Python网络爬虫(三):连续爬取百度百科词条数据
1.前言
在Python网络爬虫系列的前两篇文章中,我们分别介绍了使用socket库和urllib库爬取网页数据,也稍稍提及了正则表达式。
但是,实际的爬虫工作更具系统性,更具模块性,也更加具备实用价值
接下来,我们将在一个模块中完成爬虫的几项基本工作:第一,爬取网页;第二,分析网页数据;第三,存储所需资源。
一个可参考的实例是:指定初始地址,利用网络爬虫爬取n条百度百科数据。当n很大时,我们爬取的数据也将具备高价值。
4
2.实例任务
爬取一百条百度百科数据,包含网址,百科词条(标题),百科简介(因为全文数据量较大,故作为演示只需爬取内容简介即可)。初始词条可设置为任意你感兴趣的内容,比如大家现在最喜欢抢的“红包君”。
3.预热分析
在抓取某种网页之前,我们有必要去分析这种网页的重要元素:内容特征,网页结构,编码格式等等。
比如,打开“红包”的百度百科页面,如下图所示:

值得注意的内容有:
一、网址url,注意显示的url并不完全,用鼠标点击可以获取完整的url如下:
完整url:
http://baike.baidu.com/link?url=q1Vnx75TGnVKe-2VGavkiyKpv6bDvayEWkd5NE8na3yTAgl2TjvkqfOJbPuRURvjIT_t9B80T6yVwtJ5dbl53TLthZpI2TucIi9dldjN_3a;
二、百科词条(红包)
三、内容简介
四、超链接(蓝字部分)
接下来,就需要使用审查元素功能查看网页的内容特征和结构。
我们编程时会用到的信息显示在下面两图中:


当然还有编码格式,在head部分可以找到:
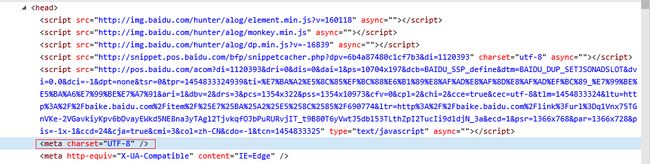
现在准备工作已基本完成。我们就来开始编程工作吧!
4.非封装方式
为了便于理解,本文不采用面向对象的方式编程,但是下一篇博客我会将其整理为五个模块:爬虫调度器,数据管理器,爬虫下载器,网页分析器,内容输出器
以下代码采用循序渐进的方式呈现出来,能够体现出爬虫实现的思想历程。
- 首先导入一些有用的包
#coding:utf8
#written by python 2.7
import re
import urlparse
import urllib
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'- 完成基本网页内容下载
#coding:utf8
#written by python 2.7
import re
import urlparse
import urllib
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
url = raw_input('Enter-') #default url
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
##Download and Prettify Using BeautifulSoup
response = urllib.urlopen(url)
data = response.read()
soup = BeautifulSoup(data)
#print soup.prettify()
print soup #test crawing运行程序,直接按Enter选择默认url执行程序,结果如下图所示:

可知爬虫爬取成功,中文能够正确显示。
接下来我们将从该页面中提取标题和内容简介,这就必须用到预热分析中的标注内容。
- 存储网页关键数据
#coding:utf8
#written by python 2.7
import re
import urlparse
import urllib
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
data_want = dict() #Used to store data contained in one url
data_list = list() #Used to store all data as list
url = raw_input('Enter-')
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
##Download and Prettify Using BeautifulSoup
response = urllib.urlopen(url)
print 'code:', response.getcode() #return 200 if crawing success
data = response.read()
soup = BeautifulSoup(data)
#print soup.prettify()
#print soup #test crawing
##Store important data in a dictionary
data_want['url'] = url
#
title_node = soup.find('dd', attrs = {'class' : 'lemmaWgt-lemmaTitle-title'}).find('h1')
data_want['title'] = title_node.getText()
#
sum_node = soup.find('div', attrs = {'class' : 'lemma-summary'})
data_want['summary'] = sum_node.getText()
data_list.append(data_want) #add one url_data to list
print data_list #Test if data is correct
我们运行程序测试,结果如下所示:

我们发现summary对应的数据是ascii码格式输出,并不是我们希望看到的结果,这里稍微做一下格式化输出的修改即可。
for dic in data_list :
print('url:%s\ntitle:%s\nsummary:%s\n' %(dic['url'], dic['title'], dic['summary']))
输出如下:

