Windows环境下python爬虫常用库和工具的安装(UrlLib、Re、Requests、Selenium、lxml、Beautiful Soup、PyQuery 、PyMySQL等等)
本文列出了使用python进行爬虫时所需的常用库和工具的安装过程,基本上只有几行命令行的功夫就可以搞定,还是十分简单的。
目录
- 一、UrlLib 与 Re
- 验证
- 二、Requests
- 验证
- 三、Selenium
- 验证
- ChromeDriver的安装
- 四、PhantomJs
- 五、lxml
- 未顺利安装
- 六、Beautiful Soup
- 七、PyQuery
- 八、PyMySQL
- 九、PyMongo
- 十、Redis
- 十一、Flask
- 十二、Django
- 十三、Jupyter
- 结束
一、UrlLib 与 Re
这两个库是python的内置库,若系统中已经成功安装了python的话,这两个库一般是没有什么问题的。
验证
打开命令行,进入python交互模式。使用以下命令:
import urllib
import urllib.request
urllib.request.urlopen(‘http://www.baidu.com’)
也就是先导入urllib以及其下的request库,并传入百度的网址进行测试如下图:

回车后返回了值,说明这个库是可以正常使用的。
再导入re,没有报错,那么一切ok。如下图:
二、Requests
这个库要的安装要用到第三方工具(pip)
首先进入命令行模式,进行pip的安装:
pip3 install requests
![]()
验证
进入python交互模式,输入以下命令并回车:
import requests
requests.get(‘http://www.baidu.com’)
得到返回值,说明这个库可以正常使用了。
三、Selenium
这是一个用来驱动浏览器的库,主要用来做自动化测试,可以拿到网页经过js渲染后的内容。
首先进入python交互模式,看看这个库是否已经安装。输入以下命令并回车:
import selenium

如果看到了上图的报错,恭喜你,咱们还没安装呢。
那么就用pip来安装吧~
使用命令行模式,输入以下命令并回车:

如果所示,安装完毕。
验证
在python交互模式下,输入以下命令并回车:
import selenium
如果没有出现之前的报错,就说明安装成功了。
接下来继续测试一下这个库中的命令。
在python交互模式下,输入以下命令并回车:
from selenium import webdriver
driver = webdriver.Chrome()

这里试图创建一个浏览器对象并且直接启动Chrome浏览器,但是现在缺少一个Chrome驱动器,因此报错了。所以接下来我们需要安装这个ChromeDriver。
ChromeDriver的安装
在搜索引擎中搜索ChromeDriver,一般第一个就是其官网,咱们进去看看。
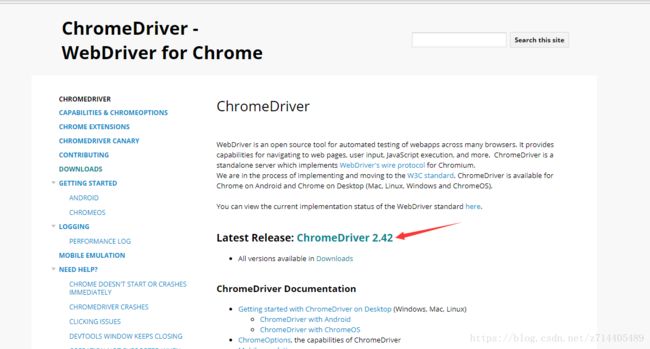
箭头所指的地方发布了最新版本,咱们下它!
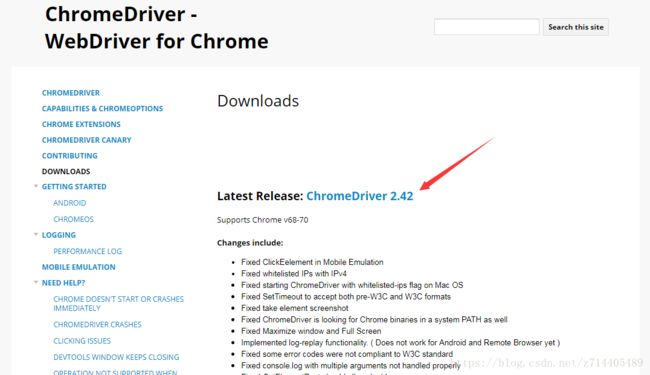
进入之后看到有许多版本,我们下载windows那个。
把下载好的压缩包解压后会得到一个可执行文件,我们把它解压到某个已经配置好环境变量的路径下(比如Anaconda3目录下)
或者把这个exe放到Scipts文件夹下也是可以的,那么它将和pip处在同一级的目录下。
以上的目录都是已经配置好环境变量的,那么现在系统就可以找到这个chromedriver了。在命令行模式下,输入以下命令并回车:
chromedriver
可以看到已经ok了。
现在再次进行刚才的尝试,在python交互模式下,输入以下命令并回车:
from selenium import webdriver
driver = webdriver.Chrome()
如果你看到浏览器一闪而过,并且命令行窗口中给出报错信息,别抓狂,这可能是由于chrome的版本不匹配导致的。 所以就需要换一个版本使其兼容。
http://chromedriver.chromium.org/downloads
进入以上的网址(也就是之前下载chromedriver的地方),并往下浏览,可以看到更早时候的版本。选择一个更低的版本进行下载,并重复之前的步骤,最后替换掉之前下载的exe文件。那么这就完成了一个版本的更换。
那么现在再试一次吧~
在python交互模式下,输入以下命令并回车:
from selenium import webdriver
driver = webdriver.Chrome()
终于乖乖蹦出来了一个浏览器!
继续测试:
python交互模式下,输入以下命令并回车:
driver.get(‘http://www.baidu.com’)

