Text to Video
https://arxiv.org/pdf/1710.00421.pdf
该论文使用VAE和GAN混合模型。提取静态特征(文本调节的背景颜色和对象布局结构)和动态特征(通过将输入文本转换为图像过滤器来考虑)。获取大量的数据来训练深度学习模型,我们开发了一种自动创建匹配的方法来文本视频语料库来自公开的在线视频。试验结果表明,提出的框架产生合理和多样的视频,同时准确地反映出这一点输入文字信息。它明显优于基准直接适应文本到图像生成过程的模型制作视频。
hybrid framework: Variational Autoencoder (VAE) + Generative Adversarial Network (GAN).
Static features- “gist” :sketch text-conditioned background color and object layout structure.
Dynamic features: Transforming input text into an image filter
关键:
-both the broad picture and object motion must be determined by the text input.
视频生成与视频预测有关。在视频中预测,目标是学习非线性传递函数在给定帧之间预测后续帧(Vondrick和Torralba 2017) - 这一步也是视频生成所必需的。但是,仅仅预测未来的帧是不够的生成完整的视频。最近的视频生成工作已将视频分解为静态背景,蒙版和移动物体。
与之前的这些关于视频生成的作品形成对比,我们有条件地生成基于视频的侧面信息,特别是文字说明。文本到视频生成需要一个好的条件方案和一个好的视频发生器。 Conditional Scheme + video generator
有一些现有的文本到图像生成的模型(Reed et al。2016;Elman Mansimov和Salakhutdinov 2016);不幸的是,只用视频发生器替换图像发生器即可提供较差的性能(例如严重模式崩溃),我们在我们的实验中详细说明。这些挑战揭示了即使有精心设计的神经网络模型,从文本生成视频也很困难。
为了解决这个问题,我们把这一代任务分成两个部分。首先,一个有条件的VAE模型用于从输入生成视频的“要点”文本,其中的要点是给出背景的图像所需视频的颜色和对象布局。内容和运动在视频要点和文字输入的基础上生成。
1)conditional VAE model
-generate the “gist” of the video from the input text,
- the gist is an image that gives the background color and object layout of the desired video.
2)The content and motion of the video is then generated by conditioning
on both the gist and text input.
这一代的程序是旨在模仿人类创造艺术的方式。特别是艺术家经常画一个广泛的草案,然后填写详细的信息。换句话说,要点生成步骤从文字提取静态和“通用”功能,而视频发生器从中提取动态和“详细”信息文本。
(the gist-generation step extracts static and“universal” features from the text, while the video generator extracts the dynamic and “detailed” information from the text.)
一种结合文本和要点信息的方法是简单地连接来自编码的特征向量文字和要点,就像以前在图像生成中使用的那样(Yan等2016)。这种方法很不幸不能平衡每个功能集的相对强度,因为它们是截然不同的维度。(Instead, this work computes a set of image filter kernels based on the input text and applies the generated filter on the gist picture to get an encoded text gist feature vector.)
相反,这项工作
-计算出一组基于输入文本的图像过滤器内核
-把生成的过滤器应用在主旨图片上以获得编码的文本特征矢量。
-computes a set of image filter kernels based on the input text
- applies the generated filter on the gist picture to get an encoded text gist feature vector.
这个组合矢量更好地模拟了文本与主旨之间的交互不是简单的连接,并且类似于(De Brabandere et al人。 2016)视频预测和图像风格转换。正如我们在实验中演示的那样,文本过滤器更好捕获运动信息并添加详细内容要旨。
我们的贡献总结如下:(i)通过查看要点作为中间步骤,我们提出一个有效的文本到视频生成框架。 (ii)我们证明了这一点使用输入文本生成更好的模型动态过滤器特征。 (iii)我们提出一种构建培训的方法基于YouTube1视频的数据集,其中的视频标题和描述用作附带的文字。这允许丰富的在线视频数据将被用于构建健壮的和强大的视频表现。
Model
文字到视频的生成需要比现在更强大的条件生成器文本到图像生成所必需的。视频是一种4D张量,其中每个帧都是具有颜色信息的2D图像时空依赖。增加的维度挑战生成器提取静态和动作来自输入文字的信息。
第三部分:模型描述
一些Notation
Data: collection of N videos and associated text descriptions, {Vi, ti} for i = 1, . . . , N.
Each video Vi ∈R (T ×C×H×W) with frames Vi = {v1i , · · · , vT i},
- C :number of color bands (typically C = 1 or C = 3)
- H and W :number of pixels in the height and width dimensions, respectively, for each video frame.
Note: that all videos are cut to the same number of frames; this limitation can be avoided by using an RNN generator, but this is left for future work.
Text description t : a sequence of words (natural language).
The index i is only included when necessary for clarity.
The text input was processed with a standard text encoder, which can be jointly trained with the model. we directly adopt the skip-thought vector encoding model (Kiros et al. 2015).
3.1 Gist Generator
在短视频剪辑中,背景通常是静态的只有很小的动作变化。要点产生使用CVAE从文本中产生静态背景(参见示例)图1中的要点)。训练CVAE需要一对文本和图像;在实践中,我们已经发现,简单地使用视频的第一帧,v1,效果很好。CVAE是通过最大化变分下限来训练的。
原来的VAE设定之后(Kingma和Welling 2013),先验p(zg)被设定为各向同性多变量高斯分布; θg和φg分别与解码器和编码器网络有关。该下标g表示要点。编码器网络qφg(zg | v,t)有两个子编码器网络η(·)和ψ(·)。 η(·)被应用到视频帧v。ψ(·)应用于文本输入t。编码器顶部使用线性组合层用来组合编码视频帧和文本。
解码网络将随机噪声zg作为输入。输出这个CVAE网络被称为“gist”,这就是其中之一视频发生器的输入。在测试时间,视频帧上的编码网络是忽略,只有文本上的编码网络ψ(·)是应用。这一步确保模型获取文字条件下视频的sketch。在我们的实验中,我们展示直接创建一个多样化的合理视频文字很难。这个中间步骤很关键。
如前所述,有条件的GAN是以前的用于从文本构建图像(Reed et al。2016)。因为这项工作需要考虑到要点和文本,
it is unfortunately complicated to construct gist-text-video triplets in a similar manner. Instead, first a motion filter is computed based on the text t and applied to the gist, further described in Section 3.3.
不幸的是构建要点文本视频很复杂。相反,首先我们基于文本t计算运动过滤器并进一步应用于要点如3.3节所述。这一步迫使模型使用文本信息生成合理的运动;(simply concatenating the feature sets allows the text information to be given minimal importance on motion generation.)只是连接特征集使得文本信息对于运动生成的重视程度降到最低。这些特征映射被进一步用作CNN编码器的输入(图2中的绿色立方体),如(Isola et al。2016)所述。该编码器的输出由文本向量gt表示,它们共同考虑了要点和文本信息。到目前为止,这项议案并没有在文本要点向量中引入多样性,虽然在基于文本信息的要点抽样中引入了一些变化。
方法的多样性和详细的信息是主要通过串联等距高斯来引入。用文本要点向量生成噪声nv,形成zv = [gt; Nv]。该下标v是视频的简称。随机噪声向量nv为视频赋予运动多样性并对其进行综合信息。我们使用引入的场景动态分解(Vondrick,Pirsiavash和Torralba 2016)。给定矢量zv,发生器的输出视频由下式给出(Notation好多我最后手写搞定了----)等下把手写稿弄上来
第二篇
http://papers.nips.cc/paper/6194-generating-videos-with-scene-dynamics.pdf
Generating Video with Scene Dynamics
Abstract
scene dynamics for both video recognition tasks (e.g. action classification) and
video generation tasks (e.g. future prediction). 视频识别+生成
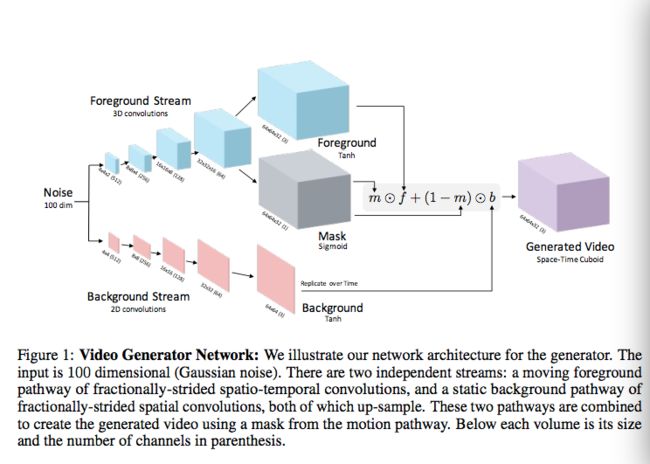
a generative adversarial network for video with a spatio-temporal convolutional architecture that untangles the scene’s foreground from the background.
-视频生成性的对抗网络
-时空卷积架构
-解耦场景的背景和前景。
实验表明这种模式可以:
-在全帧速率下生成比简单基线更好的微小视频,
-预测静态图像的未来方面表现出它的实用性。
-在最小限度监督下 内部学习动作的有用特征 (the model internally learns useful features for recognizing actions with minimal supervision)说明 scene dynamics是一个有用的representation
Intro
但是,由于注释这些知识既昂贵又含糊,而是试图直接从大量的未标记的视频中学习。未标记的视频具有可以在大规模中便宜可大量获得,但包含丰富的免费时间信号的优点,因为帧在时间上是连贯的。为了捕捉视频中大量未标记的时间信号,我们提供了一种方法来学习生成具有相当逼真动态的微小视频。为此,我们利用生成对抗网络的最新进展[9,31,4],。我们引入了一个明确建立模型的双流生成模型把前景与背景分开,这使我们可以强制背景固定,帮助网络学习哪些物体移动,哪些不移动。
我们的实验表明,我们的模型已经开始了解动力学。
1.在我们的生成实验中,模型可以产生合理运动的场景。我们进行心理物理学研究,要求超过一百人比较生成的视频和人,我们更多的时候会选择来自我们full模型的视频。此外,通过使模型conditional on输入图像上,我们的模型有时可以预测一个合理的(但“不正确的”)未来。在我们的识别实验中,我们展示了我们的模型如何在没有监督的情况下学会有用的特征用于人类行为分类。此外,学习表示的可视化表明未来生成可能是学习识别运动物体的有希望的监督信号。(Moreover, visualizations of the learned representation suggest future generation may be a promising supervisory signal for learning to recognize objects of motion.