Python 学习笔记 Day2
笔记目录
- Ⅰ.Python中的几种基本数据类型
- 1.数字
- 进制
- int函数
- float函数
- time库
- 时间获取
- 时间格式化
- 程序计时
- 其他用法
- 数字格式化
- 练习
- 2.字符串
- 字符串的编码
- 创建字符串
- 转义字符
- 拼接字符串
- 复制字符串
- 不换行打印
- 从控制台上读取字符串
- 提取字符串
- 字符串替换
- 字符串切片
- 分割和合并
- 驻留机制
- 常用查找方法
- 去除首位信息
- 字符串格式化
- str.format()
- 3.布尔
- 数值比较
- 数值运算
- 布尔值间运算
- Ⅱ.基本算术运算符
- math库
- 数论和表示函数
- 幂和对数函数
- 三角函数
- 角度转换
- 双曲函数
- 特殊函数
- 常数
- 其他用法
- Ⅲ.增强型赋值运算符
- 1.自动转型
- 2. 操作顺序
- 3.赋值
- 链式赋值
- 系列解包赋值
- Ⅳ.同一运算符
- 整数缓存问题
Ⅰ.Python中的几种基本数据类型
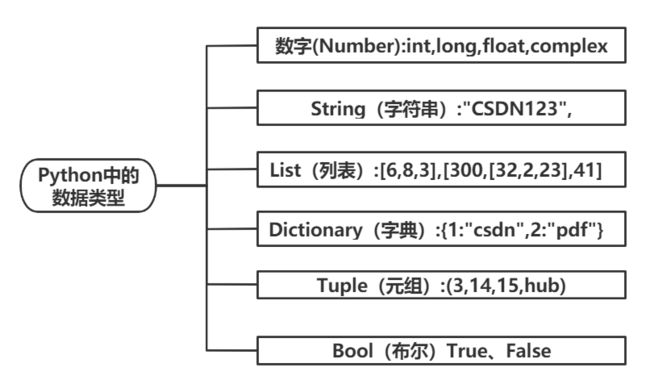
在python中,不需要声明变量的类型就可以直接赋值,因为它把所有的东西都认为是对象
1.数字
数字包括int、long、float、complex:
| 类型 | 说明 |
|---|---|
| int | 整型, int()函数无法转换小数形式的字符串 |
| long | Python3中没有long类型 |
| float | 带小数点的数 |
| complex | 复数 |
进制
在Python中,除了十进制,还常用到几种进制:
| 进制 | 基本进制单位 |
|---|---|
| 二进制(0b或0B) | 0 1 |
| 八进制(0o或0O) | 0 1 2 3 4 5 6 7 |
| 十六进制(0x或0X) | 0 1 2 3 4 5 6 7 8 9 a b c d e f |
int函数
int() 函数用于将一个字符串或数字转换为整型,但要注意:
①浮点数会直接舍弃小数部分,如:int(10.33)的结果是10
②布尔值True转为1,False转为0,int(True)结果是1
③整数格式的字符串可以转换成对应整数,但无法转换小数形式的字符串
float函数
浮点数在内存中用科学计数法存储,关于科学计数法:比如说3.1415,表示成31415E-4或31415e-4
float函数类似于int(),它可以将其他类型转换成浮点数
time库
计算机中的时间是从1970年1月1日 00:00:00开始计时的
Unix时间戳:从格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数
time库:一个可以提供各种与时间相关的函数的库
time库常用的函数分为以下三类:

时间获取
#time()函数
>>>import time
>>>print(time.time()) #获取当前时间戳(返回一个浮点数)
1589482155.6408982
#ctime()函数
>>>print(time.ctime()) #获取当地时区的当前时间(返回字符串)
Fri May 15 02:49:15 2020
#gmtime()函数 - 注:函数的返回的时间是格林威治时间
>>>print(time.gmtime())
time.struct_time(tm_year=2020, tm_mon=5, tm_mday=14, tm_hour=18, tm_min=53, tm_sec=27, tm_wday=3, tm_yday=135, tm_isdst=0)
时间格式化
时间格式化:把自己获取到的时间, 以自己想要表达的格式表达出来

#strftime(tpl,ts)函数 tpl是格式化模板字符串,用来定义自己想要的输出效果
# ts是系统内部时间类型变量
>>>import time
>>>t=time.gmtime()
>>>print(time.strftime("%H:%M:%S",t))
19:12:41
#strptime(str,tpl)函数 str是字符串形式的时间值
>>>tStr='2020-05-15' #自己定义的tStr的时间格式必须和tpl一致
>>>print(time.strptime(tStr,"%Y-%m-%d"))
