
翻译 | AI科技大本营(rgznai100)
参与 |尚岩奇、周翔
8 月 6 日,为期 6 天的国际机器学习大会 ICML 在澳大利亚悉尼正式拉开帷幕。据统计,今年的 ICML 共接收 1676 篇论文,其中 434 篇被收录,双双创下历史记录。作为谷歌学术中排名最高的机器学习相关的出版机构,以及被中国计算机学会推荐的A类人工智能国际学术会议,ICML 的在机器学习理论研究方面的地位毋庸置疑。
根据 ICML 官方的消息,今年的最佳论文奖(Best Paper Award)被 Pang Wei Koh 和 Percy Liang 收入囊中,其中 Pang Wei Koh 目前是斯坦福大学的在读博士生,而 Percy Liang 则是斯坦福大学的助理教授,都是华人。

左:Pang Wei Koh;右: Percy Liang
AI科技大本营发现,Pang Wei Koh 来自新加坡,是名副其实的学神,其 GRE的成绩为:Quantitative 800/800,Verbal 800/800,Writing 6/6,大学本科的整体平均 GPA 为 4.19/4, CS 专业的 GPA 为 4.23/4。不仅如此,Pang Wei Koh 还曾经与吴恩达共事,并在 2012 年的时候加入 Coursera,成为该在线教育平台的第三名员工。2015 年的时候,Pang Wei Koh 重返斯坦福大学做研究,2016 年正式开始博士生涯,而这篇 ICML 2017 最佳论文则是 Pang Wei Koh 和助理教授 Percy Liang 的工作成果之一。
根据 jeffhuang 的统计,华人首次获得 ICML 最佳论文奖可以追溯到 2010 年,之后 ICML 2014 的最佳论文奖则被北京大学的 Jian Tang 拿下,而 ICML 2016 的三篇最佳论文之一“Dueling Network Architectures for Deep Reinforcement Learning”的第一作者是 Ziyu Wang。
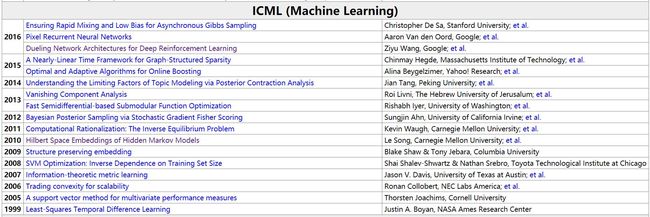
jeffhuang 统计的自 1999 年以来的 ICML 历届最佳论文清单
与此同时,另一重磅奖项——最具时间价值奖(Test of Time Award)则颁给了 Sylvain Gelly 和 David Silver,以奖励他们在蒙特卡洛树搜索算法领域的贡献。此外,还有 4 篇论文获荣誉奖(Honorable Mentions)。
以下是获奖论文简介:
最佳论文奖(Best Paper Award)

论文标题:借助影响函数理解黑箱预测(Understanding Black-box Predictions via Influence Functions)
论文作者:Pang Wei Koh、Percy Liang
论文摘要:如何解释黑箱模型作出的预测?在本文中,我们利用影响函数法(稳健统计中的一种经典方法)追踪模型的预测,以此识别出最可能导致给定预测的训练点。为了扩展影响函数使其适应现代机器学习系统,我们开发了一种简单且高效的实现方法,这种方法只需用到梯度的 oracle 访问途径以及 Hessian 向量积。我们证明了,即使是在不适用理论的 non-convex 模型和 non-differentiable 模型上,影响函数的近似算法仍能给出很有用的信息。我们在线性模型和卷积神经网络上证明了影响函数可作以下用途:理解模型行为、调试模型、检测数据集错误以及生成视觉上无法分辨的训练集攻击。
论文地址:https://arxiv.org/pdf/1703.04730.pdf
最具时间价值奖(Test of Time Award)

论文标题:整合 UCT 算法中的在线和离线知识(Combining Online and Offline Knowledge in UCT)
论文作者:Sylvain Gelly、David Silver
论文摘要:UCT 算法利用基于样本的搜索来学习在线价值函数。针对策略性分布(on-policy distribution),T D(λ) 算法可以离线学习价值函数。我们探讨了三种在 UCT 算法里整合离线和在线价值函数的方法。
方法一:在进行 Monte-Carlo(蒙特卡洛) 模拟期间将离线价值函数作为默认策略;
方法二:将 UCT 价值函数与对行动值(action values)的快速在线预测相整合;
方法三:将离线价值函数用作为 UCT 搜索树中的先验知识。
我们让这些算法与 GnuGo 3.7.10 在 9×9 的围棋上进行对战,以此对这些算法作出评估。第一个算法在表现上要好于使用随机模拟策略的 UCT 算法,但是却意外地落后于使用较差的人为模拟策略。第二个算法的表现优于 UCT 算法。第三个算法的表现优于使用人为模拟策略的 UCT 算法。我们在MoGo(最强大的 9 × 9 围棋程序)中整合了这些算法。每种方法都可以在很大程度上提高MoGo 的棋术。
AI科技大本营注:UCT 算法(Upper Confidence Bound Apply to Tree),即上限置信区间算法,是一种博弈树搜索算法,该算法将蒙特卡洛树搜索(Monte—Carlo Tree Search,MCTS)方法与 UCB 公式结合,在超大规模博弈树的搜索过程中相对于传统的搜索算法有着时间和空间方面的优势。
论文地址:http://www.machinelearning.org/proceedings/icml2007/papers/387.pdf
荣誉奖(Honorable Mentions)

论文标题:Pegasos: Primal Estimated sub-GrAdient SOlver for SVM
论文作者:Shai Shalev-Shwartz、Yoram Singer、Nathan Srebro、Andrew Cotter
论文摘要:本文阐述并分析了一种简单且有效的随机次梯度下降算法,这种算法可以解决支持向量机(SVM)的优化问题。我们证明了,得出精准度解决方案所需的迭代次数为 ε 是
而且每次迭代都在单个训练实例上进行。相反地,此前针对 SVM 的随机梯度下降法求解则需要进行
次迭代。在先前设计的 SVM 求解算法中,迭代次数也以 1/λ 线性增加,其中 λ 为SVM的正则化参数。对于线性核函(linear kernel)来说,我们方法的总运行时间为
,
其中 d 为每个实例中非零特征数量的限制参数。由于运行时间的长短与训练集的大小无直接关系,因此得出的算法特别适合用于学习大数据集。我们的方法在只求解原始目标函数(primal objective function)时经扩展还可以求解非线性核函数,但是在这种情况下,总运行时间与训练集大小呈线性关系。我们的算法特别适合用于解决大篇幅文本分类问题,并且我们还证明了该算法解决此类问题的速度要比之前的 SVM 学习方法高一个数量级。
论文地址:http://ttic.uchicago.edu/~nati/Publications/PegasosMPB.pdf

论文标题:Lost Relatives of the Gumbel Trick
论文作者:Matej Balog, Nilesh Tripuraneni, Zoubin Ghahramani, Adrian Weller
论文地址:https://arxiv.org/pdf/1706.04161.pdf

论文标题:Modular Multitask Reinforcement Learning with Policy Sketches
论文作者:Jacob Andreas, Dan Klein, Sergey Levine
论文地址:https://arxiv.org/pdf/1611.01796.pdf

论文标题:A Unified Maximum Likelihood Approach for Estimating Symmetric Properties of Discrete Distributions
论文作者:Jayadev Acharya, Hirakendu Das, Alon Orlitsky, Ananda Suresh
论文地址:http://people.ece.cornell.edu/acharya/papers/pml-opt.pdf
历届被引用量最高论文解读
除了最佳论文之外,AI科技大本营还精选了历届 ICML 收录论文“被引用次数”最高的前五位(来自谷歌学术),通过这些论文,我们可以一窥近年来对机器学习领域产生重要影响的工作:
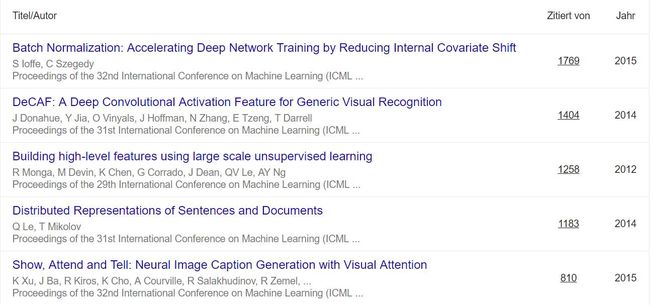
谷歌学术排名
1. 论文标题:批量归一化:通过减少内部协变量转移加速深度网络训练(被引用次数:1769)

