我的Python数据分析笔记之一
利用Python 进行数据分析<.第二版>笔记基础一
- 数据
- 结构化数据
- 非结构化数据
- Python库
- [查看所拥有的方法] —— dir(object)
- Numpy
- 导入
- 创建ndarray
- 属性
- 方法
- Pandas
- 导入
- Ndarray和DataFrame
- Numpy_Pandas : Series_DataFrame_Panel
- Series
- 创建
- 方法
- DataFrame
- 创建
- 方法
- Panel
- 创建
(声明:本教程仅供本人学习使用,如有人使用该技术触犯法律与本人无关)
(如果有错误,还希望指出。共同进步)
【注】:【书籍在线地址】--------="" 这里 “”=--------
数据
- 分为结构化数据和非结构化数据
结构化数据
- 表格型数据,其中各列可能是不同的类型
- 多维数组(矩阵)
- 通过关键列相互联系的多个表,如SQL用户来说,就是指主键和外键
- 间隔平均或不平均的时间序列
非结构化数据
- 文章,例如新闻文章可以被处理成词频表转化为结构化数据
- 一段文字
- 总的来说就是:指没有维度索引的数据集合(自己理解)
Python库
- Numpy
- Pandas
- Matplotlib
- Scipy
- Scikit-learn
- statsmodels
[查看所拥有的方法] —— dir(object)
Numpy
导入
import numpy as np
创建ndarray
arr1 = np.array( parms:list )
- parms参数介绍
- 列表
- 嵌套序列(比如由一组等长列表组成的列表),如[[1, 2, 3, 4], [5, 6, 7, 8]]
属性
- np.ndim: 查看维度
- np.shape: 形状(各维度的长度)
- np.size: 总长度(元素的总个数)
- np.dtype: 元素类型
方法
-
np.astype(<类型>): 将np对象转换成指定的数据类型
几种常见的类型
1、np.float64
2、np.int32
3、np.int64
4、np.string_
arr = np.array([1, 2, 3, 4, 5])
float_arr = arr.astype(np.float64)
- np.ones(shape, dtype=None, order=“C”): 数据全部为1
ones = np.ones((400, 600, 3), dtype="float")
- np.zeros(shape, dtype=None, order=“C”) : 数据全部为0
- np.arange([start, ]stop, [step, ]dtype=None): 创建从start开始到stop(不包括stop)结束,以step为间隔的array对象,类型为dtype
- np.eye(5):对角线为1其它的位置为0 (5行5列)
- np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) :start:开始,stop:结束;num等分成多少
- np.random.randint(low, high=None, size=None, dtype=‘l’)
- np.random.randn(d0, d1, …, dn) (基数为0,方差为1,)
- np.random.normal(loc=0.0, scale=1.0, size=None): 伪随机数生成(loc定义基数,scale定义方差)
- np.random.random(size=None)
- np.where(cond, xarr, yarr): 根据cond中的值选取xarr和yarr的值:当cond中的值为True时,选取xarr的值,否则从yarr中选取
xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
cond = np.array([True, False, True, True, False])
result = np.where(cond, xarr, yarr)
# 拓展
# np.where(arr > 0, 2, -2)
# np.where(arr > 0, 2, arr)
result
# array([ 1.1, 2.2, 1.3, 1.4, 2.5])
- np.sum(arr, axis=0|1) : 求和
- arr.sum(axis=0|1)
- np.mean(axi=0|1): 求平均值
- np.cumsum(axis=0|1): 累加函数
- np.save(‘some_array’, arr): 将arr数组以未压缩的原始二进制格式保存在扩展名为.npy的文件中,文件路径末尾没有扩展名.npy,则该扩展名会被自动加上
- np.load(‘some_array.npy’):读取磁盘上的数组
- np.dot(x, y): 矩阵点乘
- arr1 @ arr2: 矩阵点乘
Pandas
导入
import pandas as pd
from pandas import Series
from pandas import DataFrame
from pandas import Panel
Ndarray和DataFrame
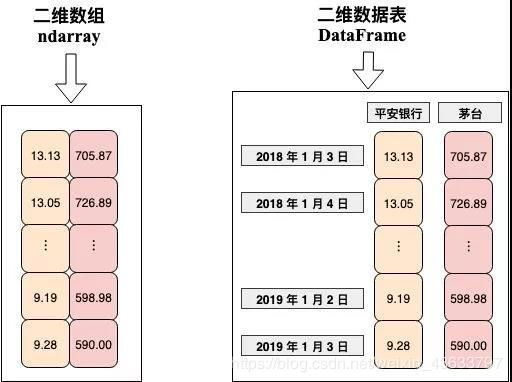
【下标默认如同列表的数字下标】/【拥有行索引和列索引】
Numpy_Pandas : Series_DataFrame_Panel
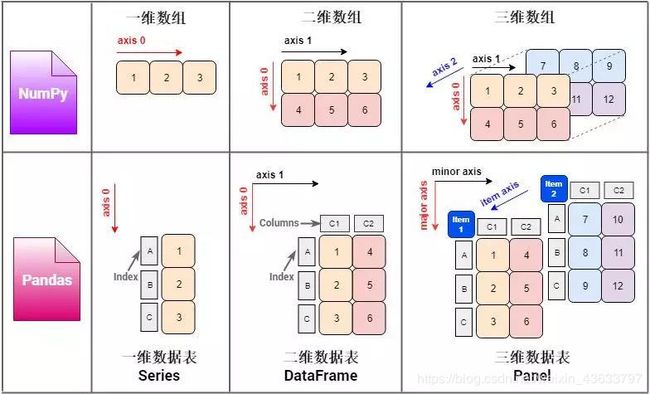
【解释】:np.narray对象中narray中的n指的是几维,如下的1D_array指的是1维的narray对象。
- Series = 1D_array + index
- DataFrame = 2D_array + index + columns
- Panel = 3D_array + index + columns + item
Series
是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,类似于 python 中的基本数据的 list 或 NumPy 中的 1D array。Pandas 里最基本的数据结构
字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引
创建
pd.Series( x, index=idx )
X 是位置参数,指的是数据值,类型可以是:
* 列表 (list)
* numpy 数组 (1D_array)
* 字典 (dict)X 参数详解
index是默认参数,设置的是数据下标参数,默认值:
* idx = range(0, len(x))
方法
ser = pd.Series([1, 2, 3, 4, 5, 6])
* ser.value: 打印ser中的数据元素
* ser.index: 打印ser中元素对应的索引
* ser.name: Series本身的name属性
* ser.index.name: Series索引的name属性
# 修改Series 的索引
ser.index = [1, 2, 3, 4, 5, 6]
# 修改 Series 的 name
ser.name = "测试用例"
# 修改 Series 的索引的 name
ser.index.name = "index_set"
* len(ser) : 统计个数
* ser.shape: 形状(用元组表示)
* ser.count(): ser中不含Nan的元素个数
* ser.unique(): 返回ser中不重复的元素
* ser.value_counts(): 统计ser中非Nan元素的出现次数
ser + ser
# >>> ser + ser
# 1 2
# 2 4
# 3 6
# 4 8
# 5 10
# 6 12
# dtype: int32
DataFrame
是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
二维数据,类似于 R 中的 data.frame 或 Matlab 中的 Tables。DataFrame 是 Series 的容器
最常见的数据类型是二维的 DataFrame,其中
- 每行代表一个示例 (instance)
- 每列代表一个特征 (feature)
DataFrame 可理解成是 Series 的容器,每一列都是一个 Series,或者 Series 是只有一列的 DataFrame
创建
pd.DataFrame( x, index=idx, columns=col )
X 是位置参数,指的是数据值,类型可以是:
* 二维列表 (list)
* 二维 numpy 数组 (3D_array)
* 字典 (dict),其值是一维列表、numpy 数组或 Series
* 另外一个 DataFrame
index是默认参数,设置的是数据"行"下标参数,默认值:
* idx = range(0, x.shape[0])
columns是默认参数,设置的是数据"列"下标参数,默认值:
* col = range(0, x.shape[1])
方法
data = {
'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]
}
# 创建DataFrame对象
df2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five', 'six'])
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
six 2003 Nevada 3.2 NaN
* del df2["debt"] : 删除指定列
* df2.head(n):查看前n行,默认是5行
* df2.tail(n):查看后n行,默认是5行
* df2.describe():统计数据
* df2.groupby():分组统计数据与统计函数连用如sum、max、count等
Panel
【注】: Panel 支持python2, 不支持python3
Panel 可理解成是 DataFrame 的容器
创建
pd.Panel( x, item=itm, major_axis=n1, minor_axis=n2 )
其中 x 可以是
* 三维列表 (list)
* 三维 numpy 数组 (3D_array)
* 字典 (dict),其值是 DataFrame
x 是位置参数
* items 是默认参数 (axis 0),默认值为 itm = range(0, number of DataFrame)
* major_axis 是默认参数 (axis 1),默认值和 DataFrame 的默认 index 一样
* minor_axis 是默认参数 (axis 2),默认值和 DataFrame 的默认 columns 一样
pn = pd.Panel(np.random.randn(2, 5, 4))