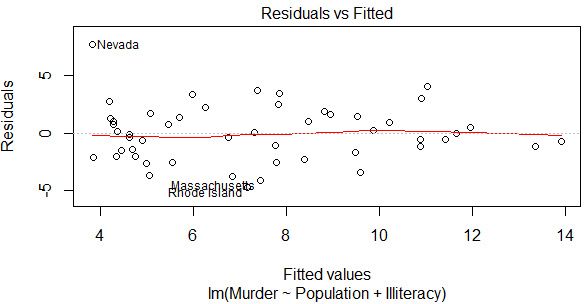
plot(lmfit2,which = 1)
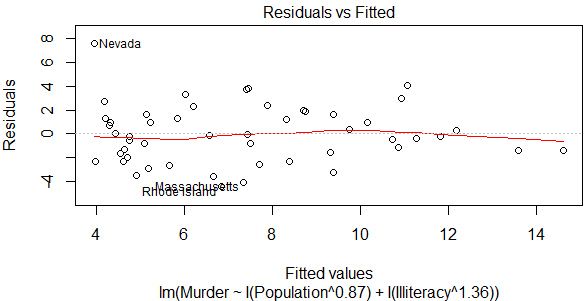
summary(lmfit)

summary(lmfit2)

可以发现残差图和Adjusted R2的提升都甚微,因此没有必要作非线性转换。
4、模型分析
(1)模型比较
前面只是简单得用Adjusted R2来比较模型,《R语言实战》里介绍了可以用方差分析来比较嵌套模型(即它的一些项完全包含在另一个模型中)有没有显著性差异。方差分析的思想是:如果线性模型y~x1+x2+x3与y~x1+x2没有显著性差异,若同时x3变量对模型也不显著,那就没必要加上变量x3。下面进行试验:
aovfit1 <- lm(Murder~Population+Illiteracy+Income+Frost,data=states)
aovfit2 <- lm(Murder~Population+Illiteracy,data=states)
anova(aovfit1,aovfit2)
Analysis of Variance Table
Model 1: Murder ~ Population + Illiteracy + Income + Frost
Model 2: Murder ~ Population + Illiteracy
Res.Df RSS Df Sum of Sq F Pr(>F)
1 45 289.17
2 47 289.25 -2 -0.078505 0.0061 0.9939
summary(aovfit1)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.235e+00 3.866e+00 0.319 0.7510
Population 2.237e-04 9.052e-05 2.471 0.0173 *
Illiteracy 4.143e+00 8.744e-01 4.738 2.19e-05 ***
Income 6.442e-05 6.837e-04 0.094 0.9253
Frost 5.813e-04 1.005e-02 0.058 0.9541
Residual standard error: 2.535 on 45 degrees of freedom
Multiple R-squared: 0.567, Adjusted R-squared: 0.5285
F-statistic: 14.73 on 4 and 45 DF, p-value: 9.133e-08
summary(aovfit2)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.652e+00 8.101e-01 2.039 0.04713 *
Population 2.242e-04 7.984e-05 2.808 0.00724 **
Illiteracy 4.081e+00 5.848e-01 6.978 8.83e-09 ***
Residual standard error: 2.481 on 47 degrees of freedom
Multiple R-squared: 0.5668, Adjusted R-squared: 0.5484
F-statistic: 30.75 on 2 and 47 DF, p-value: 2.893e-09
Income和Frost两个变量不显著,两个模型之间没有显著性差异,就可以不加这两个变量。删去这两个不显著的变量后,R2略微减少,Adjusted R2增大,这也符合二者的定义。
《R语言实战》里还介绍到了用AIC(Akaike Information Criterion,赤池信息准则)值来比较模型,AIC值越小的模型优先选择,原理不明。
aovfit1 <- lm(Murder~Population+Illiteracy+Income+Frost,data=states)
aovfit2 <- lm(Murder~Population+Illiteracy,data=states)
AIC(aovfit1,aovfit2)
df AIC
aovfit1 6 241.6429
aovfit2 4 237.6565
第二个模型AIC值更小,因此选第二个模型(真是简单粗暴)。注:
ANOVA需限定嵌套模型,AIC则不需要。可见AIC是更简单也更实用的模型比较方法。
(2)变量选择
这里的变量选择与最开始的变量选择同也不同,虽然是一回事,但一开始是一个粗略的变量的选择,主要是为了构建模型;这里则要进行细致的变量选择来调整模型。
- 逐步回归
前面提到的向前或向后选择或者是同时向前向后选择变量都是
逐步回归法。MASS包中的stepAIC() 函数可以实现逐步回归模型(向前、向后和向前向后),依据的是精确AIC准则。以下实例是向后回归法:
library(MASS)
aovfit1 <- lm(Murder~Population+Illiteracy+Income+Frost,data=states)
stepAIC(aovfit1,direction = "backward") # “forward”为向前选择,"backward"为向后选择,"both"为混合选择
Start: AIC=97.75
Murder ~ Population + Illiteracy + Income + Frost
Df Sum of Sq RSS AIC
- Frost 1 0.021 289.19 95.753
