Kaggle竞赛:泰坦尼克号灾难数据分
https://www.kaggle.com/c/titanic
- 目标确定:根据已有数据预测未知旅客生死
- 数据准备:
- 数据获取,载入训练集csv、测试集csv
- 数据清洗,补齐或抛弃缺失值,数据类型变换(字符串转数字)
- 数据重构,根据需要重新构造数据(重组数据,构建新特征)
- 数据分析:
- 描述性分析,画图,直观分析
- 探索性分析,机器学习模型
- 成果输出:csv文件上传得到正确率和排名
载入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
数据获取
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head()
|
PassengerId |
Survived |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
| 0 |
1 |
0 |
3 |
Braund, Mr. Owen Harris |
male |
22.0 |
1 |
0 |
A/5 21171 |
7.2500 |
NaN |
S |
| 1 |
2 |
1 |
1 |
Cumings, Mrs. John Bradley (Florence Briggs Th… |
female |
38.0 |
1 |
0 |
PC 17599 |
71.2833 |
C85 |
C |
| 2 |
3 |
1 |
3 |
Heikkinen, Miss. Laina |
female |
26.0 |
0 |
0 |
STON/O2. 3101282 |
7.9250 |
NaN |
S |
| 3 |
4 |
1 |
1 |
Futrelle, Mrs. Jacques Heath (Lily May Peel) |
female |
35.0 |
1 |
0 |
113803 |
53.1000 |
C123 |
S |
| 4 |
5 |
0 |
3 |
Allen, Mr. William Henry |
male |
35.0 |
0 |
0 |
373450 |
8.0500 |
NaN |
S |
test.head()
|
PassengerId |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
| 0 |
892 |
3 |
Kelly, Mr. James |
male |
34.5 |
0 |
0 |
330911 |
7.8292 |
NaN |
Q |
| 1 |
893 |
3 |
Wilkes, Mrs. James (Ellen Needs) |
female |
47.0 |
1 |
0 |
363272 |
7.0000 |
NaN |
S |
| 2 |
894 |
2 |
Myles, Mr. Thomas Francis |
male |
62.0 |
0 |
0 |
240276 |
9.6875 |
NaN |
Q |
| 3 |
895 |
3 |
Wirz, Mr. Albert |
male |
27.0 |
0 |
0 |
315154 |
8.6625 |
NaN |
S |
| 4 |
896 |
3 |
Hirvonen, Mrs. Alexander (Helga E Lindqvist) |
female |
22.0 |
1 |
1 |
3101298 |
12.2875 |
NaN |
S |
数据概览
train.shape, test.shape
((891, 12), (418, 11))
train.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
test.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
train.csv 具体数据格式
- PassengerId 乘客ID
- Survived 是否幸存。0遇难,1幸存
- Pclass 船舱等级,1Upper,2Middle,3Lower
- Name 姓名,object——————————
- Sex 性别,object—————————
- Age 年龄 缺失177——m————————
- SibSp 兄弟姐妹及配偶个数
- Parch 父母或子女个数
- Ticket 乘客的船票号,object————————
- Fare 乘客的船票价
- Cabin 乘客所在舱位,object,缺失687———————
- Embarked 乘客登船口岸,object,缺失3————————
train.head()
|
PassengerId |
Survived |
Pclass |
Name |
Sex |
Age |
SibSp |
Parch |
Ticket |
Fare |
Cabin |
Embarked |
| 0 |
1 |
0 |
3 |
Braund, Mr. Owen Harris |
male |
22.0 |
1 |
0 |
A/5 21171 |
7.2500 |
NaN |
S |
| 1 |
2 |
1 |
1 |
Cumings, Mrs. John Bradley (Florence Briggs Th… |
female |
38.0 |
1 |
0 |
PC 17599 |
71.2833 |
C85 |
C |
| 2 |
3 |
1 |
3 |
Heikkinen, Miss. Laina |
female |
26.0 |
0 |
0 |
STON/O2. 3101282 |
7.9250 |
NaN |
S |
| 3 |
4 |
1 |
1 |
Futrelle, Mrs. Jacques Heath (Lily May Peel) |
female |
35.0 |
1 |
0 |
113803 |
53.1000 |
C123 |
S |
| 4 |
5 |
0 |
3 |
Allen, Mr. William Henry |
male |
35.0 |
0 |
0 |
373450 |
8.0500 |
NaN |
S |
数据清洗
缺失过多或无关值抛弃