可以看到,该浏览器跳转到了百度的界面。
再换个网址试试?
python交互模式下,输入以下命令并回车:
driver.get(‘https://www.python.org’)
![]()
可以看到,浏览器又跳转到了python的官网。
紧接着我们使用page_source语句就可以打印出网页的源代码了:
driver.page_source
![]()
可以看到窗口中打印出了一堆代码,反正我是看得密集恐惧症都犯了。
其实这就是上面python官网页面的源代码了。
总之~通过selenium库,我们就可以拿到js渲染过的网页的内容了。
四、PhantomJs
现在我们觉得在做爬虫时,一直存在一个浏览器的界面摆在那儿太不方便了,有没有一个没有浏览器界面的运行模式呢?
PhantomJs就是一个安静的美男子(无界面的浏览器)。有了它,就可以让它在后台静默的运行,这样爬虫时我们只需要看着命令行就行了。
现在我们到官网去下载它:
http://phantomjs.org/download.html
你你自己去搜索也行~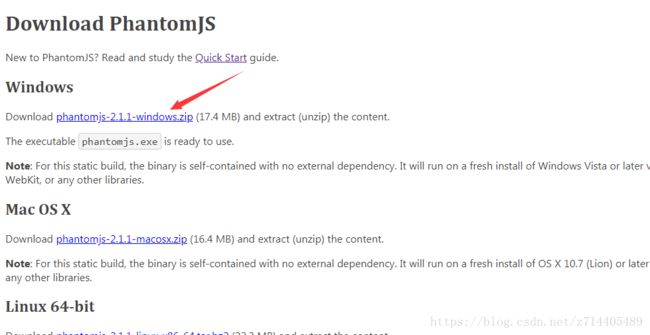
找到windows版本,点击就可以下载了压缩包了。
下载好之后解压(随便解压到哪儿),解压后可以看到,在bin目录下有一个exe文件。
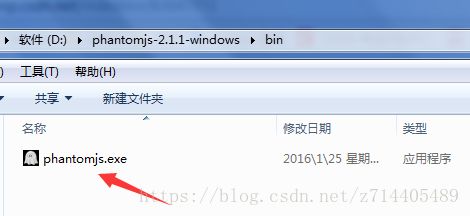
现在我们要把它配置到环境变量中去:
计算机–>右键–>属性–>高级系统设置–>环境变量
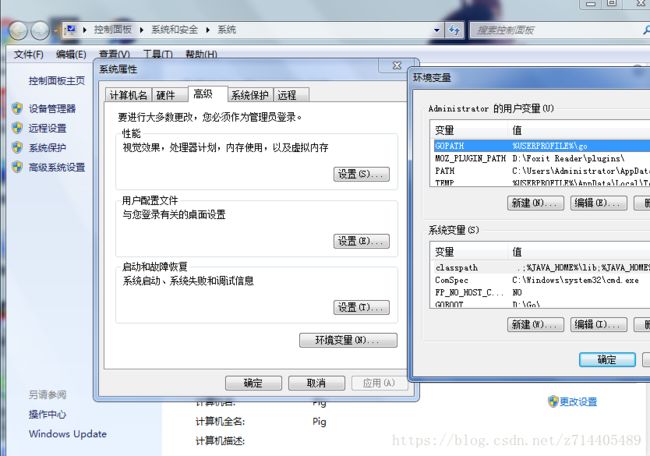
编辑用户变量中的PATH:
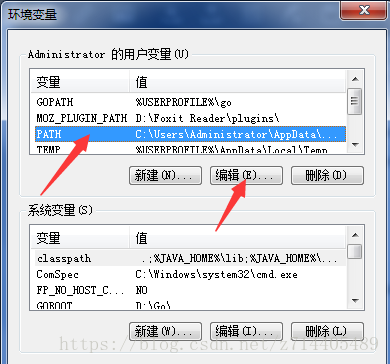
把exe文件所在bin的目录拷贝到PATH编辑栏的最后(注意与之前的路径用半角的分号隔开)。
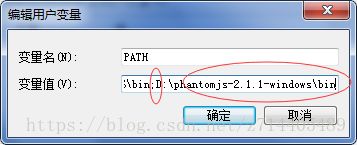
确定后就配置好环境变量了。
现在在命令行模式下输入phantomjs并回车:

竟然不行,有点尴尬啊,我去重启试试……
(1分钟后)我又回来了,现在再试一次看看:

果然重启后就可以了,不知道是否一定要重启呢?
如上图,现在就进入了交互模式,现在试试执行一些js程序,因为这里此时相当于一个网络控制台。
console.log(‘Hello World!’)
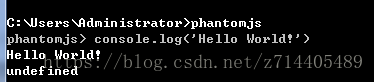
使用ctrl+C可以切换回命令行模式。
现在使用python交互模式:
依次使用如下命令:
from selenium import webdriver
driver=webdriver.PhantomJS()
driver.get(‘http://www.baidu.com’)
driver.page_source
可以看到,让我密集恐惧症的东西又被打印出来了,这就是百度首页的源代码了,比起上次,这次我们并没有看到浏览器的窗口,这就是PhantomJs的好处了。
五、lxml
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高。
安装方法:在命令行模式下,输入pip3 install lxml并回车。

如果已经安装好会出现上图提示,如果未安装过,会执行安装过程(如下图),稍微等待就好了。

未顺利安装
( 顺利安装可以跳过此节)
如果未fan墙或是网络原因导致安装过程过慢,那么去搜索lxml:
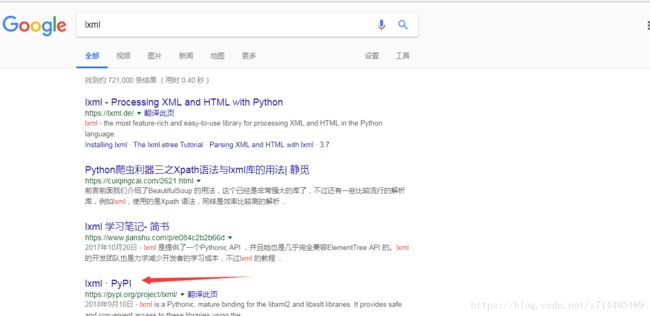
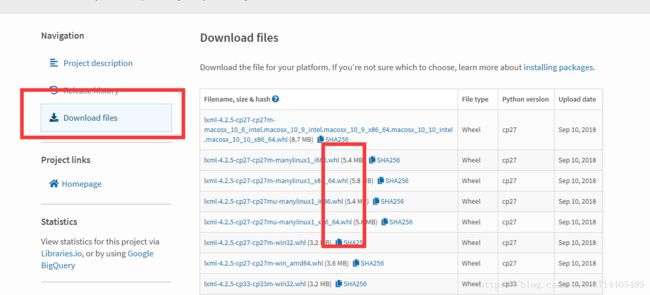
可以选择一个whl来下载并且使用pip安装,前提是必须安装whell库(使用pip3 install wheel命令)。
安装过程:
先下载好whl文件(注意下载的是对应win系统的),在文件夹中显示,并右键–>属性–>安全,可以看到文件的完整路径。
![]()
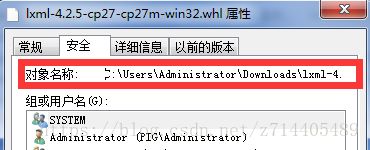
把这个路径复制下来,在命令行中执行命令:
pip3 install +路径。
(在命令行窗口属性中勾选快速编辑模式,可以直接在光标处右击就可以完成复制)

注意要先安装wheel库:pip3 install wheel

如果出现lxml-3.7.3-cp35-cp35m-win32.whl is not a supported wheel on this platform.红色字体(如上图),则是*.whl文件选择错误,重新下载对应的*.whl文件重新安装即可(32位或64位看清楚再下载)。
六、Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup会帮你节省数小时甚至数天的工作时间,就如它的名字一样“美丽”~
注意,这个库是依赖在lxml库下的,所以安装这个库前必须已经完成了上一步的安装。
安装过程:在命令行输入
pip3 install beautifulsoup4
并回车(别漏了4,这是个版本号)。
检查:
在python交互模式下,输入命令并回车:
from bs4 import BeautifulSoup
soup=BeautifulSoup(’’,‘lxml’)
![]()
这是创建一个beautifulsoup对象并且调用方法进行解析。
没有报错的话就说明一切顺利啦~
七、PyQuery
前端大大们的福音来了,PyQuery 来了,乍听名字,你一定联想到了 jQuery,如果你对 jQuery 熟悉,那么 PyQuery 来解析文档就是不二之选。PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。不熟悉也没关系,它依然很友好。
安装:
命令行模式下输入并回车:
pip3 install pyquery
如上图就已经安装完毕了。
验证:
进入python交互模式,依次输入以下命令并回车:
from pyquery import PyQuery as pq
doc=pq(’’)
doc=pq(‘Hello’)
result=doc(‘html’).text()
result
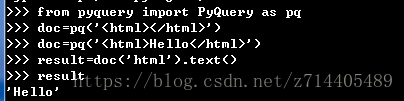
可以看到我们写入的内容被成功打印了。
八、PyMySQL
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb。
安装:
在命令行模式下输入
pip3 install pymysql
并回车。
很顺利吧。验证过程需要与数据库进行交互,这部分暂时略过。
九、PyMongo
PyMongo是一个用于MongoDB的Python工具,也是一个被推荐的Python操作MongoDB数据库的方式。
安装:
首先检查MongoDB服务是否已经启动。
在命令行模式下执行命令: pip3 install pymongo

验证:
在python交互模式下依次执行以下命令:
import pymongo
client=pymongo.MongoClient(‘localhost’)
db=client[‘newtestdb’]
db[‘table’].insert({‘name’:‘Bob’})
db[‘table’].find_one({‘name’:‘Bob’})
![]()
最后不报错并返回信息,说明可以正常使用了。
十、Redis
这也是一个非关系型数据库,用key-value形式进行存储,它主要用在分布式爬虫,维护一个爬取队列,它的运行效率还是很高的。
安装:
在命令行模式下执行
pip3 install redis

验证:
在python交互模式下依次执行以下命令:
import redis
r=redis.Redis(‘localhost’,6379)
r.set(‘name’,‘Bob’)
r.get(‘name’)

如上图,写入和获取数据一切顺利。
十一、Flask
这是一个Web库。后续做一些代理设置的时候可能会用到这个库,因为我们要设置一个Web服务器,用它来设置一些代理的获取、存储之类的接口。
安装:
依然十分简单,在命令行模式下执行以下命令:
pip3 install flask
十二、Django
这个库是一个Web服务器框架,它提供了一个完整的后台管理,以及一些模板、接口、路由,也可以用它来做一个完整的网站。
安装:
依然依然十分简单,在命令行模式下执行以下命令:
pip3 install django
搞定!
验证:
在python交互模式下执行import django