- Income 1 0.057 289.22 95.759
- Population 1 39.238 328.41 102.111
- Illiteracy 1 144.264 433.43 115.986
Step: AIC=95.75
Murder ~ Population + Illiteracy + Income
Df Sum of Sq RSS AIC
- Income 1 0.057 289.25 93.763
- Population 1 43.658 332.85 100.783
- Illiteracy 1 236.196 525.38 123.605
Step: AIC=93.76
Murder ~ Population + Illiteracy
Df Sum of Sq RSS AIC
- Population 1 48.517 337.76 99.516
- Illiteracy 1 299.646 588.89 127.311
Call:
lm(formula = Murder ~ Population + Illiteracy, data = states)
Coefficients:
(Intercept) Population Illiteracy
1.6515497 0.0002242 4.0807366
可见原本的4元回归模型向后退了两次,最终稳定成了2元回归模型,与前面模型比较的结果一致。
- 全子集回归
《R语言实战》里提到了逐步回归法的局限:不是每个模型都评价了,不能保证选择的是“最佳”模型。比如上例中,从Murder ~ Population + Illiteracy + Income + Frost到Murder ~ Population + Illiteracy + Income再到Murder~Population+Illiteracy虽然AIC值确实在减少,但Murder ~ Population + Illiteracy + Frost没评价,如果遇到变量很多的情况下,逐步回归只沿一个方向回归,就有可能错过最优的回归方向。
library(leaps)
leaps <- regsubsets(Murder~Population+Illiteracy+Income+Frost,data=states,nbest=4)
plot(leaps,scale = "adjr2")
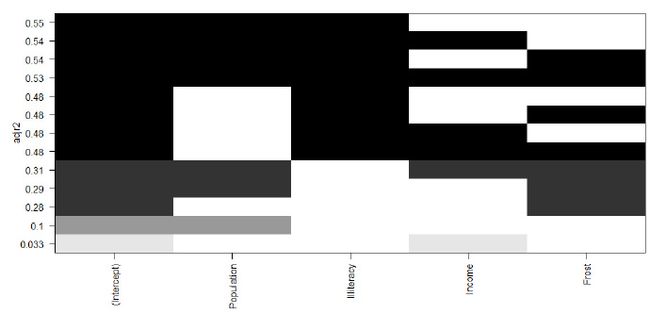
横坐标是变量,纵坐标是Adjusted R2,可见除截距项以外,只选定Population和Illiteracy这两个变量,可以使线性模型有最大的Adjusted R2。
全子集回归比逐步回归范围更广,模型优化效果更好,但是一旦变量数多了之后,全子集回归迭代的次数就很多,就会很慢。
事实上,变量的选择不是机械式地只看那几个统计指标,更主要的是根据数据的实际意义,从业务角度上来选择合适的变量。
线性模型变量的选择在《统计学习》后面的第6章还会继续讲到,到时继续综合讨论。
(3)交互项
交互项《统计学习》中花了一定篇幅来描写,但在《R语言实战》是在方差分析章节中讨论。添加变量间的交互项有时可以改善线性关系,提高Adjusted R2。针对数据的实际意义,如果两个基本上是独立的,也很难产生交互、产生协同效应的变量,那就不必考虑交互项;只有从业务角度分析,有可能产生协同效应的变量间才考虑交互项。
涉及到交互项有一个原则:如果交互项是显著的,那么即使变量不显著,也要放在回归模型中;若变量和交互项都不显著,则可以都不放。
(4)交叉验证
Andrew Ng的Machine Learning中就提到了,模型对旧数据拟合得好不一定就对新数据预测得好。因此一个数据集应当被分两训练集和测试集两部分(或者训练集、交叉验证集、测试集三部分),训练好的模型还要在新数据中测试性能。
所谓交叉验证,即将一定比例的数据挑选出来作为训练样本,另外的样本作保留样本,先在训练样本上获取回归方程,然后在保留样本上做预测。由于保留样本不涉及模型参数的选择,该样本可获得比新数据更为精确的估计。
在k 重交叉验证中,样本被分为k个子样本,轮流将k1个子样本组合作为训练集,另外1个子样本作为保留集。这样会获得k 个预测方程,记录k 个保留样本的预测表现结果,然后求其平均值。
bootstrap包中的crossval()函数可以实现k重交叉验证。
shrinkage <- function(fit, k = 10) {
require(bootstrap)
# define functions
theta.fit <- function(x, y) {
lsfit(x, y)
}
theta.predict <- function(fit, x) {
cbind(1, x) %*% fit$coef
}
# matrix of predictors
x <- fit$model[, 2:ncol(fit$model)]
# vector of predicted values
y <- fit$model[, 1]
results <- crossval(x, y, theta.fit, theta.predict, ngroup = k)
r2 <- cor(y, fit$fitted.values)^2
r2cv <- cor(y, results$cv.fit)^2
cat("Original R-square =", r2, "\n")
cat(k, "Fold Cross-Validated R-square =", r2cv, "\n")
cat("Change =", r2 - r2cv, "\n")
}
