我的Python数据分析笔记二之Pandas
利用Python进行数据分析<.第二版>笔记基础二之Pandas
- Pandas层次化索引
- 创建多层行索引
- 1、隐式构造
- 2、显示构造pd.MultiIndex
- 多层列索引
- 多层索引对象的索引与切片操作
- 1、Series的操作
- 2、DataFrame的操作
- 索引的堆(stack)
- Pandas数据处理
- 1、删除重复元素
- 2. 映射
- replace()函数:替换元素
- map()函数:
- 1.字典
- 2.lambda函数
- 3.回调函数
- rename()函数:替换索引
- 3. 异常值检测和过滤
- 4. 排序
- 5. 数据聚合【重点】
- Pandas的拼接操作
- pd.concat()级联
- 1、简单级联
- 2、不匹配级联
- 3、使用append()函数添加
- pd.merge()合并
- 使用on=显式指定哪一列为key,当有多个key相同时使用,但是用法很少
- 当有不同的列名时(数据元素类型一样),使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不想等时使用
- left_index开启左边表的行索引,right_index开启右边表的行索引,类似级联
- 内合并与外合并,how="inner/outer/left/right"
- 列冲突的解决
【注】:此篇内容为作者整理补充,书籍中可能顺序有些差别。
(声明:本教程仅供本人学习使用,如有人使用该技术触犯法律与本人无关)
(如果有错误,还希望指出。共同进步)
Pandas层次化索引
创建多层行索引
1、隐式构造
Series:(二层索引)

DataFrame:

(三层索引):

2、显示构造pd.MultiIndex
1、使用数组:pd.MultiIndex.from_arrays()

2、使用tuple:pd.MultiIndex.from_tuples()

3、使用product:pd.MultiIndex.from_product()
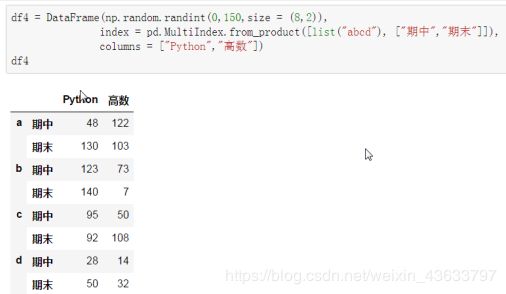
多层列索引
除了行索引Index,列索引columns也能用同样的方法创建多层索引
【注】:numpy.random.randint(0,100,size=8)表示8行一列;size=(1,8)表示一行8列

多层索引对象的索引与切片操作
1、Series的操作
【重要】对于Series来说,直接中括号[]与使用.loc()完全一样,因此,推荐使用中括号索引和切片。
2、DataFrame的操作
(1) 可以直接使用列名称来进行列索引
(2) 使用行索引需要用ix(),loc()等函数
【极其重要】推荐使用loc()函数
注意在对行索引的时候,若一级行索引还有多个,对二级行索引会遇到问题!也就是说,无法直接对二级索引进行索引,必须让二级索引变成一级索引后才能对其进行索引!只能行切片
索引的堆(stack)
stack():列索引放到行索引上面
unstack():行索引放到列索引上面
【小技巧】
使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。
where(条件):对数据的过滤,other用来指定不满足条件的参数
Pandas数据处理
1、删除重复元素
使用**duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
使用drop_duplicates()**函数删除重复的行
2. 映射
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
需要使用字典:
map = { 'label1':'value1', 'label2':'value2', ... }
replace()函数:替换元素

map()函数:
【*】:(常用)新建一列(由已有的列生成一个新列,或者修改当前列)
map函数的参数:
1.字典
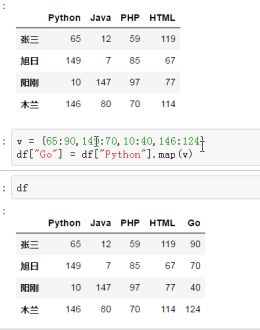
2.lambda函数
# 新建一列
df["c"] = df["GO"].map(lambda x : x-5)
# 修改当前“GO”列
df["GO"] = df["GO"].map(lambda x : x-5)
3.回调函数