time.struct_time(tm_year=2020, tm_mon=5, tm_mday=15, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=136, tm_isdst=-1)
程序计时
#perf_counter()函数 返回一个CPU级别的精确时间计数值,单位为秒
>>>import time
>>>start=time.perf_counter()
>>>print(start)
0.0786535
>>>end = time.perf_counter()
>>>print(end)
0.0786648
>>>print(start-end) #计数值起点不确定,所以连续调用求差值才有意义
-1.1299999999991872e-05
#sleep(t)函数 t为休眠时间,单位秒
>>>for x in range(1,10):
time.sleep(1) #延迟一秒执行
print(str(x))
1
2
3
4
5
6
7
8
9
其他用法
参考官网:Time access and conversions
数字格式化
数字格式化:通过指定格式模式获取我们想要的格式化数值,浮点数通过f,整数通过d进行需要的格式化
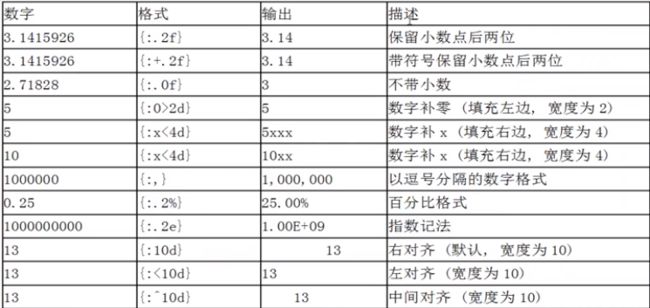
print('{:.3f}'.format(100000.333333))
print('{:+.4f}'.format(100000.333333))
print('{:.0f}'.format(100000.333333))
print('{:,.0f}'.format(100000.333333))
print('{:*^10f}'.format(100000.333333))
print('{:1%}'.format(100000.333333)) #宽度%
print('{:2e}'.format(100000.333333)) #宽度e
print('{:^20f}'.format(100000.333333)) #格式 宽度 类型
print('{:,}'.format(100000.333333))
100000.333
+100000.3333
100000
100,000
100000.333333
10000033.333300%
1.000003e+05
100000.333333
100,000.333333
练习
绘出折线图并计算起点和终点距离:
import math
import turtle
x1,y1=100,6
x1,y1=180,65
x2,y2=135,23
x3,y3=95,160
x4,y4=31,69
turtle.pu()
turtle.goto(x1,y1) #从第一个点开始画
turtle.pd()
turtle.goto(x2,y2)
turtle.goto(x3,y3)
turtle.goto(x4,y4)
distance = math.sqrt((x4-x1)**2+(y4-y1)**2) #计算距离
turtle.write(round(distance))#在图上打印出来
turtle.done()

2.字符串
字符串就是字符序列,和int()函数类似,我们可以用str()来实现把其他类型的数据转换成字符串
>>>str(True)
'True'
字符串的编码
Python3中支持Unicode(可以表示世界上任何书面语言的字符),Python3的字符默认就是16位Unicode编码,ASCII码是Unicode的子集
| 函数 | 说明 |
|---|---|
| ord() | 把字符转换成对应的Unicode码 |
| chr() | 把十进制数字转换成对应字符 |
>>>print(ord('明'))
26126
>>>print(chr(65))
A
创建字符串
我们可以根据字符内容量分为单行字符和多行字符,可以用单引号、双引号或三引号作为边界来表示它们。在Python里面,字符串是不可变的,但我们可以通过复制字符串,再创建一个新的字符串达到看似改变的效果
print( 'ACE' )
print( " It's a coder " )
print( '''
白头吟
两汉:卓文君
皑如山上雪,皎若云间月。
闻君有两意,故来相决绝。
今日斗酒会,明旦沟水头。
躞蹀御沟上,沟水东西流。
凄凄复凄凄,嫁娶不须啼。
愿得一心人,白头不相离。
竹竿何袅袅,鱼尾何簁簁!
男儿重意气,何用钱刀为!