train2 = train.loc[:,['PassengerId','Survived','Pclass','Sex','Age','SibSp','Parch','Fare']]
test2 = test.loc[:, ['PassengerId','Pclass','Sex','Age','SibSp','Parch','Fare']]
train2.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
| 0 |
1 |
0 |
3 |
male |
22.0 |
1 |
0 |
7.2500 |
| 1 |
2 |
1 |
1 |
female |
38.0 |
1 |
0 |
71.2833 |
| 2 |
3 |
1 |
3 |
female |
26.0 |
0 |
0 |
7.9250 |
| 3 |
4 |
1 |
1 |
female |
35.0 |
1 |
0 |
53.1000 |
| 4 |
5 |
0 |
3 |
male |
35.0 |
0 |
0 |
8.0500 |
test2.head()
|
PassengerId |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
| 0 |
892 |
3 |
male |
34.5 |
0 |
0 |
7.8292 |
| 1 |
893 |
3 |
female |
47.0 |
1 |
0 |
7.0000 |
| 2 |
894 |
2 |
male |
62.0 |
0 |
0 |
9.6875 |
| 3 |
895 |
3 |
male |
27.0 |
0 |
0 |
8.6625 |
| 4 |
896 |
3 |
female |
22.0 |
1 |
1 |
12.2875 |
train2.info(), test2.info()
test2.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 7 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Fare 417 non-null float64
dtypes: float64(2), int64(4), object(1)
memory usage: 22.9+ KB
填充年龄空值
age = train2['Age'].median()
age
28.0
train2['Age'].isnull()
0 False
1 False
2 False
3 False
4 False
5 True
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 True
18 False
19 True
20 False
21 False
22 False
23 False
24 False
25 False
26 True
27 False
28 True
29 True
...
861 False
862 False
863 True
864 False
865 False
866 False
867 False
868 True
869 False
870 False
871 False
872 False
873 False
874 False
875 False
876 False
877 False
878 True
879 False
880 False
881 False
882 False
883 False
884 False
885 False
886 False
887 False
888 True
889 False
890 False
Name: Age, Length: 891, dtype: bool
train2.loc[train2['Age'].isnull(), 'Age'] = age
train2.info()
test2.loc[test2['Age'].isnull(), 'Age'] = age
test2.info()
RangeIndex: 418 entries, 0 to 417
Data columns (total 7 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Sex 418 non-null object
Age 418 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Fare 417 non-null float64
dtypes: float64(2), int64(4), object(1)
memory usage: 22.9+ KB
填充船票价格空值
Fare = test2['Fare'].mode()
Fare
test2.loc[test['Fare'].isnull(),'Fare'] = Fare[0]
train2.info(),test2.info()
train2.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
| 0 |
1 |
0 |
3 |
male |
22.0 |
1 |
0 |
7.2500 |
| 1 |
2 |
1 |
1 |
female |
38.0 |
1 |
0 |
71.2833 |
| 2 |
3 |
1 |
3 |
female |
26.0 |
0 |
0 |
7.9250 |
| 3 |
4 |
1 |
1 |
female |
35.0 |
1 |
0 |
53.1000 |
| 4 |
5 |
0 |
3 |
male |
35.0 |
0 |
0 |
8.0500 |
数据类型转换
train2.dtypes,test2.dtypes
(PassengerId int64
Survived int64
Pclass int64
Sex object
Age float64
SibSp int64
Parch int64
Fare float64
dtype: object, PassengerId int64
Pclass int64
Sex object
Age float64
SibSp int64
Parch int64
Fare float64
dtype: object)
性别转换成整型数据
train2['Sex'] = train2['Sex'].map({'female':0, 'male':1}).astype(int)
test2['Sex'] = test2['Sex'].map({'female': 0, 'male': 1}).astype(int)
train2.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
| 0 |
1 |
0 |
3 |
1 |
22.0 |
1 |
0 |
7.2500 |
| 1 |
2 |
1 |
1 |
0 |
38.0 |
1 |
0 |
71.2833 |
| 2 |
3 |
1 |
3 |
0 |
26.0 |
0 |
0 |
7.9250 |
| 3 |
4 |
1 |
1 |
0 |
35.0 |
1 |
0 |
53.1000 |
| 4 |
5 |
0 |
3 |
1 |
35.0 |
0 |
0 |
8.0500 |
数据重构
将SibSp、Parch特征构建两个新特征
- 家庭人口总数 familysize
- 是否单身 isalone
train2.loc[:,'SibSp']
train2.loc[:,'Parch']
train2['familysize'] = train2.loc[:,'SibSp'] + train2.loc[:,'Parch'] + 1
test2['familysize'] = test2.loc[:,'SibSp'] + test2.loc[:,'Parch'] + 1
train2.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
familysize |
| 0 |
1 |
0 |
3 |
1 |
22.0 |
1 |
0 |
7.2500 |
2 |
| 1 |
2 |
1 |
1 |
0 |
38.0 |
1 |
0 |
71.2833 |
2 |
| 2 |
3 |
1 |
3 |
0 |
26.0 |
0 |
0 |
7.9250 |
1 |
| 3 |
4 |
1 |
1 |
0 |
35.0 |
1 |
0 |
53.1000 |
2 |
| 4 |
5 |
0 |
3 |
1 |
35.0 |
0 |
0 |
8.0500 |
1 |
train2['isalone'] = 0
train2.loc[train2['familysize'] == 1,'isalone'] = 1
train2.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
SibSp |
Parch |
Fare |
familysize |
isalone |
| 0 |
1 |
0 |
3 |
1 |
22.0 |
1 |
0 |
7.2500 |
2 |
0 |
| 1 |
2 |
1 |
1 |
0 |
38.0 |
1 |
0 |
71.2833 |
2 |
0 |
| 2 |
3 |
1 |
3 |
0 |
26.0 |
0 |
0 |
7.9250 |
1 |
1 |
| 3 |
4 |
1 |
1 |
0 |
35.0 |
1 |
0 |
53.1000 |
2 |
0 |
| 4 |
5 |
0 |
3 |
1 |
35.0 |
0 |
0 |
8.0500 |
1 |
1 |
数据重构后的最终数据
train3 = train2.loc[:,['PassengerId','Survived','Pclass','Sex','Age','Fare','familysize','isalone']]
train3.head()
test3 = test2.loc[:,['PassengerId','Pclass','Sex','Age','Fare','familysize','isalone']]
test3.head()
|
PassengerId |
Pclass |
Sex |
Age |
Fare |
familysize |
isalone |
| 0 |
892 |
3 |
1 |
34.5 |
7.8292 |
1 |
NaN |
| 1 |
893 |
3 |
0 |
47.0 |
7.0000 |
2 |
NaN |
| 2 |
894 |
2 |
1 |
62.0 |
9.6875 |
1 |
NaN |
| 3 |
895 |
3 |
1 |
27.0 |
8.6625 |
1 |
NaN |
| 4 |
896 |
3 |
0 |
22.0 |
12.2875 |
3 |
NaN |
数据分析
描述性分析
d = train3[['isalone', 'Survived']].groupby(['isalone']).mean()
d
|
Survived |
| isalone |
|
| 0 |
0.505650 |
| 1 |
0.303538 |
plt.bar(
[0,1],
[1-d.loc[0,'Survived'],1-d.loc[1,'Survived']],
0.5,
color='r',
alpha=0.5,
)
plt.xticks([0,1],['notalone','alone'])
plt.show()
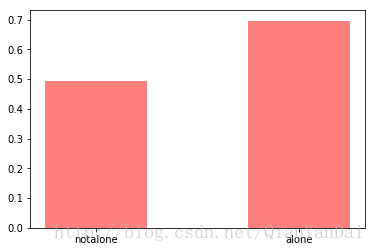
n = train3[['Sex', 'Survived']].groupby(['Sex']).mean()
n
|
Survived |
| Sex |
|
| 0 |
0.742038 |
| 1 |
0.188908 |
plt.bar(
[0,1],
[1-n.loc[0,'Survived'],1-n.loc[1,'Survived']],
0.5,
color='g',
alpha=0.7
)
plt.xticks([0,1],['female','male'])
plt.show()
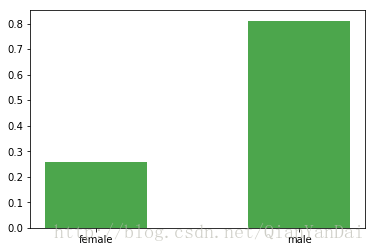
c = train3[['Pclass', 'Survived']].groupby(['Pclass']).mean()
c
|
Survived |
| Pclass |
|
| 1 |
0.629630 |
| 2 |
0.472826 |
| 3 |
0.242363 |
plt.bar(
[0,1,2],
[1-c.loc[1,'Survived'],1-c.loc[2,'Survived'],1-c.loc[3,'Survived']],
0.5,
color='b',
alpha=0.7
)
plt.xticks([0,1,2],[1,2,3])
plt.show()

age = train3[['Age', 'Survived']].groupby(['Age']).mean()
age
|
Survived |
| Age |
|
| 0.42 |
1.000000 |
| 0.67 |
1.000000 |
| 0.75 |
1.000000 |
| 0.83 |
1.000000 |
| 0.92 |
1.000000 |
| 1.00 |
0.714286 |
| 2.00 |
0.300000 |
| 3.00 |
0.833333 |
| 4.00 |
0.700000 |
| 5.00 |
1.000000 |
| 6.00 |
0.666667 |
| 7.00 |
0.333333 |
| 8.00 |
0.500000 |
| 9.00 |
0.250000 |
| 10.00 |
0.000000 |
| 11.00 |
0.250000 |
| 12.00 |
1.000000 |
| 13.00 |
1.000000 |
| 14.00 |
0.500000 |
| 14.50 |
0.000000 |
| 15.00 |
0.800000 |
| 16.00 |
0.352941 |
| 17.00 |
0.461538 |
| 18.00 |
0.346154 |
| 19.00 |
0.360000 |
| 20.00 |
0.200000 |
| 20.50 |
0.000000 |
| 21.00 |
0.208333 |
| 22.00 |
0.407407 |
| 23.00 |
0.333333 |
| … |
… |
| 44.00 |
0.333333 |
| 45.00 |
0.416667 |
| 45.50 |
0.000000 |
| 46.00 |
0.000000 |
| 47.00 |
0.111111 |
| 48.00 |
0.666667 |
| 49.00 |
0.666667 |
| 50.00 |
0.500000 |
| 51.00 |
0.285714 |
| 52.00 |
0.500000 |
| 53.00 |
1.000000 |
| 54.00 |
0.375000 |
| 55.00 |
0.500000 |
| 55.50 |
0.000000 |
| 56.00 |
0.500000 |
| 57.00 |
0.000000 |
| 58.00 |
0.600000 |
| 59.00 |
0.000000 |
| 60.00 |
0.500000 |
| 61.00 |
0.000000 |
| 62.00 |
0.500000 |
| 63.00 |
1.000000 |
| 64.00 |
0.000000 |
| 65.00 |
0.000000 |
| 66.00 |
0.000000 |
| 70.00 |
0.000000 |
| 70.50 |
0.000000 |
| 71.00 |
0.000000 |
| 74.00 |
0.000000 |
| 80.00 |
1.000000 |
88 rows × 1 columns
plt.figure(2, figsize=(20,5))
plt.bar(
age.index,
age.values,
0.5,
color='r',
alpha=0.7
)
plt.xticks(age.index,rotation=90)
plt.show()

fare = train3[['Fare', 'Survived']].groupby(['Fare']).mean()
fare
|
Survived |
| Fare |
|
| 0.0000 |
0.066667 |
| 4.0125 |
0.000000 |
| 5.0000 |
0.000000 |
| 6.2375 |
0.000000 |
| 6.4375 |
0.000000 |
| 6.4500 |
0.000000 |
| 6.4958 |
0.000000 |
| 6.7500 |
0.000000 |
| 6.8583 |
0.000000 |
| 6.9500 |
0.000000 |
| 6.9750 |
0.500000 |
| 7.0458 |
0.000000 |
| 7.0500 |
0.000000 |
| 7.0542 |
0.000000 |
| 7.1250 |
0.000000 |
| 7.1417 |
1.000000 |
| 7.2250 |
0.250000 |
| 7.2292 |
0.266667 |
| 7.2500 |
0.076923 |
| 7.3125 |
0.000000 |
| 7.4958 |
0.333333 |
| 7.5208 |
0.000000 |
| 7.5500 |
0.250000 |
| 7.6292 |
0.000000 |
| 7.6500 |
0.250000 |
| 7.7250 |
0.000000 |
| 7.7292 |
0.000000 |
| 7.7333 |
0.500000 |
| 7.7375 |
0.500000 |
| 7.7417 |
0.000000 |
| … |
… |
| 80.0000 |
1.000000 |
| 81.8583 |
1.000000 |
| 82.1708 |
0.500000 |
| 83.1583 |
1.000000 |
| 83.4750 |
0.500000 |
| 86.5000 |
1.000000 |
| 89.1042 |
1.000000 |
| 90.0000 |
0.750000 |
| 91.0792 |
1.000000 |
| 93.5000 |
1.000000 |
| 106.4250 |
0.500000 |
| 108.9000 |
0.500000 |
| 110.8833 |
0.750000 |
| 113.2750 |