可见输出已是正常文字。
- url管理器设计
注意,我们的目标是连续爬取百科词条,所以要设计待爬取词条库,而待爬取此条的url需要从当前页面中提取。那么该如何爬取url呢?
我们看看存在于当前正在爬取页面(比如红包词条)中的超链接html编码格式:
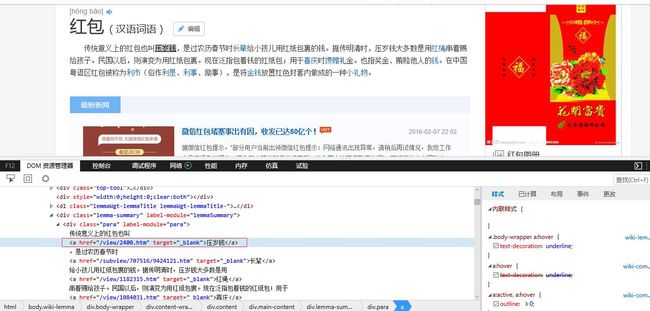
我们发现,它的url是不完整的,需要补全。这一点我们将在代码中实现。
整个程序这一阶段的完整代码如下所示(注意前面部分添加的代码):
#coding:utf8
#written by python 2.7
import re
import urllib
import urlparse
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
#data_want = dict()
data_list = list()
urls_new = list() #Store urls that have not been crawed
urls_old = list() #Store urls that have been crawed
url = raw_input('Enter-')
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
urls_new.append(url) # Add initial url to url_new
count = 1
while len(urls_new) > 0:
url = urls_new.pop()
urls_old.append(url)
print ('Crawing %d url:%s' %(count, url))
##Download and Prettify Using BeautifulSoup
response = urllib.urlopen(url)
count = count + 1
#print 'code:', response.getcode()
if response.getcode() != 200 : #If crawing fails,start next url crawing
print 'Crawing failed!'
continue
data = response.read()
soup = BeautifulSoup(data)
#print soup.prettify()
#print soup #test crawing
##Store important data in a dictionary
data_want['url'] = url
#
title_node = soup.find('dd', attrs = {'class' : 'lemmaWgt-lemmaTitle-title'}).find('h1')
data_want['title'] = title_node.getText()
#
sum_node = soup.find('div', attrs = {'class' : 'lemma-summary'})
data_want['summary'] = sum_node.getText()
# print('url:%s\ntitle:%s\nsummary:%s\n' %(data_want['url'], data_want['title'], data_want['summary']))
data_list.append(data_want) #add one url_data to list
print 'data_list:', data_list
##Find urls and add them to urls_new
links = soup.findAll('a', href = re.compile(r'/view/[0-9]*.htm'))
for link in links:
incomplete_url = link['href']
complete_url = urlparse.urljoin(url, incomplete_url)
if complete_url not in urls_new and complete_url not in urls_old:
urls_new.append(complete_url)
if count > 5 : #Test crawing 5 urls
break
#print data_list #Test if data is correct
for dic in data_list:
print('url:%s\ntitle:%s\nsummary:%s\n' %(dic['url'], dic['title'], dic['summary']))
运行,得到结果如下所示:

程序的确可以运行,但是有一个奇怪的现象:输出的data_list中的元素都是一模一样。为什么会这样!?
这里我们要复习一下list的特性,它是(元素)可变的,在嵌套了dict的基础上,如果相应的同名dict发生了变化,元素也随之变化。
这里的解决方案,我给出的是:使用函数功能屏蔽字典的嵌套,当然也可以有其他方法,大家可自行琢磨。
修改后代码如下所示:
#coding:utf8
#written by python 2.7
import re
import urllib
import urlparse
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
def data_collect(url, soup):
data_want = {}
data_want['url'] = url
title_node = soup.find('dd', attrs = {'class' : 'lemmaWgt-lemmaTitle-title'}).find('h1')
data_want['title'] = title_node.getText()
#
sum_node = soup.find('div', attrs = {'class' : 'lemma-summary'})
data_want['summary'] = sum_node.getText()
return data_want
data_list = list() #Store all the data of all urls crawed
urls_new = list() #Store urls that have not been crawed
urls_old = list() #Store urls that have been crawed
url = raw_input('Enter-')
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
urls_new.append(url) # Add initial url to url_new
count = 1
while len(urls_new) > 0:
url = urls_new.pop()
urls_old.append(url)
print ('Crawing %d url:%s' %(count, url))
##Download and Prettify Using BeautifulSoup
response = urllib.urlopen(url)
count = count + 1
#print 'code:', response.getcode()
if response.getcode() != 200 : #If crawing fails,start next url crawing
print 'Crawing failed!'
continue
data = response.read()
soup = BeautifulSoup(data)
#print soup.prettify()
#print soup #test crawing
my_data = data_collect(url, soup)
data_list.append(my_data)
# print('url:%s\ntitle:%s\nsummary:%s\n' %(data_want['url'], data_want['title'], data_want['summary']))
##Find urls and add them to urls_new
links = soup.findAll('a', href = re.compile(r'/view/[0-9]*.htm'))
for link in links:
incomplete_url = link['href']
complete_url = urlparse.urljoin(url, incomplete_url)
if complete_url not in urls_new and complete_url not in urls_old:
urls_new.append(complete_url)
# print('url:%s\ntitle:%s\nsummary:%s\n' %(data_want['url'], data_want['title'], data_want['summary']))
if count > 5 : #Test 5 urls crawing
break
#print data_list #Test if data is correct
print '\n------------------------------------------------------------------------'
for dic in data_list:
print('url:%s\ntitle:%s\nsummary:%s\n' %(dic['url'], dic['title'], dic['summary']))
输出结果如下所示:

那么这样说明我们的抓取工作是顺利进行的。count变量可用来调整我们抓取的页面数量。
- 内容输出
直接将抓取内容输出到控制台虽然可以看到抓取结果,但不利于整理和分析。因此我们将对数据进行规范存储。有几种备选方案:存储为txt文件,存储为html格式,存储到数据库。
本篇内容我们将采用最常用的方案,存储到txt文件中。
只需在最后补充代码如下:
##Store data in file
fhand = open('baike.txt', 'w')
for dic in data_list:
line = 'url:%s\ntitle:%s\nsummary:%s\n' %(dic['url'].encode('gbk'), dic['title'].encode('gbk'), dic['summary'].encode('gbk'))
fhand.write(line)
fhand.write('\n')
fhand.close()
假设将count设置为20,则打开txt所在文件(与爬虫程序在同一目录中)所见内容如下图所示:

正确存储并显示。
至此,我们的爬虫程序设计就告一段落了~
下面的代码是整理后的全部代码,诸位自取:
#coding:utf8
#written by python 2.7
import re
import urllib
import urlparse
from BeautifulSoup import BeautifulSoup
author = 'Meditator_hkx'
def data_collect(url, soup):
data_want = {}
data_want['url'] = url
title_node = soup.find('dd', attrs = {'class' : 'lemmaWgt-lemmaTitle-title'}).find('h1')
data_want['title'] = title_node.getText()
#
sum_node = soup.find('div', attrs = {'class' : 'lemma-summary'})
data_want['summary'] = sum_node.getText()
return data_want
data_list = list()
urls_new = list() #Store urls that have not been crawed
urls_old = list() #Store urls that have been crawed
url = raw_input('Enter-')
if len(url) < 1 : url = 'http://baike.baidu.com/item/%E7%BA%A2%E5%8C%85/690774'
urls_new.append(url) # Add initial url to url_new
count = 1
while len(urls_new) > 0:
try:
url = urls_new.pop()
urls_old.append(url)
print ('Crawing %d url:%s' %(count, url))
##Download and Prettify Using BeautifulSoup
response = urllib.urlopen(url)
count = count + 1
#print 'code:', response.getcode()
data = response.read()
soup = BeautifulSoup(data)
my_data = data_collect(url, soup)
data_list.append(my_data)
# print('url:%s\ntitle:%s\nsummary:%s\n' %(data_want['url'], data_want['title'], data_want['summary']))
##Find urls and add them to urls_new
links = soup.findAll('a', href = re.compile(r'/view/[0-9]*.htm'))
for link in links:
incomplete_url = link['href']
complete_url = urlparse.urljoin(url, incomplete_url)
if complete_url not in urls_new and complete_url not in urls_old:
urls_new.append(complete_url)
except:
print 'Craw failed!'
if count > 100 :
break
##Store data in file
fhand = open('baike.txt', 'w')
for dic in data_list:
line = 'url:%s\ntitle:%s\nsummary:%s\n' %(dic['url'].encode('gbk'), dic['title'].encode('gbk'), dic['summary'].encode('gbk'))
fhand.write(line)
fhand.write('\n')
fhand.close()