Java刷题常用API(三)———— 读和写txt文件内容
1)回顾:Scanner和BufferedReader从屏幕读入数据
之前讲了怎么使用Scanner和BufferedReader从屏幕读入数据,如下:
Scanner:
import java.util.Scanner;
// 省略其他代码
Scanner scan = new Scanner(System.in);
scan.nextLine();
scan.close();
BufferedReader:
import java.io.BufferedReader; // 注意是在io包中
// 省略其他代码
InputStreamReader buffer = new InputStreamReader(System.in);
BufferedReader in = new BufferedReader(buffer);
in.readLine();
in.close();
2)Scanner和BufferedReader从文件读入数据
刷题时除了从屏幕接收数据以外,还会有可能从文件中,读取数据。最常见的就是从.txt文件中读取数据。那么此时还是可以使用Scanner和BufferedReader两种方式,回看上面两个例子,其实Scanner和BufferedReader都是将System.in(类型:InputStream)作为输入源,然后进行处理:Scanner直接读取,BufferedReader将输入先放在InputStreamReader缓冲中,再读取。但其实无论是Scanner的构造方法,还是InputStreamReader构造方法,其对形参的要求都仅仅是InputStream而已:
new Scanner(System.in);

new InputStreamReader(System.in);
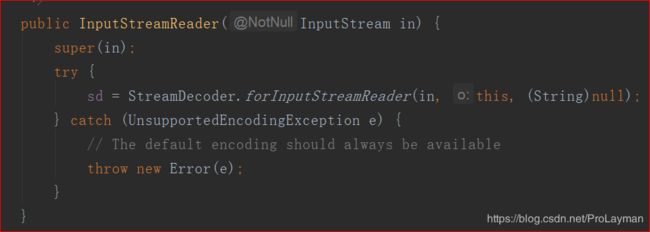