0.666667 |
| 120.0000 |
1.000000 |
| 133.6500 |
1.000000 |
| 134.5000 |
1.000000 |
| 135.6333 |
0.666667 |
| 146.5208 |
1.000000 |
| 151.5500 |
0.500000 |
| 153.4625 |
0.666667 |
| 164.8667 |
1.000000 |
| 211.3375 |
1.000000 |
| 211.5000 |
0.000000 |
| 221.7792 |
0.000000 |
| 227.5250 |
0.750000 |
| 247.5208 |
0.500000 |
| 262.3750 |
1.000000 |
| 263.0000 |
0.500000 |
| 512.3292 |
1.000000 |
248 rows × 1 columns
plt.figure(2, figsize=(20,5))
plt.bar(
fare.index,
fare.values,
0.5,
color='r',
alpha=0.7
)
plt.xticks(fare.index,rotation=90)
plt.show()
得出结论
jieguo = pd.DataFrame(np.arange(0,418),index=test3.loc[:,'PassengerId'])
jieguo.loc[:,0] = 1
jieguo.head()
|
0 |
| PassengerId |
|
| 892 |
1 |
| 893 |
1 |
| 894 |
1 |
| 895 |
1 |
| 896 |
1 |
jieguo.loc[test3[test3.loc[:,'isalone'] == 1].loc[:,'PassengerId'].values] = 0
jieguo.head()
|
0 |
| PassengerId |
|
| 892 |
1 |
| 893 |
1 |
| 894 |
1 |
| 895 |
1 |
| 896 |
1 |
输出结论
jieguo.to_csv('isalone.csv')
new3 = pd.DataFrame(np.arange(0,418),index=test3.loc[:,'PassengerId'].values)
new3[0] = 0
new3.head()
|
0 |
| 892 |
0 |
| 893 |
0 |
| 894 |
0 |
| 895 |
0 |
| 896 |
0 |
new3.loc[test3[test3.loc[:,'Sex'] == 0].loc[:,'PassengerId'].values] = 1
new3.head()
|
0 |
| 892 |
0 |
| 893 |
1 |
| 894 |
0 |
| 895 |
0 |
| 896 |
1 |
new3.loc[test2[test2.loc[:,'Pclass'] == 3].loc[:,'PassengerId'].values] = 0
new3.head()
|
0 |
| 892 |
0 |
| 893 |
0 |
| 894 |
0 |
| 895 |
0 |
| 896 |
0 |
new3.to_csv('cangwei-xingbie.csv')
机器学习建模
train3.head()
|
PassengerId |
Survived |
Pclass |
Sex |
Age |
Fare |
familysize |
isalone |
| 0 |
1 |
0 |
3 |
1 |
22.0 |
7.2500 |
2 |
0 |
| 1 |
2 |
1 |
1 |
0 |
38.0 |
71.2833 |
2 |
0 |
| 2 |
3 |
1 |
3 |
0 |
26.0 |
7.9250 |
1 |
1 |
| 3 |
4 |
1 |
1 |
0 |
35.0 |
53.1000 |
2 |
0 |
| 4 |
5 |
0 |
3 |
1 |
35.0 |
8.0500 |
1 |
1 |
from sklearn import neighbors,datasets
x = train3.loc[:,['Pclass','Sex','familysize']]
y = train3.loc[:,'Survived']
clf = neighbors.KNeighborsClassifier(n_neighbors = 20)
clf.fit(x,y)
clf
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=20, p=2,
weights='uniform')
z = clf.predict(test3.loc[:,['Pclass','Sex','familysize']])
z
array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0,
0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0,
1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1,
0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1,
0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1,
1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0,
1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0,
1, 0, 0, 0], dtype=int64)
s = np.arange(892, 1310)
s
results = pd.DataFrame(z, index=s)
results.head()
|
0 |
| 892 |
0 |
| 893 |
0 |
| 894 |
0 |
| 895 |
0 |
| 896 |
1 |
results.to_csv('Titanic_knn.csv')