''' )
空字符串:不包含任何字符且长度为0,Python是允许空字符串存在的
⭐len()函数:可以计算字符串含有多少字符
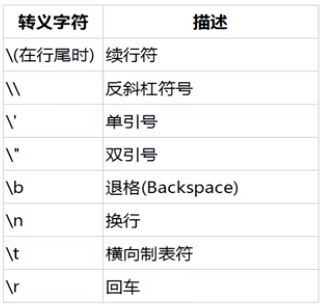
转义字符
我们可以使用 \ + 转义字符实现某些字符难表示的效果:
除此之外,我们还可以用一些其他的函数快速地优化字符串的表达:
| 函数 | 说明 |
|---|---|
| str.title() | 以首字母大写的方式显示每个单词,之后生成的新字符串 |
| str.upper() | 全部变成大写字母,之后生成的新字符串 |
| str.lower() | 全部变成小写字母,之后生成的新字符串 |
| str.capitalize() | 将字符串的第一个字母变成大写,其他字母变小写,之后生成的新字符串 |
| str.swapcase() | 大写变小写,小写变大写,之后生成的新字符串 |
| str.center(width , “fillchar”) | 返回一个长度为width,两边用fillchar(单字符)填充,并居中的字符串,填充默认为空格 |
| str.ljust(width[, fillchar]) | 类似center,左对齐 |
| str.rjust(width,[fillchar]) | 类似center,右对齐 |
>>>name = "ada lovelace"
>>>print(name.title())
Ada Lovelace
>>>print(name.upper())
ADA LOVELACE
>>>print(name.lower())
ada lovelace
拼接字符串
1.可以使用 + 将多个字符串拼接起来,但要注意:
①如果两边都是字符串,则拼接
②如果两边都是数字,则计算
③如果两边类型不同,则报错
>>>a='Leo'
>>>b='nardo'
>>>print(a+b)
Leonardo
2.我们还可以将多个字符串直接放到一起,系统会自动拼接形成一个新的字符串
>>>c='Leo''nardo'
>>>print(c)
Leonardo
复制字符串
用 乘号:* 可以实现字符串的复制
>>>c='Leo''nardo'
>>>print(c*3)
LeonardoLeonardoLeonardo
不换行打印
在使用print的时候,会自动打印一个换行符,当我们不想换行的时候,我们可以通过添加参数:end= ‘‘任意字符串’’ 来实现在末尾添加内容
>>>print("aa",end="*")
>>>print("aa",end="333")
aa*aa333
从控制台上读取字符串
我们可以使用input()函数从控制台读取键盘的内容
>>>code=input('输入密码:')
>>>print('您的密码是:'+code)
输入密码:123
您的密码是:123
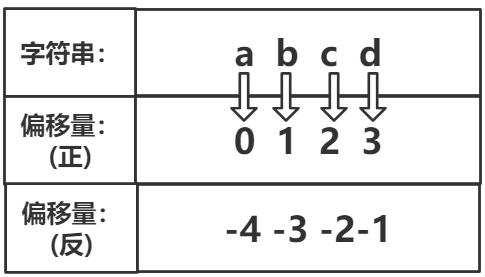
提取字符串
由于字符串的本质是字符序列,在字符串后面添加[ ],在[ ]中添加偏移量可以提取该位置的单个字符
正向搜索:最左侧的第一个字符,偏移量是 0,第二个偏移量是 1,以此类推,直至 len(str)-1
反向搜索:最右侧第一个字符,偏移量是 -1,倒数第二个是 -2,以此类推,直至 -len(str)
字符串替换
在实际操作中,我们可以通过replace()函数创建一个新的字符串,来达到替换我们需要替换的字符的目的
>>>a='abc123'
>>>a.replace('a','A') #用A替换a
>>>print(a)
abc123
>>>print(a.replace('a','A'))
Abc123
字符串切片
切片(Slice)可以快速提取子字符串,其标准格式为:
[起始偏移量Start : 终止偏移量end : 步长step]
常用操作:
| 操作 | 说明 |
|---|---|
| [ : ] | 提取整个字符串 |
| [Start: ] | 从Start到结尾 |
| [ :] | 从头到end-1 |
| [Start :end ] | 从Start 到end-1 |
| [ Start :end :step ] | 从Start 到end-1,每隔step提取一次 |
| [ : ] | 提取整个字符串 |
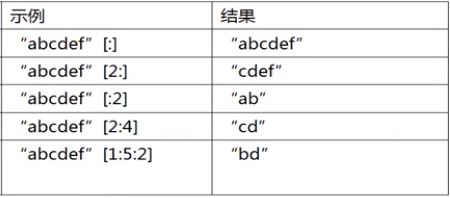
其他操作
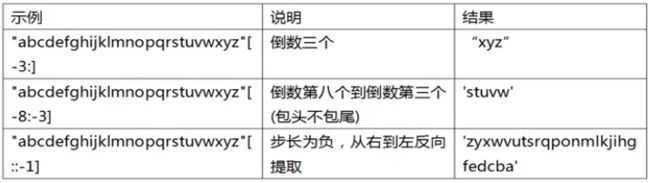
⭐注:切片操作的时候,即使起始偏移量和终止偏移量不在字符串长度范围之类([0, 字符串长度-1]),也不会报错,系统会把起始偏移量小于0的当作0(第一个开始),终止偏移量大于 长度-1 的当成-1(到最后一个),如:
>>>A="abcdefg"[-90:50]
>>>print(A)
abcdefg
练习
1.“to be or not to be ”倒序输出
>>>A="to be or not to be"[::-1]
>>>print(A)
eb ot ton ro eb ot
2.“stxstxstxstxstx” 输出所有的s
>>>A="stxstxstxstxstx"[::3]
>>>print(A)
sssss
分割和合并
1.分割
split()可以基于指定分割符将字符串分割成多个子字符串(存储到列表中)。
如果不指定分隔符,Python则默认使用空白字符(换行符/空白/制表符)
>>>A="to be or not to be"
>>>print(A.split())
['to', 'be', 'or', 'not', 'to', 'be']
>>>print(A.split('be'))
['to ', ' or not to ', '']
2.合并
join()可以用来合并,其作用与split()相反,可以将一连串小字符串连起来
>>>B=['Leo','nar','do']
>>>print('-'.join(B))
Leo-nar-do
拼接的时候,当任务量不大,使用加号或者直接放一起,又或者用join()都可以,但当遇到任务量比较大的时候,用join()比较好
import time
#使用加号
time_1 = time.time()
a=""
for i in range(10000000):
a+="AP"
time_2 = time.time()
print('运行时间'+str(time_2-time_1))
#运行时间24.510071516036987
#使用加号join()
time_3 = time.time()
li=[]
for i in range(10000000):
li.append('AP')
a = ''.join(li)
time_4 = time.time()
print('运行时间'+str(time_4-time_3))
#运行时间1.1120684146881104
驻留机制
对于符合标识符规则:仅包含下划线、字母、数字的字符串会启用字符串驻留机制:仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串驻留池中 — Python支持字符串驻留机制
>>>a = 'AAA_1'
>>>b = 'AAA_1' #'AAA_1'符合标识符规则
>>>print(a is b)
True
>>> c = '!dd#5161asd@&#¥……¥*&……%*&%#得分能力肯定发你'
>>> d = '!dd#5161asd@&#¥……¥*&……%*&%#得分能力肯定发你' #不符合
>>> print(c is d)
False
'''
1.显然,如果查看a和b的地址会发现是相同的,故a和b指向的是同一个对象,如果比较两个对象的值a==b,也是相等的
如果,比较c和d的地址会发现是不同的,说明不是同一个对象,但比较他们的值:c == d 是相等的
2. 通过上诉测试可知:可以直接用==或!= 对字符串进行比较,看看是否有相同的字符(值)
3. 用is 或 is not判断是否是同一个对象,比较的是地址
'''
⭐注:在IDLE里是支持上述机制的,但在PyCharm里对于不符合标识符规则的字符串也会进行驻留
常用查找方法
用一段文本来做测试:
a='鲁迅,中国文学家、思想家和革命家。原名周树人,字豫才,浙江绍兴人。出身于破落封建家庭。青年时代受进化论、尼采超人哲学和托尔斯泰博爱\
思想的影响。1902年去日本留学,原在仙台医学院学医,后从事文艺工作,企图用以改变国民精神。1905—1907年,参加革命党人的活动,\
发表了《摩罗诗力说》、《文化偏至论》等论文。期间曾回国奉母命结婚,夫人朱安。1909年,与其弟周作人一起合译《域外小说集》,介绍外国文学。\