论文摘要:在深度神经网络的训练过程中,前一层参数的调整会导致之后每一层输入值的分布发生变化,这种现象使模型的训练变得十分复杂。因此在训练模型时,通常需要选取较小的学习速率并谨慎地对参数进行初始化,但是这不仅会拖慢训练速度,而且还会使饱和非线性模型的训练变得极为困难。这种现象称为“内部协变量转移(covariate shift)”,我们通过归一化(normalizing)每层的输入来解决这个问题。该方法的强大之处在于我们把归一化作为模型架构的一部分, 并对每个训练 mini-batch 都执行归一化操作。批量归一化使我们能够使用更高的学习速率,并且不必过分担心初始化参数的影响,在某些情况下它还可以使模型的训练不依赖 Dropout。
我们在最先进的图像分类模型上应用了批量归一化法,实验证明应用该方法的模型在训练步数减少到原来的 1/14 的情况下可以实现与原模型相同的精度,并且在性能上远超原模型。通过使用批量归一化的网络模型,我们以 4.8% 的测试误差率刷新了 ImageNet 图像分类大赛的最佳纪录,并超出了人类评估者的准确率。
2. 论文标题:DeCAF:应用于一般视觉识别任务的深度卷积激活特征(被引用次数:1404)

论文摘要:本文探究的是,使用一个物体识别任务大数据集对深度卷积网络进行全监督训练,在网络激活时提取出的特征能否应用到新的一般任务中。这些一般任务可能与原来的训练任务大不相同,而且用来训练或调整深度卷积架构适应新任务的标记数据或未标记数据也可能不足。我们对多个此类任务中深度卷积特征的语义分簇进行了研究和可视化操作,这些任务包括场景识别、领域自适应和细粒度图像识别。
我们比较了依据不同网络层定义某一固定特征的效果,在多个重要视觉识别挑战上取得了远远超过当前最高水平的新成绩。我们公布了 DeCAF ,这些深度卷积激活特征的开源实现形式,以及所有相关网络参数,目的是使视觉识别研究人员能够使用深度表征在多种视觉概念学习范例上进行试验。
3. 论文标题:通过大规模无监督学习构建高级别特征(被引用次数:1258)

论文摘要:本文探究的是使用未标记数据构建特定类别的高级特征检测器。例如:仅使用未标记图像,是否能训练一个面部特征检测器?为了回答这个问题,我们借助 pooling(池化法) 和局部对比归一化法,用一个大型图像数据集训练了一个局部连接的 9 层稀疏自动编码器模型(该模型的连接数为 10 亿,该数据集包含 1000 万张从网上下载的200x200像素的图像)。
我们将模型放在一个由 1000 台机器(处理器核心数为 16000)组成的机群上,使用模型并行和异步 SGD 训练三天,生成了该网络。实验结果表明,在不对图像进行(“有脸部”或“无脸部”)标记的情况下,无法训练面部检测器。这与普遍持有的观点截然相反。控制实验表明,该特征检测器不仅对转译,还对缩放和离面转动(out-of-plane rotation)有较好的鲁棒。
我们还发现,同一网络对其他高级概念也很敏感,如猫脸和人体。使用这些训练特征训练该网络,训练后的网络在识别 ImageNet上 的22000个物体类别时实现了 15.8% 的准确度,比先前的最高纪录高 70%。
4. 论文标题:语句和文章的分布式表征(被引用次数:1183)

论文摘要:许多机器学习算法要求输入数据必须表示为长度固定的特征向量。如果输入的是文本,最普遍的一个定长特征为词袋(bag-of-words)特征。词袋特征虽然普及度较高,但是却有两大弊端:它们会打乱单词顺序和忽视单词含义。例如,“powerful” ,“strong” 和 “Paris”这三个单词的分布是等距的。在本文中,我们提出了段落向量(Paragraph Vector),这是一种可以从长度不定的文本(如语句、段落和文章)中学习定长特征表示的无监督算法。这种算法用一个密集向量(dense vector)表示每一篇文章,该向量经过训练后可以预测文章中的文字。密集向量的结构可以使该算法能克服词袋模型的缺陷。实验结果表明,段落向量的表现优于词袋模型和其他文本表示方法。最后,我们在几个文本分类和语义分析任务中刷新了当前的最优成绩。
5. 论文标题:Show,Attend and Tell算法:使用Attention机制生成视觉神经图像描述(被引用次数:810)

论文摘要:基于机器学习和物体识别近期取得的成果,我们提出了一种基于注意力(attention)机制的模型,该模型可以自动学习如何描述图像内容。本文阐述了我们如何使用标准反向传播算法确定地训练模型以及如何通过最大化变分下界(variational lower bound)来随机训练模型。我们还通过可视化方法说明了当在输出序列中生成相应的描述性文字时,模型如何自动学习聚焦图像中明显的物体。我们在 Flickr9k, Flickr30k 和 MS COCO 这三个基准数据集上应用了注意力机制,试验结果表明使用该机制可以实现最佳性能。
在AI科技大本营微信公众号(rgznai100)会话回复“ICML”,下载本文所提到的所有论文。