这个自定义的shrinkage()函数用来做k重交叉验证,比计算训练集和交叉验证集的R方差异。这个函数里涉及到一个概念:
复相关系数。
复相关系数实际上就是y和fitted(y)的简单相关系数。对于一元线性回归,R2就是简单相关系数的平方;对于多元线性回归,R2是复相关系数的平方。这个我没有成功地从公式上推导证明成立,就记下吧。这个方法用到了自助法的思想,这个在统计学习后面会细致讲到。
fit <- lm(Murder ~ Population + Income + Illiteracy +
Frost, data = states)
shrinkage(fit)
Original R-square = 0.5669502
10 Fold Cross-Validated R-square = 0.441954
Change = 0.1249963
可见这个4元回归模型在交叉验证集中的R2下降了0.12之多。若换成前面分析的2元回归模型——
fit2 <- lm(Murder ~ Population + Illiteracy , data = states)
shrinkage(fit2)
Original R-square = 0.5668327
10 Fold Cross-Validated R-square = 0.517304
Change = 0.04952868
这次R2下降只有约0.05。
R2减少得越少,则预测得越准确。
5、模型应用
(1)预测
最重要的应用毫无疑问就是用建立的模型进行预测了。构建好模型后,可用predict()函数进行预测——
fit2 <- lm(Murder ~ Population + Illiteracy , data = states)
predict(fit2,
newdata = data.frame(Population=c(2000,3000),Illiteracy=c(1.7,2.2)),
interval = "confidence")
fit lwr upr
1 9.037174 8.004911 10.06944
2 11.301729 9.866851 12.73661
这里newdata提供了两个全新的点供模型来预测。还可以用interval指定返回置信区间(confidence)或者预测区间(prediction),这也反映了统计与机器学习的一个差异——可解释性。注意置信区间考虑的是平均值,而预测区间考虑的是单个观测值,所以预测区间永远比置信区间广,因此预测区间考虑了单个观测值的不可约误差;而平均值同时也把不可约误差给抵消掉了。
(2)相对重要性
有的时候需要解释模型中各个自变量对因变量的重要程度,简单处理可以直接看系数即可,《R语言实战》里自定义了一个relweights()函数可以计算各个变量的权重:
relweights <- function(fit, ...) {
R <- cor(fit$model)
nvar <- ncol(R)
rxx <- R[2:nvar, 2:nvar]
rxy <- R[2:nvar, 1]
svd <- eigen(rxx)
evec <- svd$vectors
ev <- svd$values
delta <- diag(sqrt(ev))
# correlations between original predictors and new orthogonal variables
lambda <- evec %*% delta %*% t(evec)
lambdasq <- lambda^2
# regression coefficients of Y on orthogonal variables
beta <- solve(lambda) %*% rxy
rsquare <- colSums(beta^2)
rawwgt <- lambdasq %*% beta^2
import <- (rawwgt/rsquare) * 100
lbls <- names(fit$model[2:nvar])
rownames(import) <- lbls
colnames(import) <- "Weights"
# plot results
barplot(t(import), names.arg = lbls, ylab = "% of R-Square",
xlab = "Predictor Variables", main = "Relative Importance of Predictor Variables",
sub = paste("R-Square = ", round(rsquare, digits = 3)),
...)
return(import)
}
不要在意算法原理和代码逻辑这种细节,直接看结果:
fit <- lm(Murder ~ Population + Illiteracy + Income +
Frost, data = states)
relweights(fit, col = "lightgrey")
Weights
Population 14.723401
Illiteracy 59.000195
Income 5.488962
Frost 20.787442

fit$coefficients
(Intercept) Population Illiteracy Income Frost
1.2345634112 0.0002236754 4.1428365903 0.0000644247 0.0005813055
barplot(fit$coefficients[2:5])

在本例中,相对权重与系数的排序结果一致。推荐用相对权重。