同年回国,先后在杭州、绍兴任教。辛亥革命后,曾任南京临时政府和北京政府教育部部员、佥事等职,兼在北京大学、女子师范大学等校授课'
print( len(a) ) #字符串长度
print( a.startswith('鲁迅') ) #以指定字符开头
print( a.endswith('鲁迅') ) #以指定字符结尾
print( a.find('革命党') ) #第一次出现指定字符的位置
print( a.rfind('革') ) #最后一次出现指定字符的位置
print( a.count('文') ) #指定字符出现了多少次
print( a.isalnum() ) #所有字符都是字母或数字
264
True
False
124
219
5
False
其他方法

去除首位信息
| 函数 | 说明 |
|---|---|
| str.strip() | 去除字符串两端指定的字符 |
| str.lstrip() | 去除左边指定的字符 |
| str.rstrip() | 去除右边指定的字符 |
注:不填的话就是去除空格,包含’\n’ , ‘\r’ , ‘\t’ , ’ ’
字符串格式化
格式化字符串:通过某种办法方法,把指定的字符串转换为想要的输出的样子
str.format()
在str.format()中,我们可以直接通过{索引} / {参数名}直接映射参数值,实现对字符串的格式化
a="name:{0},age:{1}"
print(a.format('Leo','100000'))
b='账号:{account}, 密码:{code}'
print(b.format(account='aaa111',code='123456'))
name:Leo,age:100000
账号:aaa111, 密码:123456
填充与对齐
1.对齐:
| 符号 | 说明 |
|---|---|
| ^ | 居中 |
| < | 左对齐 |
| > | 右对齐 |
>>>a="name:{0:^9},age:{1}" #居中,宽度9
>>>print(a.format('Leo','100000'))
name: Leo ,age:100000
2.填充
填充包括:填充符号和填充位数,需要注意的是冒号(:)后面跟着填充的字符,只能是一个字符,若不写就默认用空格填充
>>>a="name:{0:#^9},age:{1}" # 用#号填充,居中,宽度9
>>>print(a.format('Leo','100000'))
name:###Leo###,age:100000
注:冒号后的书写顺序: 符号→对齐符号→填充位数→数字格式化
>>>a="name:{0:^9},age:{1:*^10.2f}"
#符号 * → 对齐符号 ^ →填充位数 10 →数字格式化 .2f
>>>print(a.format('Leo',100000.333333))
name: Leo ,age:100000.33*
3.布尔
用数据做逻辑判断的运算叫布尔运算,布尔运算会产生布尔值,布尔值会产生True和False

数值比较
在比较条件中,计算机会先做一次布尔运算,判断条件,然后再把判断的结果以布尔值的方式表达出来,这些条件通常包括:等于(==)、不等于(!=)、大于(>)、小于(<)、大于等于(>=)、小于等于(<=)
print(1 == 1) #真
print('a' != 'a') #假
print(1 > 2) #假
print(1 < 2) #真
print(1 >= 2) #假
print(1 <= 1) #真
数值运算
| 真的 | 假的 |
|---|---|
| True | False |
| 非零整数or非零浮点数 | 0 |
| 非空字符串 | 空字符串 |
| 非空字典 | 空字典 |
| 非空列表 | 空列表 |
| None |
print(bool('')) #假
print(bool(100)) #真
在Python3中,人们把True和False定义成了关键字,但他们的本质是0和1,可以和数字进行运算
>>>x = True
>>>print(x+5.66)
>6.66
我们可以使用bool()函数来查看一个数据会被判断为真还是假
>>>print(bool(None))
False
>>>print(bool(3.14))
True
布尔值间运算
布尔值间运算分为五种:and、or、not、in、not in
| 计算方式 | 说明 |
|---|---|
| and | 要求条件全部都要满足为True |
| or | 满足其中一个条件为True |
| not | 对条件取反 |
| in | 判断元素是否在集合里 |
| not in | 判断元素是否不在集合里 |
短路问题:
在计算x or y的时候,若x为True则不计算y,直接返回True
在计算x and y的时候,若x为False,则不计算y直接返回False
a=3
b=-14
c=True
d=[15,9,26]
print(a==3 and b==-14) #真
print(a==3 or b==2) #真
print(not c) #假
print(0 in d) #假
print(5 not in d) #真
Ⅱ.基本算术运算符
| 运算符 | 说明 |
|---|---|
| + | 加法,也可以用来拼接字符串 |
| - | 减法 |
| * | 乘法 |
| / | 除法,当两个整数相除的时候,只取结果的整数部分(只要除号两边有一个数是浮点数,那么结果就是浮点数) |
| // | 整数除法 |
| % | 取模 |
| ** | 幂 |
| divmod(a,b) | 同时得到商和余数的元组 |
| round(value) | 返回四舍五入的新值(不改变原来的值) |
math库
math库包含了各种由C语言定义的数学函数,值得注意的是本库的数域不支持复数域,此外如果没有明确的说明,返回的值都是浮点数。math库主要函数分为以下几类:
数论和表示函数

幂和对数函数

三角函数
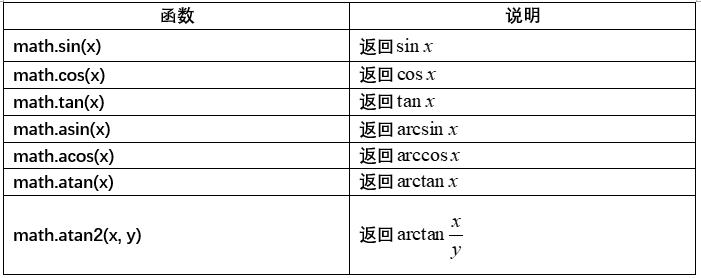
角度转换

双曲函数

特殊函数

常数
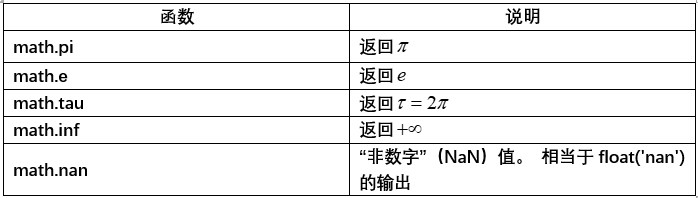
其他用法
参考官网:
math库:Mathematical functions
cmath库:Mathematical functions for complex numbers
SymPy库: SymPy Tutorial
Ⅲ.增强型赋值运算符
| 运算符 | 例子 | 等价形式 |
|---|---|---|
| += | a+=1 | a=a+1 |
| -= | a-=1 | a=a-1 |
| *= | a*=1 | a=a*1 |
| /= | a/=1 | a=a/1 |
| //= | a//=1 | a=a//1 |
| **= | a**=1 | a=a**1 |
| %= | a%=1 | a=a%1 |
注:增强型赋值运算符中间不能加空格
1.自动转型
整数和浮点数混合运算的时候,表达式结果会自动转成浮点数。如1+2.3 结果是 3.3
2. 操作顺序
当一个表达式中出现多个操作符时,求值的顺序依赖于优先顺序原则。对于数学操作符,Python遵守数学的传统规则:先乘除后加减,从左到右运算。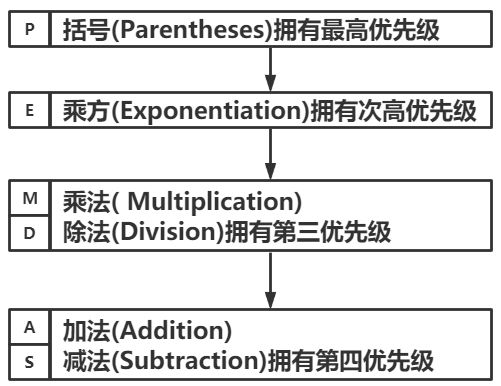
3.赋值
链式赋值
把同一个对象赋值给多个对象
x = y =111
#等价于
x=111
y=111
系列解包赋值
给对应相同个数的变量赋值
x,y,z=3,1,4
#等价于
x=3
y=1
z=4
⭐注:Python不支持常量,需要自行定义
Ⅳ.同一运算符
同一运算符用于比较两个对象的储存单元,也就是比较两个对象的地址
| 运算符 | 说明 |
|---|---|
| is | 判断标识符是不是引用同一个对象 |
| is not | 判断标识符是不是引用同不同对象 |
⭐is 和 ==的区别:
前者主要比较的是对象的地址,而后者判断引用对象的值是否相等( 默认调用对象的eq() )
>>>a=3
>>>b=-14
>>>print(id(a))
140721995961440
>>>print(id(b))
2135891043760
>>>print(a is not b)
True
>>>print(a==b)
False
整数缓存问题
在命令行中执行时,Python只对比较小的整数对象进行缓存便于重复使用,范围为[-5,256],需要注意的是:换到PyCharm中 或 保存为文件执行后,范围是[-5,任意正整数],原因是解释器做了一部分优化
⭐is 运算符比 == 效率高,在变量和None进行比较的时候,用is更好