Python 不用selenium 带你高效爬取京东商品评论
文章目录
- 一、项目说明
- 1.项目背景
- 2.项目环境
- 二、项目实施
- 1.项目分析
- 2.代码实现
- 导入模块和定义常量
- 爬取评论主体函数
- 主函数
- 三、项目分析和说明
- 1.运行测试
- 2.改进分析
- 3.其他说明
一、项目说明
1.项目背景
一天,一朋友扔给我一个链接https://item.jd.com/100000499657.html,让我看看这个歌商品的所有评论怎么抓取,我打开一看,好家伙,竟然有近300万条评论,不是一个小数目啊。
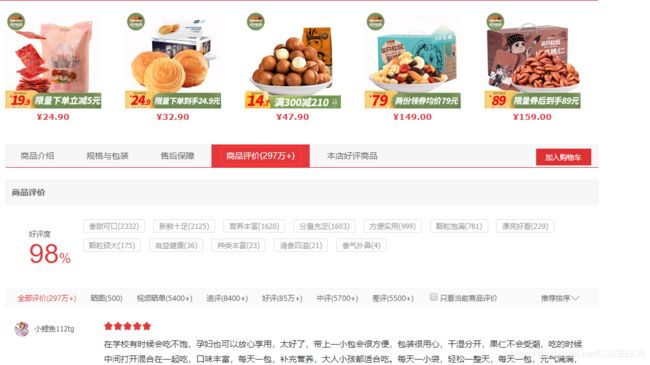
但是仔细一看,原来有234万+的评论是默认好评,还是有少部分是有价值的评价的。
经过进一步观察,可以看到

显然,网页中显示的只有100页数据,每页显示10条,通常可以用selenium点击每一页然后获取,但是这样效率是不是太低了呢?还是直接用requests来得更直接,很多情况下网页显示的数据是请求得到的JSON数据在网页上渲染而显示出来的,京东的评论会不会也是这样呢?好,说干就干!!!
2.项目环境
这个小项目使用Python爬取,不需要太多的配置,只需要安装requests库就足够 ,我相信对于很多玩爬虫的小伙伴来说这个库肯定是必备的,没装requests不要告诉我你会爬虫 。
二、项目实施
1.项目分析
上面说到,网页中的数据很多都是通过渲染请求的JSON数据得到的,那么我们就来看看京东是不是也是这样的。
利用浏览器的审计工具,选择Network栏,可以看到

仔细查看,寻找链接中于评论(comment)有关的链接,可以找到其中的一个请求链接https://club.jd.com/comment/productCommentSummaries.action?referenceIds=100000499657&callback=jQuery1951081&_=1586669401777,如上图。这是关于该商品评论的整体情况的,可以看到具体的总评论数、默认好评数、好评数、好评率等,虽然不是我们想要的,但是也近了一步,继续寻找,又找到了一条带comment字眼的链接https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100000499657&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1,如图

后边有10条评论,应该就是该商品对应的第一页评论了,点开查看,如下:

对比网页中显示的评论可以看到,这就就是我们要找的东西。
由于得到的数据不是标准格式的JSON,所以我选择使用正则表达式来获取相关的内容。
现在还有一个问题,我们只获得了1页评论,那怎么获取所有的评论呢?会不会秘密隐藏在链接中呢?
对于链接https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100000499657&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1,显然有很多参数,不难找到,有参数productId和page,如果猜得不错,应该是商品id和评论页数(从0开始),这时,换一个商品id,那么商品id怎么获得呢?举个例子,在链接https://item.jd.com/100000499657.html中,商品id就是100000499657。另找一个商品,将其商品id替换掉评论链接中的productId,获得的正是该商品的第一页评论。现在尝试翻页,逐渐增大page参数的值,如1、2、3…,也能获取到对应页的评论数据。
现在分析工作已经做的差不多了,可以开始码代码了。
2.代码实现
导入模块和定义常量
import re
import time
import csv
import os
import requests
import html
# 设置请求头
headers = {
'cookie': 'shshshfp=22dd633052035d21be92463ffa35684d; shshshfpa=ab283f84-c40f-9710-db89-84a8d3366a81-1586333030; __jda=122270672.1586333031101106032014.1586333031.1586333031.1586333031.1; __jdv=122270672|direct|-|none|-|1586333031103; __jdc=122270672; shshshfpb=bUe7tI9%2FOOaJKd7vP0EtSOg%3D%3D; __jdu=1586333031101106032014; areaId=22; ipLoc-djd=22-1977-1980-0; 3AB9D23F7A4B3C9B=7XEQD4BFTGEH44EK7LN7HLFCHJW6W2NS5VJOQOCHABZVI7LXJJIW3K2IX5MTPZ4TBERBLY6TRQR5CA3S3IYVLQ2JGI; jwotest_product=99; shshshsID=a7457cee6a4a9fa285fe2cff44c6bd17_4_1586333142454; __jdb=122270672.4.1586333031101106032014|1.1586333031; JSESSIONID=8C21549A613B83F0CB86EF1F38FD63D3.s1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36'
}
导入需要使用到的模块,并且定义请求头用于请求,减少被反爬的概率。
爬取评论主体函数
def comment_crawl(page, writer):
'''爬取评论'''
print('当前正在下载第%d页评论' % (page + 1))
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100000499657&score=0&sortType=5&page=%d&pageSize=10&isShadowSku=0&fold=1' % page
# 请求链接获取数据
text = requests.get(url, headers=headers).text
# 正则表达式匹配数据
comment_list = re.findall(
r'guid":".*?"content":"(.*?)".*?"creationTime":"(.*?)",".*?"replyCount":(\d+),"score":(\d+).*?usefulVoteCount":(\d+).*?imageCount":(\d+).*?images":',
text)
for result in comment_list:
# 根据正则表达式结果匹配数据
content = html.unescape(result[0]).replace('\n', ' ')
comment_time = result[1]
reply_count = result[2]
score = result[3]
vote_count = result[4]
image_count = result[5]
# 写入数据
writer.writerow((comment_time, score, reply_count, vote_count, image_count, content))
这是爬取评论的主体部分,在请求获取到数据后,通过正则表达式匹配到所需内容。
这里有一个注意点,html.unescape(result[0])是为了将评论内容的HTML转义字符如…等转化成普通字符串,这样数据更完整清晰。
主函数
if __name__ == '__main__':
'''主函数'''
start = time.time()
if os.path.exists('DATA.csv'):
os.remove('DATA.csv')
with open('DATA.csv', 'a+', newline='', encoding='gb18030') as f:
writer = csv.writer(f)
writer.writerow(('留言时间', '评分', '回复数', '点赞数', '图片数', '评论内容'))
for page in range(100):
comment_crawl(page, writer)
run_time = time.time() - start
print('运行时间为%d分钟%d秒。' % (run_time // 60, run_time % 60))
主函数创建文件用于保存数据,并对程序计时,以观察执行效率。
三、项目分析和说明
1.运行测试
整个小项目很简单,重点在分析过程和思路,只要分析好了,代码实现就很容易。
一次测试的示意如下:

效率还是很不错的,23秒内获取了近千条评论。
数据部分截图如下:

如果需要获取其他商品评论在代码中直接更改函数中url的productId即可。
完整代码可点击https://download.csdn.net/download/CUFEECR/12323279下载。
2.改进分析
- 采用的是单线程,在数据较少时尚可,一旦需要爬取的评论较多时,可能会有效率上的瓶颈,因此可以用多线程或多进程,主函数中改进如下:
pool = ThreadPoolExecutor(3)
...
for page in range(100):
pool.submit(comment_crawl, page, data_list)
代码可点击https://download.csdn.net/download/CUFEECR/12323373下载学习。
演示如下:

运行时间缩短了三分之一左右,显然大大提高了效率。
- 因为京东的反爬措施较少,因此对反爬的防范措施也较少,爬取较少尚可,如果需求较高时,肯定会触发反爬机制,从而导致爬取失败。
- 扩展性还有待提高,目前只是爬取了京东商品评论,但是对于别的电商平台如淘宝就很难搞了,这对代码提出了进一步要求。
3.其他说明
- 本项目仅限学习和计数交流之用,不得用于恶意爬虫、非法牟利等用途,违者责任自负。
- 如侵犯他人利益,请联系删改。