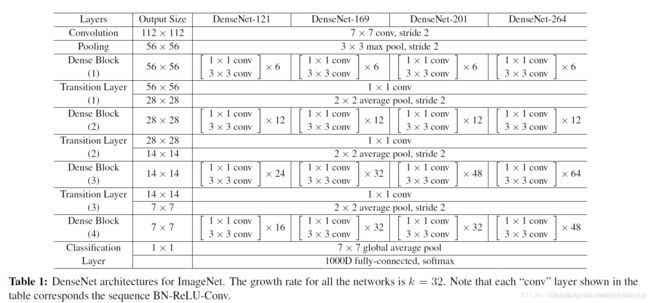
如图所示,densenet由多个denseblock组成,每个densebolck为稠密连接,即每层输入都接受该层之前所有的输入,代码实现如下。
def block(net, layers, growth, scope='block'):
for idx in range(layers):
bottleneck = bn_act_conv_drp(net, 4 * growth, [1, 1],
scope=scope + '_conv1x1' + str(idx))
tmp = bn_act_conv_drp(bottleneck, growth, [3, 3],
scope=scope + '_conv3x3' + str(idx))
net = tf.concat(axis=3, values=[net, tmp])
return net
这种稠密连接的方式即为跳接 ,bn_act_conv_drp为denseblock内每层之间所做的操作,包括BN,激活,卷积,池化:
def bn_act_conv_drp(current, num_outputs, kernel_size, scope='block'):
current = slim.batch_norm(current, scope=scope + '_bn')
current = tf.nn.relu(current)
current = slim.conv2d(current, num_outputs, kernel_size, scope=scope + '_conv')
current = slim.dropout(current, scope=scope + '_dropout')
return current
growth为增长率,表示每层输出feature map的数目:
每个block之间有个transition layer,用于减少每个block输出的维度。
def transition(net, num_outputs, scope='transition'):
net = bn_act_conv_drp(net, num_outputs, [1, 1], scope=scope + '_conv1x1')
net = slim.avg_pool2d(net, [2, 2], stride=2, scope=scope + '_avgpool')
return net
以下为densenet的整体代码:
def densenet(images, num_classes=1001, is_training=False,
dropout_keep_prob=0.8,
scope='densenet'):
growth = 24
compression_rate = 0.5
def reduce_dim(input_feature):
return int(int(input_feature.shape[-1]) * compression_rate)
end_points = {}
with tf.variable_scope(scope, 'DenseNet', [images, num_classes]):
with slim.arg_scope(bn_drp_scope(is_training=is_training,
keep_prob=dropout_keep_prob)) as ssc:
net = images
net = slim.conv2d(net, 2*growth, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='pool1')
net = block(net, 6, growth, scope='block1')
net = transition(net, reduce_dim(net), scope='transition1')
net = slim.avg_pool2d(net, [2, 2], stride=2, scope='avgpool1')
net = block(net, 12, growth, scope='block2')
net = transition(net, reduce_dim(net), scope='transition2')
net = block(net, 24, growth, scope='block3')
net = transition(net, reduce_dim(net), scope='transition3')
net = block(net, 16, growth, scope='block4')
net = slim.batch_norm(net, scope='last_batch_norm_relu')
net = tf.nn.relu(net)
net = tf.reduce_mean(net, [1, 2], name='pool2', keep_dims=True)
blases_initializer = tf.constant_initializer(0, 1)
net = slim.conv2d(net, num_classes, [1, 1], biases_initializer=blases_initializer, scope='logits')
logits = tf.squeeze(net, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
end_points['predictions'] = slim.softmax(logits, scope='predictions')
return logits, end_points
DenseNet 连接比较密集,实现起来只能进行反复拼接(tf.concat),将之前层的输出与当前层的输出拼接在一起,然后传给下一层(即densenet的主要创新点)。对于tensorflow而言,每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个 L 层的网络,要消耗相当于 L(L+1)/2 层网络的内存(第 l 层的输出在内存里被存了 (L-l+1) 份)。导致densenet会消耗较多的显存