换言之,只要输入是InputStream类型即可,而输入输出流明显除了屏幕还可以来自文件甚至网络,所以如果原始问题是怎么读取.txt文件内容的话,现在问题变成了:怎么将.txt文件转化为InputStream。只要转化为了InputStream,剩下的处理其实和System.in作为入参是一样的。
将一个文件转化为InputStream:FileInputStream(InputSteam子类):
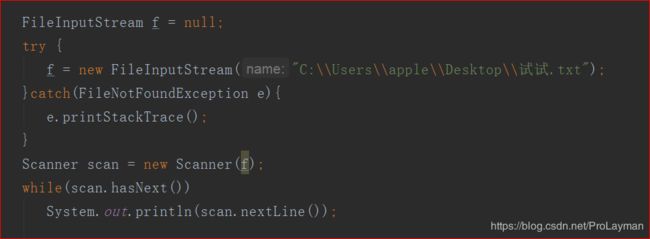
试试.txt内容:
输出:
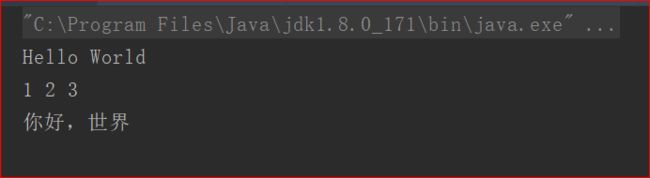
使用BufferedReader的代码及结果:

因为BufferedReader没有像Scanner.hasNext()判断有没有到文件末的判断,所以只能使用while+判断读取下一行的内容是不是null来读取完整的.txt文件。
两个方法都介绍完毕,核心其实就是:
FileInputStream f = new FileInputStream("Path");
3)不是Java默认文件编码方式UTF-8文件的读取
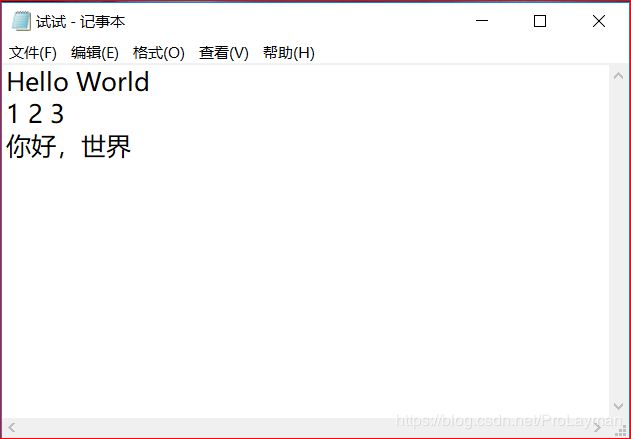
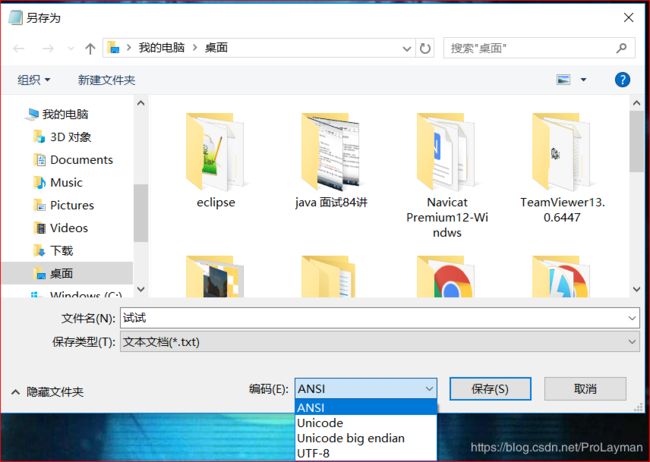
上述例子是成功了,但是其实做了一个预处理的工作:保存文件格式时选择了UTF-8,如果换个编码方式呢:
试试.txt编码方式选择ANSI::
Scanner的读取结果:
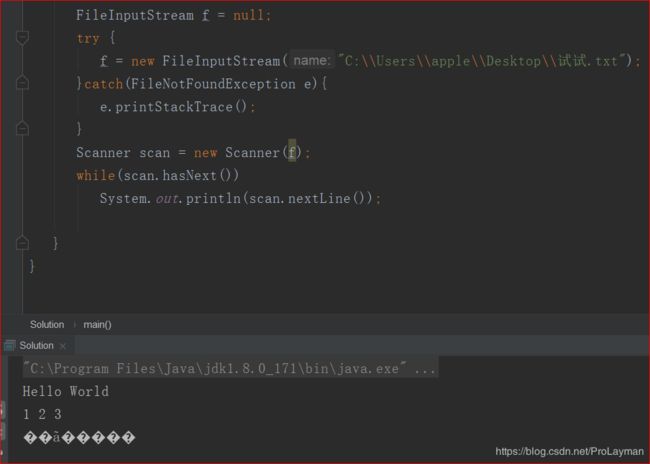
可以看到,中文“你好,世界”乱码了。
这该怎么办呢?
最简单的方法当然就是将.txt文件格式改回为UTF-8编码,并且保证输入文件的格式都是UTF-8格式的。但是有时我们不能控制源文件的编码方式,修改源文件的数据包括格编码方式来适应我们的编程也不符合要求。如果现在就需要读取一定编码方式(不是UTF-8,但已知)的.txt文件,该怎么做呢?