如果没有报错就说明成功了。
十三、Jupyter
可以理解为一个强大的记事本,它运行在网页端,你可以在记事本里写上些代码和调试…形成一个非常方便的代码纪录。
安装:
依然依然依然十分简单,在命令行模式下执行以下命令:
pip3 install jupyter
安装完后可以看到在Scipts文件夹下多了这么些相关的东东:
验证:
在命令行模式下直接执行
jupyter notebook
可以发现这时跳出了一个新的网页:
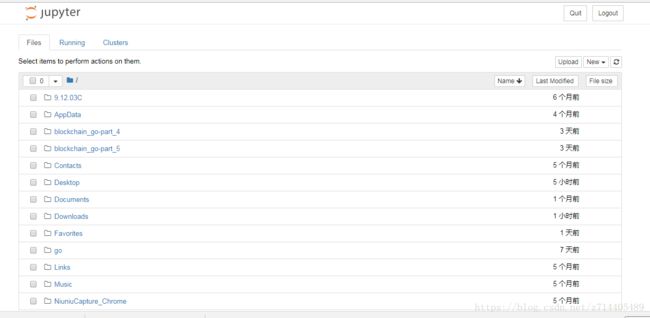
这个网页列出了当前执行目录下的一些文件信息。
我们甚至可以直接在网页上新建一个代码文件:
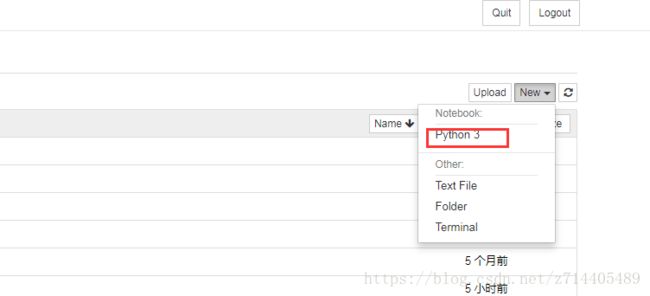
在编辑框中键入代码并执行(左边的小按钮),可以看到代码顺利执行了,它使用的解释器就是其所在目录的python3解释器。
那么我们再试试,按下键盘的"B"键可以新建一个代码块,我们运行以下的程序:
import requests
response = requests.get(‘http://www.baidu.com’)
print(response.text)
执行后可以看到,打印出了密集…的东西。
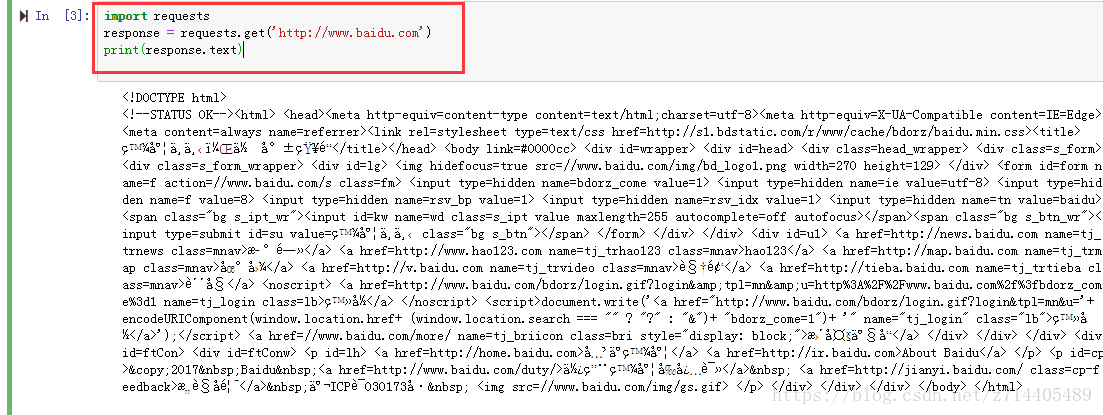
厉害吧,在上面还可以进行Markdown等其他模式的编程…等等。
结束
好了,至此,所有相关的库和工具基本上安装完毕了,开始愉快的爬虫把!