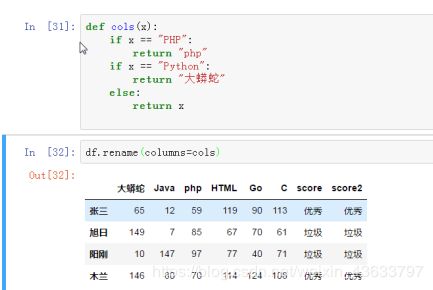
rename()函数:替换索引
仍然是新建一个字典
使用rename()函数替换行索引
3. 异常值检测和过滤
使用describe()函数查看每一列的描述性统计量
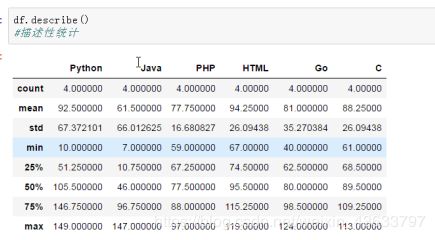
中位数:奇数个是最中间的数,偶数个是中间两个数的平均值
std():可以求得DataFrame对象每一列的标准差
df.drop(labels,inplace = True):删除特定索引
4. 排序
【排序】
1、使用**.take()函数排序
2、可以借助np.random.permutation()**函数随机排序
# nums 指dataframe数据的行数
df.take(np.random.permutation(nums))
【随机抽样】
当DataFrame规模足够大时,直接使用**np.random.randint()函数,就配合take()**函数实现随机抽样
# left 指随机数据行数开始行
# right 指随机数据行数结束行
# nums 指随机抽样数据的个数
df.take(np.random.randint(left, right, size=nums))
5. 数据聚合【重点】
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。

数据分类处理:
核心: groupby()函数
分组:先把数据分为几组——groupby()之后的数据是一个对象;一般后面跟上聚合操作
用函数处理:为不同组的数据应用不同的函数以转换数据
合并:把不同组得到的结果合并起来
Pandas的拼接操作
pandas的拼接分为两种:
级联:pd.concat, pd.append
合并:pd.merge, pd.join
pd.concat()级联


1、简单级联
和np.concatenate一样,优先增加行数(默认axis=0),可以通过设置axis来改变级联方向;【注意】index在级联时可以重复
也可以选择忽略ignore_index,重新索引

或者使用多层索引 keys
concat([x,y],keys=[‘x’,‘y’])

2、不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致;有3种连接方式:
–外连接:补NaN(默认模式),join=“outer”;默认
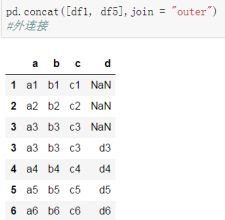
–内连接:只连接匹配的项,匹配不到的不要

–连接指定轴 join_axes

3、使用append()函数添加
由于在后面级联的使用非常普遍,因此有一个函数append专门用于在后面添加
pd.merge()合并
merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
1)一对一合并(重复的保留一次)
2)多对一合并(数据总数为:多乘一+不重复的)
3)多对多合并(数据总数:多乘多+不重复的)
4) key的规范化:
使用on=显式指定哪一列为key,当有多个key相同时使用,但是用法很少

suffixes用来指定合并后的列名

当有不同的列名时(数据元素类型一样),使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不想等时使用

left_index开启左边表的行索引,right_index开启右边表的行索引,类似级联

内合并与外合并,how=“inner/outer/left/right”

内合并:只保留两者都有的数据(默认模式)
外合并:数据没有的补上Nan
左合并:左边表的数据一个都不能少,即使不上Nan也不能把数据丢掉
右合并:右边表的数据一个都不能少,即使不上Nan也不能把数据丢掉
列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
可以使用suffixes=自己指定后缀