答案就在Scanner和InputStreamReader的构造方法中:
Scanner(InputStream source,String charsetName)

InputStreamReader(InputStream in,String charsetName)
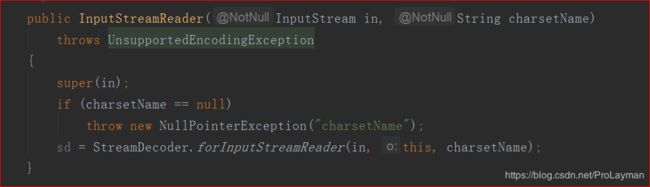
我们可以这么理解:
![]()
FileInputStream获取特定路径下的文件的字节流,注意不是按照编码方式将文件内容由字符流转化为字节流,这涉及到一个基础知识,这里稍微说一下。
文件中的数据在硬盘中都是以01比特流(确切地说是字节流,因为编码方式最小也是字节为最小单位)存储的,但是编码方式指定了各个字符在内存(硬盘中)会以什么样01流表示,相应地,从字节流还原为字符流一定需要使用原来的编码方式——Decode使用Encode的加密算法的你过程即可成功解码,否则一定会报错。
而
![]()
FileInputStream会直接读取硬盘中的“试试.txt”的字节流(01比特流),故不用指定编码方式(没有带charset的构造方法),给了也用不着。而InputStreamReader是做字节流到字符流转换工作的,这个过程中肯定要使用特定的编码方式将01比特流(字节流)翻译为相应的文字,通常我们使用无参的构造方法:
![]()
这里其实默认会使用UTF-8编码方式进行转换(翻译):
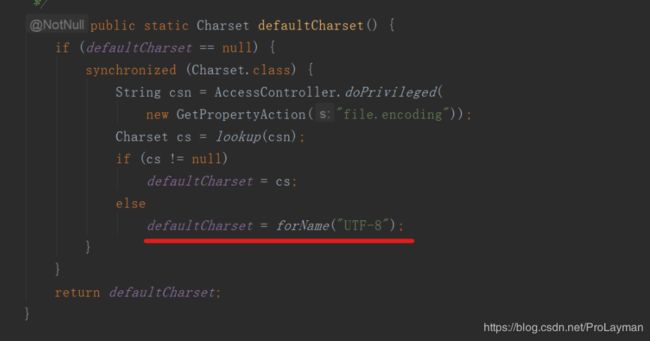
当我们的源文件即“试试.txt”使用的不是UTF-8编码,如GBK编码时——即FileInputStream拿到的是GBK对应的01比特流,当进行字节流到字符流的转换(InputStreamReader)时我们需要使用相同的编码方式。这也就是为什么InputStreamReader提供了带charset的构造方法的原因:
Scanner的入参虽然是InputStream——字节流,但是其所做的操作——nextLine()等返回值全是String,换言之,Scanner自己做了从InputStream到字节流的工作(Reader的工作),当然也可以指定编码:
这样一来问题就迎刃而解了:
我们在Scanner和InputStreamReader的构造方法上加上编码方式即可:
Scanner:
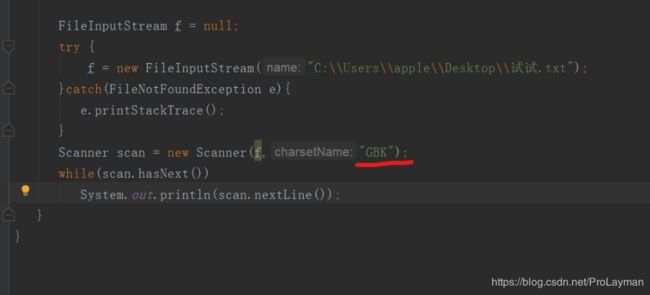
BufferedReader(InputStreamReader):
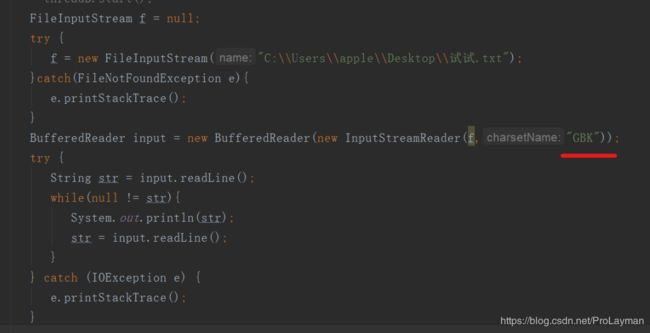
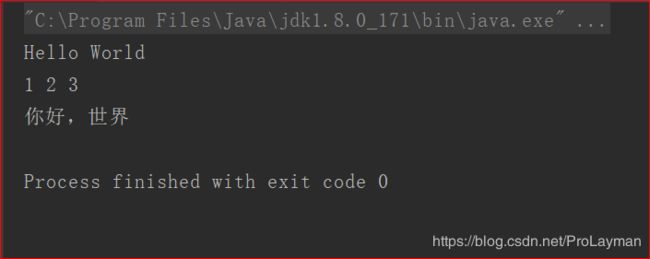
结果:
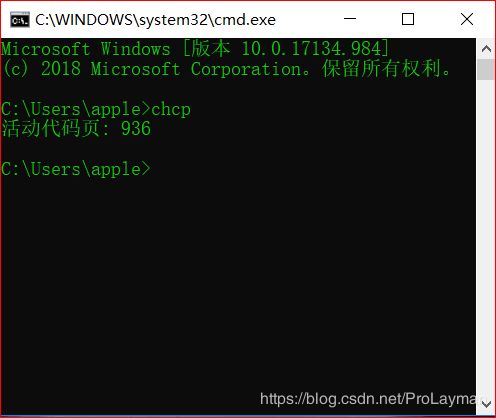
BTW,保存“试试.txt”时我们选择的编码方式明明是:ANSI,为什么上面不指定编码方式为“ANSI” 呢,原因在于Windows的ANSI编码方式代表的是Windows操作系统版本默认的编码,对于中文简体系统即GBK,繁体即Big-5,这个可以命令行 -chcp即可,936意思就是GBK:
4)最简洁的写法
其实,上述读取文件(任何编码方式)的方式还是在System.in上启发修改的,其实Java已经为我们提供了更为快捷的API,看以下例子:
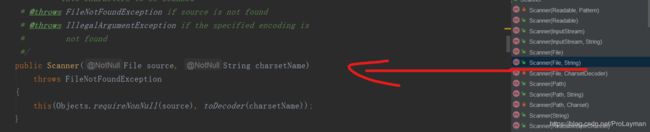
即直接读取文件,那么理所当然的一个简洁方式出现了:
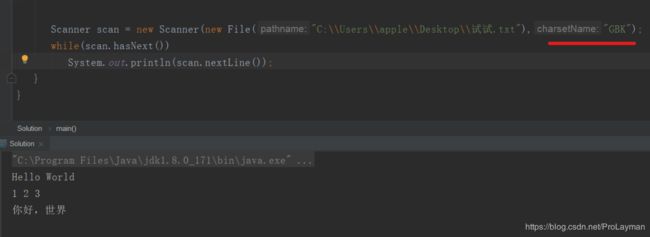
当然,如果源文件就是UTF-8编码,就直接使用new Scanner(new File("Path"))就好了。
5)输出到txt文件

结果:
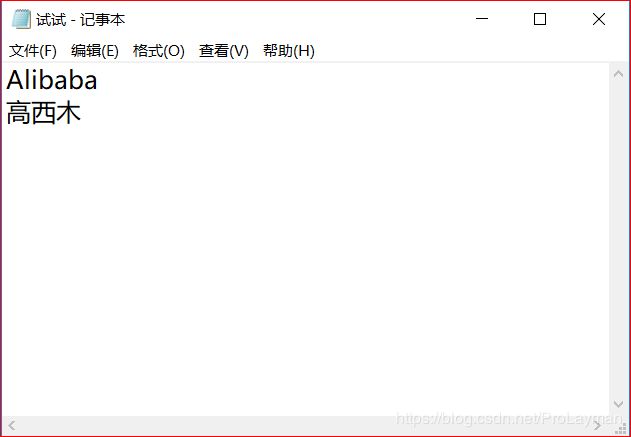
PS:这个有助于理解: